文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
- [3. 实战总结](#3. 实战总结)
1. 实战概述
- 本次实战通过
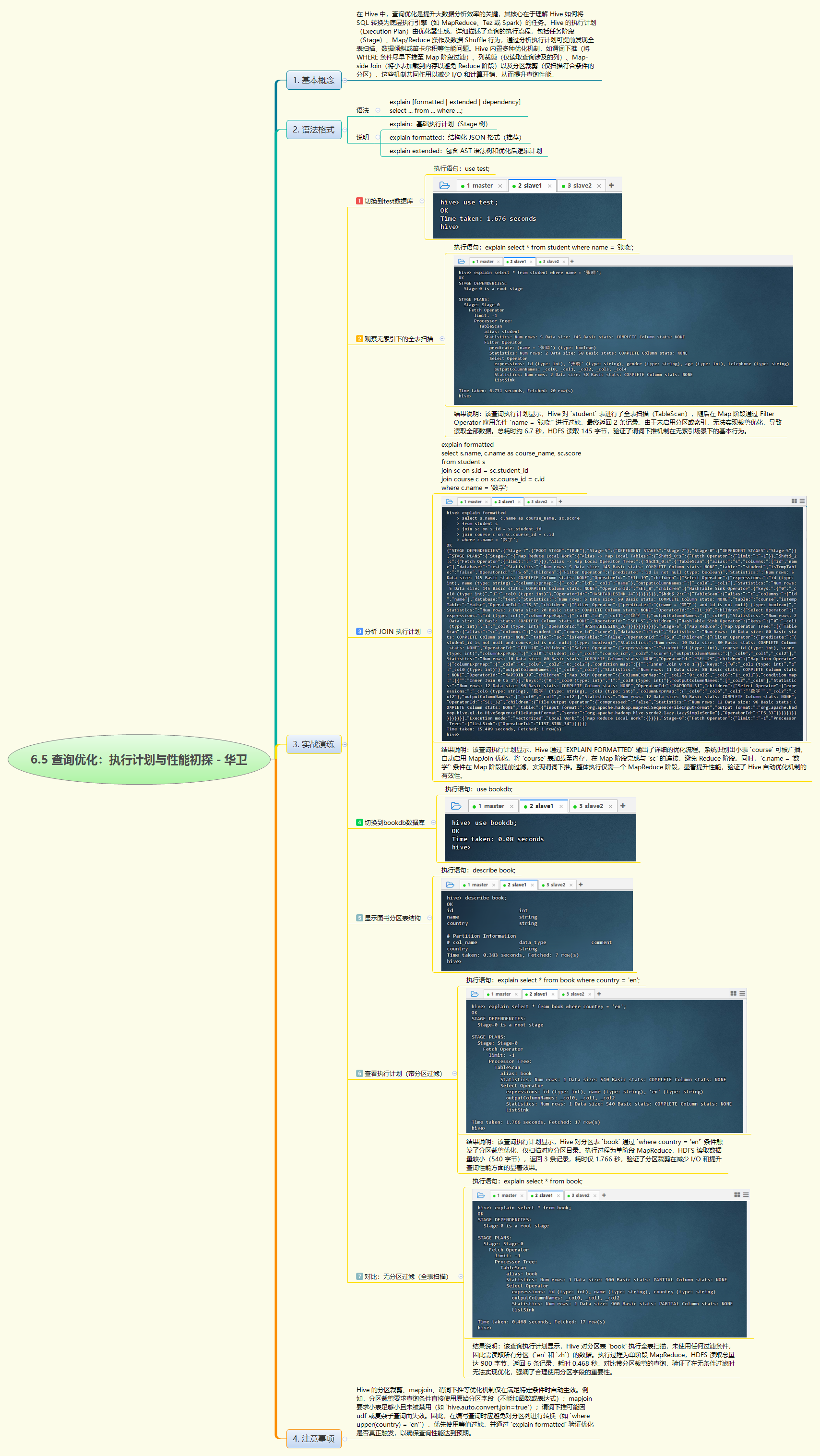
explain命令分析了三类典型查询的执行计划:普通表全表扫描、多表 JOIN 优化及分区表裁剪效果。验证了谓词下推、MapJoin 和分区裁剪等 Hive 自动优化机制的实际生效情况,直观展示了合理使用分区字段与小表关联对减少 I/O、提升性能的关键作用。
2. 实战步骤
3. 实战总结
- 本次实训围绕 Hive 查询优化展开,通过
explain命令深入分析了执行计划的结构与优化行为。在test数据库中,验证了普通表查询虽无法分区裁剪,但能通过谓词下推在 Map 阶段过滤数据;多表join 查询因course表较小,自动触发 MapJoin 优化,避免 Reduce 阶段,提升效率。在bookdb数据库中,利用按country分区的book表,清晰对比了带分区条件(where country = 'en')与无条件查询的执行差异:前者仅扫描目标分区,显著减少 HDFS 读取量,后者则全表扫描所有分区。实验表明,合理设计表结构(如分区)、规范编写查询语句(避免对分区列使用函数),并结合explain formatted验证优化效果,是实现高效 Hive 查询的关键实践。