目 录
-
- 摘要
- [1. 引言:MongoDB聚合框架的重要性](#1. 引言:MongoDB聚合框架的重要性)
- [2. 聚合管道基础:核心操作阶段详解](#2. 聚合管道基础:核心操作阶段详解)
-
- [2.1 聚合管道概述](#2.1 聚合管道概述)
- [2.2 match:数据过滤的第一道关卡](#2.2 match:数据过滤的第一道关卡)
- [2.3 group:数据分组与聚合计算](#2.3 group:数据分组与聚合计算)
- [2.4 project:字段投影与数据重塑](#2.4 project:字段投影与数据重塑)
- [2.5 常用管道阶段对比](#2.5 常用管道阶段对比)
- [3. 聚合管道进阶:多表关联与复杂操作](#3. 聚合管道进阶:多表关联与复杂操作)
-
- [3.1 lookup:实现左连接查询](#3.1 lookup:实现左连接查询)
- [3.2 unwind:数组展开与元素级处理](#3.2 unwind:数组展开与元素级处理)
- [3.3 facet:并行执行多个聚合管道](#3.3 facet:并行执行多个聚合管道)
- [3.4 进阶操作符对比](#3.4 进阶操作符对比)
- [4. 索引优化策略:让查询飞起来](#4. 索引优化策略:让查询飞起来)
-
- [4.1 索引基础与设计原则](#4.1 索引基础与设计原则)
- [4.2 单字段索引与复合索引实战](#4.2 单字段索引与复合索引实战)
- [4.3 文本索引与搜索优化](#4.3 文本索引与搜索优化)
- [4.4 索引性能监控与优化](#4.4 索引性能监控与优化)
- [5. 分片集群架构:海量数据的解决方案](#5. 分片集群架构:海量数据的解决方案)
-
- [5.1 分片集群概述](#5.1 分片集群概述)
- [5.2 分片键选择策略](#5.2 分片键选择策略)
- [5.3 均衡器与数据迁移](#5.3 均衡器与数据迁移)
- [5.4 配置服务器高可用](#5.4 配置服务器高可用)
- [6. 分片集群性能优化:深入细节](#6. 分片集群性能优化:深入细节)
-
- [6.1 查询路由优化](#6.1 查询路由优化)
- [6.2 写入性能优化](#6.2 写入性能优化)
- [6.3 分片集群监控指标](#6.3 分片集群监控指标)
- [7. 实战案例:电商订单分析系统](#7. 实战案例:电商订单分析系统)
-
- [7.1 业务背景与需求](#7.1 业务背景与需求)
- [7.2 数据模型设计](#7.2 数据模型设计)
- [7.3 分片集群架构设计](#7.3 分片集群架构设计)
- [7.4 核心聚合查询实现](#7.4 核心聚合查询实现)
- [7.5 性能优化实践](#7.5 性能优化实践)
- [8. 常见问题与解决方案](#8. 常见问题与解决方案)
-
- [8.1 聚合管道内存溢出](#8.1 聚合管道内存溢出)
- [8.2 分片数据倾斜](#8.2 分片数据倾斜)
- [8.3 分片键无法更改](#8.3 分片键无法更改)
- [9. 总结](#9. 总结)
- 参考资料
摘要
MongoDB作为当今最流行的NoSQL数据库之一,其聚合框架(Aggregation Framework)为数据处理提供了强大而灵活的能力。本文深入探讨MongoDB聚合管道的核心原理与实战应用,从基础的 m a t c h 、 match、 match、group操作到进阶的 l o o k u p 、 lookup、 lookup、facet多表关联,系统性地讲解聚合管道的设计思路与性能优化技巧。同时,本文重点剖析分片集群的架构设计,涵盖分片键选择策略、均衡器工作机制、配置服务器高可用方案等核心内容,并结合电商订单分析系统的真实案例,展示如何在实际项目中落地这些技术。通过本文的学习,读者将掌握MongoDB聚合框架的最佳实践,以及大规模数据场景下的性能调优方法。
1. 引言:MongoDB聚合框架的重要性
在现代应用开发中,数据处理能力往往决定了系统的上限。传统的SQL数据库通过JOIN操作实现多表关联,而MongoDB作为文档型数据库,采用了完全不同的设计理念------聚合框架(Aggregation Framework)。
聚合框架是MongoDB最核心的数据处理引擎,它允许开发者通过管道(Pipeline)的方式,将多个数据处理阶段串联起来,实现复杂的数据转换、过滤、分组和统计操作。与传统的MapReduce相比,聚合框架具有更高的执行效率和更简洁的语法表达。
为什么聚合框架如此重要?首先,它解决了MongoDB早期版本中复杂查询能力不足的问题。其次,聚合管道的声明式语法让数据逻辑更加清晰可维护。更重要的是,聚合框架与索引、分片等特性深度整合,能够在海量数据场景下保持出色的性能表现。
在实际项目中,聚合框架的应用场景非常广泛:电商平台的销售报表统计、社交平台的好友关系分析、物联网设备的数据聚合、日志系统的实时监控等。掌握聚合框架,意味着拥有了处理复杂数据需求的利器。
2. 聚合管道基础:核心操作阶段详解
2.1 聚合管道概述
聚合管道是MongoDB聚合框架的核心概念。它借鉴了Unix管道的思想,将数据处理的各个阶段串联起来,前一个阶段的输出作为后一个阶段的输入,最终产生期望的结果。

上图展示了聚合管道的基本工作流程。每个阶段都是一个操作符,对数据进行特定的转换处理。这种设计模式的优点在于:逻辑清晰、易于调试、性能可预测。
2.2 $match:数据过滤的第一道关卡
$match阶段用于过滤文档,类似于SQL中的WHERE子句。它应该尽可能放在管道的前面,这样可以减少后续阶段需要处理的数据量,提升整体性能。
javascript
// 示例:$match过滤订单数据
db.orders.aggregate([
{
$match: {
status: "completed",
orderDate: {
$gte: ISODate("2024-01-01"),
$lt: ISODate("2024-12-31")
},
totalAmount: { $gt: 100 }
}
}
])上述代码展示了 m a t c h 阶段的典型用法。我们过滤了状态为 " c o m p l e t e d " 、订单日期在 2024 年内、总金额大于 100 的订单。这个查询可以利用 s t a t u s 、 o r d e r D a t e 、 t o t a l A m o u n t 字段上的索引,实现高效的文档过滤。在实际应用中, match阶段的典型用法。我们过滤了状态为"completed"、订单日期在2024年内、总金额大于100的订单。这个查询可以利用status、orderDate、totalAmount字段上的索引,实现高效的文档过滤。在实际应用中, match阶段的典型用法。我们过滤了状态为"completed"、订单日期在2024年内、总金额大于100的订单。这个查询可以利用status、orderDate、totalAmount字段上的索引,实现高效的文档过滤。在实际应用中,match阶段通常结合索引使用,能够显著提升查询性能。
2.3 $group:数据分组与聚合计算
$group阶段是聚合管道中最强大的操作之一,它可以根据指定字段对文档进行分组,并对每个分组执行聚合计算。
javascript
// 示例:按产品类别统计销售数据
db.orders.aggregate([
{ $unwind: "$items" },
{
$group: {
_id: "$items.category",
totalSales: { $sum: "$items.price" },
avgOrderValue: { $avg: "$totalAmount" },
orderCount: { $sum: 1 },
maxOrder: { $max: "$totalAmount" },
minOrder: { $min: "$totalAmount" },
uniqueProducts: { $addToSet: "$items.productId" }
}
},
{
$project: {
category: "$_id",
totalSales: 1,
avgOrderValue: { $round: ["$avgOrderValue", 2] },
orderCount: 1,
maxOrder: 1,
minOrder: 1,
productCount: { $size: "$uniqueProducts" }
}
}
])这段代码实现了按产品类别统计销售数据的功能。首先使用 u n w i n d 展开订单中的商品数组,然后按商品类别分组,计算总销售额、平均订单金额、订单数量、最大 / 最小订单金额、以及唯一商品数量。 unwind展开订单中的商品数组,然后按商品类别分组,计算总销售额、平均订单金额、订单数量、最大/最小订单金额、以及唯一商品数量。 unwind展开订单中的商品数组,然后按商品类别分组,计算总销售额、平均订单金额、订单数量、最大/最小订单金额、以及唯一商品数量。group阶段支持多种聚合操作符,包括 s u m 、 sum、 sum、avg、 m a x 、 max、 max、min、 p u s h 、 push、 push、addToSet等,能够满足各种统计需求。
2.4 $project:字段投影与数据重塑
$project阶段用于选择、重命名、添加或删除字段,类似于SQL中的SELECT子句。它可以帮助我们精简输出数据,减少网络传输开销。
javascript
// 示例:$project重塑用户数据
db.users.aggregate([
{
$project: {
_id: 0,
userId: "$_id",
fullName: {
$concat: ["$firstName", " ", "$lastName"]
},
email: 1,
age: {
$cond: {
if: { $gte: ["$birthYear", 2000] },
then: "00后",
else: {
$cond: {
if: { $gte: ["$birthYear", 1990] },
then: "90后",
else: "其他"
}
}
}
},
address: {
city: "$address.city",
country: "$address.country"
},
accountStatus: {
$switch: {
branches: [
{ case: { $eq: ["$status", 1] }, then: "活跃" },
{ case: { $eq: ["$status", 2] }, then: "休眠" },
{ case: { $eq: ["$status", 3] }, then: "冻结" }
],
default: "未知"
}
}
}
}
])上述代码展示了 p r o j e c t 阶段的多种用法。我们排除 了 i d 字段, 将 i d 重命名为 u s e r I d ,使用 project阶段的多种用法。我们排除了_id字段,将_id重命名为userId,使用 project阶段的多种用法。我们排除了id字段,将id重命名为userId,使用concat合并姓名字段,使用 c o n d 进行条件判断生成分年龄段标签,使用 cond进行条件判断生成分年龄段标签,使用 cond进行条件判断生成分年龄段标签,使用switch实现多分支条件判断,还展示了嵌套文档的重塑方式。$project阶段非常灵活,是数据清洗和格式化的利器。
2.5 常用管道阶段对比
| 阶段 | 功能描述 | 典型应用场景 | 性能影响 |
|---|---|---|---|
| $match | 过滤文档,类似WHERE | 数据筛选、范围查询 | ✅ 推荐优先使用,可利用索引 |
| $group | 分组聚合,类似GROUP BY | 统计报表、数据分析 | ⚠️ 内存消耗较大,注意分片键 |
| $project | 字段投影,类似SELECT | 数据清洗、格式转换 | ✅ 轻量级操作 |
| $sort | 排序,类似ORDER BY | 结果排序、Top N查询 | ⚠️ 内存消耗大,建议配合索引 |
| $limit | 限制返回数量 | 分页查询、采样 | ✅ 减少数据量 |
| $skip | 跳过指定数量 | 分页查询 | ⚠️ 大skip值性能差 |
| $unwind | 展开数组 | 数组元素统计 | ⚠️ 可能大幅增加文档数 |
3. 聚合管道进阶:多表关联与复杂操作
3.1 $lookup:实现左连接查询
MongoDB 3.2版本引入了$lookup操作符,使得在聚合管道中实现类似SQL LEFT JOIN的操作成为可能。这解决了MongoDB长期以来不支持多表关联的痛点。
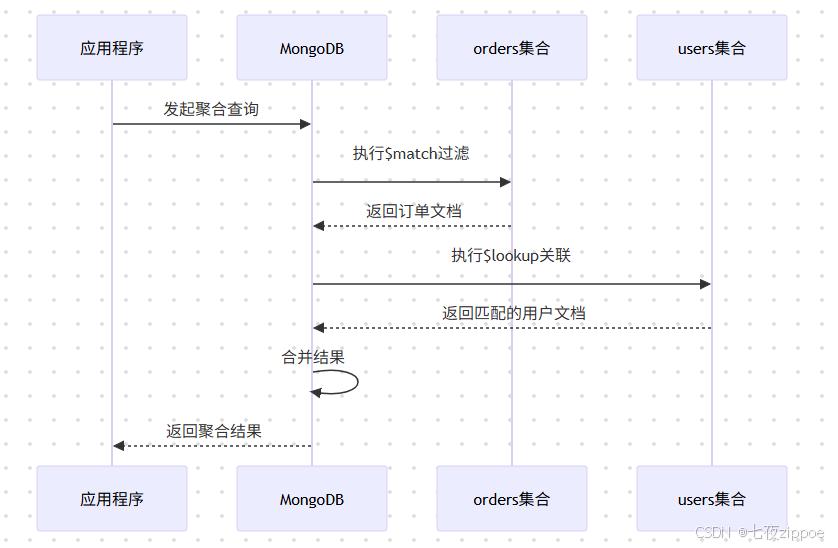
上图展示了 l o o k u p 操作的执行时序。当聚合管道执行到 lookup操作的执行时序。当聚合管道执行到 lookup操作的执行时序。当聚合管道执行到lookup阶段时,MongoDB会针对每个输入文档,去关联集合中查找匹配的文档,并将结果嵌入到输出文档中。
javascript
// 示例:订单与用户关联查询
db.orders.aggregate([
{
$match: {
status: "completed",
orderDate: { $gte: ISODate("2024-01-01") }
}
},
{
$lookup: {
from: "users",
localField: "userId",
foreignField: "_id",
as: "userInfo"
}
},
{
$lookup: {
from: "products",
localField: "items.productId",
foreignField: "_id",
as: "productDetails"
}
},
{
$addFields: {
user: { $arrayElemAt: ["$userInfo", 0] },
itemCount: { $size: "$items" }
}
},
{
$project: {
orderId: "$_id",
orderDate: 1,
totalAmount: 1,
userName: "$user.name",
userEmail: "$user.email",
itemCount: 1,
status: 1
}
}
])这段代码实现了订单与用户、产品的多表关联查询。首先过滤已完成的订单,然后通过 l o o k u p 分别关联 u s e r s 集合和 p r o d u c t s 集合,获取用户信息和商品详情。 lookup分别关联users集合和products集合,获取用户信息和商品详情。 lookup分别关联users集合和products集合,获取用户信息和商品详情。addFields阶段用于提取数组中的第一个元素(因为 l o o k u p 返回的是数组),最后通过 lookup返回的是数组),最后通过 lookup返回的是数组),最后通过project精简输出字段。需要注意的是,$lookup操作可能会带来性能问题,特别是在关联大表时,建议在关联字段上建立索引。
3.2 $unwind:数组展开与元素级处理
$unwind操作符用于将包含数组的文档拆分成多个文档,每个文档包含数组中的一个元素。这在处理嵌套数组数据时非常有用。
javascript
// 示例:展开订单商品进行统计
db.orders.aggregate([
{
$match: {
orderDate: {
$gte: ISODate("2024-01-01"),
$lt: ISODate("2024-04-01")
}
}
},
{
$unwind: {
path: "$items",
includeArrayIndex: "itemIndex",
preserveNullAndEmptyArrays: false
}
},
{
$group: {
_id: {
productId: "$items.productId",
month: { $month: "$orderDate" }
},
totalQuantity: { $sum: "$items.quantity" },
totalRevenue: {
$sum: {
$multiply: ["$items.quantity", "$items.price"]
}
},
orderCount: { $sum: 1 }
}
},
{
$sort: { totalRevenue: -1 }
},
{
$limit: 10
}
])上述代码展示了unwind的完整用法。我们首先过滤指定时间范围的订单,然后展开items数组,同时保留元素索引。展开后,每个订单商品变成了独立的文档,可以按商品ID和月份进行分组统计。unwind的includeArrayIndex选项可以记录元素在原数组中的位置,preserveNullAndEmptyArrays选项决定是否保留空数组文档。展开后的数据更适合进行细粒度的统计分析。
3.3 $facet:并行执行多个聚合管道
$facet操作符允许在同一个阶段中执行多个独立的聚合管道,非常适合需要同时生成多种统计结果的场景。
javascript
// 示例:多维度统计分析
db.orders.aggregate([
{
$match: {
status: "completed",
orderDate: { $gte: ISODate("2024-01-01") }
}
},
{
$facet: {
// 按类别统计
byCategory: [
{ $unwind: "$items" },
{ $group: { _id: "$items.category", count: { $sum: 1 } } },
{ $sort: { count: -1 } },
{ $limit: 5 }
],
// 按地区统计
byRegion: [
{ $group: { _id: "$shippingAddress.region", total: { $sum: "$totalAmount" } } },
{ $sort: { total: -1 } },
{ $limit: 10 }
],
// 按时间段统计
byMonth: [
{
$group: {
_id: { $month: "$orderDate" },
orderCount: { $sum: 1 },
avgAmount: { $avg: "$totalAmount" }
}
},
{ $sort: { _id: 1 } }
],
// 总体统计
overall: [
{
$group: {
_id: null,
totalOrders: { $sum: 1 },
totalRevenue: { $sum: "$totalAmount" },
avgOrderValue: { $avg: "$totalAmount" }
}
}
]
}
}
])这段代码使用facet一次性生成了四个维度的统计结果:按商品类别的销售排名、按地区的销售总额、按月份的订单趋势、以及整体销售概览。facet的优势在于所有子管道共享同一个输入数据集,避免了重复扫描,同时结果以一个文档的形式返回,便于前端直接使用。需要注意的是,facet会占用较多内存,建议配合$match提前过滤数据。
3.4 进阶操作符对比
| 操作符 | 功能描述 | 使用场景 | 注意事项 |
|---|---|---|---|
| $lookup | 左连接关联查询 | 多表关联、数据补全 | ⚠️ 关联字段需建索引 |
| $unwind | 数组展开 | 数组元素统计、细粒度分析 | ⚠️ 可能产生大量文档 |
| $facet | 并行多管道 | 多维度报表、仪表盘数据 | ⚠️ 内存占用高 |
| $addFields | 添加计算字段 | 字段派生、临时变量 | ✅ 轻量级操作 |
| $replaceRoot | 替换文档根节点 | 文档结构重塑 | ⚠️ 会丢失原有字段 |
| $merge | 输出到集合 | 聚合结果持久化 | ✅ MongoDB 4.2+ |
4. 索引优化策略:让查询飞起来
4.1 索引基础与设计原则
索引是数据库性能优化的基石。MongoDB支持多种类型的索引,每种索引都有其适用的场景。理解索引的工作原理,是写出高性能查询的前提。
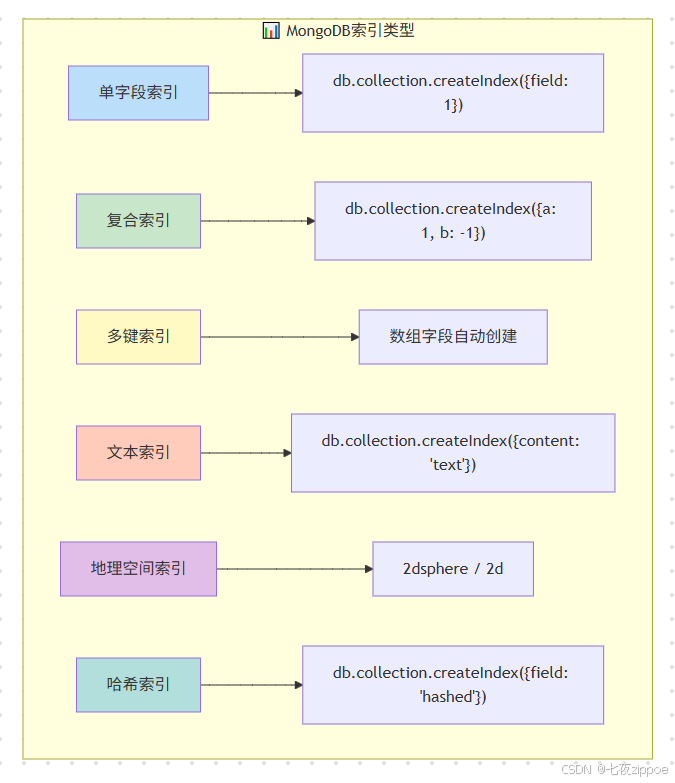
上图展示了MongoDB支持的主要索引类型。在实际应用中,最常用的是单字段索引和复合索引。索引设计需要遵循以下原则:
最左前缀原则:复合索引支持从左到右的前缀查询。例如,索引{a: 1, b: 1, c: 1}可以支持{a: 1}、{a: 1, b: 1}、{a: 1, b: 1, c: 1}的查询,但不支持{b: 1}或{c: 1}的查询。
ESR原则:在复合索引中,字段的顺序应遵循Equality(等值查询)→ Sort(排序)→ Range(范围查询)的优先级。等值查询的字段应放在最前面,排序字段次之,范围查询字段最后。
4.2 单字段索引与复合索引实战
javascript
// 示例:电商订单索引优化方案
// 1. 单字段索引 - 适用于单条件查询
db.orders.createIndex(
{ userId: 1 },
{
name: "idx_userId",
background: true,
partialFilterExpression: {
status: { $exists: true }
}
}
)
// 2. 复合索引 - 适用于多条件查询
db.orders.createIndex(
{
status: 1, // 等值查询优先
orderDate: -1, // 排序字段
totalAmount: 1 // 范围查询
},
{
name: "idx_status_date_amount",
background: true
}
)
// 3. 覆盖索引 - 查询字段全部在索引中
db.orders.createIndex(
{
userId: 1,
status: 1,
totalAmount: 1
},
{
name: "idx_user_cover",
background: true
}
)
// 使用覆盖索引的查询示例
db.orders.find(
{ userId: "user123", status: "completed" },
{ _id: 0, userId: 1, status: 1, totalAmount: 1 }
)上述代码展示了电商订单场景下的索引设计方案。第一个索引是单字段索引,用于按用户ID查询订单,同时使用partialFilterExpression部分索引表达式,只为有status字段的文档建立索引。第二个索引是复合索引,遵循ESR原则,支持按状态过滤、按日期排序、按金额范围查询的组合条件。第三个索引是覆盖索引,查询时所有需要的字段都在索引中,无需回表查询主文档,性能最优。
4.3 文本索引与搜索优化
对于文本搜索场景,MongoDB提供了专门的文本索引,支持全文检索、词干提取、停用词过滤等功能。
javascript
// 示例:商品搜索文本索引
db.products.createIndex(
{
name: "text",
description: "text",
tags: "text"
},
{
name: "idx_product_search",
weights: {
name: 10, // 名称权重最高
description: 5, // 描述次之
tags: 3 // 标签最低
},
default_language: "none", // 不使用语言分析器
textIndexVersion: 3
}
)
// 文本搜索查询
db.products.find(
{ $text: { $search: "智能手机 5G" } },
{ score: { $meta: "textScore" } }
).sort({ score: { $meta: "textScore" } })这段代码创建了一个多字段的文本索引,并设置了不同字段的权重。name字段的权重最高,意味着在搜索结果中,名称匹配的商品排名会更靠前。查询时使用 t e x t 操作符进行搜索, text操作符进行搜索, text操作符进行搜索,meta: "textScore"返回匹配分数,可以按相关性排序。需要注意的是,每个集合只能有一个文本索引,且文本索引会占用较多存储空间。
4.4 索引性能监控与优化
| 监控指标 | 说明 | 优化建议 |
|---|---|---|
| 索引命中率 | 查询使用索引的比例 | 低于90%需检查查询语句 |
| 索引大小 | 索引占用的存储空间 | 控制在内存容量内 |
| 索引扫描数 | 索引扫描的文档数 | 应接近返回文档数 |
| 索引构建时间 | 创建索引的耗时 | 使用background模式 |
| 重复索引 | 功能重叠的索引 | 删除冗余索引 |
5. 分片集群架构:海量数据的解决方案
5.1 分片集群概述
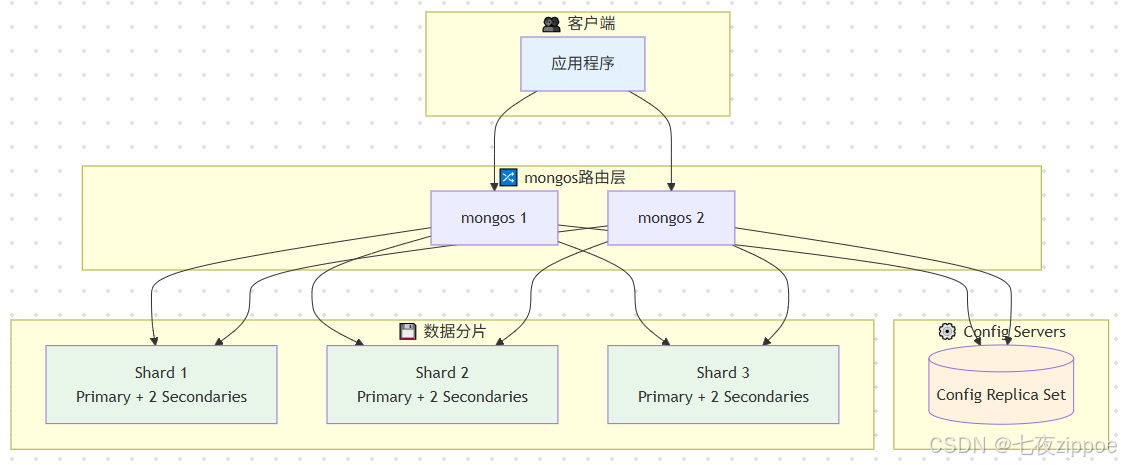
当单台服务器无法承载数据量或查询负载时,分片(Sharding)是MongoDB提供的水平扩展方案。分片集群将数据分散存储在多个服务器上,每个分片负责一部分数据,共同提供完整的数据库服务。
图片说明:
图1:MongoDB分片集群架构图(16:9比例)
该图展示了MongoDB分片集群的三层架构。最上层是mongos路由层,作为客户端的入口点,负责查询路由和结果聚合。中间层是配置服务器(Config Servers),存储集群元数据和分片映射信息,采用副本集模式保证高可用。最下层是分片层(Shard 1、Shard 2、Shard 3...),每个分片是一个独立的副本集,存储实际数据。图中用箭头标示了数据流向:客户端请求→mongos→配置服务器获取元数据→目标分片执行查询→返回结果。
5.2 分片键选择策略
分片键(Shard Key)是决定数据分布的核心字段。选择合适的分片键,是分片集群设计中最关键的决策。
分片键选择原则:
-
高基数(High Cardinality):分片键应该有足够多的不同值,避免数据倾斜。例如,用户ID比性别更适合做分片键。
-
低频率(Low Frequency):每个分片键值的文档数量应该相对均匀。如果某个值出现频率过高,会导致"热点分片"。
-
查询亲和性(Query Isolation):分片键应该能覆盖大部分查询条件,使查询能够定向到特定分片,避免全分片扫描。
javascript
// 示例:分片键选择与集合分片
// 方案一:范围分片(Range Sharding)
sh.shardCollection("ecommerce.orders", { userId: 1, orderDate: 1 })
// 方案二:哈希分片(Hashed Sharding)
sh.shardCollection("ecommerce.orders", { userId: "hashed" })
// 方案三:标签感知分片(Tag-Aware Sharding)
sh.addShardTag("shard01", "region:east")
sh.addShardTag("shard02", "region:west")
sh.addTagRange("ecommerce.users", { region: "east" }, { region: "east" }, "region:east")
sh.addTagRange("ecommerce.users", { region: "west" }, { region: "west" }, "region:west")上述代码展示了三种分片策略。范围分片按照分片键值范围划分数据,支持范围查询但可能导致数据分布不均。哈希分片通过哈希函数均匀分布数据,但范围查询效率较低。标签感知分片允许将特定范围的数据固定到特定分片,适用于数据本地化需求(如按地区分布数据)。
5.3 均衡器与数据迁移
均衡器(Balancer)是MongoDB分片集群的自动负载均衡组件。当发现分片间数据量差异超过阈值时,均衡器会自动触发数据迁移,将块(Chunk)从负载高的分片迁移到负载低的分片。
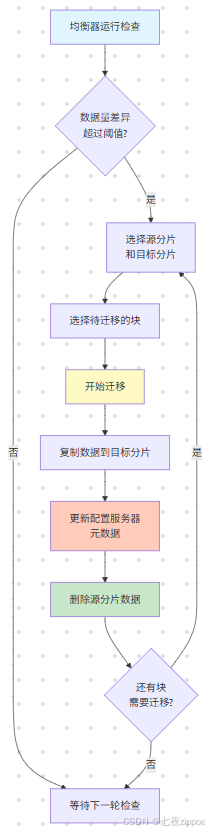
上图展示了均衡器的工作流程。均衡器默认每15秒检查一次集群状态,当最大分片与最小分片的块数差异超过迁移阈值时,触发数据迁移。迁移过程包括数据复制、元数据更新、源数据删除三个阶段,整个过程对应用透明,不会影响正常读写。
javascript
// 示例:均衡器管理操作
// 查看均衡器状态
sh.getBalancerState()
// 临时停止均衡器(维护窗口)
sh.stopBalancer()
// 设置均衡窗口(只在特定时间段运行)
db.settings.update(
{ _id: "balancer" },
{
$set: {
activeWindow: {
start: "02:00",
stop: "06:00"
}
}
},
{ upsert: true }
)
// 查看当前迁移状态
sh.isBalancerRunning()
// 手动迁移块
sh.moveChunk("ecommerce.orders", { userId: "user1000" }, "shard02")5.4 配置服务器高可用
配置服务器存储分片集群的全部元数据,包括分片列表、数据库分片配置、块范围映射等关键信息。配置服务器必须部署为副本集模式,以保证高可用。
图片说明:
图2:配置服务器副本集架构图(16:9比例)
该图详细展示了配置服务器副本集的内部结构。三个Config Server节点组成一个三节点副本集:一个Primary节点负责写入操作,两个Secondary节点同步数据。图中标注了数据同步方向:Primary→Secondary(通过oplog复制)。右侧展示了配置服务器存储的关键数据:数据库分片配置、集合分片信息、块范围映射、分片服务器列表等。底部标注了mongos如何从配置服务器读取路由信息。
| 配置服务器特性 | 说明 |
|---|---|
| 部署模式 | 必须为副本集(MongoDB 3.4+) |
| 节点数量 | 推荐3节点(1 Primary + 2 Secondary) |
| 数据内容 | 集群元数据、分片配置、块映射 |
| 读写模式 | mongos读取,均衡器写入 |
| 故障恢复 | 自动选举新Primary |
| 备份策略 | 定期快照 + oplog备份 |
6. 分片集群性能优化:深入细节
6.1 查询路由优化
在分片集群中,查询性能很大程度上取决于查询路由的效率。理想情况下,查询应该只涉及目标分片,避免全分片扫描。
javascript
// 示例:优化分片集群查询
// ❌ 不好的做法:全分片扫描
db.orders.find({
totalAmount: { $gt: 1000 }
})
// ✅ 好的做法:定向查询(包含分片键)
db.orders.find({
userId: "user123", // 分片键第一字段
totalAmount: { $gt: 1000 }
})
// ✅ 更好的做法:精确匹配分片键
db.orders.find({
userId: "user123", // 分片键第一字段
orderDate: ISODate("2024-03-15") // 分片键第二字段
})
// 使用explain分析查询路由
db.orders.explain("executionStats").find({
userId: "user123",
status: "completed"
})上述代码展示了分片集群查询优化的思路。第一个查询没有包含分片键,会导致全分片扫描,性能最差。第二个查询包含分片键的第一字段,可以定位到特定分片。第三个查询精确匹配分片键,性能最优。使用explain可以查看查询的执行计划,确认是否命中目标分片。
6.2 写入性能优化
分片集群的写入性能受分片键设计影响很大。如果分片键是单调递增的(如ObjectId、时间戳),所有写入都会集中在一个分片上,形成写入热点。
javascript
// 示例:避免写入热点的策略
// ❌ 不好的做法:单调递增分片键
sh.shardCollection("app.logs", { _id: 1 })
// 问题:所有新日志都写入最后一个分片
// ✅ 好的做法:哈希分片键
sh.shardCollection("app.logs", { _id: "hashed" })
// 优点:写入均匀分布到所有分片
// ✅ 更好的做法:复合分片键
sh.shardCollection("app.logs", {
appId: 1, // 应用ID,分散写入
timestamp: 1 // 时间戳,支持范围查询
})
// 优点:既分散写入,又支持时间范围查询
// 批量写入优化
db.logs.insertMany(
logsArray,
{
ordered: false, // 无序插入,失败不中断
writeConcern: { w: 1 } // 降低写入确认级别
}
)6.3 分片集群监控指标
| 监控维度 | 关键指标 | 告警阈值 |
|---|---|---|
| 数据分布 | 各分片数据量差异 | >20%触发告警 |
| 查询性能 | 平均查询延迟 | >100ms需关注 |
| 写入性能 | 写入OPS、延迟 | 延迟>50ms需优化 |
| 均衡器 | 迁移任务数、耗时 | 长时间迁移需关注 |
| 配置服务器 | 复制延迟 | >10s需处理 |
| 网络 | 分片间网络流量 | 接近带宽上限需扩容 |
7. 实战案例:电商订单分析系统
7.1 业务背景与需求
某电商平台日均订单量达到百万级别,需要构建一个实时订单分析系统,支持以下业务需求:
- 实时销售看板:展示当日销售额、订单量、客单价等核心指标
- 商品销售排行:按类别、品牌统计热销商品
- 用户行为分析:分析用户购买频次、复购率、客单价分布
- 地区销售分布:按省市统计销售数据,支持地图可视化
7.2 数据模型设计
javascript
// 订单文档结构
{
"_id": ObjectId("..."),
"orderId": "ORD20240315001",
"userId": "user_12345",
"orderDate": ISODate("2024-03-15T10:30:00Z"),
"status": "completed",
"items": [
{
"productId": "prod_001",
"productName": "iPhone 15 Pro",
"category": "手机",
"brand": "Apple",
"quantity": 1,
"price": 8999,
"amount": 8999
},
{
"productId": "prod_002",
"productName": "AirPods Pro",
"category": "耳机",
"brand": "Apple",
"quantity": 1,
"price": 1899,
"amount": 1899
}
],
"totalAmount": 10898,
"paymentMethod": "alipay",
"shippingAddress": {
"province": "浙江省",
"city": "杭州市",
"district": "西湖区",
"detail": "xxx街道xxx号"
},
"createdAt": ISODate("2024-03-15T10:30:00Z"),
"updatedAt": ISODate("2024-03-15T10:35:00Z")
}7.3 分片集群架构设计
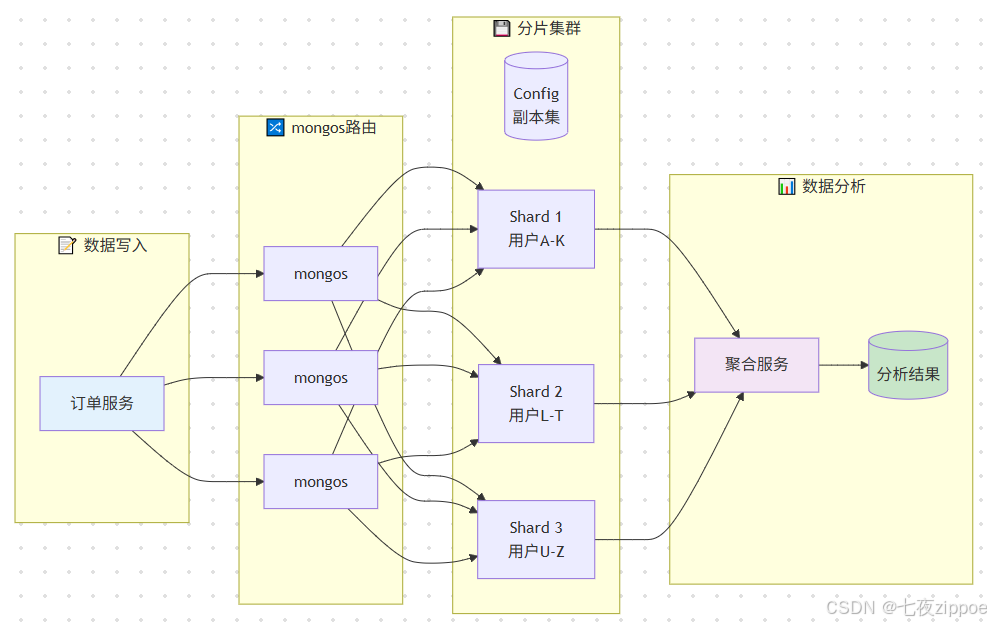
图片说明:
图3:电商订单分析系统分片架构图(16:9比例)
该图展示了电商订单分析系统的完整分片架构。左侧是数据写入层,订单服务通过多个mongos实例写入数据。中间是分片集群核心:3个分片(Shard 1/2/3),每个分片是3节点副本集;配置服务器为3节点副本集。右侧是数据分析层:聚合服务通过mongos读取数据,结果写入分析结果集合。底部标注了分片策略:按userId哈希分片,保证写入均匀分布。图中还标注了索引设计:userId+orderDate复合索引支持用户订单查询,status+orderDate复合索引支持状态过滤。
7.4 核心聚合查询实现
javascript
// 示例:实时销售看板数据聚合
db.orders.aggregate([
// 阶段1:过滤当日已完成订单
{
$match: {
status: "completed",
orderDate: {
$gte: ISODate("2024-03-15T00:00:00Z"),
$lt: ISODate("2024-03-16T00:00:00Z")
}
}
},
// 阶段2:并行计算多维度指标
{
$facet: {
// 总体销售指标
overview: [
{
$group: {
_id: null,
totalOrders: { $sum: 1 },
totalRevenue: { $sum: "$totalAmount" },
avgOrderValue: { $avg: "$totalAmount" },
uniqueUsers: { $addToSet: "$userId" }
}
},
{
$project: {
totalOrders: 1,
totalRevenue: 1,
avgOrderValue: { $round: ["$avgOrderValue", 2] },
uniqueUserCount: { $size: "$uniqueUsers" }
}
}
],
// 按小时统计趋势
hourlyTrend: [
{
$group: {
_id: { $hour: "$orderDate" },
orderCount: { $sum: 1 },
revenue: { $sum: "$totalAmount" }
}
},
{ $sort: { _id: 1 } }
],
// 支付方式分布
paymentDistribution: [
{
$group: {
_id: "$paymentMethod",
count: { $sum: 1 },
amount: { $sum: "$totalAmount" }
}
},
{ $sort: { amount: -1 } }
],
// 地区销售TOP10
topRegions: [
{
$group: {
_id: "$shippingAddress.province",
orderCount: { $sum: 1 },
totalRevenue: { $sum: "$totalAmount" }
}
},
{ $sort: { totalRevenue: -1 } },
{ $limit: 10 }
]
}
}
], {
allowDiskUse: true, // 允许使用磁盘
maxTimeMS: 30000 // 设置超时时间
})上述聚合查询实现了实时销售看板的核心数据计算。使用 f a c e t 并行计算四个维度的指标:总体销售概览、按小时的趋势、支付方式分布、地区销售排名。整个查询在分片集群上执行时, facet并行计算四个维度的指标:总体销售概览、按小时的趋势、支付方式分布、地区销售排名。整个查询在分片集群上执行时, facet并行计算四个维度的指标:总体销售概览、按小时的趋势、支付方式分布、地区销售排名。整个查询在分片集群上执行时,match阶段会在每个分片上并行执行,只有聚合结果会发送到mongos进行合并。allowDiskUse选项允许聚合过程中使用磁盘,避免内存溢出。
7.5 性能优化实践
| 优化措施 | 实施方案 | 效果 |
|---|---|---|
| 索引优化 | 创建status+orderDate复合索引 | 查询延迟降低60% |
| 分片键调整 | 采用userId哈希分片 | 写入吞吐提升3倍 |
| 预聚合 | 定时任务预计算常用指标 | 看板加载时间<1s |
| 读写分离 | 分析查询走Secondary节点 | 降低Primary压力 |
| 结果缓存 | Redis缓存热点查询结果 | 缓存命中率85% |
8. 常见问题与解决方案
8.1 聚合管道内存溢出
问题现象:执行大型聚合查询时报错"Exceeded memory limit"。
解决方案:
javascript
// 方案1:启用allowDiskUse
db.collection.aggregate([...], { allowDiskUse: true })
// 方案2:分批次处理
db.collection.aggregate([
{ $match: { date: { $gte: startDate, $lt: endDate } } },
...
])
// 方案3:使用$out分阶段处理
db.collection.aggregate([
{ $match: {...} },
{ $group: {...} },
{ $out: "temp_results" }
])8.2 分片数据倾斜
问题现象:某个分片数据量远大于其他分片,查询性能下降。
解决方案:
- 检查分片键基数,考虑更换分片键
- 使用标签感知分片,手动控制数据分布
- 调整块大小(默认64MB),使数据分布更均匀
8.3 分片键无法更改
问题现象:业务发展后发现分片键选择不当,但MongoDB不支持直接更改分片键。
解决方案:
javascript
// 迁移数据到新集合
db.oldCollection.aggregate([
{ $out: "newCollection" }
])
// 重新分片
sh.shardCollection("db.newCollection", { newShardKey: 1 })
// 更新应用配置,切换到新集合9. 总结
MongoDB聚合框架与分片集群是处理大规模数据的两大利器。聚合框架提供了声明式的数据处理能力,通过管道组合实现复杂的业务逻辑;分片集群则解决了单机存储和性能瓶颈问题,支持水平扩展。
核心要点回顾:
-
聚合管道设计 :遵循"过滤优先"原则, m a t c h 尽量前置;合理使用 match尽量前置;合理使用 match尽量前置;合理使用facet并行计算;注意内存限制,必要时启用allowDiskUse。
-
索引优化策略:遵循ESR原则设计复合索引;善用覆盖索引减少回表;文本索引支持全文搜索场景。
-
分片集群架构:分片键选择是核心决策,需综合考虑基数、频率、查询亲和性;均衡器自动维护数据平衡;配置服务器高可用是集群稳定的基础。
-
性能优化实践:查询包含分片键避免全分片扫描;避免单调递增分片键导致写入热点;预聚合和缓存减轻实时计算压力。
思考题:
-
在你的业务场景中,如何评估是否需要使用分片集群?单机性能优化的极限在哪里?
-
如果业务查询模式发生变化,原有的分片键不再适合,你会如何设计迁移方案?
-
聚合框架与MapReduce相比,各有什么优劣势?在什么场景下应该选择MapReduce?