目录
[❌ 问题 1:无法表示"关注程度"](#❌ 问题 1:无法表示“关注程度”)
[❌ 问题 2:不能归一化,梯度可能爆炸或不稳定](#❌ 问题 2:不能归一化,梯度可能爆炸或不稳定)
[1、 拿到输入的基本维度](#1、 拿到输入的基本维度)
[5、生成下三角mask让模型 不能看到未来的 token。](#5、生成下三角mask让模型 不能看到未来的 token。)
[6. softmax 得到注意力权重,并乘上 v](#6. softmax 得到注意力权重,并乘上 v)
[7. 把多头结果拼回去](#7. 把多头结果拼回去)
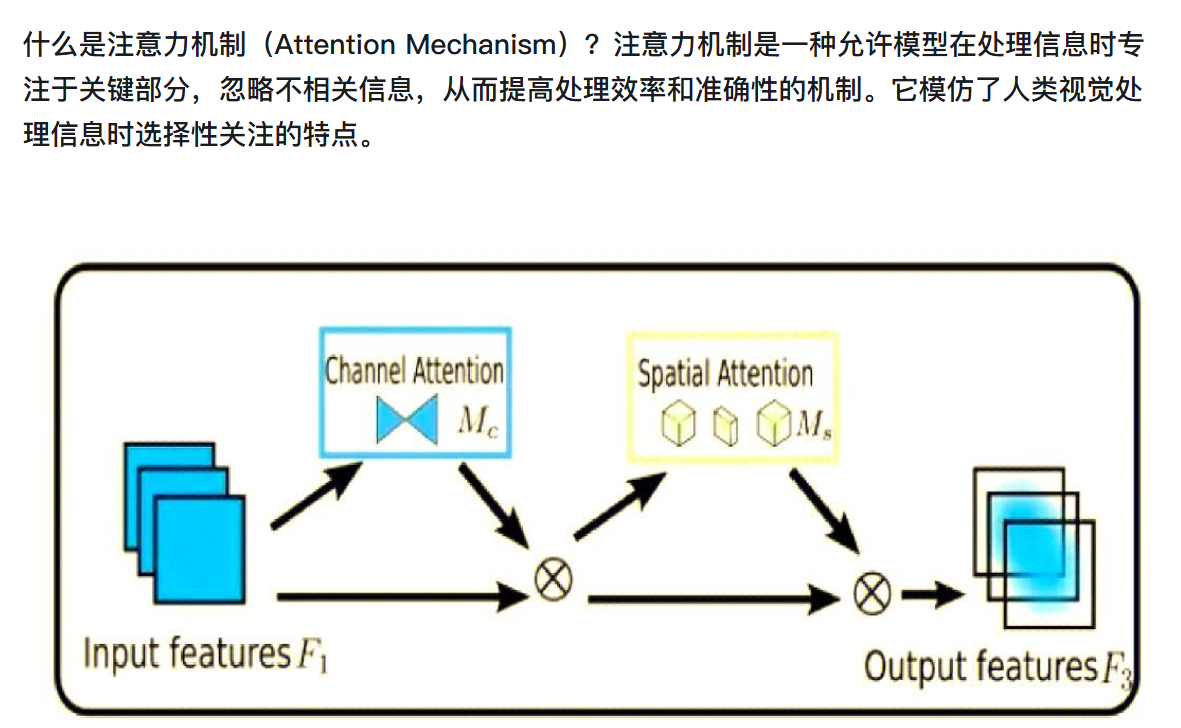
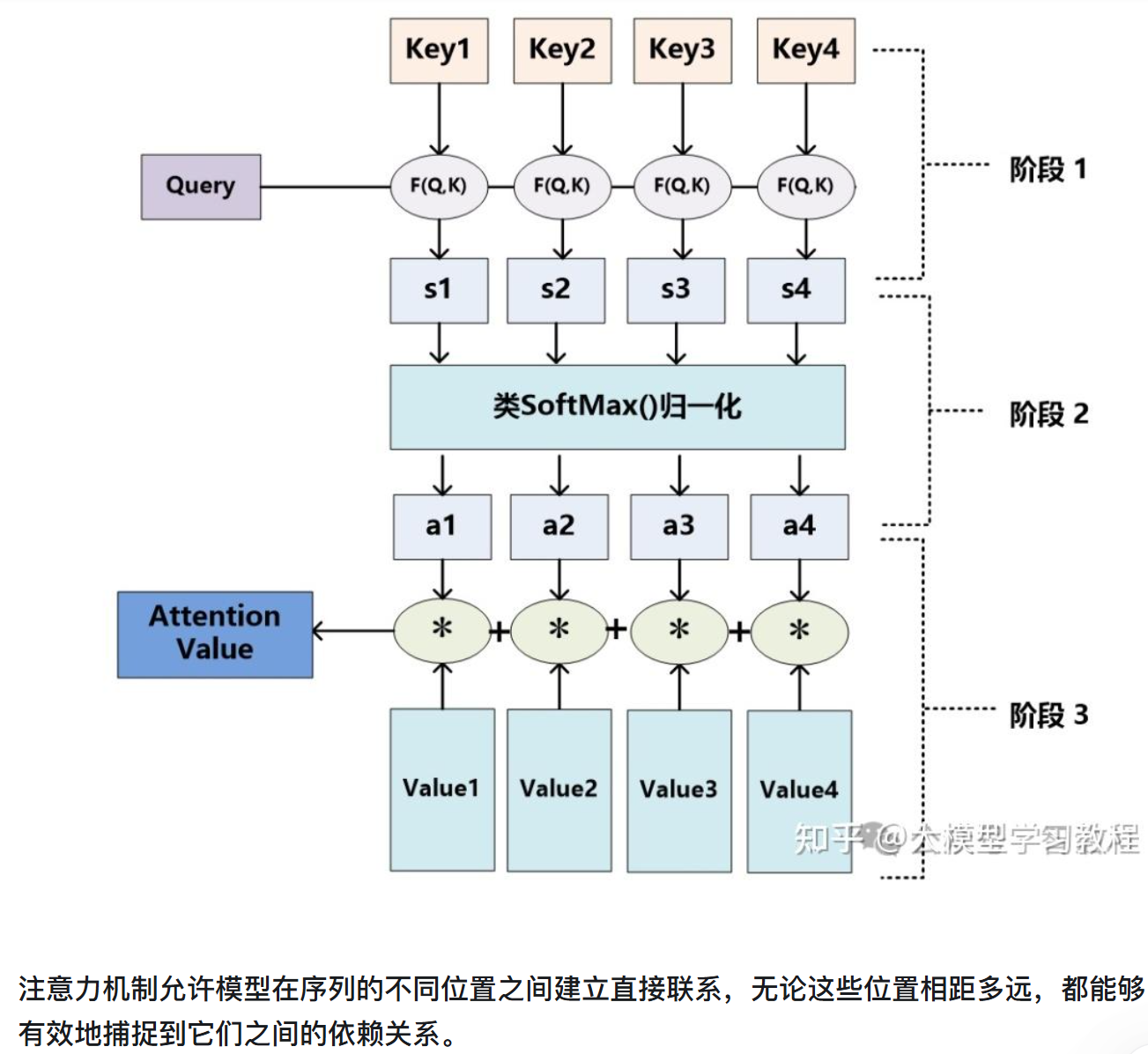
注意力机制允许模型在序列的不同位置之间建立直接联系,无论这些位置相距多远,都能够有效地捕捉到它们之间的依赖关系。
注意力分数是什么?注意力分数用来量化注意力机制中某一部分信息被关注的程度,反映了信息在注意力机制中的重要性。在注意力机制中,模型会根据注意力分数来决定对不同输入信息的关注程度。
注意力机制要做的事情是:
让模型决定:输入序列中每个 token 应该关注哪些其他 token,并关注多少。
1、定义数据、参数、导包
导包之后,生成测试数据的batch、时序、一个词多少维度:

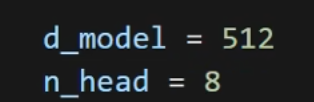
定义两个参数:1、把QKV映射到多少维度,2、有几个头。
2、多头注意力初始化
-
多头注意力(Multi-Head Attention):将查询(Query)、键(Key)、值(Value)投影到不同子空间,并行计算多个注意力头后拼接结果,增强模型捕捉多样依赖关系的能力。
class multi_head_attention(nn.Module):
def init(self,d_model,n_head) ->None:
super(multi_head_attention).init()
self.n_head=n_head
self.d_model=d_model
self.w_q=nn.Linear(d_model,d_model) #线性层输入输出
self.w_k=nn.Linear(d_model,d_model)
self.w_v=nn.Linear(d_model,d_model)
self.w_combine=nn.Linear(d_model,d_model)
self.softmax=nn.Softmax(dim=-1)
nn.Linear()全连接层:

对输入的每个向量(维度 = d_model),用三套不一样的 nn.Linear,把它分别变成 Q / K / V。我们把输入叫做"句子中每个词的表示,对每个词,我们建立了三个变换:
| 变换层 | 作用 |
|---|---|
| w_q | 把输入变成 Query: 用于问"我应该关注谁?" |
| w_k | 把输入变成 Key: 用于告诉别人"我是谁,我有什么特征" |
| w_v | 把输入变成 Value: 被注意力加权后的值 |
Q = w_q(x);K = w_k(x);V = w_v(x);就是把同一个输入做了三次不同的线性变换。
Softmax归一化的原因:
注意力分数来自: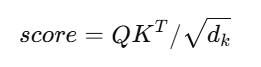
但是这个 score 本身没有范围限制,可能是任意大、任意小、负数、正数......
如果直接用这些数加权V:attention_output = score * V
❌ 问题 1:无法表示"关注程度"
没有 softmax 时,score 可能长这样:tensor([[ 12.3, -2.1, 8.7, 0.6]])
这根本不能看出:
-
哪个是"重点"
-
哪个是不重要
-
总量也不固定
❌ 问题 2:不能归一化,梯度可能爆炸或不稳定
如果 score 很大,比如 100、200、500,
加权后 V 会被放大 100 倍、500 倍,训练会极不稳定。
而Softmax 会把每一行注意力分数变成一个 **0~1 的概率分布,**注意力机制就能明确:
我应该把主要注意力放在哪个位置。
combine是因为这里涉及到多头的信息结合。
3、前向传播
def forward(self,q,k,v):
#得到qkv的维度
batch,time,dimension = q.shape
#每一个token的qkv的维度n_d
n_d = self.d_model//self.n_head
#qkv放到上面定义的映射里面,得到在QKV空间的一个表示
q,k,v=self.w_q(q),self.w_k(k),self.w_v(v)
#permute维度转换,方便多头计算
q=q.view(batch,time,self.n_head,n_d).permute(0,2,1,3)
k=q.view(batch,time,self.n_head,n_d).permute(0,2,1,3)
v=v.view(batch,time,self.n_head,n_d).permute(0,2,1,3)
score=q@k.transpose(2,3)/math.sqrt(n_d)
mask=torch.tril(torch.ones(time,time,dtype=bool))
score=score.masked_fill(mask==0,float("-inf"))
score=self.softmax(score)@v
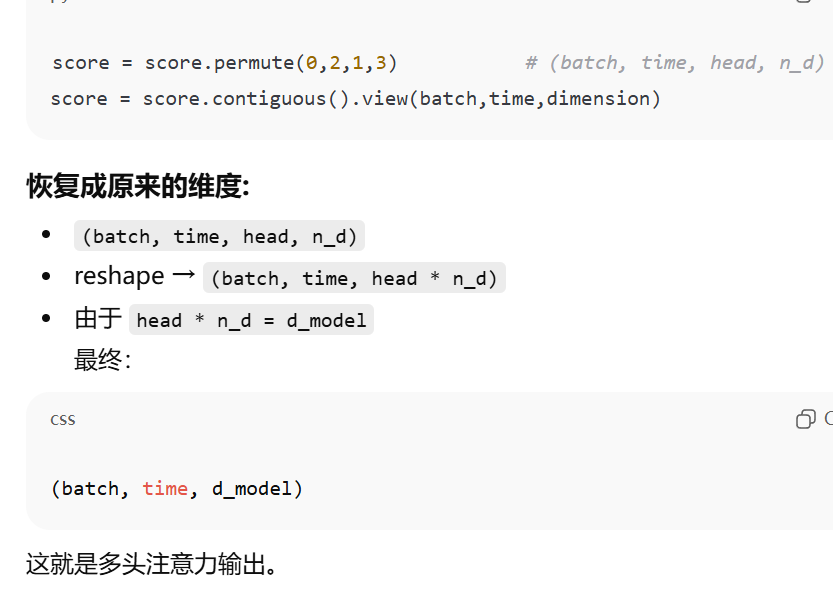
score=score.permute(0,2,1,3).contiguous().view(batch,time,dimension)1、拿到输入的基本维度
多头注意力 = 把 d_model 切成 n_head 份,每个头自己算一小份,分到n_d维。这里d_model=512, n_head=8 → n_d = 64
2、输入分别线性映射到Q\K\V空间
三个线性层:
-
w_q:负责让 q 进入 Query 空间 -
w_k:负责让 k 进入 Key 空间 -
w_v:负责让 v 进入 Value 空间
3、切头+维度转换
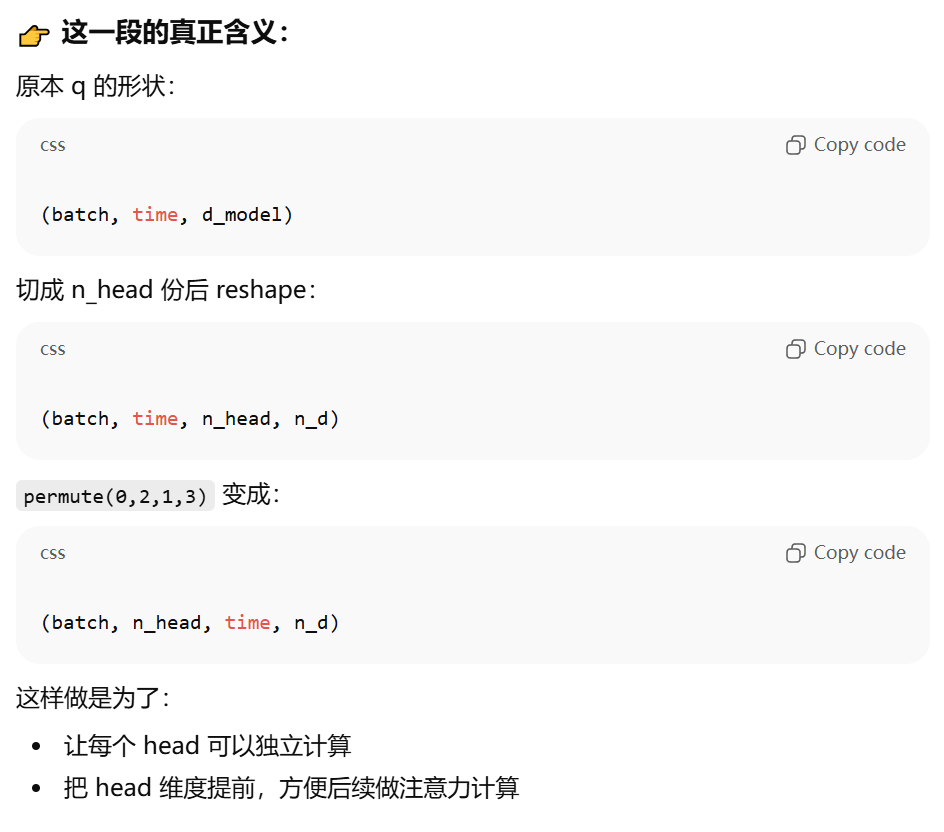
4、注意力得分Q*K转置
k.transpose(2,3) 就是交换张量的第 2 和第 3 个维度。
-
q:
(batch, head, time, n_d) -
k:
(batch, head, time, n_d)→k.transpose(2,3)→(batch, head, n_d, time)
点积 @ 衡量两个向量相似度。(每组对应元素乘,再求所有积的和)

5、生成下三角mask让模型 不能看到未来的 token。
mask = torch.tril(torch.ones(time,time,dtype=bool))
score = score.masked_fill(mask==0, float("-inf"))
float("-inf"):表示负无穷。
6. softmax 得到注意力权重,并乘上 v
每个 head 对所有 token 的信息做加权平均。

7. 把多头结果拼回去
------小狗照亮每一天
20251201