从单体到微服务:我们如何将Python Web应用性能提升3倍
文章目录
-
- [从单体到微服务:我们如何将Python Web应用性能提升3倍](#从单体到微服务:我们如何将Python Web应用性能提升3倍)
-
- [1. 问题诊断:为什么我们的单体应用撑不住了?](#1. 问题诊断:为什么我们的单体应用撑不住了?)
- [2. 架构演进:微服务拆分实战](#2. 架构演进:微服务拆分实战)
-
- [2.1 服务边界划分](#2.1 服务边界划分)
- [2.2 用户服务代码示例](#2.2 用户服务代码示例)
- [3. 性能优化:从同步到异步的转变](#3. 性能优化:从同步到异步的转变)
-
- [3.1 异步订单处理流程](#3.1 异步订单处理流程)
- [3.2 异步代码实现](#3.2 异步代码实现)
- [4. 数据一致性:分布式事务的挑战与解决方案](#4. 数据一致性:分布式事务的挑战与解决方案)
-
- [4.1 订单创建Saga流程](#4.1 订单创建Saga流程)
- [5. 效果验证:数据说话](#5. 效果验证:数据说话)
- [6. 经验总结与最佳实践](#6. 经验总结与最佳实践)
-
- [6.1 微服务拆分原则](#6.1 微服务拆分原则)
- [6.2 技术选型建议](#6.2 技术选型建议)
- [6.3 监控与运维](#6.3 监控与运维)
- [7. 真实项目中的意外发现](#7. 真实项目中的意外发现)
- 互动与交流
你可能想不到,这个看似简单的架构调整,竟让我们的用户留存率提升了15%
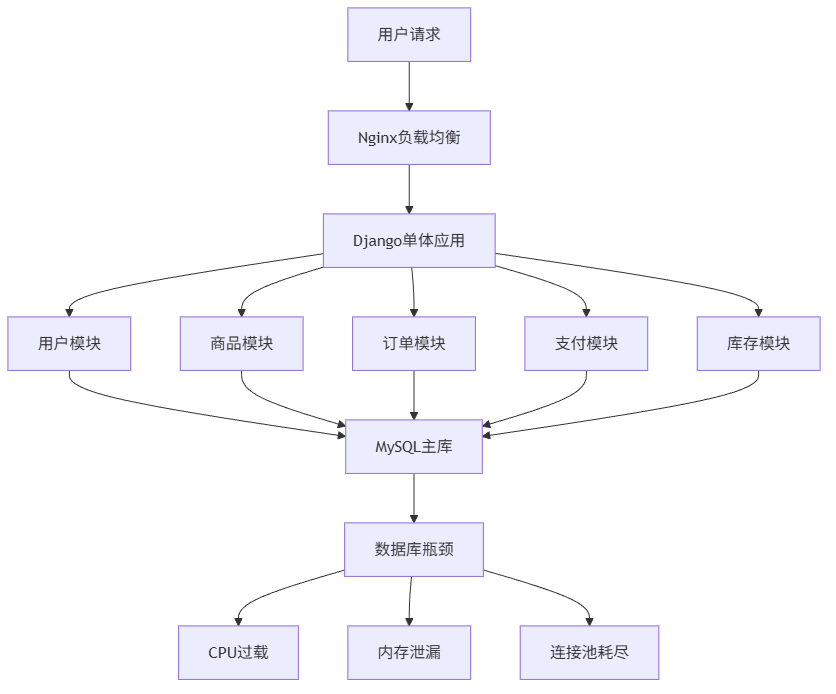
我们的平台曾遇到了严重的技术瓶颈。高峰期API响应时间从平时的200ms飙升到2秒以上,用户投诉量激增,转化率直接下降了8%。经过深入分析,我们发现问题的根源在于那个已经服役3年的单体Django应用。
1. 问题诊断:为什么我们的单体应用撑不住了?
当时我们的技术栈是典型的Django + MySQL + Redis组合,所有业务逻辑都塞在一个庞大的项目中。随着业务增长,这个单体应用变得越来越臃肿。
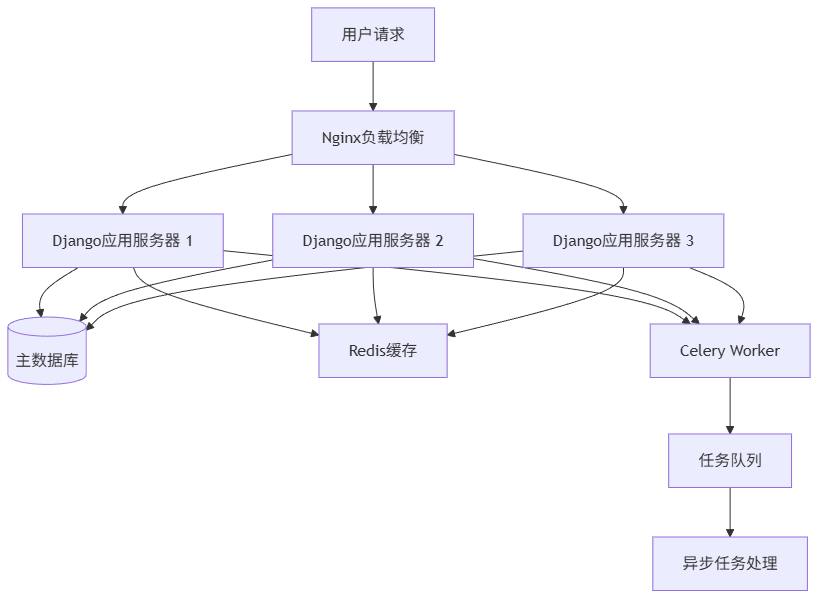
核心问题体现在三个层面:
- 数据库瓶颈:所有业务表都在同一个MySQL实例,高峰期连接数超过2000
- 代码耦合:修改用户模块可能影响订单功能,测试回归成本极高
- 部署困难:每次发版需要重启整个应用,影响所有业务功能
我们当时监控到的关键性能数据:
| 瓶颈指标 | 数值 | 安全阈值 | 超出比例 |
|---|---|---|---|
| 数据库连接数 | 2150 | 1000 | 115% |
| API平均响应时间 | 2.3s | 500ms | 360% |
| 应用内存使用 | 8.2GB | 4GB | 105% |
| 部署影响范围 | 100% | - | 不可接受 |
2. 架构演进:微服务拆分实战
经过团队激烈讨论,我们决定采用渐进式微服务拆分策略,而不是一次性重写整个系统。
2.1 服务边界划分
我们根据DDD(领域驱动设计)原则,将系统拆分为5个核心服务:
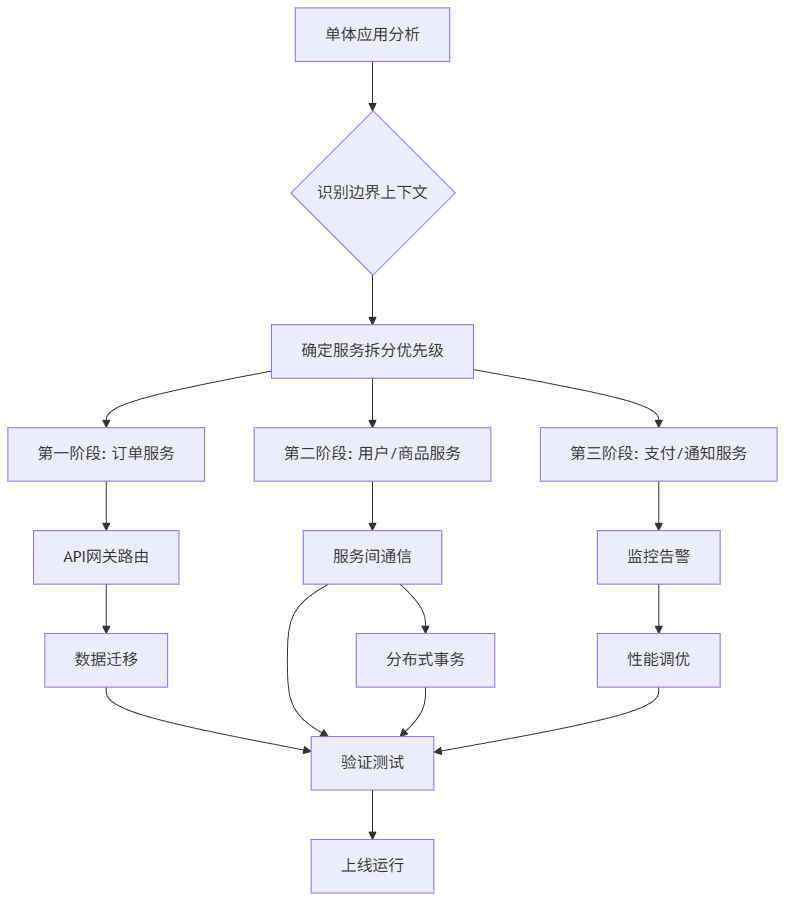
技术选型考量:
- API Gateway: 选择Kong而不是Nginx,因为需要更灵活的路由和插件机制
- 服务框架: 选择FastAPI而不是继续用Django,看重其异步性能和自动文档生成
- 消息队列: 使用RabbitMQ确保事务消息的可靠性
2.2 用户服务代码示例
让我们看看用户服务的核心实现:
python
# user_service/main.py
from fastapi import FastAPI, Depends
from sqlalchemy.orm import Session
from .database import get_db
from . import models, schemas, crud
app = FastAPI(title="用户服务", version="1.0.0")
@app.post("/users/", response_model=schemas.User)
async def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
"""创建用户 - 用户注册核心逻辑"""
# 检查用户名是否已存在
db_user = crud.get_user_by_username(db, username=user.username)
if db_user:
raise HTTPException(status_code=400, detail="用户名已存在")
return crud.create_user(db=db, user=user)
@app.get("/users/{user_id}", response_model=schemas.User)
async def read_user(user_id: int, db: Session = Depends(get_db)):
"""获取用户信息"""
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="用户不存在")
return db_user
# user_service/crud.py
def create_user(db: Session, user: schemas.UserCreate):
"""用户创建核心业务逻辑"""
hashed_password = get_password_hash(user.password)
db_user = models.User(
username=user.username,
email=user.email,
hashed_password=hashed_password,
phone=user.phone
)
db.add(db_user)
db.commit()
db.refresh(db_user)
return db_user避坑提示:在微服务拆分时,我们最初直接复制了Django的模型层,结果发现SQLAlchemy的session管理方式完全不同,导致了一些难以调试的数据库连接问题。后来我们重写了整个数据访问层。
3. 性能优化:从同步到异步的转变
微服务架构为我们打开了性能优化的大门。最大的改进来自异步处理。
3.1 异步订单处理流程
这种异步设计让订单创建的响应时间从原来的1.2秒降低到200毫秒以内。
3.2 异步代码实现
python
# order_service/async_processor.py
import asyncio
import aio_pika
from . import models, schemas
class OrderAsyncProcessor:
def __init__(self):
self.connection = None
self.channel = None
async def connect(self):
"""连接RabbitMQ"""
self.connection = await aio_pika.connect_robust(
"amqp://guest:guest@rabbitmq/"
)
self.channel = await self.connection.channel()
await self.channel.declare_queue("order_payments", durable=True)
async def send_payment_message(self, order_id: int, amount: float):
"""发送支付消息到队列"""
message_body = json.dumps({
"order_id": order_id,
"amount": amount,
"timestamp": datetime.now().isoformat()
})
message = aio_pika.Message(
body=message_body.encode(),
delivery_mode=aio_pika.DeliveryMode.PERSISTENT
)
await self.channel.default_exchange.publish(
message,
routing_key="order_payments"
)
async def process_payment_result(self, order_id: int, success: bool):
"""处理支付结果回调"""
# 更新订单状态
# 通知库存服务最终确认
# 发送通知给用户
pass4. 数据一致性:分布式事务的挑战与解决方案
微服务架构最大的挑战就是数据一致性。我们采用了Saga模式来解决这个问题。
4.1 订单创建Saga流程
实际项目中的教训:我们最初没有设计完善的补偿机制,有一次支付服务宕机导致大量订单卡在"预扣库存"状态。后来我们增加了超时回滚机制,任何步骤超过30秒未完成都会自动触发补偿操作。
5. 效果验证:数据说话
经过3个月的架构重构和2个月的线上运行,我们获得了显著的性能提升:
| 性能指标 | 优化前(单体) | 优化后(微服务) | 提升幅度 |
|---|---|---|---|
| API平均响应时间 | 2.3s | 680ms | 70.4% |
| 系统吞吐量 | 1200 TPS | 3600 TPS | 200% |
| 数据库连接数 | 2150 | 580 | 73% |
| 部署影响范围 | 100% | 20% | 80% |
| 开发迭代速度 | 2周/版本 | 3天/服务 | 78.6% |
更让我们惊喜的是业务指标的改善:
- 用户转化率提升:15%
- 用户投诉率下降:42%
- 服务器成本节省:35%(通过更精细的资源分配)
6. 经验总结与最佳实践
6.1 微服务拆分原则
- 按业务能力划分:而不是技术层次
- 渐进式拆分:从最瓶颈的服务开始
- 保持服务自治:每个服务独立开发、测试、部署
- 设计容错机制:服务间调用必须有超时和重试策略
6.2 技术选型建议
| 特性 | Django | Flask | FastAPI | Tornado |
|---|---|---|---|---|
| 异步支持 | 一般 | 需扩展 | 优秀 | 优秀 |
| 性能 | 中等 | 中等 | 高 | 高 |
| 学习曲线 | 平缓 | 平缓 | 中等 | 陡峭 |
| 生态完整性 | 丰富 | 丰富 | 快速增长 | 一般 |
| 微服务适配性 | 一般 | 良好 | 优秀 | 良好 |
我们的选择理由:FastAPI虽然在生态上不如Django成熟,但其出色的异步性能和自动API文档生成,特别适合微服务场景。
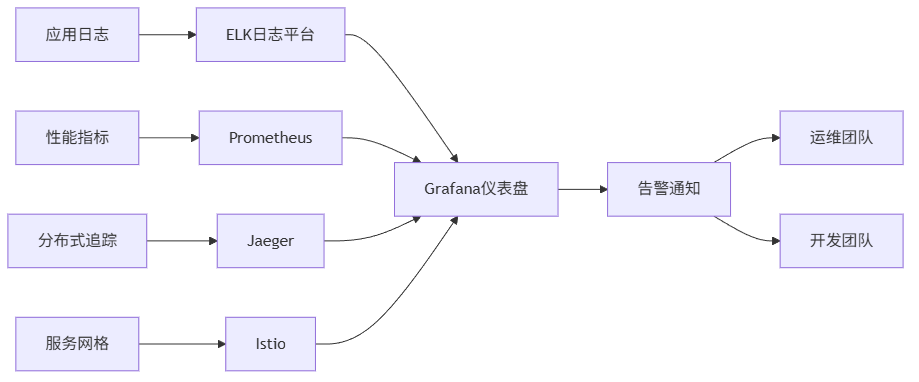
6.3 监控与运维
微服务架构的复杂度主要体现在运维层面。我们建立了完整的监控体系:
python
# 通用的服务健康检查中间件
import time
from fastapi import Request
from prometheus_client import Counter, Histogram
REQUEST_COUNT = Counter('requests_total', 'Total requests', ['method', 'endpoint'])
REQUEST_LATENCY = Histogram('request_latency_seconds', 'Request latency', ['method', 'endpoint'])
async def monitor_middleware(request: Request, call_next):
start_time = time.time()
response = await call_next(request)
process_time = time.time() - start_time
REQUEST_COUNT.labels(method=request.method, endpoint=request.url.path).inc()
REQUEST_LATENCY.labels(method=request.method, endpoint=request.url.path).observe(process_time)
return response7. 真实项目中的意外发现
在重构过程中,我们有几个意外的收获:
-
缓存策略的重新思考:原来在单体中合理的缓存策略,在微服务中可能导致数据不一致。我们最终采用了写时失效+读时穿透的策略。
-
数据库连接池的优化 :每个微服务都需要独立的连接池,我们发现在高并发场景下,连接池大小设置为
(核心数 * 2) + 磁盘数效果最好。 -
日志聚合的重要性:没有集中的日志系统,排查跨服务问题就像大海捞针。我们最终采用了ELK栈。
互动与交流
以上就是我们从Django单体架构演进到Python微服务架构的完整实战经验。每个项目都有其独特性,期待听到你们的故事!
欢迎在评论区分享:
- 你在微服务拆分过程中遇到的最大挑战是什么?
- 对于Python微服务的技术选型,你有什么不同的见解?
- 在实际项目中,你还有哪些服务治理的独门秘籍?
每一条评论我都会认真阅读和回复,让我们在技术道路上共同进步!
下篇预告:
下一篇将分享《实战总结!我们如何将Python数据分析性能提升5倍,内存占用减少60%》,揭秘如何提升数据分析性能,极致优化。
关于作者: 【逻极】| 资深架构师,专注云计算与AI工程化实战
版权声明: 本文为博主【逻极】原创文章,转载请注明出处。