SDS(Simple Dynamic String,简单动态字符串)是 Redis 自研的字符串实现,也是 Redis 最基础、最核心的数据结构 ------Redis 中所有字符串类型的键 / 值、AOF 缓冲区、客户端输入缓冲区等场景均基于 SDS 实现。Redis 6.2 对 SDS 做了极致的内存优化,核心目标是兼顾性能、内存效率、安全性,解决原生 C 字符串的诸多缺陷。
一、为什么 Redis 不使用原生 C 字符串?
原生 C 字符串(以 \0 结尾的字符数组)存在以下致命问题,无法满足 Redis 高性能、高可靠性的需求:
- 长度计算低效 :获取字符串长度需遍历到
\0,时间复杂度 O (n); - 缓冲区溢出风险:拼接 / 修改字符串时,若未提前分配足够内存,会覆盖相邻内存;
- 不支持二进制安全 :
\0被视为结束符,无法存储图片、视频等二进制数据; - 内存重分配频繁 :每次修改字符串(增 / 删)都需手动调用
realloc,性能损耗大; - 功能单一:仅支持最基础的字符操作,无长度记录、内存预分配等能力。
Redis 6.2 的 SDS 针对以上问题做了全方位优化,同时兼容部分 C 字符串函数(如 strcmp)。
二、Redis 6.2 SDS 的结构体设计(核心优化点)
Redis 6.2 为了最小化内存开销 ,根据字符串长度设计了 5 种 SDS 头部变体(sdshdr5/8/16/32/64),不同长度的字符串使用不同大小的头部,避免「小字符串占用大头部」的内存浪费。
核心定义(源码位于 src/sds.h)
类型别名:typedef char *sds
typedef char *sds;核心设计巧思:
sds不是指向 SDS 头部,而是指向buf柔性数组的起始地址;- 直接兼容 C 字符串函数:可将
sds传给strlen/strcmp等(因buf末尾保留\0); - 头部通过「指针偏移」获取(
s - 头部大小),封装头部细节,降低上层使用成本。
SDS 头部结构体
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
// sdshdr16/32/64 结构与 sdshdr8 一致,仅 len/alloc 类型为 uint16_t/32_t/64_t
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};1. 关键属性:__attribute__ ((__packed__))
- 作用:取消编译器的内存对齐(默认按 4/8 字节对齐),避免头部内存碎片;
- 示例:sdshdr8 头部由
len(1)+alloc(1)+flags(1)组成,不加__packed__会被填充到 4 字节,加后仅占 3 字节,极致节省内存。
2. 各头部字段解析

3. sdshdr5 的特殊说明
注释明确「sdshdr5 从未直接使用,仅文档化」:
- 原因:sdshdr5 的长度存在
flags高 5 位,修改长度需位运算,比单独的len字段操作复杂; - 替代方案:即使字符串长度 < 31,Redis 也优先使用 sdshdr8(操作更简单,性能损失可忽略)。
类型操作宏(头部指针计算)
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
#define SDS_TYPE_MASK 7 // 二进制 00000111,提取 flags 低 3 位(类型)
#define SDS_TYPE_BITS 3 // 类型位的位数(3 位)
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
#define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS) // 提取 sdshdr5 的长度(右移 3 位)核心宏解析

五、内联函数(高频操作,零调用开销)
static inline 特性:编译时展开,无函数调用栈开销,适合 len/avail 等高频操作。
1. sdslen:获取 SDS 实际长度
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1]; // s 指向 buf,往前 1 字节是 flags
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8: return SDS_HDR(8,s)->len;
case SDS_TYPE_16: return SDS_HDR(16,s)->len;
case SDS_TYPE_32: return SDS_HDR(32,s)->len;
case SDS_TYPE_64: return SDS_HDR(64,s)->len;
}
return 0; // 异常兜底(理论不会走到)
}核心价值 :O (1) 获取长度,解决原生 C 字符串 strlen O (n) 的问题。
2. sdsavail:获取可用空间
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: return 0; // sdshdr5 无 alloc,无可用空间
case SDS_TYPE_8: { SDS_HDR_VAR(8,s); return sh->alloc - sh->len; }
// 16/32/64 逻辑同 8
}
return 0;
}用途:拼接 / 修改字符串前,快速判断是否需要扩容。
3. sdssetlen:设置 SDS 长度
static inline void sdssetlen(sds s, size_t newlen) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: { // 修改 flags 高 5 位(长度)+ 低 3 位(类型)
unsigned char *fp = ((unsigned char*)s)-1;
*fp = SDS_TYPE_5 | (newlen << SDS_TYPE_BITS);
} break;
case SDS_TYPE_8: SDS_HDR(8,s)->len = newlen; break;
// 16/32/64 逻辑同 8
}
}注意 :仅修改长度字段,不检查边界(由上层函数如 sdsMakeRoomFor 保证安全性)。
4. 其他内联函数

六、核心 API 声明(按功能分类)
1. 创建 / 复制 / 释放(基础生命周期)

2. 扩容 / 内存管理(性能核心)
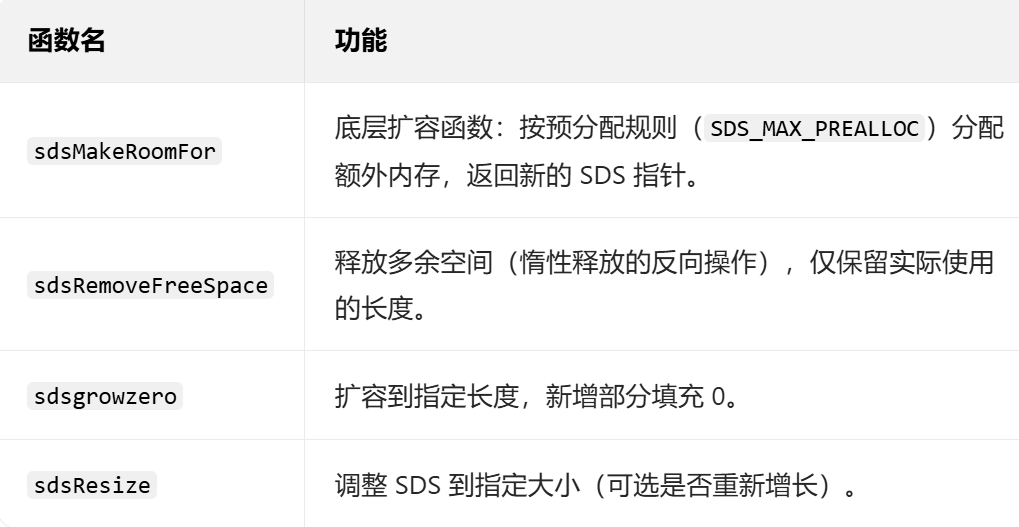
3. 拼接 / 复制(业务高频)

4. 格式化 / 转义(灵活输出)

5. 修改 / 修剪 / 截取(内容编辑)
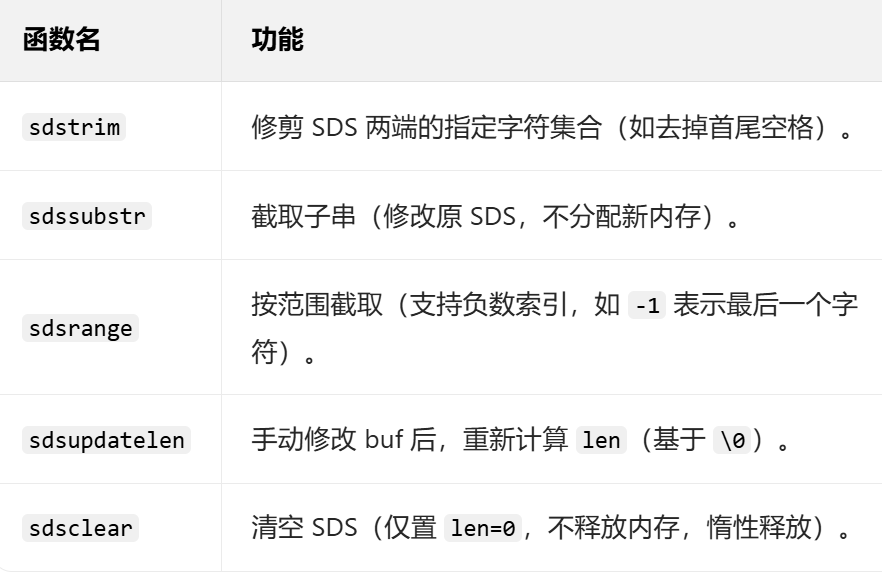
6. 比较 / 转换(类型 / 内容对比)

7. 拆分 / 拼接(批量处理)
