一、数组名的理解
在深入理解指针(1)与深入理解指针(2)中,我们不止一次提过数组名与首地址之间的关系。
接下来,我们就来严谨详细地说一下。
cpp
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
return 0;
}
我们发现,数组名与数组首元素的地址打印出来一模一样,这就说明:
数组名就是数组首元素(第一个元素)的地址。
那我们就不禁有疑问,那下述代码的arr究竟怎么理解呢?
cpp
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("%d\n", sizeof(arr));
return 0;
}
这就说明,数组名就是数组首元素(第一个元素)的地址是对的,但是有两个例外:
1.sizeof(数组名),sizeof中单独放数组名,这里的数组名表示整个数组,计算的是整个数组的大小,单位是字节;
2.&数组名,这里的数组名表示整个数组,取出的是整个数组的地址(整个数组的地址和数组首元素的地址是有区别的)。
讲到这里,或许一切都已经说通了,但是如果我们不小心运行了以下代码:
cpp
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
printf("&arr = %p\n", &arr);
return 0;
}
三个地址打印的结果一模一样,这里我们就又迷惑了,那arr和&arr到底有什么区别?
cpp
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0]+1 = %p\n", &arr[0]+1);
printf("arr = %p\n", arr);
printf("arr+1 = %p\n", arr+1);
printf("&arr = %p\n", &arr);
printf("&arr+1 = %p\n", &arr+1);
return 0;
}
我们发现,&arr0与&arr0+1相差4个字节,arr与arr+1相差4个字节,是因为&arr0和arr都是首元素的地址,+1就是跳过一个元素(整型)。
但是&arr与&arr+1相差40个字节,这就是因为&arr是数组的地址,+1的操作是跳过整个数组的。
现在,想必大家都已经对数组名有了更深、更透彻的理解。
二、使用指针访问数组
有了前面知识的支持,再结合数组的特点,我们就可以很方便的使用指针访问数组了。
cpp
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
for (int i = 0; i < sz; i++)
{
scanf("%d", (p + i));
}
for (int i = 0; i < sz; i++)
{
printf(" %d", *(p + i));
}
return 0;
}上述代码就是通过指针来实现数组的遍历。
那么我们可以思考一下,既然p代表的是数组首地址,那么我们在for循环中,直接使用arr可不可以呢?
cpp
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
/*int* p = arr;*/
for (int i = 0; i < sz; i++)
{
scanf("%d", (arr + i));
}
for (int i = 0; i < sz; i++)
{
printf(" %d", *(arr + i));
}
return 0;
}答案也是可以的。
那我们就来思考一下指针与数组二者之间的本质联系与区别:
1.数组就是数组,是一块连续的空间(数组的大小与数组的元素个数、数组的类型都有关系);
2.指针(变量)就是指针(变量),是一个变量的话就占4或8个字节;
3.数组名是地址,是首元素的地址;
4.可以使用指针来访问数组。
在我们之前遍历数组时,for循环里用的都是arri,现在我们知道也可以写成*(arr+i)的形式,这就说明了 操作符的意义。
那我们根据交换律可推*(arr+i)==*(i+arr),根据 的意义,我们是否可以得出*(i+arr)==iarr呢?
进而推得:arri==*(arr+i)==*(i+arr)==iarr。
我们来验证一下:
cpp
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
/*int* p = arr;*/
for (int i = 0; i < sz; i++)
{
scanf("%d", &i[arr]);
}
for (int i = 0; i < sz; i++)
{
printf(" %d", i[arr]);
}
return 0;
}
可以看出,是完全可以的。也就是说,我们的推断没有问题,是完全正确的。
三、一维数组传参本质
cpp
void test(int arr[10], int sz)
{
/*int* p = arr;*/
for (int i = 0; i < sz; i++)
{
printf(" %d", arr[i]);
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
test(arr,sz);
return 0;
}这里可能会有疑问,主函数调用的是arr是地址,为什么自定义函数定义的是整型数组呢?
实际上:int arr10只是更容易理解这一语法规则,其本质上还是int* arr。
cpp
void test(int* arr, int sz)
{
int* p = arr;
for (int i = 0; i < sz; i++)
{
printf(" %d", *(p + i));
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
test(arr, sz);
return 0;
}
如果你还是对上述说法存疑,我们可以再来看一个代码:
cpp
void test(int arr[10])
{
int sz= sizeof(arr) / sizeof(arr[0]);
/*int* p = arr;*/
for (int i = 0; i < sz; i++)
{
printf(" %d", arr[i]);
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
test(arr);
return 0;
}在x86的环境下,运行结果为:

这是为什么呢?
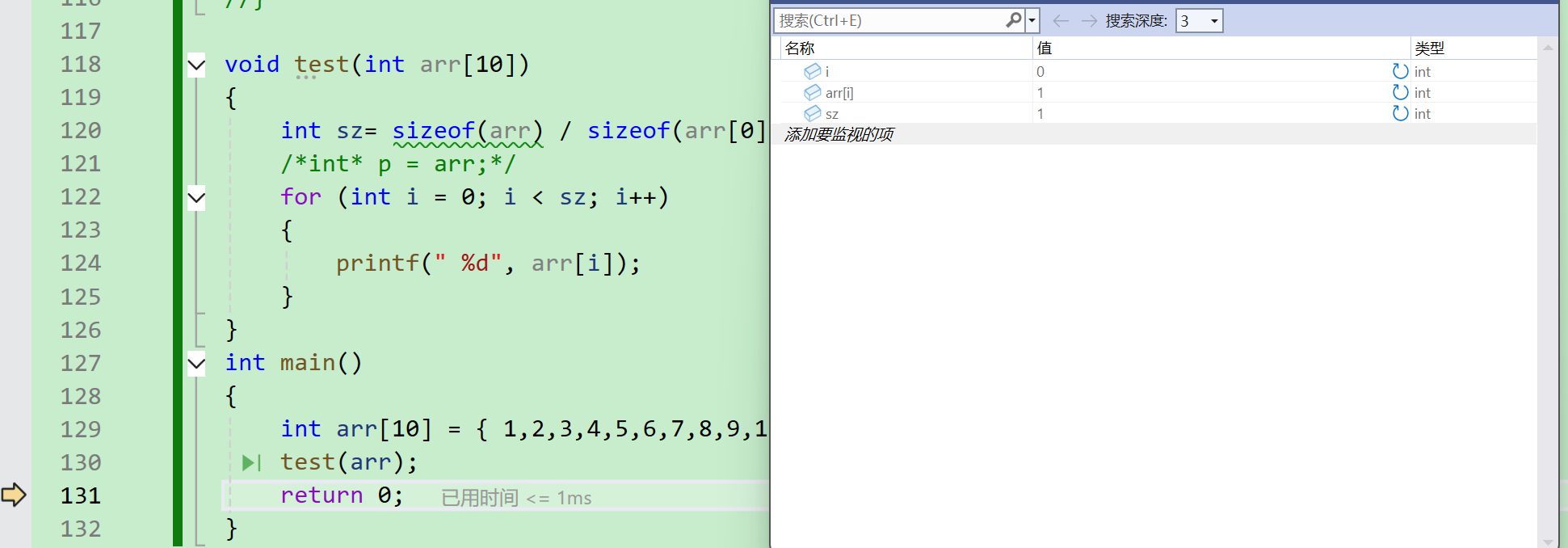
我们可以看到,sz的计算结果为1,所以for循环只执行了一次,所以最终打印在屏幕上的数字是1。
这恰恰印证了int arr10就是int* arr。因为主函数中test(arr)中的arr是数组首元素地址的意思,那传给自定义函数的地址也就只有首元素的地址,所以在自定义函数中sizeof(arr)算的是指针的大小。
总结一下:
1.数组传参的本质是传递了数组首元素的地址,所以形参访问的数组和实参的数组是同一个数组;
2.形参的数组是不会单独再创建数组空间的,所以形参的数组是可以省略掉数组大小的。
四、冒泡排序
冒泡排序的核心思想就是:两两相邻元素进行比较。
题目:将9 8 7 6 5 4 3 2 1 0进行升序排列。

上图就是一趟冒泡排序,可以明显看出,将9排列好了,一趟冒泡排序解决了一个数字。

上图就是第二趟,将8也排列好了。
我们可以看出,每趟的重复是一个循环,每一趟内部又会有两两元素的比较这一内部循环,所以我们就可以尝试写一下我们的代码了。
代码一:
cpp
#include<stdio.h>
void bubble_sort(int* arr, int sz)
{
for (int i = 0; i < sz - 1; i++)
{
for (int j = 0; j <sz-1-i ; j++)
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
void Printf(int* arr,int sz)
{
for (int i = 0; i < sz; i++)
{
printf(" %d", arr[i]);
}
}
int main()
{
int arr[10] = { 9,8,7,6,5,4,3,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
Printf(arr,sz);
return 0;
}
但是这个代码有一个稍微遗憾的地方,就是如果一个数组已经接近升序了,
比如:0 1 2 3 4 5 6 7 9 8。
这时候,按照上面的代码我们还是要进行9趟,且每一趟都要两两比较,那么有没有什么办法优化一下代码呢?
代码二:
cpp
void bubble_sort(int* arr, int sz)
{
for (int i = 0; i < sz - 1; i++)
{
int flag = 1;//假设这一趟已经有序了;
int j = 0;
flag = 0;//发生交换就说明这一趟实际上是无序的;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
if (flag == 1)
break;//这一趟没交换就说明已经有序,且后续无需排序了;
}
}
void Printf(int* arr, int sz)
{
for (int i = 0; i < sz; i++)
{
printf(" %d", arr[i]);
}
}
int main()
{
int arr[10] = { 9,8,7,6,5,4,3,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
Printf(arr, sz);
return 0;
}
上述优化完的代码就很好地提升了代码运行的效率,是一段优质的代码。
五、二级指针
指针变量也是变量,是变量就有地址,那指针变量的地址存放在哪里?
由此,我们引出了二级指针的概念。
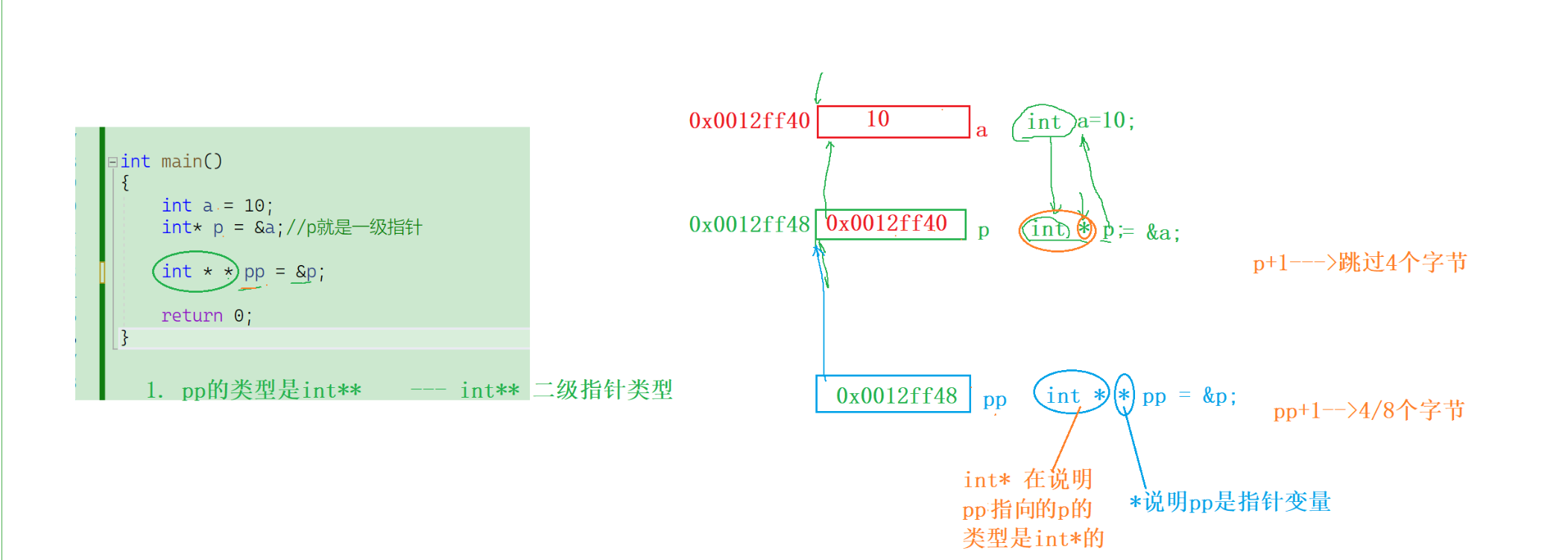
cpp
int main()
{
int a = 10;
int* p = &a;//p就是一级指针
int** pp = &p;//pp就是二级指针
return 0;
}这里我们解释一下:
1.int * p中:*p说明p是一个指针变量,int说明p指向int类型;
2.int **pp中:*pp说明pp是一个指针变量,int *说明pp指向int*类型。
以此类推:
cpp
int main()
{
int a = 10;
int* p = &a;//p就是一级指针
int** pp = &p;//pp就是二级指针
int*** ppp = &pp;//ppp就是三级指针
//......
return 0;
}那我们来用代码验证一下:
cpp
int main()
{
int a = 10;
int* p = &a;//p就是一级指针
int** pp = &p;//pp就是二级指针
printf("%p\n", p);
printf("%d\n", **pp);
printf("%p\n", &a);
return 0;
}
六、指针数组
指针数组是指针还是数组?
我们类比一下:整型数组,是存放整形的数组,字符数组是存放字符的数组。
那指针数组呢?不言而喻,是存放指针的数组。


指针数组的每个元素都是用来存放地址(指针)的。
指针数组的每个元素是地址,又可以指向一块区域。
七、指针数组模拟二维数组
cpp
int main()
{
int arr1[] = { 1,2,3,4,5,6 };
int arr2[] = { 2,3,4,5,6,7 };
int arr3[] = { 3,4,5,6,7,8 };
int* arr[] = { arr1,arr2,arr3 };
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 6; j++)
{
printf("%2d", arr[i][j]);
}
printf("\n");
}
}这里的arr i j 并不是二维数组,因为二维数组在空间内占据的内存是连续的,而arr1,arr2,arr3明显是三个不同的数组,内存不可能连续。而这里的arr i j 其实是模拟二维数组。
我们来探究一下arr i j 的本质:
我们可以看到*(arr1 j )==arr 1 j ,所以容易看出,这里是指针运算,并不是二维数组。
我们也可以展示一下程序编译时究竟怎么运算的:
1.首先,arr i ==*(arr + i);
2.然后,(arr i ) j ==*(*(arr + i)+j)。