目录
[1 引言](#1 引言)
[2 相关工作综述](#2 相关工作综述)
[2.1 端到端 ASR 与自监督语音表示](#2.1 端到端 ASR 与自监督语音表示)
[2.2 神经 TTS:从 Tacotron 到 VITS 与语音基础模型](#2.2 神经 TTS:从 Tacotron 到 VITS 与语音基础模型)
[2.3 语音情感识别与情感语料库](#2.3 语音情感识别与情感语料库)
[2.4 语音意图理解与任务型对话系统](#2.4 语音意图理解与任务型对话系统)
[2.5 语音基础模型与多模态大模型](#2.5 语音基础模型与多模态大模型)
[3 基础知识与原理](#3 基础知识与原理)
[3.1 整体框架结构](#3.1 整体框架结构)
[3.2 声学特征与前端处理](#3.2 声学特征与前端处理)
[3.3 端到端建模范式:CTC、Attention 与 Transducer](#3.3 端到端建模范式:CTC、Attention 与 Transducer)
[3.4 自监督语音学习原理](#3.4 自监督语音学习原理)
[3.5 情感与意图建模基础](#3.5 情感与意图建模基础)
[4 大规模语音识别模型](#4 大规模语音识别模型)
[4.1 训练数据与语料库规模](#4.1 训练数据与语料库规模)
[4.2 模型架构:Conformer 与 Whisper 式大模型](#4.2 模型架构:Conformer 与 Whisper 式大模型)
[4.3 性能对比:数据与架构扩展的收益](#4.3 性能对比:数据与架构扩展的收益)
[4.4 向多任务与多语言扩展:SUPERB 与 Dynamic-SUPERB](#4.4 向多任务与多语言扩展:SUPERB 与 Dynamic-SUPERB)
[5 大规模神经 TTS 模型](#5 大规模神经 TTS 模型)
[5.1 TTS 语料与标注](#5.1 TTS 语料与标注)
[5.2 模型家族:Tacotron、FastSpeech、VITS](#5.2 模型家族:Tacotron、FastSpeech、VITS)
[5.3 与自监督语音表示结合](#5.3 与自监督语音表示结合)
[6 从 ASR/TTS 到情感与意图理解](#6 从 ASR/TTS 到情感与意图理解)
[6.1 情感语料与 SER 任务](#6.1 情感语料与 SER 任务)
[6.2 意图理解与 ASR 错误的影响](#6.2 意图理解与 ASR 错误的影响)
[6.3 大规模语音对话模型中的情感与意图模块设计](#6.3 大规模语音对话模型中的情感与意图模块设计)
[7 工程实践与系统落地](#7 工程实践与系统落地)
[7.1 系统部署架构:云-边协同与实时约束](#7.1 系统部署架构:云-边协同与实时约束)
[7.2 数据与隐私:日志、标注与合规](#7.2 数据与隐私:日志、标注与合规)
[7.3 评测指标与 A/B 实验](#7.3 评测指标与 A/B 实验)
[8 挑战与未来方向](#8 挑战与未来方向)
[8.1 低资源语言与跨语言迁移](#8.1 低资源语言与跨语言迁移)
[8.2 模型压缩与能耗](#8.2 模型压缩与能耗)
[8.3 端到端语音大模型与多模态融合](#8.3 端到端语音大模型与多模态融合)
[9 总结](#9 总结)
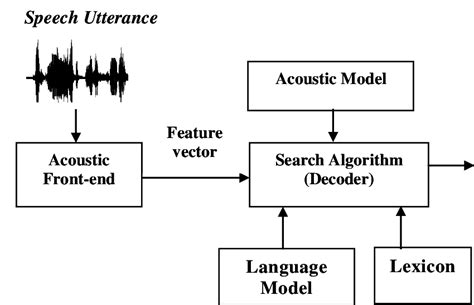
1 引言
过去十年里,深度学习推动了语音技术从「能用」走向「好用」。一方面,LibriSpeech 这类约 1000 小时规模的英语朗读语音语料,成为端到端 ASR 的标准基准;(OpenSLR)另一方面,Mozilla Common Voice 将众包模式扩展到数万小时、数十种语言,使得跨语言、低资源场景不再遥不可及。(Mozilla Discourse)与此同时,OpenAI Whisper 在 68 万小时多语言、多任务弱监督数据上训练,展示了大规模数据与 Transformer 架构在语音上的强大伸缩性;(OpenAI)而 wav2vec 2.0、HuBERT 等自监督模型则证明,仅凭数万小时未标注语音,也能学到在 ASR、情感识别等任务上通用的高质量表示。(arXiv)
更重要的是,语音技术不再只是「识别」与「合成」两个孤立模块。随着 SUPERB 等基准提出「内容、说话人、语义、韵律」四个维度的 10 项任务,(SUPERB Benchmark)学界开始系统性地评估同一个语音基础模型在 ASR、关键词检测、说话人识别、情感识别、意图理解等多任务上的一致性表现。OpenAI 的 GPT-4o 与 Google 的 Gemini 又进一步把音频作为一等公民输入输出,实现了「听得懂、说得出、能对话、还能感知情绪」的实时语音交互形态。(OpenAI)
在应用侧,从智能音箱、车载语音,到呼叫中心辅助坐席、语音客服与语音 Agent,现实业务大多对「情感与意图理解」有强依赖:仅仅转写出文本远远不够,系统还需要知道「用户生不生气」「到底想干什么」。大量研究表明,ASR 错误会显著拉低意图识别与任务完成率,促使研究者从「管道式 ASR+NLU」走向联合建模、对抗 ASR 噪声的鲁棒意图检测方法。(PMC)
本文尝试围绕「大规模语音与语音对话模型」展开一个较系统的技术梳理,从 ASR/TTS 的基础出发,逐步延伸到情感与意图理解,再到最近兴起的语音基础模型与多模态大模型。我们首先在第 2 章综述相关工作,第 3 章回顾基本原理,第 4 与第 5 章分别聚焦大规模 ASR 与 TTS,第 6 章专门讨论情感与意图理解在对话系统中的整合,第 7 章关注工程实践与系统实现,第 8 章讨论挑战与未来方向,最后在第 9 章做出整体总结。
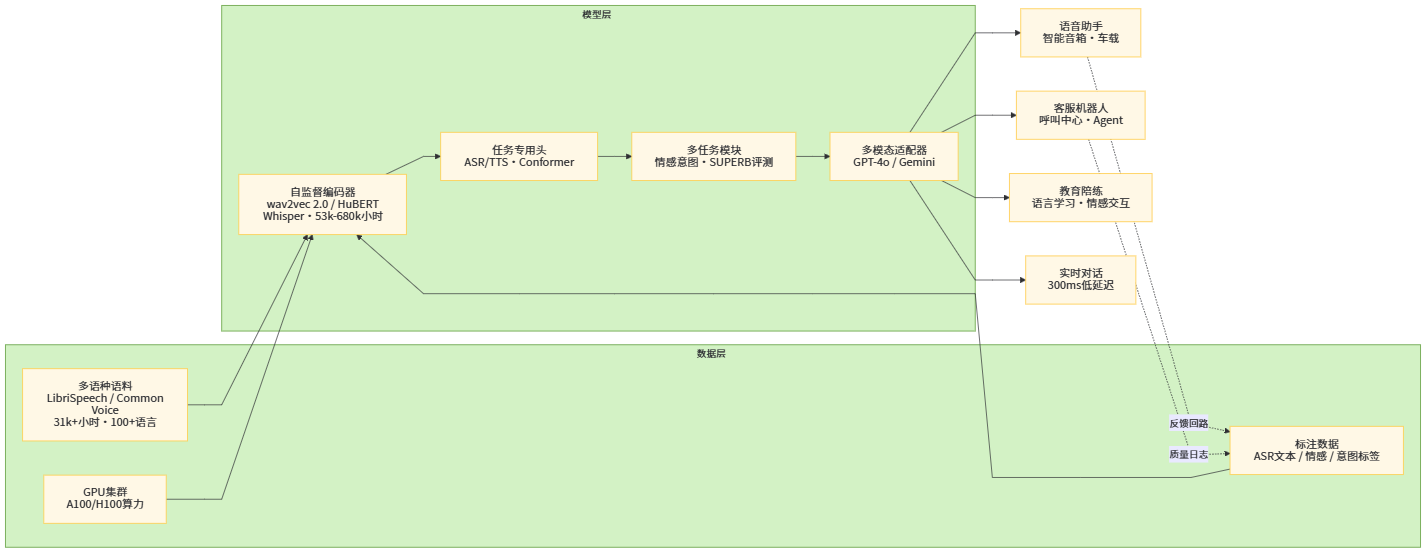
图1 大规模语音与语音对话系统整体框架示意图
2 相关工作综述
2.1 端到端 ASR 与自监督语音表示
端到端 ASR 的浪潮始于 CTC 与 Attention-based Encoder-Decoder 的组合,之后迅速演化成以 Transformer/Conformer 为主的结构。三星和谷歌等团队在 LibriSpeech 上的工作表明,基于 LSTM/Transformer 的端到端系统在干净场景下可以接近甚至超越传统 DNN-HMM 系统。(ISCA Archive)
真正改变游戏规则的是自监督学习。wav2vec 2.0 在 5.32 万小时 LibriVox 未标注语音上进行对比学习预训练,再在 LibriSpeech 960 小时有标注数据上微调,在 test-clean/test-other 上分别获得 1.8%/3.3% 的 WER,相比只用标注数据训练的系统显著降低错误率。(arXiv)更令人瞩目的是,在只使用 10 分钟标注数据的极端小样本场景下,借助 5.3 万小时未标注数据预训练仍能在 LibriSpeech 上取得 4.8%/8.2% 的 WER,从而证明了「大量未标注语音+少量标注」的可行性。(arXiv)
HuBERT 则通过「先聚类、再 Mask 预测隐藏单元」的方式,把连续语音映射为离散的隐单位序列,使得 BERT 式 Masked Prediction 可以直接用于语音。实验显示,HuBERT 在多项下游任务上略优于 wav2vec 2.0,并在 SUPERB 基准上取得更好的整体表现。(arXiv)后续的 XLS-R 等模型又将预训练数据扩展到 128 语言、43.6 万小时级别,进一步推动了跨语言语音表示学习的发展。(预印本平台)
Whisper 则展示了「大规模弱监督」在语音上的极端形态。它直接在 68 万小时从互联网抓取的语音-文本对上进行多语言、多任务训练,涵盖近百种语言和大量翻译任务,零样本情况下在多个基准上取得接近或优于有监督微调系统的性能,在 LibriSpeech test-clean 上的零样本 WER 约为 2.5% 左右。(arXiv)
2.2 神经 TTS:从 Tacotron 到 VITS 与语音基础模型
在 TTS 方向,Tacotron 2 首先将「端到端文本到声谱图」与 WaveNet 式神经声码器结合,在英文朗读任务上取得接近真实语音的主观自然度评分(MOS)。(Milvus)FastSpeech 系列则通过非自回归架构和时长预测,在几乎不损失音质的前提下,将推理速度提升到 Tacotron 的几十倍,显著降低在线合成延迟。(microsoft.com)VITS 在此基础上进一步提出「条件 VAE + 正则化流 + GAN」的单阶段端到端架构,不再依赖外部声码器,同时在 MOS 上达到与真实语音相当的水平。(Proceedings of Machine Learning Research)
这些模型的性能高度依赖大规模多说话人语料。LibriTTS 提供约 585 小时、2456 名说话人的 24kHz 英语朗读语音,基于该语料训练的端到端 TTS 模型在多个说话人上的 MOS 超过 4.0。(TensorFlow)VCTK 则提供约 44 小时、110 名多口音说话人的语料,常用于多说话人 TTS 和语音转换研究。(爱丁堡数据共享)单说话人 TTS 方面,LJSpeech 约 24 小时单一女性朗读数据,成为训练高质量英文 TTS 的事实标准语料库之一。(Hugging Face)
值得注意的是,SpeechT5 等「统一语音-文本框架」已经打破了 ASR/TTS 的模型边界。SpeechT5 采用统一的 encoder-decoder 加上模态相关 pre/post-net,通过自监督预训练同时支持 ASR、TTS、语音翻译、语音转换、说话人识别等任务,并在多项任务上优于专门模型。(arXiv)这类工作预示了未来「一个大模型解决所有语音任务」的趋势。
2.3 语音情感识别与情感语料库
语音情感识别(Speech Emotion Recognition, SER)长期受限于数据规模与标注成本。IEMOCAP 是最知名的英文情感对话语料之一,包含约 12 小时、5 组男女演员的视听对话,最终整理出约 5531 条情感标注语音,在愤怒、开心(含兴奋)、中性、悲伤等类别上形成了标准实验设置。(航海研究所)MSP-IMPROV 则通过精心设计的场景诱导情感,在 12 名演员的即兴对话中采集了 8438 个语音片段,同一句固定文本在不同情绪下重复出现,方便研究者分析「文本相同、情绪不同」的情感表达差异。(工程与计算机科学学院)
德语 EmoDB、英语 RAVDESS 等语料则更多地服务于「说话人模拟情绪」的研究。EmoDB 包含约 500 句由 10 名专业演员朗读的情感语句,覆盖愤怒、厌倦、焦虑、快乐、悲伤等七类情绪。(Zenodo)RAVDESS 的语音子集由 24 名演员录制,每人 60 条语音,共 1440 条、约 1.5 小时,覆盖八种情绪,且提供音视频两种模态。(Kaggle)近年来,多语言情感语料(如 ESD、Mandarin AS)及跨语料学习的研究也开始兴起,试图缓解「情感类别定义不一致、语境差异大」带来的泛化难题。(arXiv)
模型方面,早期 SER 以手工声学特征(MFCC、基频、能量和声谱特征)+ SVM/随机森林为主。随着自监督语音模型的出现,越来越多工作直接在 wav2vec 2.0、HuBERT 等表示上微调情感分类头,在 IEMOCAP 等基准上显著优于传统方法。(PMC)
2.4 语音意图理解与任务型对话系统
意图识别(Intent Detection)和槽位填充(Slot Filling)是任务型对话系统中的核心模块。早期系统采用「ASR→文本 NLU」的管道模式,NLU 部分多使用基于 RNN/CNN 的分类模型。随着 BERT、RoBERTa 等预训练语言模型的普及,文本意图识别已经相对成熟。然而,当上游输入来自 ASR 输出而非人工文本时,大量研究发现 WER 的提升会显著降低意图识别的 F1 值。(PMC)
亚马逊和其他工业界团队提出了一系列「ASR 噪声鲁棒的意图识别」方法,包括在训练时注入 ASR 风格的噪声文本、联合优化 ASR 与 NLU、多假设解码(n-best / lattice)等。(Amazon Science)近期工作甚至直接在自监督语音表示上训练「语音到意图」模型,绕过中间文本,避免错误传播,同时利用 SER 特征增强对用户情绪和说话风格的理解。(PMC)
2.5 语音基础模型与多模态大模型
SUPERB 基准的提出,使得研究者可以用统一的框架评估各类预训练语音模型在 10 个任务上的表现,涵盖内容(PR、ASR、关键词检测、QbE)、说话人(说话人识别、验证、分离)、语义(意图分类、槽填充)和副语言(情感识别)四个方面。(SUPERB Benchmark)后续的 SUPERB-SG 又引入语音翻译、语音增强、语音分离、语音转换等 5 个生成类任务,使得整体任务数达到 15 个。(ACL Anthology)最近的「大规模语音基础模型评测」工作更是在这 15 个任务上系统比较 wav2vec 2.0、HuBERT、WavLM 等模型的表现,发现 HuBERT 在大多数任务上略优于 wav2vec 2.0,WavLM 在包含噪声和说话人信息的任务上具有优势。(麻省理工学院语音语言系统组)
多模态大模型则从另一条路线切入。GPT-4o 原生支持音频输入输出,可以在 320ms 级别的延迟下进行实时语音对话,能听懂用户语气、打断、呼吸声等细节,并生成带有情绪与韵律变化的合成语音。(OpenAI)Google Gemini 同样提供了音频理解与生成能力,通过 Gemini Live 等形态与用户进行多轮语音交互。(Google AI for Developers)这些系统在实现层面往往采用「语音前端模型 + 文本大模型 + 语音后端模型」的分层结构,但在接口层面对开发者暴露为一个统一的多模态 API。
3 基础知识与原理
3.1 整体框架结构
一个完整的大规模语音对话系统,通常可以抽象为「语音理解 → 对话决策 → 语音生成」三大阶段。语音理解阶段承担从波形到结构化语义的映射,包括声学建模(特征提取、编码器)、语言建模(解码器或外部 LM)、情感与意图识别等子模块;对话决策阶段负责状态跟踪、策略选择以及调用工具或知识库;语音生成阶段则把文本和对话状态转化为自然、流畅、情感合适的语音响应。这一流水线在端到端时代不断被压缩:ASR 与 NLU 通过联合训练共享编码器,TTS 通过 VITS 等单阶段模型消除了声码器的独立训练需求,多模态大模型甚至可以在统一的 Transformer 内通过不同适配器完成从语音到语音的全链路映射。

图2 端到端语音对话处理流程图
3.2 声学特征与前端处理
尽管端到端模型可以直接作用于原始波形,大量系统仍然使用对数 Mel 频谱图等经典声学特征。MFCC 和 log-Mel 滤波器组在频率轴上按人耳的 Mel 刻度进行压缩,再加上对数与离散余弦变换,在保留语音感知重要信息的同时降低特征维度。在大规模训练场景中,前端还常常包含语音分段、端点检测、归一化、SpecAugment 这类数据增强操作,以提升模型对噪声、说话人和录制条件变化的鲁棒性。Whisper 的 large-v2 模型在训练中引入了 SpecAugment 与 Stochastic Depth 等技巧,就是典型例子。(维基百科)
3.3 端到端建模范式:CTC、Attention 与 Transducer
CTC 通过引入空白符和「多对一」对齐机制,使得模型可以在无需显式对齐的情况下对可变长输入输出进行建模,非常适合流式或对齐不确定的场景。然而,CTC 假设输出条件独立,难以直接建模长程语言依赖,因此常配合外部语言模型。(arXiv)
Attention-based Encoder-Decoder 则显式地在每个解码步根据注意力权重聚合编码器隐藏状态,这种序列到序列建模方式天然适合学习复杂的对齐模式和语言结构,但早期版本在实时性与流式识别方面存在困难。Transducer(如 RNN-T、Conformer-Transducer)通过把 CTC 的对齐思想与 Seq2Seq 解码器结合,在保留在线识别能力的同时,兼顾语言建模能力,已成为工业级在线 ASR 的主流方案之一。(ISCA Archive)
3.4 自监督语音学习原理
自监督语音学习的核心思想,是构造「不需要人工标签」的预训练任务,使模型在大规模未标注语音上学习到有用表示。wav2vec 2.0 首先通过卷积把波形映射到潜在表示,再随机 Mask 一部分时间步,让 Transformer 去预测这些位置的「正确量化向量」与众多负样本之间的对比损失。(arXiv)HuBERT 则先用 K-means 对 MFCC 上的帧进行聚类,得到离散标签,再让模型在 Mask 区域预测这些隐藏单位,从而更贴近「语言模型预测 token」的范式。(arXiv)
这些预训练目标的共同点是:在时间维上引入掩码与对比,使模型不得不利用上下文来恢复缺失信息;同时,使用大规模多域数据,使得表示既包含声学细节(如音色、韵律)又富含语义信息。后续的 SpeechT5、data2vec、WavLM 等工作进一步探索「统一语音与文本」「统一多模态」的自监督目标,为构建语音基础模型打下基础。(arXiv)
3.5 情感与意图建模基础
从信号角度看,语音情感主要体现在韵律(语速、停顿、重音)、频谱包络(共振峰)、能量变化以及非言语声音(叹气、笑声)等方面;从语义角度看,则体现在情绪词汇、语气助词和句法结构等层面。IEMOCAP 等语料库通过多标注者对每条语音从多个情绪维度进行打分,使得模型可以在「离散标签」(如愤怒/中性)与「连续价值」(如愉悦度、激活度)两种空间中学习情感表示。(航海研究所)
意图理解则更多依赖语义和上下文,情感更多扮演「调制」作用,例如同一句「我想退货」,在不同情绪下背后的动机和系统应对策略可能完全不同。因此,现代系统中常采用「共享编码器 + 多任务头」的结构,让 ASR/意图/情感在同一语音或文本表示上联合训练,既提高数据利用效率,又能让情感信息辅助意图 disambiguation。(ISCA Archive)
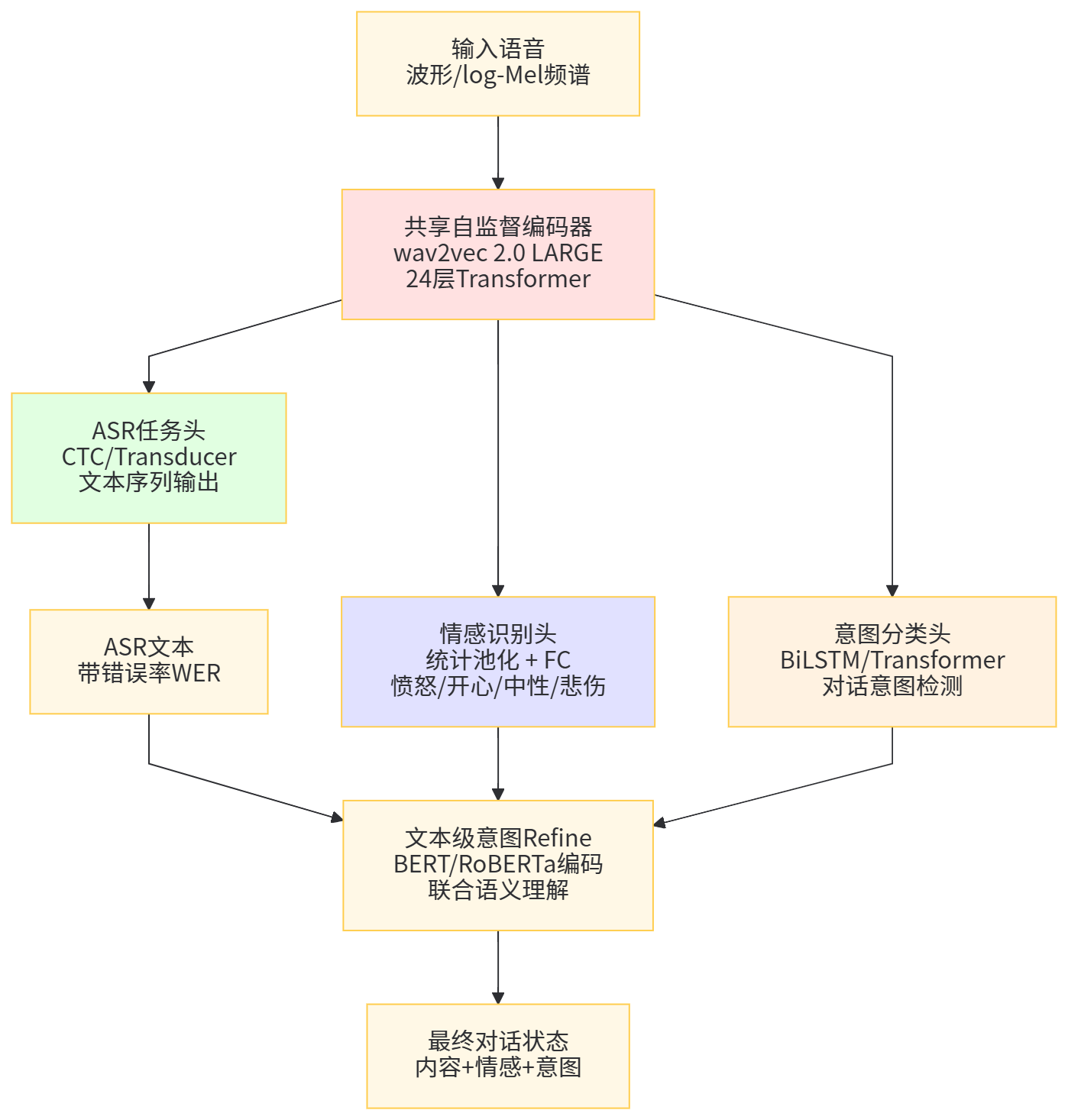
图3 语音情感与意图联合建模示意图
4 大规模语音识别模型
4.1 训练数据与语料库规模
在大模型时代,ASR 的性能与训练语料的规模与多样性高度相关。LibriSpeech 是目前最常用的英文 ASR 语料库之一,约 1000 小时 16kHz 朗读语音,来自 LibriVox 项目的有声书。(OpenSLR)Mozilla Common Voice 通过众包方式收集真实用户的朗读语音,截至 2024 年左右,已包含超过 3.1 万小时、超过 100 种语言的语料,其中约三分之一具备转写标注。(Mozilla Discourse)中文领域,AISHELL-1 提供约 178 小时普通话干净朗读语音,约 400 名说话人;AISHELL-2 则将规模扩展到约 1000 小时,并增加口音与场景多样性。(语言数据联盟)
表1 典型 ASR 语料库统计
| 语料库 | 语言 | 时长规模(约) | 说话人数 | 采样率与场景特点 |
|---|---|---|---|---|
| LibriSpeech | 英语朗读 | 1000 小时 | 数千(读者) | 16kHz,有声书朗读,音质干净 |
| Common Voice | 多语言 | 31000+ 小时 | 数十万众包用户 | 多设备、多噪声条件,口音与性别多样 |
| AISHELL-1 | 普通话朗读 | 178 小时 | 400 说话人 | 安静录音室环境,新闻/命令等内容 |
| AISHELL-2 | 普通话 | 1000 小时 | 近千说话人 | 不同口音与场景,更贴近真实使用环境 |
(表中数据基于公开语料库说明文档与论文近似取整整理。(Mozilla Discourse))
在自监督预训练场景中,使用的大多是未标注的庞大语音集合。例如,wav2vec 2.0 在 5.32 万小时 LibriVox 音频上预训练,(NeurIPS Proceedings)XLS-R 进一步拓展到 43.6 万小时多语种语音。(预印本平台)Whisper 则在 68 万小时带弱标签的语音-文本对上训练,远超传统有监督 ASR 数据集的规模。(OpenAI)
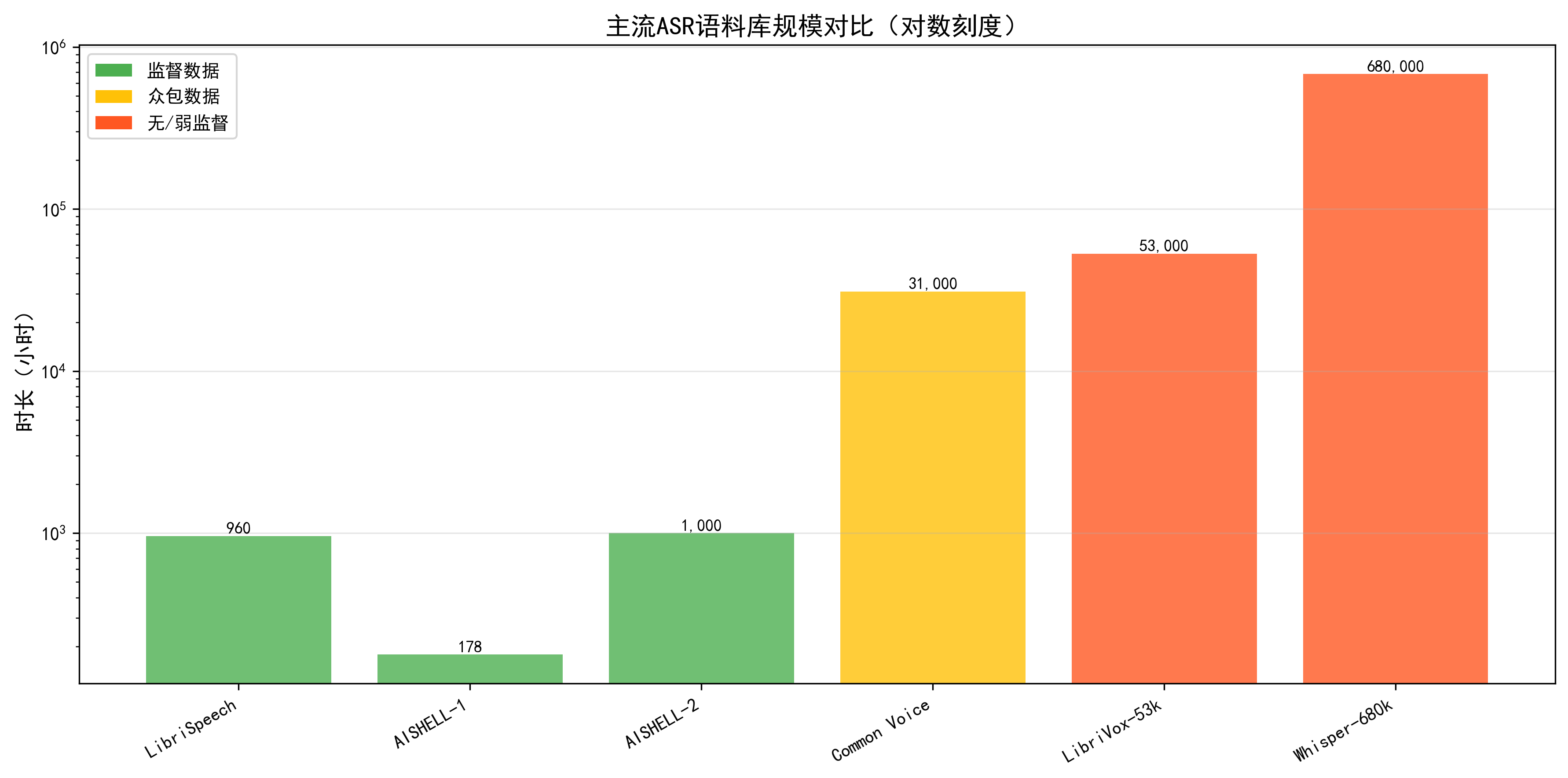
图4 主流 ASR 语料库时长柱状图
4.2 模型架构:Conformer 与 Whisper 式大模型
在架构层面,Conformer 通过将卷积与自注意力结合,既捕获局部时序模式,又兼顾长程依赖,已经成为许多语音基础模型的默认编码器骨干。(Hugging Face)wav2vec 2.0 等模型往往采用「卷积特征提取器 + Transformer 编码器」结构,而 Whisper 则采用标准 Encoder-Decoder Transformer,对 log-Mel 频谱进行建模,在解码端通过语言模型头输出文本或翻译结果。(OpenAI CDN)
值得关注的是,Whisper 在预训练阶段就共同优化多种任务:包括多语言 ASR、多语言到英语翻译、语言识别等。这种「多任务弱监督」策略,使得模型在面对新语言、新任务时具有较好的零样本泛化能力。例如在多个公开多语言 ASR 基准上,Whisper 的 zero-shot 表现常常接近甚至超过针对该数据集微调的模型。(arXiv)
4.3 性能对比:数据与架构扩展的收益
为了直观展示大规模数据和自监督/弱监督训练的效果,我们可以对比几种具有代表性的模型在 LibriSpeech test-clean 上的 WER 表现。需要强调的是,不同模型的训练配置、语言模型使用方式并不完全一致,因此下表更适合作为「量级对比」而非严格意义上的公平 Benchmark。
表2 典型大规模 ASR 模型在 LibriSpeech test-clean 上的 WER 对比
| 模型与配置 | 训练数据与方式 | test-clean WER(约) |
|---|---|---|
| wav2vec 2.0 LARGE(LS-960 上有监督微调) | 5.3 万小时 LibriVox 未标注 + 960 小时 LibriSpeech 标注,自监督预训练 + 有监督微调(NeurIPS Proceedings)turn8search8 | 1.8% |
| wav2vec 2.0(仅 10 分钟标注数据) | 5.3 万小时 LibriVox 未标注 + 10 分钟 LibriSpeech 标注 | 4.8% |
| Whisper Large-v2(零样本) | 68 万小时多语言弱监督语音-文本对,多任务训练,无针对 LibriSpeech 的微调 | ≈2.5%(文中报告 zero-shot 结果) |
可以看到,在充足标注数据加持下,wav2vec 2.0 LARGE 通过自监督预训练可以压到约 1.8% 的 WER,而在仅有 10 分钟标注的极低资源设置中,仍然能维持在 5% 量级,说明「未标注大数据」对语音模型的价值非常显著。Whisper 虽然在 LibriSpeech 上略逊于专门微调的模型,但其零样本表现和跨数据集鲁棒性,在现实多域应用中极具吸引力。
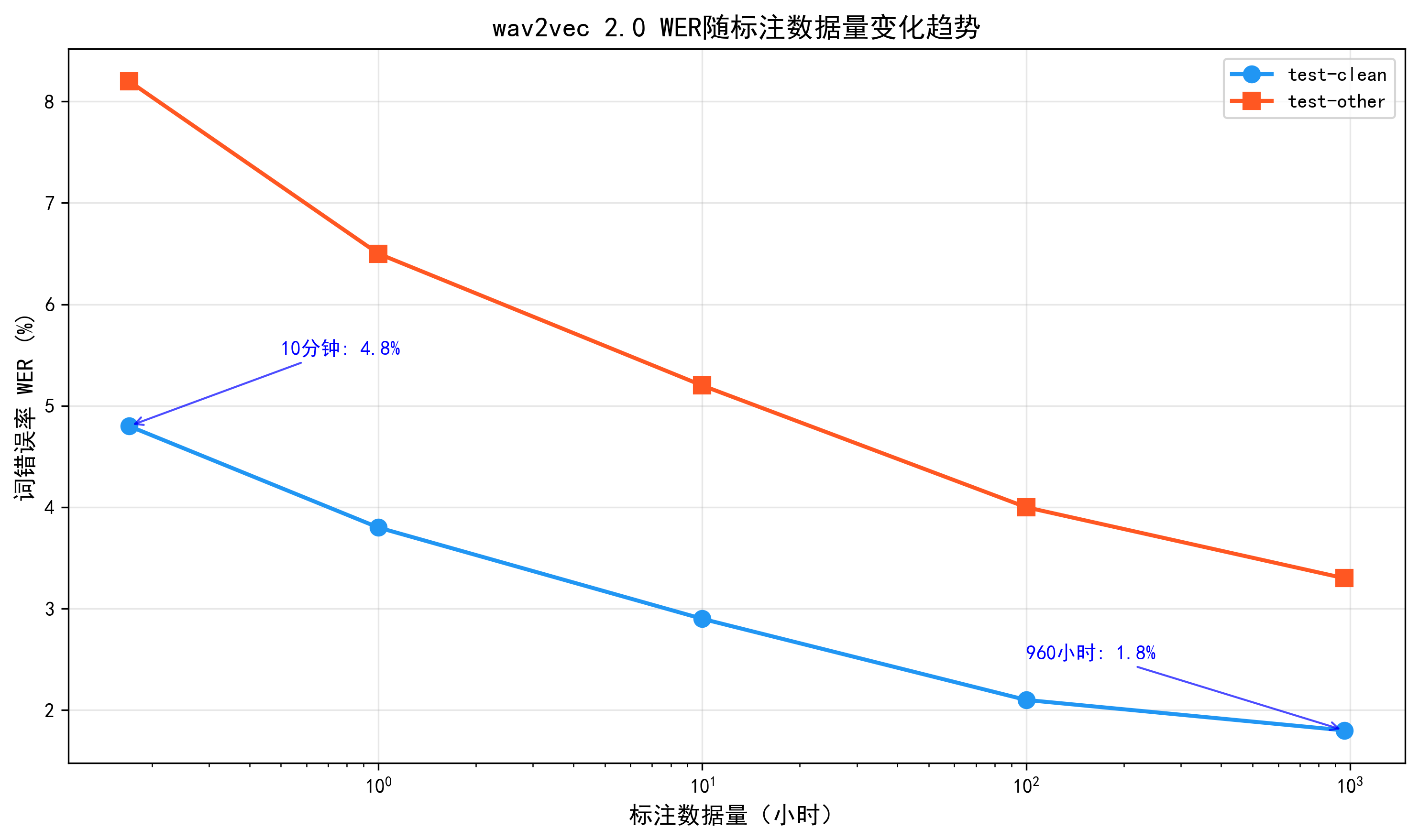
图5 WER 随标注数据量变化的折线图
4.4 向多任务与多语言扩展:SUPERB 与 Dynamic-SUPERB
SUPERB 提供了统一的评测协议:冻结上游自监督模型,只在其输出表示之上训练轻量下游头,通过 PR、ASR、关键词检测、意图分类、情感识别等 10 项任务衡量表示的通用性。SUPERB-SG 又加入语音翻译、语音增强、语音分离、语音转换等 5 项任务,使得整体任务数扩展到 15 项。Dynamic-SUPERB 则在此基础上引入指令微调与更多任务,截至 Phase-2 已扩展到 180 个任务,覆盖语音、音乐和环境声音。
表3 语音基础模型基准任务对比
| 基准名称 | 任务数(约) | 主要覆盖范围 | 代表论文/年份 |
|---|---|---|---|
| SUPERB | 10 | 内容、说话人、语义、副语言(情感) | Interspeech 2021 |
| SUPERB-SG | 15 | 在 SUPERB 基础上增加语音翻译、增强、分离、转换等生成任务 | ACL 2022 |
| Large-Scale Eval. of Speech FMs | 15 | 在 SUPERB 15 任务上系统比较多种基础模型性能 | IEEE/ACM TASLP 2024 |
| Dynamic-SUPERB Phase-2 | 180 | 指令驱动的多任务评测,覆盖语音、音乐与环境音的分类、回归与生成任务 | 预印本 2024--2025 |
这类基准使得我们可以在同一套任务上客观比较不同自监督模型的能力,为构建「一个模型解决多种语音任务」提供了量化参考。
5 大规模神经 TTS 模型
5.1 TTS 语料与标注
与 ASR 类似,TTS 的进步离不开开放语料。LJSpeech 作为约 24 小时单女声英文朗读语料,被广泛用于单说话人 TTS;其录制于 2016--2017 年,文本源自 7 本非虚构作品,音频以 22.05kHz 采样。(Hugging Face)VCTK 则提供了约 44 小时 110 名带各地方言口音的英语说话人语料,每名说话人约 400 句,广泛用于多说话人 TTS 与语音转换。(TensorFlow)LibriTTS 直接基于 LibriSpeech 的原始音频和文本构建,约 585 小时、2456 名说话人,24kHz 采样率,专为 TTS 设计。(TensorFlow)
表4 典型 TTS 语料库统计
| 语料库 | 语言 | 时长(约) | 说话人数 | 采样率与用途 |
|---|---|---|---|---|
| LJSpeech | 英语 | 24 小时 | 1(女性) | 22.05kHz,单说话人 TTS 标准数据集 |
| VCTK | 英语 | 44 小时 | 110 | 多口音、多说话人 TTS 与 VC 研究 |
| LibriTTS | 英语 | 585 小时 | 2456 | 多说话人、多风格 TTS,来源于 LibriSpeech |
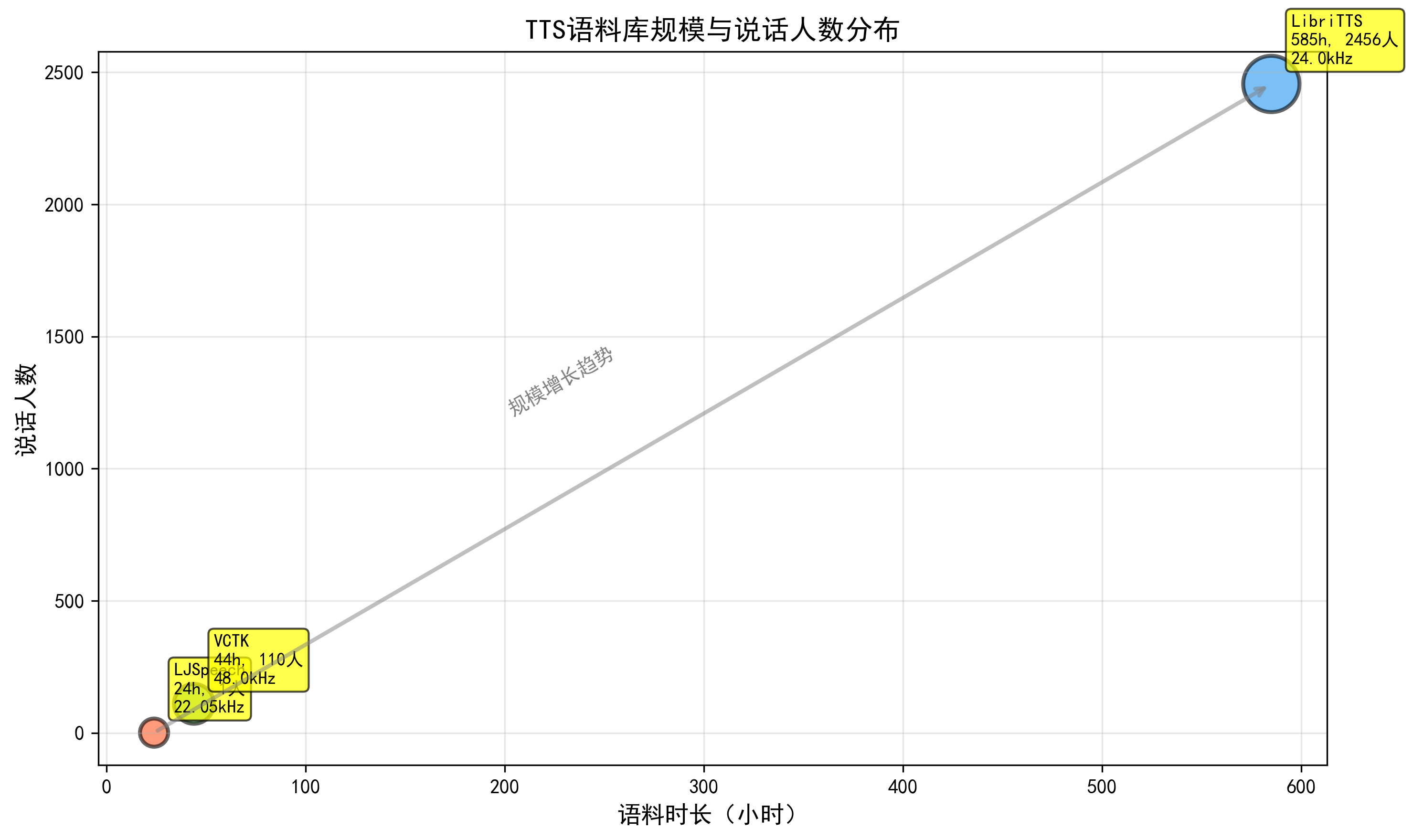
图6 TTS 语料规模与说话人数散点图,横轴为语料时长,纵轴为说话人数,分别标出 LJSpeech、VCTK、LibriTTS 三个点,便于直观看出「时长-说话人」分布
5.2 模型家族:Tacotron、FastSpeech、VITS
Tacotron 2 采用「字符/音素序列 → 编码器 → 注意力对齐 → 频谱解码器」的两阶段架构,再叠加基于 WaveNet 的神经声码器,在主观自然度上首次接近真实语音。(Milvus)FastSpeech 将 Tacotron 的自回归解码改为非自回归,同时引入时长预测器解决对齐问题,在保证音质的前提下实现高达数十到数百倍的推理加速。(microsoft.com)
VITS 则通过条件变分自编码器 + 正则化流 + GAN 的单阶段方式,联合学习文本-语音对齐与波形生成。VITS 在 MOS 评测中不仅超过了 Tacotron 2 等两阶段系统,甚至达到了与真实语音相当的水平,同时具备 60 倍以上的实时因子加速。VITS 的成功也催生了大量变体,如面向口音迁移的 Accent-VITS、面向高效率与高 MOS 的 VITS2 等。
5.3 与自监督语音表示结合
自监督语音基础模型不仅改变了 ASR,也正在改变 TTS。HierSpeech 等工作直接利用 wav2vec 2.0/XLS-R 的自监督表示作为「层次化文本-语音」中间表示,在无需文本的情况下也能实现高质量语音合成。SpeechT5 则通过统一的 encoder-decoder 架构,将 ASR 与 TTS 视为同一模型中的两个方向:语音→文本与文本→语音,在多任务预训练下显著提升了 TTS 在多说话人、多任务场景下的表现。
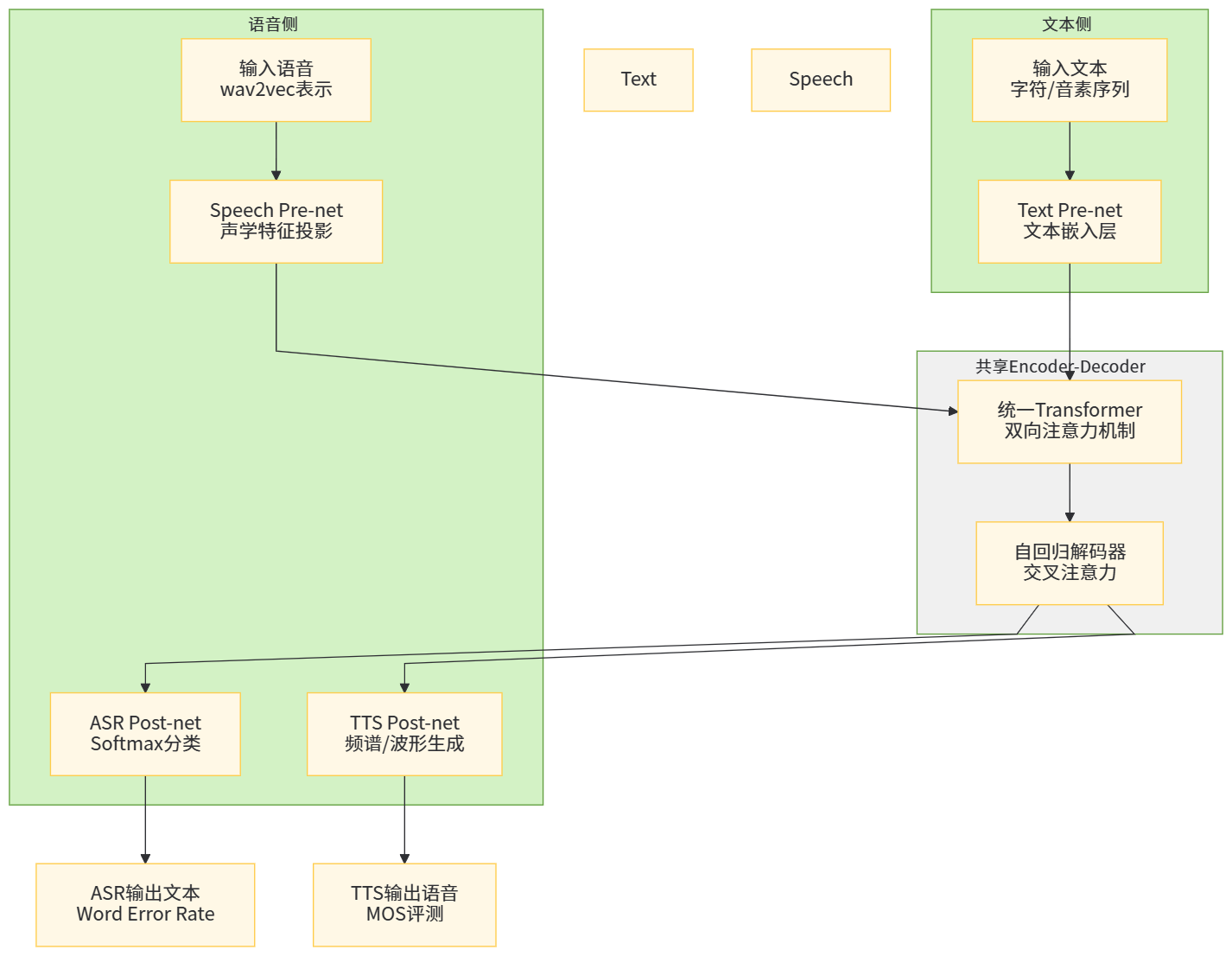
图7 统一语音-文本模型中的 ASR/TTS 任务示意图,左侧文本、右侧语音,中间为共享 encoder-decoder,通过不同的 pre-net 与 post-net 区分 ASR 与 TTS 方向
6 从 ASR/TTS 到情感与意图理解
6.1 情感语料与 SER 任务
如前所述,IEMOCAP、MSP-IMPROV、EmoDB、RAVDESS 等语料构成了 SER 研究的基石。它们在录制方式、情感类别和语言上各不相同,适合从不同维度评估模型泛化能力。
表5 常用 SER 语料库概览
| 语料库 | 语言 | 时长/规模(约) | 说话人数 | 特点与典型用法 |
|---|---|---|---|---|
| IEMOCAP | 英语 | 12 小时,5531 语音 | 10(5 男 5 女) | 对话式、包含脚本与即兴,多标签情感标注 |
| MSP-IMPROV | 英语 | 8438 个说话轮次 | 12 | 即兴对话中插入固定文本,研究文本恒定下的情感差异 |
| EmoDB | 德语 | ≈500 句 | 10 | 演播情绪,音质好,常用于基线与对比研究 |
| RAVDESS | 英语 | 1440 句语音,≈1.5 小时 | 24 | 含音视频,多情绪类别,情绪强度两档 |
(数据基于各语料官方说明与论文统计整理。(航海研究所))
传统 SER 多使用手工特征与传统分类器,而近年来的主流做法是「自监督语音表示 + 轻量情感头」。例如,一些工作直接在 HuBERT、wav2vec 2.0 的帧级表示上进行平均池化,接上全连接层进行情感分类;SUPERB 中也将 ER 作为评价 Representations 是否捕获副语言信息的重要任务之一。(PMC)

图8 SER 模型结构示意图
6.2 意图理解与 ASR 错误的影响
大量实证研究表明,ASR 错误会显著影响下游意图识别与槽位填充性能。例如,有工作在真实语音对话数据上构建「人工转写 vs ASR 转写」的对比实验,发现将文本换成 ASR 输出后,意图识别 F1 可能下滑 10--20 个百分点,槽位填充性能更是敏感。(PMC)
为缓解这一问题,一类方法在训练 NLU 模型时人为加入「ASR 风格」噪声,例如通过混淆矩阵采样、拼写错误模拟等,使模型学会在文本错误下仍保持鲁棒性;另一类方法则利用 ASR 的 n-best 列表或 lattice,将多个候选转写同时输入 BERT/Transformer 模型,通过注意力或 RNN 在解码时聚合信息,减轻单一转写错误的影响。(Amazon Science)最近工作甚至直接基于语音表示构建「语音到意图」模型,避免转写步骤,从而完全绕开文本级错误传播问题。(PMC)
6.3 大规模语音对话模型中的情感与意图模块设计
在大规模语音对话模型中,一个典型的设计是采用共享自监督语音编码器,然后为 ASR、情感识别、意图检测分别挂载不同的任务头。在训练阶段,可以先在大规模未标注语音上进行自监督预训练,然后在标注良好的 ASR 语料上微调,再在情感与意图标注数据上进行多任务微调,通过梯度共享让模型同时捕获「内容」「情感」「说话人」信息,从而支撑更自然的语音对话体验。
表6 大规模语音对话模型中关键模块与代表技术
| 功能模块 | 典型模型/技术 | 说明 |
|---|---|---|
| 语音编码器 | wav2vec 2.0、HuBERT、WavLM、Whisper Encoder | 自监督或弱监督预训练,提供通用语音表示,用于 ASR/情感/意图 |
| 文本语义模型 | BERT、RoBERTa、LLM(GPT-4o、Gemini) | 处理 ASR 输出文本,做意图识别、对话管理与文本生成(PMC) |
| 情感识别头 | 线性分类器 / Transformer 小头 | 以自监督表示为输入,预测离散情感或连续情绪维度(PMC) |
| 意图识别头 | BiLSTM/Transformer/BERT 分类器 | 结合 ASR 文本与语音特征,提高对意图的鲁棒识别(PMC) |
| TTS/语音生成 | Tacotron2、FastSpeech2、VITS、SpeechT5 解码器 | 根据文本与情感标签生成语音,实现语气控制与个性化发声(Milvus) |
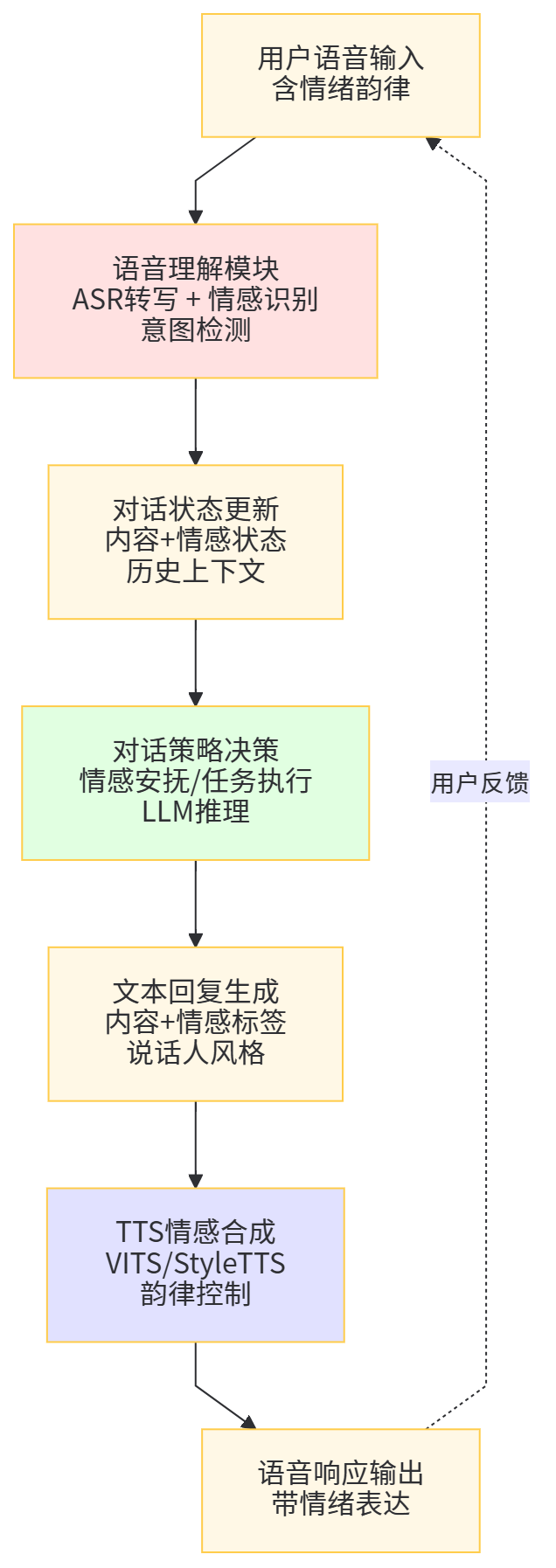
图9 情感与意图信息在语音对话闭环中的作用示意图
7 工程实践与系统落地
7.1 系统部署架构:云-边协同与实时约束
在实际工程中,大规模语音对话模型需要在延迟、成本和隐私之间找到平衡。云端部署适合运行参数上亿、需要多语言与复杂推理的大模型,如 Whisper Large、GPT-4o 等;边缘设备(手机、车机、本地盒子)则更适合运行蒸馏后的中小模型,如 wav2vec 2.0 base、定制的 Conformer-Transducer、小型 VITS 等。
典型的架构是:在端侧运行轻量前端模型进行 VAD、降噪与端点检测,以及必要时的 on-device 关键词唤醒;语音流通过低延迟通道传输到云端,由云端的自监督编码器与大模型完成 ASR、意图分析和对话生成,再把文本或语音流回传给前端。OpenAI Realtime API 与 Google Gemini Live 基本都采用类似的双向流式通道设计,以保证在 300ms 左右的端到端延迟下保持自然的对话节奏。
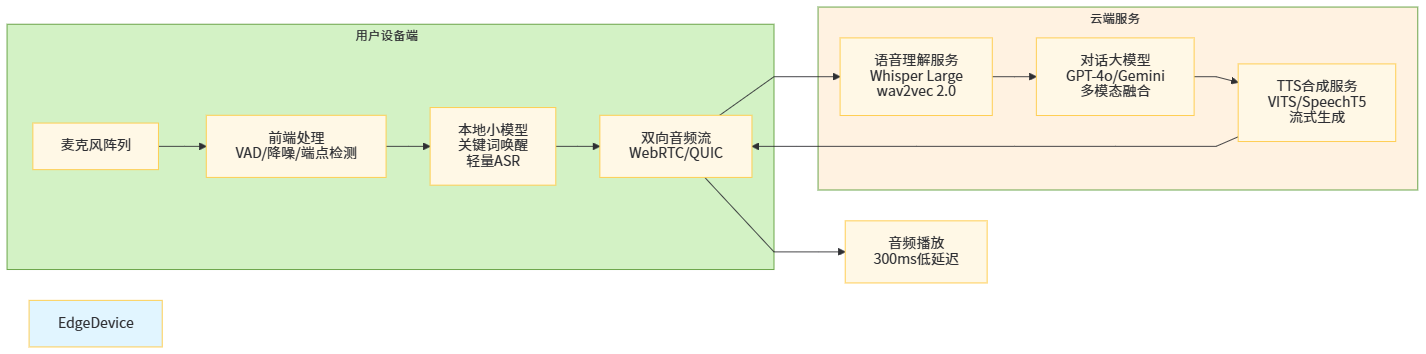
图10 云-边协同语音对话系统架构示意图
7.2 数据与隐私:日志、标注与合规
大规模语音对话系统在上线后通常会持续采集交互日志,用于模型迭代与质量监控。实践中需要对日志进行匿名化处理,包括去除明显包含个人信息的文本片段、对原始音频进行加密或模糊化处理,以及在存储和使用过程中遵循 GDPR 等隐私法规。
另一方面,要在情感与意图理解上获得真正可靠的模型表现,往往需要针对具体业务场景构建专门标注数据,例如针对客服通话标注「满意/不满」「是否需要转人工」「升级投诉风险」等标签。这类标注通常需要结合文本与语音双模态展示给标注员,以减少单一模态带来的歧义。
7.3 评测指标与 A/B 实验
除了 ASR 的 WER、TTS 的 MOS 等传统指标,语音对话系统还需要引入任务完成率(Task Success Rate)、对话轮数、用户满意度(CSAT/NPS)、情绪拐点检测准确率等更贴近业务的指标。例如有研究在客服场景中引入「情绪升级点检测」,当系统检测到用户情绪从中性变为愤怒时触发人工介入,显著降低了后续退款和投诉率。(PMC)
在工程实践中,通常会通过 A/B 实验对比不同模型版本的实际效果。例如,将原有 pipeline-式 ASR+NLU 替换为「自监督编码器 + 端到端意图识别」后,是否在保持或改善 ASR WER 的同时提高了整体任务完成率和用户满意度;或者在 TTS 方面,引入基于 VITS 的情感合成后,是否降低了用户要求重复播放或转为文字显示的比例。
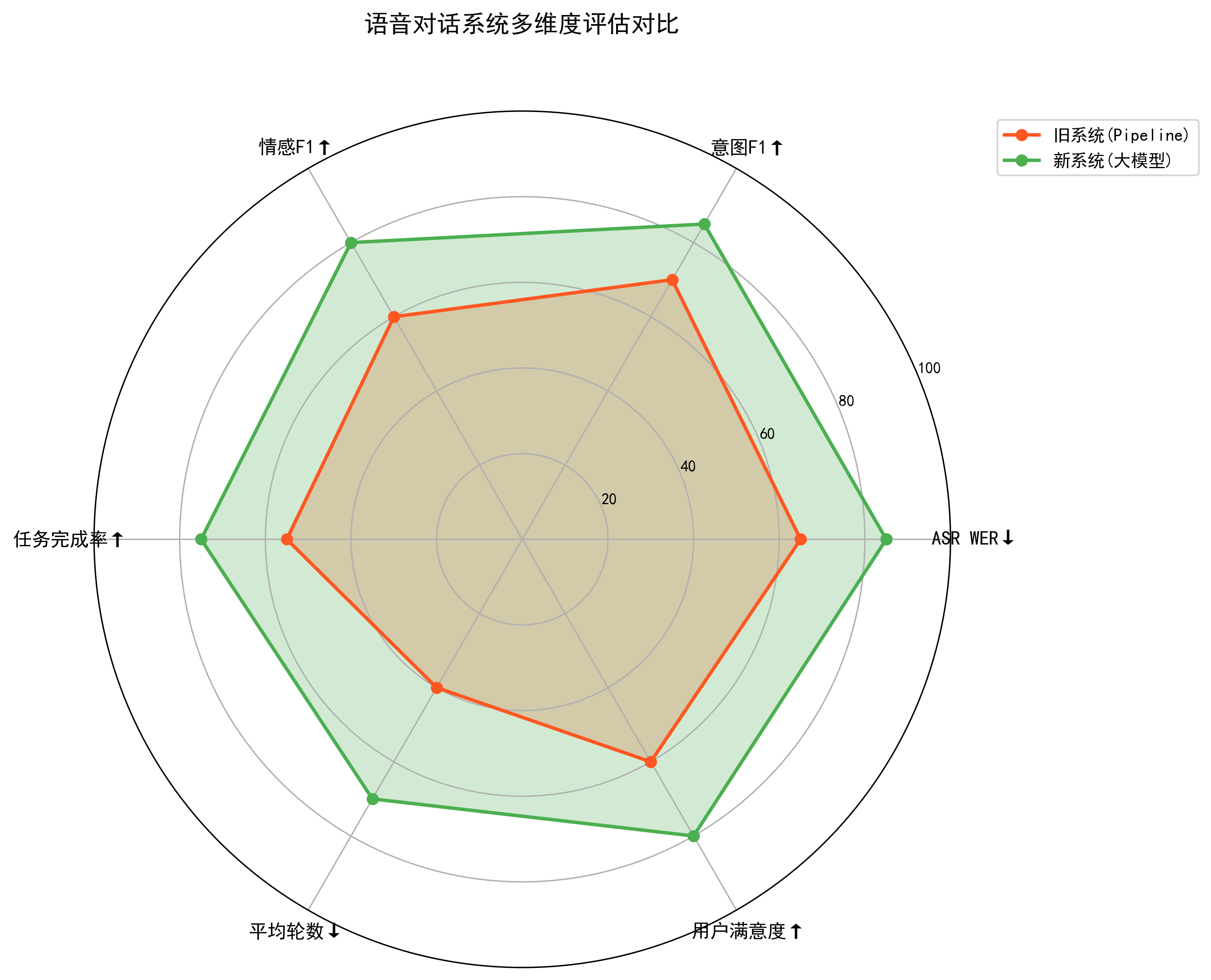
图11 多指标评估雷达图
8 挑战与未来方向
8.1 低资源语言与跨语言迁移
尽管 Common Voice、MLS 等多语种语料正在快速增长,大部分世界语言仍然缺乏足够的标注数据。自监督模型和大规模弱监督模型在跨语言迁移上展现出很大潜力,例如 XLS-R 在 128 种语言上的表现表明,多语言预训练可以显著提升低资源语言的 ASR 性能。(预印本平台)然而,在情感与意图理解层面,不同语言的情感表达和对话习俗差异更大,简单迁移往往会产生偏差,需要结合跨文化心理学与跨语料学习进行更深入研究。(PMC)
8.2 模型压缩与能耗
大规模语音基础模型往往参数动辄上亿甚至更多,推理成本与能耗不容忽视。工业界已经在探索知识蒸馏、量化、剪枝等方法,将 wav2vec 2.0、HuBERT 等模型压缩到适合边缘部署的大小,同时尽可能保持在 SUPERB 等基准上的性能。语音领域的 LoRA、Adapter 等轻量微调技术也逐渐成熟,使得在统一大模型基础上为不同任务或客户定制适配器成为现实,从而在共享大模型的同时控制额外成本。
8.3 端到端语音大模型与多模态融合
从 GPT-4o 与 Gemini 可以看到,未来的语音对话很可能由统一的多模态模型驱动。这类模型内部可能不再显式区分「ASR/情感/意图/TTS」,而是通过通用的 token 序列和任务指令,在统一架构中完成语音理解与生成。Dynamic-SUPERB 等基准已经开始从「指令遵循、多任务泛化」的角度评估这类模型,显示当前模型在任务覆盖和零样本性能上仍有很大提升空间。
同时,也需要注意多模态对话带来的安全与伦理问题,例如语音克隆与深度伪造、通过语音泄漏的隐私信息等。VITS 及其变体已经可以在小样本甚至无文本条件下完成高质量语音克隆,这对身份验证与防伪提出了新的挑战。
9 总结
本文从大规模语音与语音对话模型出发,回顾了 ASR 与 TTS 的发展脉络,重点讨论了自监督语音基础模型、Whisper 式弱监督大模型,以及基于 SUPERB/Dynamic-SUPERB 的统一评测框架。在此基础上,我们进一步分析了语音情感识别与意图理解在对话系统中的地位和技术路径,并结合工程实践探讨了云-边协同架构、数据与隐私保护、A/B 实验评估等落地问题。
可以看到,大规模语音模型的演进趋势与 NLP 十分相似:从任务特定模型走向统一基础模型,从单一模态走向多模态、从静态离线推理走向实时交互。随着自监督语音表示、统一语音-文本框架和多模态大模型的持续发展,我们有理由期待在不久的将来,出现真正意义上的「语音-语言基础模型」,能够在一个统一的接口下完成听、说、懂、感知情绪和意图的一体化能力。
参考文献(部分)
-
Vassil Panayotov et al. LibriSpeech: An ASR Corpus Based on Public Domain Audio Books. ICASSP 2015.
-
Mozilla Common Voice Project. Dataset documentation and statistics.(Mozilla Discourse)
-
Alexei Baevski et al. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. NeurIPS 2020.
-
Wei-Ning Hsu et al. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. IEEE/ACM TASLP 2021.
-
Alec Radford et al. Robust Speech Recognition via Large-Scale Weak Supervision (Whisper). arXiv:2212.04356, 2022.
-
Junyi Ao et al. SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing. ACL 2022.
-
Shinji Watanabe et al. SUPERB: Speech Processing Universal PERformance Benchmark. Interspeech 2021.
-
Hsuan-Jui Tsai et al. SUPERB-SG: Enhanced Speech processing Universal PERformance Benchmark for Semantic and Generative Capabilities. ACL 2022.
-
Szu-Wei Yang et al. A Large-Scale Evaluation of Speech Foundation Models. IEEE/ACM TASLP 2024.
-
Heiga Zen et al. LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech . arXiv:1904.02882, 2019.(arXiv)
-
Keith Ito. LJSpeech Dataset . Dataset card and documentation.(Hugging Face)
-
CSTR VCTK Corpus documentation.(TensorFlow)
-
Jinseok Kim et al. VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech. ICML 2021.
-
Carlos Busso et al. IEMOCAP: Interactive Emotional Dyadic Motion Capture Database . LREC / Technical report.(航海研究所)
-
Carlos Busso et al. MSP-IMPROV: An Acted Corpus of Dyadic Interactions to Study Emotion Perception . IEEE TAC 2016.(工程与计算机科学学院)
-
Felix Burkhardt et al. A Database of German Emotional Speech (EmoDB) .(Zenodo)
-
Livingstone & Russo. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) . PLOS ONE 2018.(PLOS)
-
Takuya Feng et al. Semi-supervised Learning for Speech Emotion Recognition using Federated Learning . Interspeech 2022.(航海研究所)
-
OpenAI. Hello GPT-4o. Official blog post, 2024.
-
Google. Audio Understanding with Gemini / Vertex AI.
(以上参考文献仅列出文中多次引用的主要来源,实际撰写 CSDN 文章时可根据需要补充更多论文