| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之Milvus部署架构选型+Linux实战:Docker一键部署+WebUI使用 |
前情摘要
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
9、零基础学AI大模型之Prompt提示词工程
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain链
13、零基础学AI大模型之Stream流式输出实战
14、零基础学AI大模型之LangChain Output Parser
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之大模型的"幻觉"
17、零基础学AI大模型之RAG技术
18、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
19、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析
20、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战
21、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析
22、零基础学AI大模型之LangChain 文本分割器实战:CharacterTextSplitter 与 RecursiveCharacterTextSplitter 全解析
23、零基础学AI大模型之Embedding与LLM大模型对比全解析
24、零基础学AI大模型之LangChain Embedding框架全解析
25、零基础学AI大模型之嵌入模型性能优化
26、零基础学AI大模型之向量数据库介绍与技术选型思考
27、零基础学AI大模型之Milvus向量数据库全解析
28、零基础学AI大模型之Milvus核心:分区-分片-段结构全解+最佳实践
29、零基础学AI大模型之Milvus部署架构选型+Linux实战:Docker一键部署+WebUI使用
本文章目录
- 零基础学AI大模型之Milvus实战:Attu可视化安装+Python整合全案例
-
- 一、Attu可视化客户端:Milvus图形化管理利器
- 二、Attu安装实战(跨平台适配)
-
- [1. 前置条件](#1. 前置条件)
- [2. Windows系统安装](#2. Windows系统安装)
- [3. macOS系统安装](#3. macOS系统安装)
- [4. Linux系统安装(Debian/Ubuntu)](#4. Linux系统安装(Debian/Ubuntu))
- [5. Docker部署(跨平台通用方案)](#5. Docker部署(跨平台通用方案))
- 三、Python整合Milvus:SDK安装与验证
-
- [1. 安装PyMilvus](#1. 安装PyMilvus)
- [2. 验证安装](#2. 验证安装)
- [3. PyMilvus核心接口分类](#3. PyMilvus核心接口分类)
- 四、Python操作Milvus核心流程
-
- [1. 连接Milvus服务](#1. 连接Milvus服务)
- [2. 数据库操作(创建/使用/删除)](#2. 数据库操作(创建/使用/删除))
- 五、Collection与Schema实战:静态+动态字段
-
- [1. 核心概念](#1. 核心概念)
- [2. 字段类型详解(常用)](#2. 字段类型详解(常用))
- [3. 静态Schema+Collection创建](#3. 静态Schema+Collection创建)
- [4. 动态Schema+Collection创建与数据插入](#4. 动态Schema+Collection创建与数据插入)
- [5. 关键参数说明](#5. 关键参数说明)
零基础学AI大模型之Milvus实战:Attu可视化安装+Python整合全案例
一、Attu可视化客户端:Milvus图形化管理利器
Attu是Zilliz团队专为Milvus向量数据库打造的开源图形化管理工具,核心价值是"让Milvus操作脱离命令行,降低学习与运维成本"。
核心特性
- 跨平台兼容:支持Windows、Linux、macOS三大系统,同时提供Docker镜像部署方案
- 开箱即用:无需编写任何代码,通过界面即可完成数据库、集合、索引的全生命周期管理
- 深度集成:与Milvus生态无缝衔接,由官方团队维护,功能迭代与Milvus版本同步
- 版本适配:需重点注意Attu与Milvus的版本匹配(当前实战环境:Milvus V2.5X,建议搭配Attu 2.5.X版本)
- 开源地址:https://github.com/zilliztech/attu
核心功能模块
- 数据库与集合管理:创建/删除数据库、定义集合字段(主键、标量、向量)、索引构建、数据导入导出
- 分区与分片优化:支持按业务维度(时间/用户组)划分分区,分片数可配置(默认2个,支持水平扩展)
- 向量检索能力:支持L2(欧氏距离)、余弦相似度等度量方式,结合标量过滤实现混合查询
- 资源与权限控制:加载/释放内存数据,多角色权限分配(全局权限、集合权限、用户权限)
二、Attu安装实战(跨平台适配)
Attu支持多种安装方式,以下是不同系统的最简部署流程,核心目标:通过"IP+端口"连接Milvus服务。
1. 前置条件
- 已部署Milvus服务(本地或远程,确保网络可通)
- Milvus服务端口默认19530(TCP端口)、9091(HTTP端口)
- 安装版本匹配:Milvus 2.5X → Attu 2.5.X(避免接口不兼容)
2. Windows系统安装
-
访问Attu GitHub Releases页面,下载Windows对应的exe安装包(如attu-windows-x64.exe)
-
双击安装包,按向导完成安装(默认路径即可,无需额外配置)
-
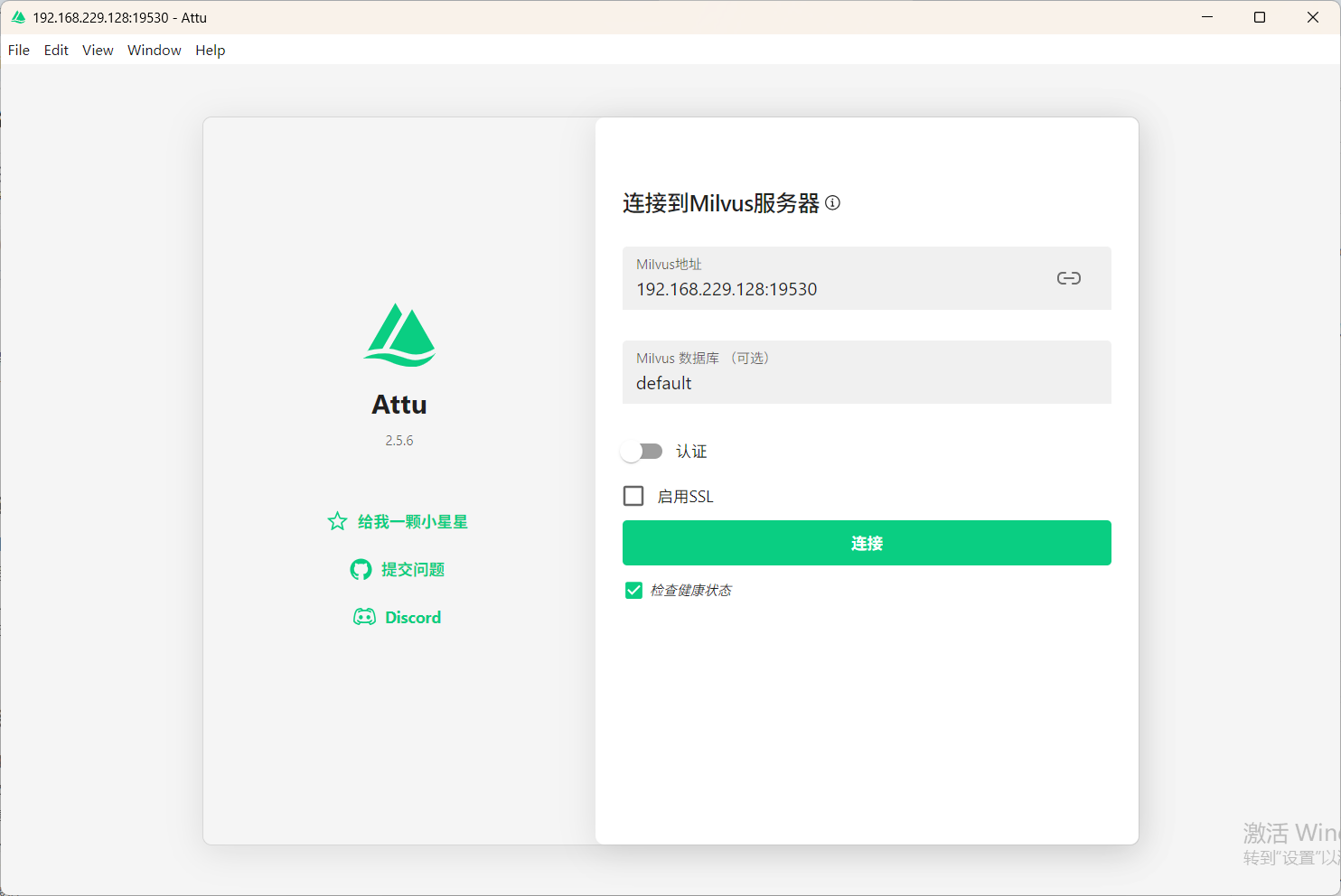
启动Attu,在连接页面输入:Milvus服务IP + 端口19530,点击"Connect"即可登录
3. macOS系统安装
- 下载macOS对应的dmg安装包(attu-macos-x64.dmg)
- 拖拽安装包到应用程序文件夹,完成安装
- 启动Attu,输入Milvus服务IP和19530端口,验证连接(若提示权限不足,右键选择"打开"即可)
4. Linux系统安装(Debian/Ubuntu)
- 下载deb安装包:wget https://github.com/zilliztech/attu/releases/download/v2.5.3/attu_2.5.3_amd64.deb(版本号可按需替换)
- 执行安装命令:sudo dpkg -i attu_2.5.3_amd64.deb
- 启动Attu:在终端输入attu,或通过应用列表启动,输入连接信息即可
5. Docker部署(跨平台通用方案)
- 拉取Attu镜像:docker pull zilliz/attu:v2.5.3
- 启动容器(映射本地8080端口,连接Milvus服务):
bash
docker run -p 8080:3000 -e MILVUS_URL=xxx.xxx.xxx.xxx:19530 zilliz/attu:v2.5.3- 访问界面:打开浏览器输入http://localhost:8080,输入Milvus连接信息登录
三、Python整合Milvus:SDK安装与验证
Milvus提供多语言SDK(Python/Node.js/GO/Java),其中Python SDK(PyMilvus)是最常用的开发工具,以下是实战步骤。
1. 安装PyMilvus
核心要求:PyMilvus版本需与Milvus服务器版本匹配(当前环境:Milvus 2.5X → PyMilvus 2.5.5)
bash
pip install pymilvus==2.5.52. 验证安装
执行以下命令,无报错则说明安装成功:
python
python -c "from pymilvus import Collection"3. PyMilvus核心接口分类
- DDL/DCL:创建/删除集合、分区,检查集合/分区是否存在(createCollection、dropCollection等)
- DML/Produce:数据插入、删除、更新操作
- DQL:向量搜索、标量查询、混合查询操作
四、Python操作Milvus核心流程
Python操作Milvus的核心链路:连接服务 → 数据库操作 → 集合操作 → 数据操作 → 检索查询,以下是关键步骤实战。
1. 连接Milvus服务
支持两种连接方式(推荐第二种MilvusClient,语法更简洁):
python
# 方式1:使用connections.connect(传统方式)
from pymilvus import connections, db
# 连接远程Milvus服务(替换为你的服务IP)
conn = connections.connect(host="192.168.229.128", port=19530)
# 方式2:使用MilvusClient(推荐,Milvus 2.3+支持)
from pymilvus import MilvusClient
client = MilvusClient("http://192.168.229.128:19530")2. 数据库操作(创建/使用/删除)
python
from pymilvus import connections, db
# 连接服务
connections.connect(host="192.168.229.128", port=19530)
# 1. 创建数据库(名称自定义)
db.create_database("my_rag_database")
# 2. 切换使用目标数据库
db.using_database("my_rag_database")
# 3. 列出所有数据库
all_dbs = db.list_database()
print("所有数据库:", all_dbs) # 输出:['default', 'my_rag_database']
# 4. 删除数据库(谨慎操作!)
db.drop_database("my_rag_database")五、Collection与Schema实战:静态+动态字段
Collection是Milvus中的"数据表",Schema定义表结构(字段类型、主键、向量维度等),支持静态字段和动态字段两种模式。
1. 核心概念
- Schema:集合的结构定义,由多个FieldSchema(字段定义)组成
- FieldSchema:单个字段的定义,包括名称、数据类型、是否为主键、向量维度等
- 静态Schema:字段固定,需提前定义所有字段(适用于数据结构稳定的场景,如用户画像)
- 动态Schema:支持新增未定义的字段(Milvus 2.3+支持,适用于日志、多变数据场景)
2. 字段类型详解(常用)
| 数据类型 | 说明 | 示例 |
|---|---|---|
| INT64 | 64位整型,常用作主键 | DataType.INT64 |
| VARCHAR | 变长字符串,需指定max_length | DataType.VARCHAR(max_length=50) |
| FLOAT | 单精度浮点数 | DataType.FLOAT |
| FLOAT_VECTOR | 浮点型向量,需指定dim(维度) | DataType.FLOAT_VECTOR(dim=128) |
3. 静态Schema+Collection创建
python
from pymilvus import connections, FieldSchema, DataType, CollectionSchema, Collection
# 1. 连接服务并切换数据库
connections.connect(host="192.168.229.128", port=19530)
db.using_database("my_rag_database")
# 2. 定义字段(静态Schema:所有字段提前声明)
fields = [
# 主键字段:id(自增或手动指定)
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
# 向量字段:dim=128(需与嵌入模型输出维度一致)
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128),
# 标量字段:文档标签
FieldSchema(name="doc_tag", dtype=DataType.VARCHAR, max_length=50)
]
# 3. 创建Schema(添加描述)
schema = CollectionSchema(
fields=fields,
description="RAG系统文档向量集合(静态字段)",
enable_dynamic_field=False # 关闭动态字段
)
# 4. 创建Collection(指定分片数,分布式场景关键)
collection = Collection(
name="static_doc_collection",
schema=schema,
shards_num=2 # 推荐值:集群节点数×2,单节点场景默认2即可
)
print("Collection创建成功!")4. 动态Schema+Collection创建与数据插入
动态Schema允许插入未定义的字段,灵活适配多变数据场景:
python
from pymilvus import connections, FieldSchema, DataType, CollectionSchema, Collection
# 1. 连接服务
connections.connect(host="192.168.229.128", port=19530)
db.using_database("my_rag_database")
# 2. 定义核心字段(仅声明必要字段)
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128)
]
# 3. 创建Schema(启用动态字段)
dynamic_schema = CollectionSchema(
fields=fields,
description="RAG系统动态字段集合",
enable_dynamic_field=True # 关键:开启动态字段
)
# 4. 创建Collection
dynamic_collection = Collection(
name="dynamic_doc_collection",
schema=dynamic_schema,
shards_num=2
)
# 5. 插入数据(包含未定义的动态字段color、doc_source)
data = [
{
"id": 0,
"embedding": [0.358, -0.602, 0.184, -0.263, 0.903], # 简化为5维示例
"color": "pink_8682",
"doc_source": "pdf_file_1.pdf"
},
{
"id": 1,
"embedding": [-0.334, -0.257, 0.899, 0.940, 0.538],
"color": "grey_8510",
"doc_source": "docx_file_2.docx"
}
]
# 插入数据(动态字段会自动作为键值对存储)
insert_result = dynamic_collection.insert(data=data)
print("数据插入成功,插入ID:", insert_result.primary_keys)5. 关键参数说明
- shards_num:分片数量,创建后不可修改,直接影响分布式扩展能力
- enable_dynamic_field:是否启用动态字段,Milvus 2.3+版本支持
- dim:向量维度,需与嵌入模型(如BERT、Sentence-BERT)输出的向量维度完全一致
如果觉得本文对你有帮助,欢迎点赞、收藏、关注~ 你的支持是我持续更新的动力!
