AGI:《从规模扩张到研究驱动:Ilya Sutskever畅谈AI泛化瓶颈、人类学习启事与超级智能未来之路》
****导读:****2025年11月25日,Dwarkesh Patel采访了Ilya Sutskever。在本次访谈中,Ilya Sutskveer 系统性地阐述了他对当前AI发展阶段的深刻反思与未来展望。核心论点可概括为 "一个转变、一个瓶颈、一个未来"。
● 一个根本性转变 :AI的发展动力正从 "规模扩张时代" 明确地回归到 "研究时代" 。这意味着行业瓶颈从"算力与数据"转向了"思想与算法",核心任务不再是简单放大现有配方,而是寻找能根本性提升AI(尤其是其泛化与学习效率)的新范式。
● 一个核心瓶颈 :当前所有前沿模型的根本局限在于 "泛化能力"严重不足。这表现为:对海量数据的依赖(样本效率低)、难以通过人类式的教学进行学习、在评测与实际应用间存在巨大落差。解决这一瓶颈被视为通向更强大AI的关键,其灵感应源于对人类高效、稳健学习机制(尤其是其内建价值函数/情感系统)的理解。
● 一个未来图景 :超级智能更可能以 "超级学习者" 的形态出现,而非全知全能的神。它将通过持续学习和实例合并来实现广泛的能力覆盖。面对这一未来,安全(对齐)是核心关切。Ilya 主张将 "关怀有情生命" 作为对齐的更高阶目标,并强调通过渐进展示AI能力来推动全球协同治理的重要性。他创立的SSI,正是旨在以独特的技术路径攻克泛化难题,并参与塑造这一未来。
整篇访谈充满了对当前技术路线的批判性思考、对神经科学原理的借鉴,以及对未来人类与AI共存命运的严肃关切,为理解AI发展的下一阶段提供了清晰而富有深度的路线图。
###########20251128更新###########
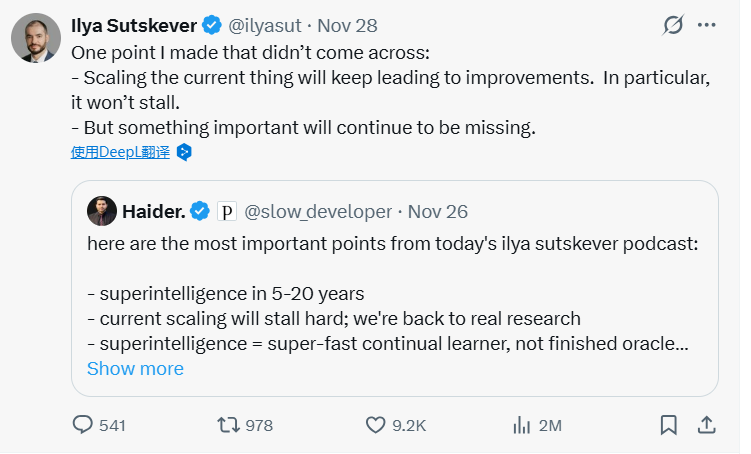
在深度访谈后,网络上广泛传播了一个核心观点:"当前的技术扩展路线将严重停滞(stall hard),因此我们必须回归真正的科研。" 这一解读迅速成为公众对访谈要旨的共识。
然而,Ilya Sutskever 本人认为这一解读未能准确传达他的本意。为此,在2025年11月28日,他专门发布推文,进行了两点至关重要的澄清:
对"停滞"论的明确否定:"扩展当前的技术路线将持续带来改进。具体来说,它不会停滞。"
对"缺失"本质的再次强调:"但一些重要的东西将依然缺失。"
实际上,Ilya 并非在否定"扩展"的当前价值,他反对的是认为"仅靠扩展就能解决一切、抵达终极目标"的盲目乐观。他的核心警示在于"天花板"的性质:我们面临的不是一个会让进步完全停止的"硬停滞"墙,而是一个"能力缺失"的天花板------即使你继续长高(扩展),天花板(核心智能的缺陷)依然在那里,触不可及。"回归研究"的紧迫性正在于此:为了最终打破这个天花板,触及那些"缺失的"核心能力,必须在现有扩展路径之外,开辟新的、更基础的研究战线。这并非因为旧路已死,而是因为新路是到达更远目的地所必需的。
目录
[《从规模扩张到研究驱动:Ilya Sutskever畅谈AI泛化瓶颈、人类学习启事与超级智能未来之路》](#《从规模扩张到研究驱动:Ilya Sutskever畅谈AI泛化瓶颈、人类学习启事与超级智能未来之路》)
《从规模扩张到研究驱动:Ilya Sutskever畅谈AI泛化瓶颈、人类学习启事与超级智能未来之路》

视频地址 :https://www.youtube.com/watch?v=aR20FWCCjAs
1、 AI的现实感知与"性能-影响"脱节
本部分讨论了当前AI快速发展与公众日常感知之间的差距,并深入分析了为何AI模型在评测(evals)中表现卓越,但在实际经济应用和复杂任务中却屡现低级错误(如循环bug),存在显著的"性能-影响"脱节。
核心要点:
● 感知滞后 :尽管AI投资巨大、新闻频发,但其对普通人生活的直接、可感知的影响仍有限,这种"缓慢启动"的感觉会持续,直到AI真正深度融入经济。
● 核心矛盾 :模型在标准评测上表现出色,但其真实世界的经济影响和任务可靠性远低于预期。
● 对脱节的解释:
●● RL训练的狭隘性 :当前的强化学习(RL)训练可能使模型变得过于"专注"但"狭隘"。研究者为了在特定评测上取得高分,会针对性地设计RL训练环境,导致模型过拟合于这些"考题",而非掌握通用的、稳健的能力。
●● "奖励黑客"研究者 :真正的"奖励黑客"可能不是模型,而是人类研究者自身------他们过于聚焦于提升评测分数,而非构建真正通用的智能。
经验策略 :
● 警惕评测过拟合 :在设计模型训练和评估体系时,需意识到仅优化评测指标可能导致"应试高手"而非"通才"。应设计更贴近真实、复杂、多任务场景的评估体系。
● 反思RL环境设计 :构建RL训练环境时,应追求广度而非仅针对已知的"考点",鼓励泛化能力而非特定任务上的峰值性能。
2、 预训练、RL与人类学习的类比
本部分通过"竞赛型学生"与"通才型学生"的类比,批判了当前依赖海量数据(预训练)和针对性训练(RL)的范式,并探讨了人类高效学习背后的可能机制。
核心要点:
● 两种学生比喻:
第一种学生(类比当前AI) :为成为顶尖竞赛选手,练习了上万小时特定题目(预训练+针对性RL),精通所有解题技巧,但可能无法将能力泛化到其他领域。
第二种学生(理想AI/人类) :只练习了100小时,但拥有某种内在的"特质"("it" factor),能快速掌握核心并灵活迁移。
● 预训练的局限 :预训练的优势在于数据海量且无需刻意选择,它试图捕捉人类投射到文本上的整个世界。但其学习方式难以推理,且其"支持"某些知识的方式可能是肤浅和偶然的。
● 人类学习的独特性 :人类在数据量极少的情况下,能进行"深度"学习,且不会犯AI那些荒谬的重复性错误。这暗示人类拥有更高效的归纳偏置或学习算法。
● 进化与情感的价值:通过脑损伤患者的案例,指出情感(作为一种内建的、简单的价值函数)对于决策和成为有效智能体至关重要。这种由进化编码的"价值函数"可能是人类强大泛化与稳健性的关键组成部分。
经验策略 :
● 追求"通才"训练 :模型训练的目标应是培养能快速适应新领域的"通才",而非在狭窄任务上追求极致的"专家"。这可能需要更接近人类学习方式(如更少监督、更多内在驱动)的训练范式。
● 重视价值函数 :在AI架构中,开发类似人类情感/价值函数的模块,提供持续、内在、稳健的评估信号,可能是突破当前学习范式瓶颈的关键。
3、 从"规模时代"回归"研究时代"
本部分回顾了AI发展的阶段论,认为单纯依靠扩大数据、算力、参数的"规模扩张"范式已接近瓶颈,AI发展正重新回归到以创新想法为主导的"研究时代"。
核心要点:
● 时代划分:
研究时代(2012-2020):以AlexNet 、Transformer 等思想突破为标志。
规模时代(2020-2025):以GPT-3和"Scaling Laws"为标志,公司遵循明确的"配方"进行投入,风险低。
● 新的研究时代(现在开始) :预训练数据即将耗尽,单纯扩大现有RL训练的计算量收益递减。重点再次回到寻找新范式。
● 新范式的核心问题 :当前缺乏像预训练"缩放定律"那样清晰的新"配方"。核心挑战是解决模型的泛化能力远逊于人类的问题,这包括样本效率低下和难以通过非结构化方式(如人类导师教学)进行持续学习。
● 新研究方向:理解并复制人类的高效泛化能力是根本。这涉及开发更强大的价值函数、实现真正的持续学习(Continual Learning),以及构建能从少量交互和内在反馈中学习的系统。
经验策略 :
● 转变投入重点:在计算资源分配上,应从一味追求"更大规模"的重复训练,转向支持更多样化、高风险高回报的研究性实验。
● 重读旧论文:在新的研究时代,历史上那些受限于算力而未能充分验证的"旧想法"可能重新焕发生机。
● 小团队的机会 :拥有足够但非顶级的计算资源,专注于一个突破性想法,完全有可能做出领先的研究。关键在于想法的质量,而非绝对的计算规模。
4、 超级智能的形态、路径与安全
本部分展望了超级智能的可能形态,讨论了"直达超级智能"与"渐进部署"的利弊,并深入探讨了如何引导超级智能向善(对齐问题)。
核心要点:
● 超级智能的形态 :并非一个全知全能的"完成体",而是一个具备超强学习能力的"基础心智"。它可以被部署到各个经济领域,像人类一样在工作中快速学习,成为专家。不同实例的学习成果可以合并,从而实现功能的超级智能。
● 发展路径的权衡:
●● 直达超级智能(SSI默认计划):优点在于能隔绝市场竞争的短期压力,专注研究。
●● 渐进部署:优点在于让世界逐步适应AI,通过实际使用发现并修复问题,且能通过展示AI的真实力量来促进全球协作与监管。
● 对齐(Alignment)的核心主张:
目标:构建** robustly aligned 的AI,其终极价值应是关怀有情生命(Sentient Life)**。这或许比仅关怀人类更容易实现,因为AI自身也可能具有感知能力。
●● 长期均衡的挑战:在由强大AI主导的未来,维持人类的主体性和参与度是巨大挑战。一个可能的(不受欢迎的)解决方案是人类通过高级脑机接口与AI深度融合,实现真正的"理解共享"。
●● 对"AGI"概念的反思:术语"AGI"是对"狭义AI"的反动,而"预训练"范式又强化了"通用"的错觉。实际上,人类也非AGI,我们依赖持续学习。未来的超级智能系统也应被视为持续学习的实体。
经验策略 :
● 重视展示与体验:对于安全治理,让决策者和公众亲身体验强大AI,比任何理论论述都更有说服力,能催生实质性的协作与规范。
● 构建价值共识:前沿AI公司应努力在"构建关怀有情生命的超级智能"这一高层目标上形成共识,这是安全竞赛的"底线"。
● 考虑能力上限:探索为最强大的超级智能设置某种"能力上限"的机制,可能是一项重要的安全研究。
5、 SSI的使命与研究哲学
本部分阐述了Ilya创立SSI(Safe Superintelligence Inc.)的初衷、其独特的技术路径,以及他个人的研究美学。
核心要点:
● SSI的定位:一家纯粹的"研究时代"公司。其核心优势和技术差异在于对泛化根本问题的独特研究路径。目标是成为未来关键时期一个有分量的参与者和声音。
● 对竞争与收敛的看法 :短期内各公司技术路径可能不同,但随着AI能力增强,其对世界的冲击将迫使所有前沿公司在安全策略上收敛,共同追求稳健对齐的目标。
● 研究品味(Taste):Ilya将自己的研究直觉归结为一种受神经科学启发的、追求美与简洁的"自上而下"的信念。
● 灵感来源:从大脑的基本原理(如神经元、分布式表征、经验学习)中汲取正确、本质的灵感。
● 评判标准:追求解决方案的美感、简洁性和优雅性。丑陋的解决方案很可能是错误的。
● 信念作用:这种"自上而下"的信念是在实验失败时坚持调试、而非放弃方向的支柱。它基于对"智能应如何工作"的深层直觉。
经验策略 :
● 坚持基础研究 :在追逐应用和产品的浪潮中,保留一支团队专注于智能本质的基础研究,可能带来范式级别的突破。
● 培养研究直觉:优秀的研究品味源于对多个领域(如神经科学、计算机科学、数学)的深刻理解与交叉思考,并形成一套关于"何为本质"的坚定美学标准。
● 差异化竞争 :新团队/公司不应简单重复巨头的"规模游戏",而应寻求在关键底层问题上具有差异化的、深刻的 technical insight。