能不用分布式事务就不用!!!
分布式事务演进
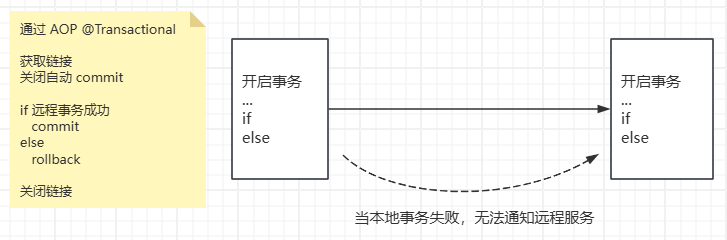
从传统的调用上来看,发起方事务失败,是无法通知接收方的;
有人可能会说:接收方挂起,等待发起方通知?
那么谁来通知发起方:接收方是否执行成,这不形成死锁了?
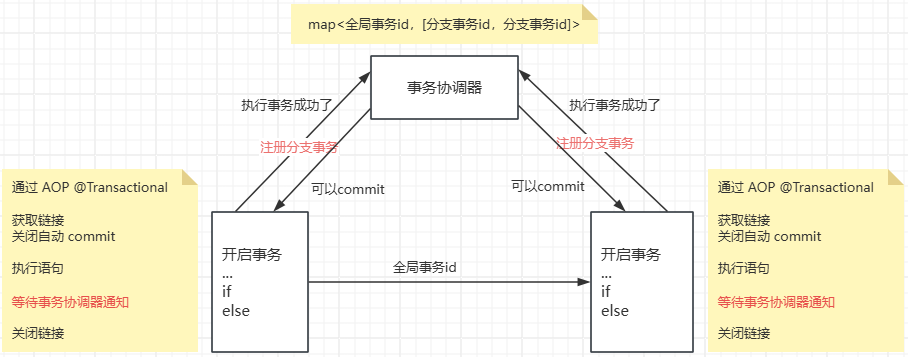
引入了事务协调器,来服务通知大家,是否可以进行最后的 commit。
2PC 是一种分布式事务思想
XA是数据库层面的实现;
TCC是业务层面的实现;
DTP模型
XA
适用于并发不高,或者必须保证强制一性 时使用;
基于数据库,会进行数据行锁定,所以不利于高并发场景使用;
文档,开发人员操作简单,开发成本低;
TCC
侵入式开发,基于业务逻辑的事务操作方案,通过新增额外表字段实现事务提交和回滚,
如,库存100,减少 10,原字段还是100,额外字段变成10,
如果成功,进行 100 -10 = 90,失败 额外字段清0
隔离性较低
-
空回滚
-
问题描述: 当一个 Try 方法因网络超时、服务宕机等原因没有被执行,但全局事务已经开启,事务管理器会直接发起回滚,调用 Cancel 方法。此时,Cancel 方法需要能够识别出"Try 未执行"的情况,并做相应的空补偿,否则会报错或误删数据。
-
旧版本困境: 在早期版本中,开发者需要在自己的业务代码中手动实现防悬挂和空回滚的逻辑,通过查询事务控制表等方式来判断 Try 是否已执行。这非常繁琐,且容易出错。
-
-
悬挂
-
问题描述: 与空回滚相对。在空回滚发生后,那个原本未执行的 Try 请求可能又到达了服务端并执行成功。这样一来,业务资源被预留(Try 执行了),但整个全局事务已经回滚,再也没有后续的 Confirm 或 Cancel 来清理这个资源,导致资源一直被占用,即"悬挂"。
-
旧版本困境: 同样需要开发者手动处理,通过记录空回滚的记录,在 Try 执行时进行检查。
-
-
幂等性
-
问题描述: 由于网络问题,事务管理器可能会重复调用 Confirm 或 Cancel 方法。业务服务必须保证这些方法被多次调用时,产生的结果与调用一次相同。
-
旧版本困境: 幂等性保障完全由业务开发者实现,通常需要通过数据库唯一索引或状态机来保证,增加了开发的复杂度和心智负担。
-
消息中间件
生产订单的同时生产消息记录;这两部操纵基于数据库保证原子性和一致性,
如果发送消息失败,基于定时任务 轮询发送失败的消息,通知其他服务,
但是其他服务执行失败,订单服务无法感知,需要人工补偿。
saga
长事务解决方案,无隔离性