摘要
承接《Spring Cloud Alibaba 核心理论体系》的微服务架构基础,本文基于 Spring Cloud Alibaba + Seata + 腾讯云 TDSQL,构建一套可直接上生产的微服务事务分级治理方案。清晰界定 Seata 跨服务事务与 TDSQL 集群内事务的定位,纠正分片 / 分区、锁机制等常见误区,衔接前文理论,补齐微服务架构中事务治理的落地短板,实现理论与实践的闭环。
一、事务分级治理的核心原理
1.1 分级治理的本质:打破「一刀切」的事务设计
微服务架构下,不同业务链路对「一致性」和「性能」的诉求天然分层:
- 支付 / 订单核心链路:需 强一致 ,可接受一定性能损耗;
- 物流 / 通知非核心链路:可接受 最终一致 ,需极致性能;
- 单一分布式数据库场景:可依托数据库内核实现 高性能强一致 ,无需应用层协调。
事务分级治理的核心 :按「一致性等级 + 性能等级 + 架构层级」划分治理规则,让 Seata(应用层)、腾讯云 TDSQL(数据库层)各司其职,而非用一种方案覆盖所有微服务场景。
1.2 分级治理的三层架构模型
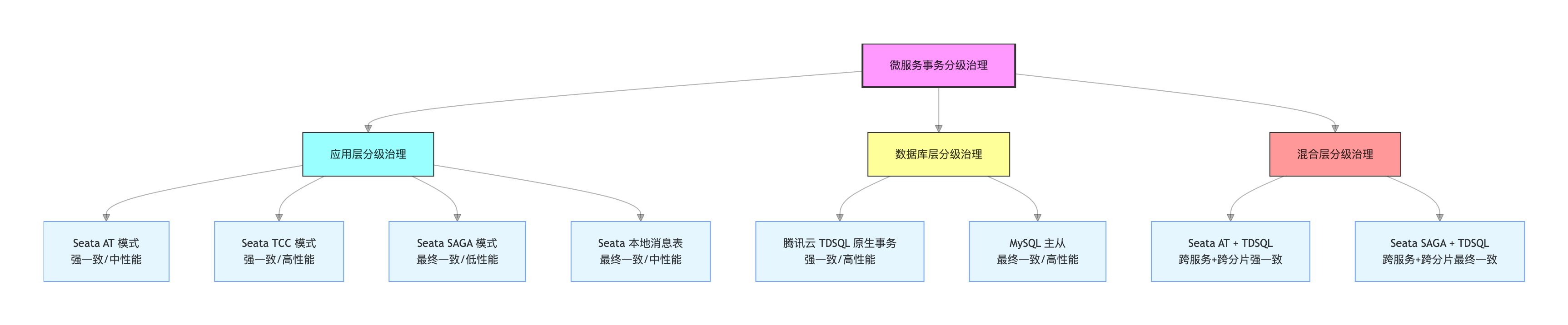
1.3 Seata 分级治理的核心适配规则
Seata 不同模式的分级适配,本质是「一致性协议 + 锁机制 + 补偿逻辑」的分层设计,适配不同微服务场景的诉求:
|--------------|-----------|----------------|-----------------------|--------------------------|---------------|
| Seata 模式 | 一致性协议 | 锁机制 | 补偿逻辑 | 核心原理 | 分级定位 |
| AT 模式 | 改良版 2PC | 应用层全局锁 + 数据库行锁 | 基于 undo_log 自动补偿 | 一阶段本地提交,二阶段异步清理 / 回滚 | 一级事务(核心链路强一致) |
| TCC 模式 | 柔性 2PC | 无锁(业务预扣减) | 手动 Try/Confirm/Cancel | 拆解事务为「预留 - 确认 - 取消」,无锁阻塞 | 一级事务(高并发核心链路) |
| SAGA 模式 | 最终一致性 | 无锁 | 手动正向 / 反向补偿 | 状态机驱动长事务,支持分支异步执行 | 二级事务(长流程最终一致) |
| 本地消息表 | 最终一致性 | 无锁 | 基于消息重试补偿 | 本地事务 + 消息队列,异步保证最终一致 | 二级事务(非核心链路) |
1.4 Seata vs 腾讯云 TDSQL 分级治理核心差异
明确:本文对比的是 腾讯云 TDSQL(MySQL 版) ,其核心优势是「运维简单、低维护成本、兼容 MySQL 生态」,事务机制并非原生 2PC,而是基于「全局事务管理器(GTM)+ 分片事务协调」实现:
|----------|----------------------------------|-----------------------------------|
| 对比维度 | Seata(应用层分级) | 腾讯云 TDSQL(数据库层分级) |
| 一致性协议 | 应用层 2PC/TCC/SAGA | 数据库层「GTM 协调 + 分片事务」(非原生 2PC) |
| 核心协调组件 | TC 集群(应用层独立部署) | 全局事务管理器(GTM,TDSQL 集群内置) |
| 锁机制 | 应用层全局锁(AT)/ 无锁(TCC/SAGA) | 数据库跨分片行锁(内核自动协调) |
| 补偿逻辑 | 应用层自动 / 手动补偿 | 数据库内核自动回滚(基于自身 undo 日志) |
| 网络开销 | 多轮应用层 RPC(TC-RM-TM) | 数据库内部分片同步(GTM 轻量协调,开销极低) |
| 适配范围 | 跨微服务、跨异构数据源(MySQL/Redis/MongoDB) | 单一 TDSQL 集群、跨分片(无跨微服务适配能力) |
| 侵入性 | 应用层低侵入(AT)/ 高侵入(TCC/SAGA) | 应用层无侵入(完全兼容 MySQL 语法,无需改微服务代码) |
| 运维成本 | 需维护 Seata TC 集群、RM 客户端配置 | 极低(腾讯云托管,自动部署、主从切换、故障自愈,无需专业 DBA) |
| 学习成本 | 需掌握 Seata 不同模式的适配规则、配置优化 | 极低(与使用单机 MySQL 完全一致,微服务开发无需额外学习) |
1.5 腾讯云 TDSQL 事务原理补充
TDSQL 事务的生效范围覆盖整个集群内的所有表操作 (并非仅单表跨分片),按场景分为两类:
- 本地事务 :同一分片内的单表 / 多表操作 → 完全兼容原生 MySQL 事务,无需 GTM 干预;
- 分布式事务 :跨分片的单表 / 多表操作 → 虽然采用两阶段流程,但并非标准 2PC,由 GTM 协调实现一致性,采用 "本地提交 + 异步标记" 的两阶段流程(非标准 2PC),规避了标准 2PC 的长锁、同步阻塞、性能差等问题。
1.5.1 TDSQL 事务执行时序图
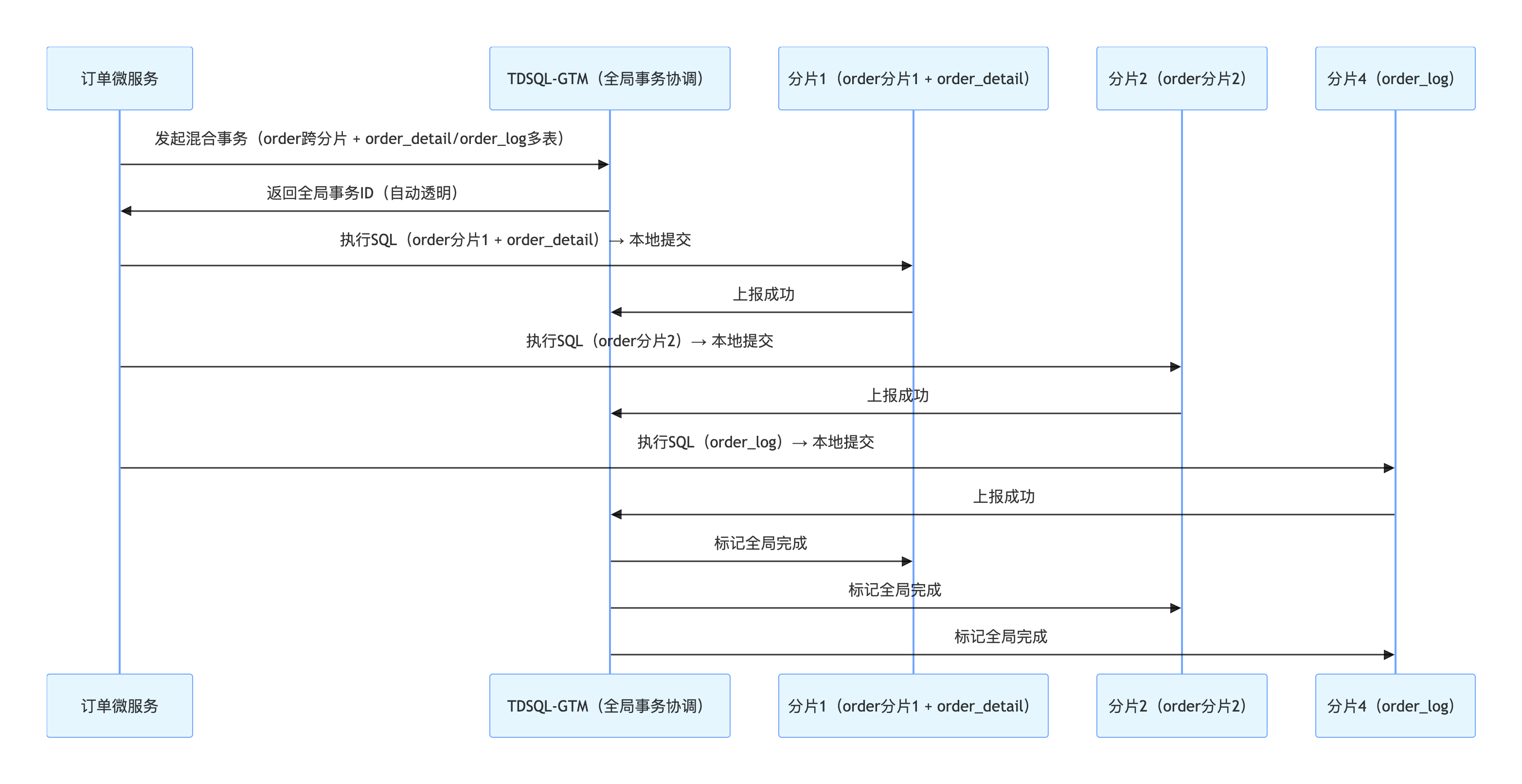
1.5.2 TDSQL(GTM + 分片)与标准 2PC 本质区别
标准 2PC 的致命问题:
- 一阶段不提交,只锁定资源
- 所有节点必须等最慢节点
- 任何一节点卡住 → 全局阻塞
- 锁持有时间极长 → 高并发直接崩
|----------|------------------------|-----------------------|
| 对比维度 | 标准 2PC | TDSQL(GTM + 分片事务) |
| 一阶段行为 | 仅 Prepare,不提交、不释放锁 | 直接本地提交 ,立即释放锁 |
| 二阶段行为 | 全局提交 / 回滚,同步阻塞 | 仅做状态标记 ,无锁、无阻塞 |
| 锁持有时长 | 极长(全程持有) | 极短(仅本地事务期间) |
| 协调器挂掉影响 | 全局阻塞、资源死锁 | 分片已提交,数据不丢、业务不堵 |
| 性能表现 | 差,高并发不可用 | 接近单机事务 ,高并发友好 |
| 本质定位 | 强一致、同步阻塞协议 | 高性能、最终一致 / 强一致兼顾 |
二、微服务事务分级治理的场景化
2.1 一级事务:核心链路强一致(AT/TCC 模式)
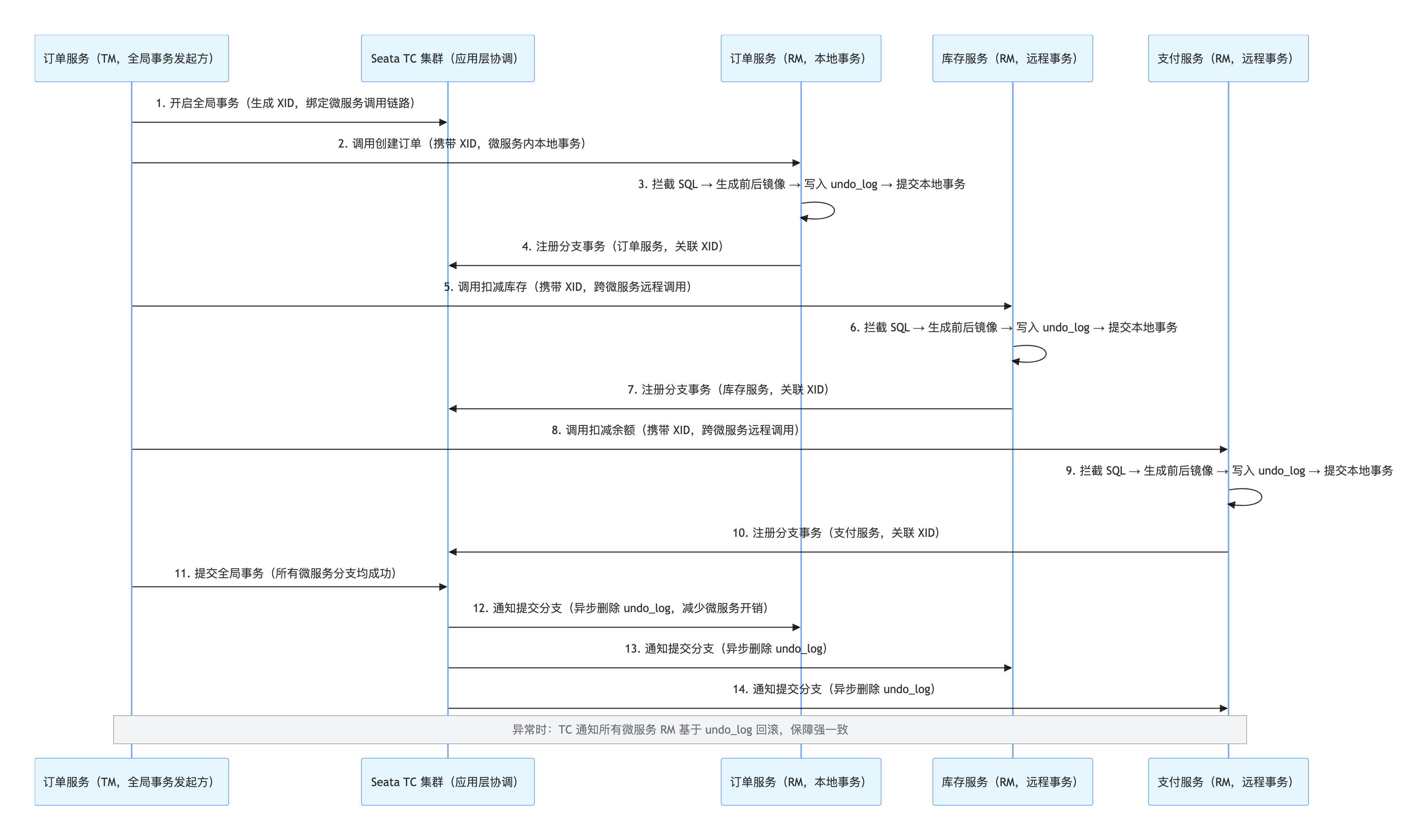
2.1.1 场景 1:订单 + 库存 + 支付(普通高并发)→ Seata AT 模式
业务特征 :跨 3 个微服务(订单服务、库存服务、支付服务)、跨 MySQL 实例、一致性要求 100%、QPS 约 1000,属于微服务核心交易链路。
AT 模式时序图 :
优劣分析 :
- ✅ 优势:应用层低侵入(微服务仅需加 @GlobalTransactional 注解)、自动补偿(无需微服务开发手动写补偿逻辑)、适配跨异构数据源(如订单用 MySQL,库存用 Redis);
- ❌ 劣势:全局锁导致高并发下锁冲突、多轮微服务 RPC 调用存在性能损耗(TPS 比 TDSQL 低 20%-30%)、需微服务团队维护 Seata TC 集群;
- 🎯 适配性:适合中小并发微服务核心链路,微服务团队开发成本低,且存在跨微服务、跨异构数据源的场景。
2.1.2 场景 2:秒杀下单(超高并发)→ Seata TCC 模式
业务特征 :单微服务 / 跨微服务、QPS 超 10000、一致性要求 100%、对锁冲突敏感,属于微服务超高并发核心链路(如电商秒杀、限时抢购)。
TCC 模式核心逻辑 :
- Try:预扣减库存(冻结库存,无锁)、预冻结用户余额(微服务内业务逻辑,不直接操作最终数据);
- Confirm:确认扣减库存、确认扣减余额(Try 成功后,执行最终数据更新);
- Cancel:解冻库存、解冻余额(Try 失败后,回滚预操作,保障数据一致)。
优劣分析 :
- ✅ 优势:无全局锁、无阻塞、高性能(TPS 接近单机事务,适配微服务超高并发)、可灵活适配复杂业务逻辑;
- ❌ 劣势:应用层高侵入(微服务开发需手动写 Try/Confirm/Cancel 三个方法)、补偿逻辑需保证幂等(避免微服务重试导致的数据异常)、开发成本高;
- 🎯 适配性:适合超高并发微服务核心链路(如秒杀、限时抢购),微服务团队需具备一定开发能力,且存在跨微服务场景。
2.1.3 场景 3:单应用内 多 表 操作 → 腾讯云 TDSQL 原生事务方案
业务特征 :无跨微服务(仅单订单微服务)、同一个 TDSQL 集群 / 同一个逻辑库内、QPS 超 5000、一致性要求 100%、追求低运维成本,属于微服务单应用跨分片核心场景。TDSQL 事务时序图 :
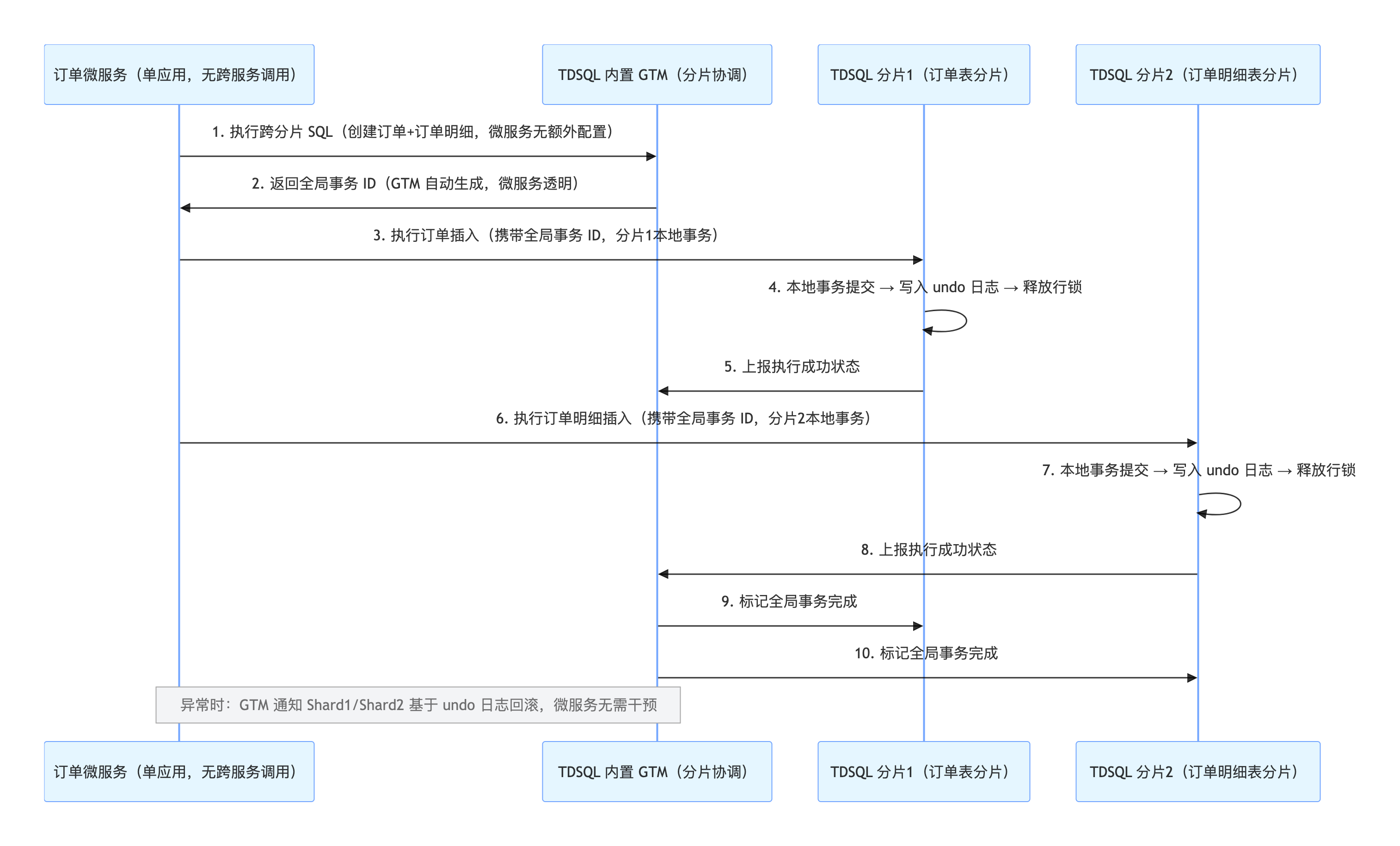 优劣分析 :
优劣分析 :
- ✅ 优势:
- 性能最优(无应用层协调,仅 GTM 轻量干预,TPS 比 Seata AT 高 20%-30%);
- 应用层无侵入(微服务无需改代码、无需加注解,与单机 MySQL 用法一致,开发成本极低);
- 运维成本极低(腾讯云托管,自动部署、主从切换、故障自愈,无需微服务团队配备专业 DBA,仅需关注分片规则);
- 一致性可靠(GTM 协调,数据库内核级回滚,无微服务数据不一致风险);
- ❌ 劣势:
- 无法跨微服务适配(只限于 同一个 TDSQL 集群内);
- 无法跨异构数据源(仅支持自身集群,不能适配微服务中常用的 Redis、MongoDB 等);
- 🎯 适配性:适合微服务单应用场景(无跨服务、无异构数据源),追求高性能、低运维成本,微服务团队不想投入精力维护 Seata 集群。
2.2 二级事务:非核心链路最终一致(SAGA / 本地消息表)
2.2.1 场景 1:订单创建 + 物流通知 + 短信推送 → Seata SAGA 最终一致性方案
业务定位 :
- 主流程:订单创建(必须成功,微服务核心数据)
- 辅助流程:物流通知、短信推送(允许短暂失败,最终一致,非核心链路)
- 一致性要求:最终一致
- 核心禁忌:订单创建成功后,不允许因为短信 / 物流失败而回滚订单(SAGA 最终一致核心原则)
SAGA 模式正确状态机图 :
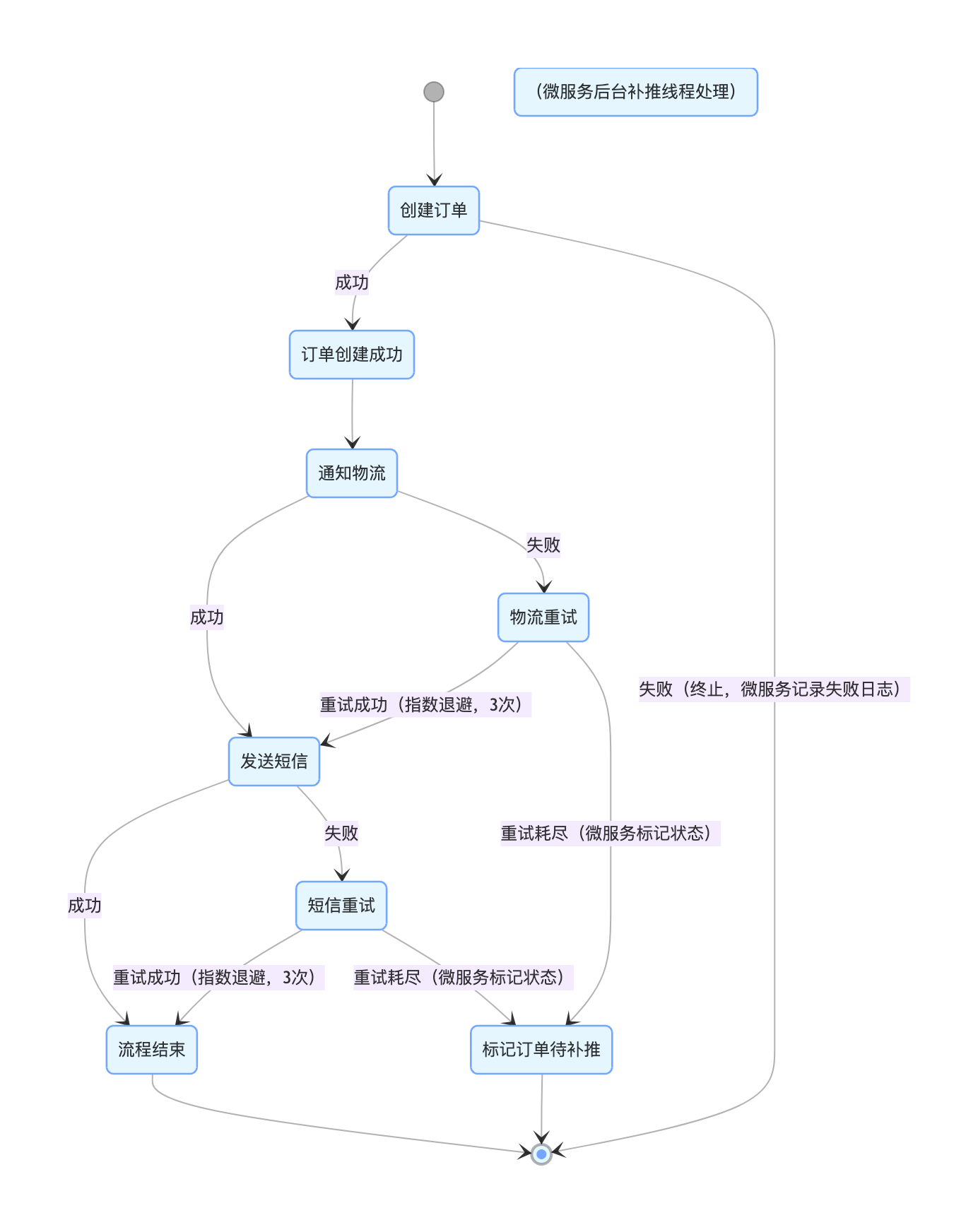
SAGA 模式正确设计原则 :
- 已创建的订单不回滚:订单是微服务核心实体数据,一旦创建成功,就不允许因为通知类服务失败而删除或回滚,避免微服务数据丢失;
- 通知类环节只重试、不回滚:物流、短信属于微服务辅助流程,失败后仅执行重试(3~5 次,指数退避),重试耗尽后标记状态、进入待补推,不影响主流程;
- SAGA 只回滚 "可撤销操作":如微服务中的库存扣回、金额解冻,不回滚订单创建、用户记录、日志等不可撤销的核心数据;
- 最终一致 = 最终会成功,不是立刻成功:通过微服务后台补推线程、人工介入,确保辅助流程最终完成,实现整体链路最终一致。
优劣分析 :
- ✅ 优势:支持长事务、无锁、可异步执行、失败可重试、适配跨微服务长流程、不阻塞微服务主流程;
- ❌ 劣势:性能低(多轮补偿,一致性窗口大)、补偿逻辑复杂(微服务需开发重试、补推、状态标记逻辑)、需维护 SAGA 状态机配置;
- 🎯 适配性:适合微服务长流程、非核心链路(如物流通知、短信推送),对实时性要求低,且存在跨微服务场景。
2.2.2 场景 2:订单日志同步 + 数据统计(低并发)→ Seata 本地消息表
业务特征 :单微服务 / 跨微服务、QPS 低于 100、可接受分钟级最终一致、开发成本要求低,属于微服务非核心链路(如日志同步、数据统计)。
优劣分析 :
- ✅ 优势:开发成本极低(微服务仅需新增消息表,无需引入额外中间件)、无额外组件依赖、稳定性高、适配微服务低并发场景;
- ❌ 劣势:一致性窗口大(分钟级)、需微服务开发手动清理消息表、性能一般;
- 🎯 适配性:适合微服务低并发、非核心链路(如日志同步、数据统计),追求极简开发,无需投入过多维护成本。
2.3 混合层事务:跨微服务 + 同一 TDSQL 集群内多表 / 跨分片 → Seata + 腾讯云 TDSQL
场景:订单跨微服务 + 同一 TDSQL 集群内多表 / 跨分片(核心链路)
业务特征 :跨 2 个微服务(订单服务 + 库存服务)、订单侧在同一个 TDSQL 集群内、一致性要求 100%、QPS 约 2000、追求高性能 + 低运维成本,属于微服务复杂核心链路。
核心优化逻辑 :
- 分工明确:Seata 负责跨微服务全局事务协调(订单服务→库存服务),TDSQL 负责本集群内所有表的事务(多表、同分片、跨分片都支持);
- 性能优化:Seata AT 模式关闭全局锁(避免与 TDSQL 内核锁冲突,减少双重锁开销,提升微服务接口性能);
- 运维优化:Seata TC 集群轻量化部署(3 节点),TDSQL 依托腾讯云托管,整体运维成本可控,降低微服务团队运维压力;
- 配置优化:Seata 事务分组与 TDSQL 分片规则对齐,避免跨分片无效协调,同时开启 Seata 异步提交,减少二阶段阻塞,提升微服务接口响应速度。
优劣分析 :
- ✅ 优势:兼顾跨微服务适配性和数据库层性能,运维成本低于「Seata+MySQL 分库分表」,一致性可靠,适配微服务复杂核心链路;
- ❌ 劣势:架构复杂度高于单一 Seata/TDSQL 方案,需微服务团队协调 Seata 与 TDSQL 的配置(如事务超时时间、分片规则);
- 🎯 适配性:适合微服务复杂核心链路,微服务团队具备基础架构设计能力,追求高性能与低运维成本的平衡。
2.4 全场景分级治理选型表
|-------------------------------------------|-----------|----------|----------------------|---------------------------------------------------------------------|---------------------------------------------|-------------------------------|-------------------------------------------|
| 微服务业务场景 | 一致性等级 | 性能要求 | 推荐方案 | 核心优势(功能 + 工程化) | 核心劣势 | 运维成本 | 适配微服务场景 |
| 订单 + 库存 + 支付(1000 QPS,跨微服务 + MySQL) | 强一致 | 中 | Seata AT | 1. 功能:低侵入、自动补偿、适配跨微服务;2. 工程化:开源成熟、适配所有 MySQL 场景 | 1. 性能:锁冲突、TPS 下降 30%+;2. 稳定性:高并发易超时 | 中(需维护 Seata TC 集群 + MySQL 运维) | 中小并发核心跨微服务链路(无高性能 / 低运维诉求) |
| 秒杀下单(10000 QPS,跨微服务) | 强一致 | 高 | Seata TCC | 1. 功能:无锁、高性能、适配超高并发;2. 工程化:可定制化强、支持流量削峰 | 1. 开发:高侵入、补偿逻辑复杂;2. 维护:需设计幂等 / 防悬挂 | 中(需维护 Seata TC 集群 + TCC 状态机) | 超高并发核心跨微服务链路(能接受开发成本) |
| 单应用内多表 / 跨分片下单(5000 QPS,无跨微服务 + TDSQL 集群) | 强一致 | 高 | 腾讯云 TDSQL 原生事务 | 1. 功能:集群内所有表事务生效(多表 / 同分片 / 跨分片);2. 工程化:性能接近单机、零代码侵入、托管运维、高稳定 | 1. 能力:无法跨微服务 / 异构数据源;2. 成本:云服务有一定费用 | 极低(仅关注业务逻辑,无需维护分片 / 事务) | 单微服务高并发核心链路(追求高性能 / 低运维) |
| 订单 + 物流 + 短信(长流程,跨微服务) | 最终一致 | 低 | Seata SAGA | 1. 功能:支持长事务、无锁、可重试;2. 工程化:适配非核心链路、容错性强 | 1. 一致性:窗口大、数据可能暂时不一致;2. 开发:补偿逻辑复杂 | 中(需维护 SAGA 状态机) | 长流程非核心跨微服务链路(可接受最终一致) |
| 订单日志同步(100 QPS,低并发) | 最终一致 | 低 | Seata 本地消息表 | 1. 功能:开发成本低、稳定可靠;2. 工程化:无需额外组件、运维简单 | 1. 一致性:窗口大;2. 维护:需定期清理消息表 | 低(无额外组件,仅清理消息表) | 低并发非核心微服务链路(追求极简开发) |
| 跨微服务 + TDSQL 集群内多表 / 跨分片(2000 QPS,核心链路) | 强一致 | 中高 | Seata AT + 腾讯云 TDSQL | 1. 功能:兼顾跨微服务 + TDSQL 集群内所有表事务;2. 工程化:性能比纯 Seata 高 40%、运维成本降 60%、高稳定 | 1. 架构:略复杂,需协调 Seata+TDSQL 配置;2. 成本:云服务有一定费用 | 中低(TDSQL 托管 + Seata 轻量化部署) | 复杂核心链路(部分微服务用 TDSQL、部分用 MySQL,追求性能 + 低运维) |
三、微服务事务分级治理的落地实战
3.1 实战环境说明
- 框架:Spring Cloud Alibaba
- 注册 / 配置中心:Nacos
- 分布式事务:Seata 1.6+
- 数据库:MySQL + 腾讯云 TDSQL(MySQL 版)
- 核心思想:同一 TDSQL 集群内所有多表 / 跨分片,都走 TDSQL 原生事务; 跨微服务、跨库场景由 Seata 统一协调。
3.2 一级事务:Seata AT 模式(跨微服务 + 普通 MySQL)
3.2.1 场景说明
- 跨微服务:订单服务 → 库存服务
- 数据库:普通 MySQL
- 特点:低侵入、开箱即用、适合中小并发核心链路
3.2.2 核心配置(application.yml)
java
spring:
application:
name: order-service
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
alibaba:
seata:
tx-service-group: order_tx_group
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/order_db?useUnicode=true&serverTimezone=UTC
username: root
password: root
seata:
registry:
type: nacos
nacos:
server-addr: 127.0.0.1:8848
group: SEATA_GROUP
config:
type: nacos
service:
vgroup-mapping:
order_tx_group: default3.2.3 核心代码
java
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private StockFeignClient stockFeignClient;
@GlobalTransactional(rollbackFor = Exception.class)
@Override
public Result<OrderVO> createOrder(OrderDTO orderDTO) {
// 1. 订单表插入(本地 MySQL)
OrderDO orderDO = new OrderDO();
orderMapper.insert(orderDO);
// 2. 跨微服务扣减库存(Seata 全局事务)
Result<Boolean> stockResult = stockFeignClient.deductStock(
orderDTO.getProductId(), orderDTO.getNum());
if (!stockResult.isSuccess() || !stockResult.getData()) {
throw new BusinessException("库存扣减失败");
}
OrderVO vo = new OrderVO();
BeanUtils.copyProperties(orderDO, vo);
return Result.success(vo);
}
}3.3 二级事务:腾讯云 TDSQL 原生事务(单应用内多表 / 跨分片)
3.3.1 场景说明
- 单应用、无跨微服务
- 同一 TDSQL 集群内操作多张表 (订单表、订单明细表、日志表等)
- 表可能是:同分片、单表跨分片、多表跨分片
- 事务完全由 TDSQL 保证,无需 Seata
- 特点:性能接近单机、零侵入、运维极低
3.3.2 核心配置
java
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://tdsql-xxx.tencentcdb.com:3306/order_db?useUnicode=true&serverTimezone=UTC
username: tdsql_user
password: tdsql_pwd3.3.3 核心代码(和单机 MySQL 完全一样)
java
@Service
public class OrderTdsqlServiceImpl implements OrderTdsqlService {
@Autowired
private OrderTdsqlMapper orderMapper;
@Autowired
private OrderDetailTdsqlMapper detailMapper;
@Transactional(rollbackFor = Exception.class)
@Override
public Result<OrderVO> createOrderInTdsql(OrderDTO orderDTO) {
// ==============================
// TDSQL 内部:多表 + 可能跨分片
// 事务由 TDSQL 原生保证原子性
// ==============================
OrderDO order = new OrderDO();
orderMapper.insertOrderShard(order); // 可能跨分片
detailMapper.insertDetail(order.getId()); // 同分片/跨分片都可以
OrderVO vo = new OrderVO();
BeanUtils.copyProperties(order, vo);
return Result.success(vo);
}
}要点:代码和单机 MySQL 完全一致,无需任何分布式改造, TDSQL 自动处理跨分片、多表事务。
3.4 三级事务:混合层事务 ------ Seata + 腾讯云 TDSQL(真正生产级)
3.4.1 场景定位
- 跨微服务:订单 + 库存
- 订单侧:腾讯云 TDSQL(多表 / 跨分片)
- 库存侧:普通 MySQL
- 目标:
- Seata 只做跨微服务协调
- TDSQL 全权负责自身集群内事务(多表 / 跨分片)
- 性能 > 纯 Seata,运维 < 纯分库分表
这不是 "叠加组件",而是 架构分层治理 :应用层管服务,数据层管数据。
3.4.2 混合事务核心思想
- Seata:负责服务之间 的全局事务边界
- TDSQL:负责订单库内部 所有表的事务(多表、同分片、跨分片都支持)
- 不重复造锁、不重复造事务,性能最优、稳定性最强
3.4.3 核心代码
java
@Service
public class OrderMixServiceImpl implements OrderMixService {
@Autowired
// TDSQL 数据源
@DataSource("tdsql")
private OrderTdsqlMapper orderMapper;
@Autowired
private StockFeignClient stockFeignClient;
@GlobalTransactional(rollbackFor = Exception.class)
@Override
public Result<OrderVO> createOrderMix(OrderDTO orderDTO) {
// ==============================
// 1. TDSQL 内部:多表 + 跨分片
// 事务由 TDSQL 保证
// ==============================
OrderDO order = new OrderDO();
orderMapper.insertOrderShard(order);
orderMapper.insertOrderDetailShard(order.getId());
// ==============================
// 2. 跨微服务:Seata 负责
// ==============================
Result<Boolean> stockResult = stockFeignClient.deductStock(
orderDTO.getProductId(), orderDTO.getNum());
if (!stockResult.isSuccess() || !stockResult.getData()) {
throw new BusinessException("库存不足,全局回滚");
}
OrderVO vo = new OrderVO();
BeanUtils.copyProperties(order, vo);
return Result.success(vo);
}
}3.5 三种实战方案对比总结
|---------------|-------------------------|--------|--------|--------|-----------|
| 方案 | 负责范围 | 性能 | 侵入 | 运维 | 适用场景 |
| Seata AT | 跨微服务 + 普通 MySQL | 中 | 低 | 中 | 中小并发、跨服务 |
| TDSQL 原生 | 单应用 + TDSQL 内多表 / 跨分片 | 极高 | 0 | 极低 | 单应用高并发核心库 |
| Seata + TDSQL | 跨微服务 + TDSQL 内部多表 / 跨分片 | 高 | 低 | 中低 | 生产级核心链路 |
3.6 实战核心结论
- 微服务事务一定要分级 :跨服务用 Seata,单应用大库用 TDSQL。
- TDSQL 不是 Seata 的替代品,而是互补 :TDSQL 解决数据层分片、多表、高性能事务 ;Seata 解决应用层服务间分布式事务 。
- 同一 TDSQL 集群内,所有表天然在一个事务里 ,无需手动处理分片、分区、多表问题。
- 混合层(Seata + TDSQL)是真正生产落地的最优架构 ,而非演示 Demo。
四、分级治理的生产级优化
4.1.1 一级事务:Seata AT 模式核心优化点
1. 精准控制全局事务范围
- 只把 "必须强一致" 的核心逻辑(下单、扣库存)放入 @GlobalTransactional;
- 非核心逻辑(日志、统计)移出全局事务,改用最终一致。
2. 差异化控制全局锁(避免安全漏洞)
- 核心数据(订单、库存):保留全局锁,开启锁重试;
- 非核心数据(日志、统计):用 lockRetryInternal = -1 关闭锁重试,或移出全局事务。
3. 合理设置事务超时
- 建议 3~5s,禁止默认超大超时,避免长事务占锁。
4. 必须定期清理 Seata undo_log 表
- 配置 Seata 自动清理(保留 7 天),加定时 SQL 脚本兜底;
- 注意:清理的是 Seata 框架的 undo_log,不是数据库内核的 undo log。
5. Seata TC 集群轻量化部署
- 3 节点足够,用 Nacos 实现自动故障转移,避免过度扩容。
4.2.1 分片与事务优化
1. 分片键选择遵循 "事务内收敛" 原则
- 优先选择 order_id、user_id 这类贯穿整个事务的关键字段 。
- 目标:让同一事务的多张表数据尽量落在同一片面 ,减少分布式事务触发。
2. 禁止超大跨分片事务
- TDSQL 虽支持多表 / 跨分片事务,但批量更新、全表更新会加重 GTM 协调压力。
- 生产拆分为小事务,避免单事务超过 1000 行。
3. 利用日期分区提升性能(不影响事务)
- 单分片内部可按日期分区,用于快速查询、快速清理历史数据。
- 分区不影响分布式事务 ,只属于单机优化。
4. 高并发下关闭不必要的外键与约束
- 由业务层保证逻辑一致性,降低数据库内部校验开销。
5. 内网访问 + 连接池合理调优
- TDSQL 必须走内网,降低事务 RT。
- 连接数按业务压测设置,避免频繁创建销毁连接。
4.3.1 三级事务:混合层核心优化点
- 严格职责隔离
- Seata:只管理跨微服务调用边界(库存、支付);
- TDSQL:全权管理集群内多表 / 跨分片事务(订单、明细表)。
2. 事务超时严格对齐
- Seata 全局超时(8s)> TDSQL 事务超时(6s);
- 避免 TDSQL 先回滚,Seata 跨服务调用还在执行导致数据不一致。
3. 只在核心链路使用混合事务
- 非核心链路(通知、日志)用最终一致,缩小强一致范围。
4. 业务设计上减少跨分片
- 分片键选 order_id/user_id,让同一事务数据尽量落在同分片,减少分布式事务触发。
五、总结
微服务分布式事务,没有银弹,只有分级治理 。
本文从场景、原理、实战到优化,完整构建了一套可直接上生产 的事务分层方案:
- 跨微服务、跨数据源 ,用 Seata 做全局事务协调,保证业务链路一致性。
2. 单应用内、同一 TDSQL 集群 ,优先用 TDSQL 原生事务 ,支持多表、跨分片,性能接近单机、零代码侵入、运维成本极低。
3. 核心生产链路 ,采用 Seata + TDSQL 混合架构 :
- Seata 管服务间
- TDSQL 管库内多表 / 跨分片
既解决分布式问题,又避免纯 Seata 的性能与锁竞争短板,是真正稳健、高效的工程化方案。
4. 分区 ≠ 分片 :
分区是单机优化,不影响分布式事务 ;TDSQL 事务只与分片 有关,与分区无关。
- TDSQL 不是标准 2PC :
采用 "本地提交 + 异步状态标记",锁持有时间极短,高并发下远优于传统分布式事务。
综上所述:能用本地事务不用分布式,能用数据层事务不用应用层事务,优先简单、优先高效。
📚 我的技术博客导航:点击进入一站式查看所有干货