本仓库展示了Wan2.2-S2V-14B 模型,该模型专为音频驱动的电影视频生成而设计。它在以下论文中被介绍: Wan-S2V: 音频驱动的电影视频生成
摘要 (Wan-S2V 论文)
当前最先进的(SOTA)音频驱动角色动画方法在主要涉及语音和唱歌的场景中表现出色。然而,在更复杂的电影和电视制作中,这些方法往往难以满足复杂元素的需求,如细腻的角色互动、逼真的身体动作和动态摄像机工作。为了解决实现电影级角色动画这一长期存在的挑战,我们提出了一种基于Wan的音频驱动模型,我们称之为Wan-S2V。与现有方法相比,我们的模型在电影环境中显著提高了表现力和保真度。我们进行了广泛的实验,将我们的方法与最先进的模型(如Hunyuan-Avatar和Omnihuman)进行基准测试。实验结果一致表明,我们的方法显著优于这些现有解决方案。此外,我们通过其在长视频生成和精确视频唇形同步编辑中的应用探索了该方法的多功能性。
我们很高兴地介绍Wan2.2 ,这是我们基础视频模型的重大升级。在Wan2.2中,我们专注于引入以下创新:
-
👍 有效的MoE架构:Wan2.2将混合专家(MoE)架构引入视频扩散模型。通过使用专门的强大专家模型跨时间步分离去噪过程,这扩大了整体模型容量,同时保持相同的计算成本。
-
👍 电影级美学:Wan2.2整合了精心策划的美学数据,包括详细的照明、构图、对比度、色调等标签。这使得可以更精确和可控地生成电影风格,并促进具有可定制美学偏好的视频创作。
-
👍 复杂的运动生成:与Wan2.1相比,Wan2.2训练的数据量显著增加,图像增加了+65.6%,视频增加了+83.2%。这种扩展显著增强了模型在多个维度上的泛化能力,如运动、语义和美学,在所有开源和闭源模型中达到顶级性能。
-
👍 高效的高清混合TI2V :Wan2.2开源了一个使用我们先进的Wan2.2-VAE构建的5B模型,实现了16×16×4 的压缩比。该模型支持720P分辨率24fps的文字到视频和图像到视频生成,并且可以在像4090这样的消费级显卡上运行。它是目前可用的最快的720P@24fps模型之一,能够同时服务于工业和学术领域。
视频演示
社区作品
如果你的研究或项目基于Wan2.1 或 Wan2.2,并且希望让更多人看到,请告知我们。
- DiffSynth-Studio 为 Wan 2.2 提供了全面的支持,包括低GPU内存逐层卸载、FP8量化、序列并行化、LoRA训练、完整训练。
- Kijai's ComfyUI WanVideoWrapper 是 ComfyUI 中 Wan 模型的另一种实现。由于其专注于 Wan,因此它处于获得前沿优化和热门研究功能的最前线,这些通常难以快速集成到结构较为固定的 ComfyUI 中。
📑 待办事项列表
- Wan2.2-S2V 语音转视频
- Wan2.2-S2V 的推理代码
- Wan2.2-S2V-14B 的检查点
- ComfyUI 集成
- Diffusers 集成
运行 Wan2.2
安装
克隆仓库:
git clone https://github.com/Wan-Video/Wan2.2.git cd Wan2.2
安装依赖项:
# Ensure torch >= 2.4.0 # If the installation of `flash_attn` fails, try installing the other packages first and install `flash_attn` last pip install -r requirements.txt
模型下载
| 模型 | 下载链接 | 描述 |
|---|---|---|
| T2V-A14B | 🤗 Huggingface 🤖 ModelScope | 文本转视频 MoE 模型,支持 480P & 720P |
| I2V-A14B | 🤗 Huggingface 🤖 ModelScope | 图像转视频 MoE 模型,支持 480P & 720P |
| TI2V-5B | 🤗 Huggingface 🤖 ModelScope | 高压缩 VAE,T2V+I2V,支持 720P |
| S2V-14B | 🤗 Huggingface 🤖 ModelScope | 语音转视频模型,支持 480P & 720P |
使用 huggingface-cli 下载模型:
pip install "huggingface_hub[cli]" huggingface-cli download Wan-AI/Wan2.2-S2V-14B --local-dir ./Wan2.2-S2V-14B
使用 modelscope-cli 下载模型:
pip install modelscope modelscope download Wan-AI/Wan2.2-S2V-14B --local_dir ./Wan2.2-S2V-14B
运行语音转视频生成
此仓库支持 Wan2.2-S2V-14B 语音转视频模型,并且可以同时支持 480P 和 720P 分辨率的视频生成。
- 单GPU语音转视频推理
python generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --offload_model True --convert_model_dtype --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard." --image "examples/i2v_input.JPG" --audio "examples/talk.wav" # Without setting --num_clip, the generated video length will automatically adjust based on the input audio length
💡 此命令可以在至少 80GB 显存的 GPU 上运行。
- 使用 FSDP + DeepSpeed Ulysses 的多GPU推理
torchrun --nproc_per_node=8 generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard." --image "examples/i2v_input.JPG" --audio "examples/talk.wav"
- 姿态 + 音频驱动的生成
torchrun --nproc_per_node=8 generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "a person is singing" --image "examples/pose.png" --audio "examples/sing.MP3" --pose_video "./examples/pose.mp4"
💡 对于语音转视频任务,
size参数表示生成视频的区域,宽高比遵循原始输入图像的比例。
💡 该模型可以从音频输入结合参考图像和可选文本提示生成视频。
💡--pose_video参数启用姿态驱动的生成,允许模型在生成与音频输入同步的视频时跟随特定的姿态序列。
💡--num_clip参数控制生成的视频片段数量,有助于通过缩短生成时间来快速预览。
不同 GPU 上的计算效率
我们在下表中测试了不同 Wan2.2 模型在不同 GPU 上的计算效率。结果以以下格式呈现:总时间 (秒) / 峰值 GPU 内存 (GB)。
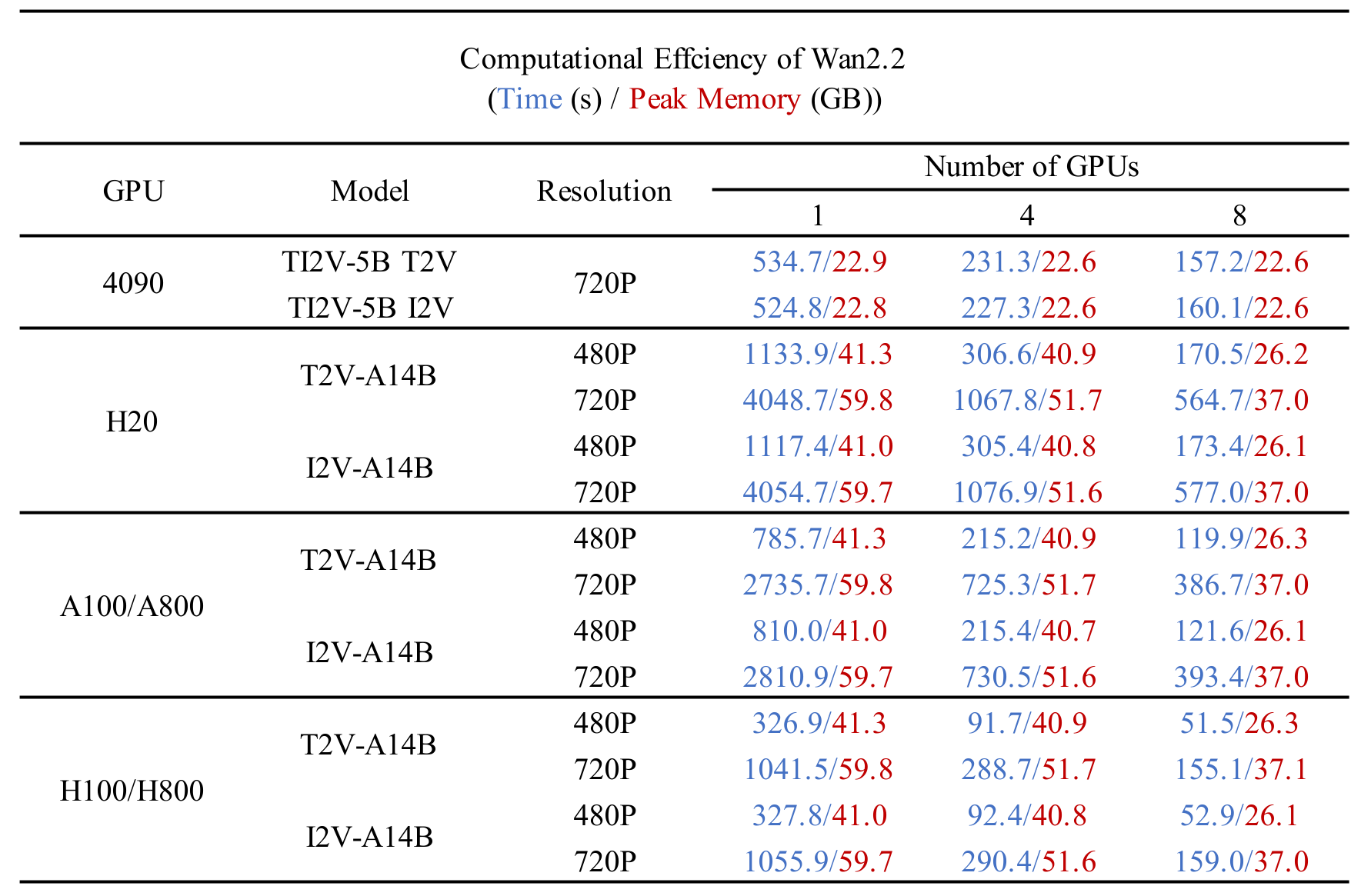
本表中测试的参数设置如下: (1) 多GPU:14B:
--ulysses_size 4/8 --dit_fsdp --t5_fsdp,5B:--ulysses_size 4/8 --offload_model True --convert_model_dtype --t5_cpu;单GPU:14B:--offload_model True --convert_model_dtype,5B:--offload_model True --convert_model_dtype --t5_cpu(--convert_model_dtype 将模型参数类型转换为config.param_dtype); (2) 分布式测试利用了内置的FSDP和Ulysses实现,并在Hopper架构GPU上部署了FlashAttention3; (3) 测试运行时未使用--use_prompt_extend标志; (4) 报告的结果是在预热阶段之后多次采样的平均值。
Wan2.2 介绍
Wan2.2 在Wan2.1的基础上进行了显著改进,提高了生成质量和模型能力。这一升级主要由一系列关键技术革新驱动,主要包括专家混合(MoE)架构、升级的训练数据和高压缩视频生成。
(1) 专家混合(MoE)架构
Wan2.2将专家混合(MoE)架构引入视频生成扩散模型。MoE已在大型语言模型中被广泛验证,是一种在保持推理成本几乎不变的情况下增加总模型参数的有效方法。在Wan2.2中,A14B系列模型采用了针对扩散模型去噪过程量身定制的双专家设计:早期阶段的高噪声专家专注于整体布局;后期阶段的低噪声专家则细化视频细节。每个专家模型约有14B参数,总共有27B参数,但每步只有14B活跃参数,从而保持推理计算和GPU内存几乎不变。

两个专家之间的切换点由信噪比(SNR)决定,这是一个随着去噪步骤ttt增加而单调递减的指标。在去噪过程开始时,ttt较大且噪声水平较高,因此SNR处于最低值SNRmin{SNR}{min}SNRmin。在这个阶段,激活高噪声专家。我们定义一个阈值步骤tmoe{t}{moe}tmoe对应于SNRmin{SNR}{min}SNRmin的一半,并在t<tmoet<{t}{moe}t<tmoe时切换到低噪声专家。
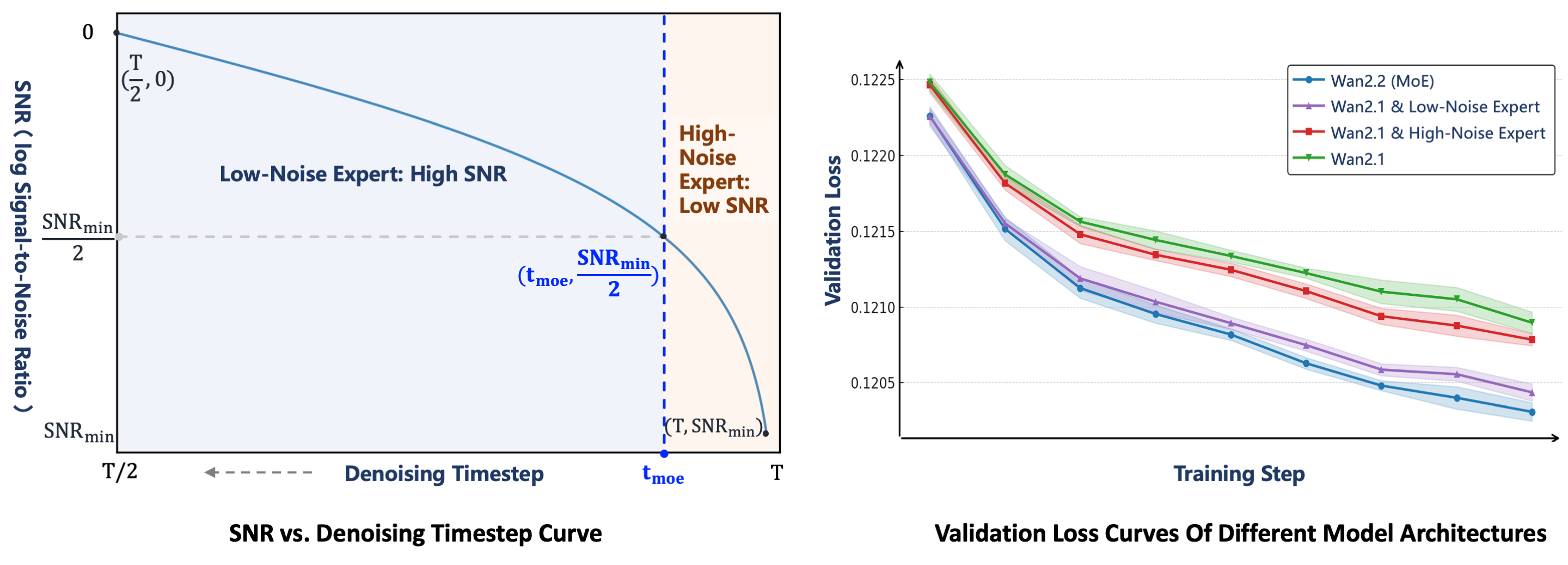
为了验证MoE架构的有效性,基于其验证损失曲线比较了四种设置。基线Wan2.1 模型不采用MoE架构。在基于MoE的变体中,Wan2.1 & 高噪声专家 重用Wan2.1模型作为低噪声专家,同时使用Wan2.2的高噪声专家,而Wan2.1 & 低噪声专家 使用Wan2.1作为高噪声专家并采用Wan2.2的低噪声专家。Wan2.2 (MoE)(我们的最终版本)实现了最低的验证损失,表明其生成的视频分布最接近真实情况并且具有优越的收敛性。
(2) 高效高清晰度混合TI2V
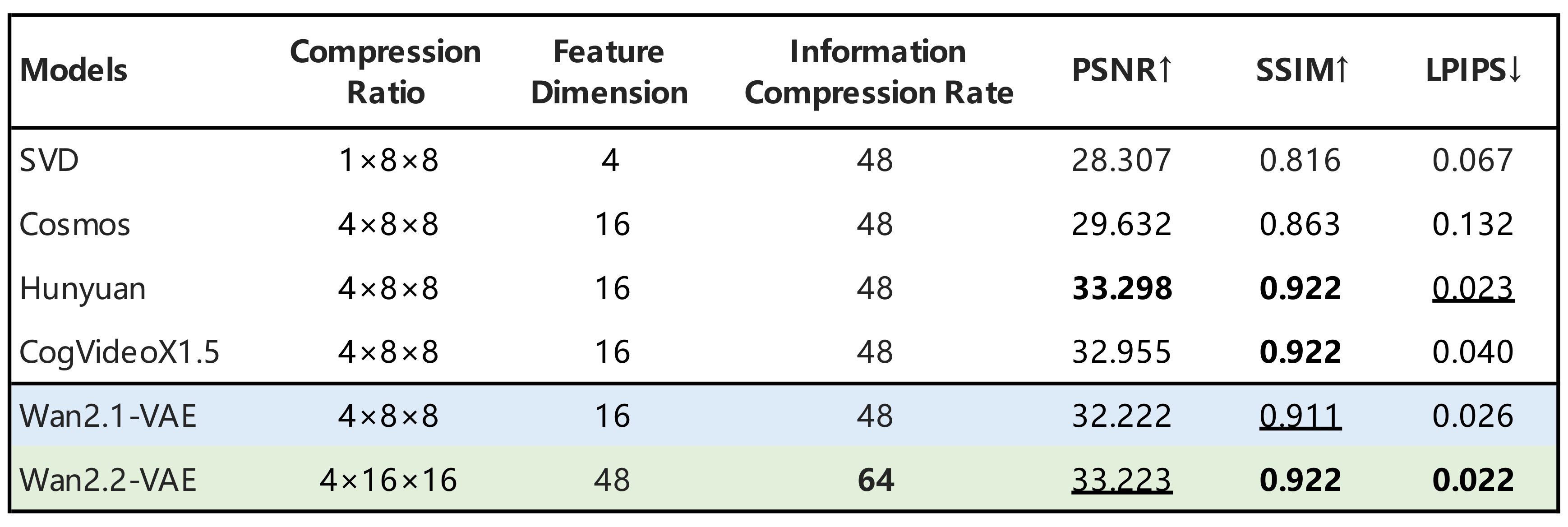
为了实现更高效的部署,Wan2.2还探索了高压缩设计。除了27B MoE模型外,还发布了一个5B密集模型,即TI2V-5B。它由一个高压缩率的Wan2.2-VAE支持,该VAE实现了T×H×WT\times H\times WT×H×W的4×16×164\times16\times164×16×16压缩比,将总体压缩率提高到64,同时保持高质量的视频重建。通过添加额外的分块层,TI2V-5B的总压缩比达到4×32×324\times32\times324×32×32。未经特定优化,TI2V-5B可以在单个消费级GPU上不到9分钟内生成一段5秒的720P视频,是最快的720P@24fps视频生成模型之一。该模型还在单一统一框架内原生支持文本到视频和图像到视频任务,覆盖学术研究和实际应用。
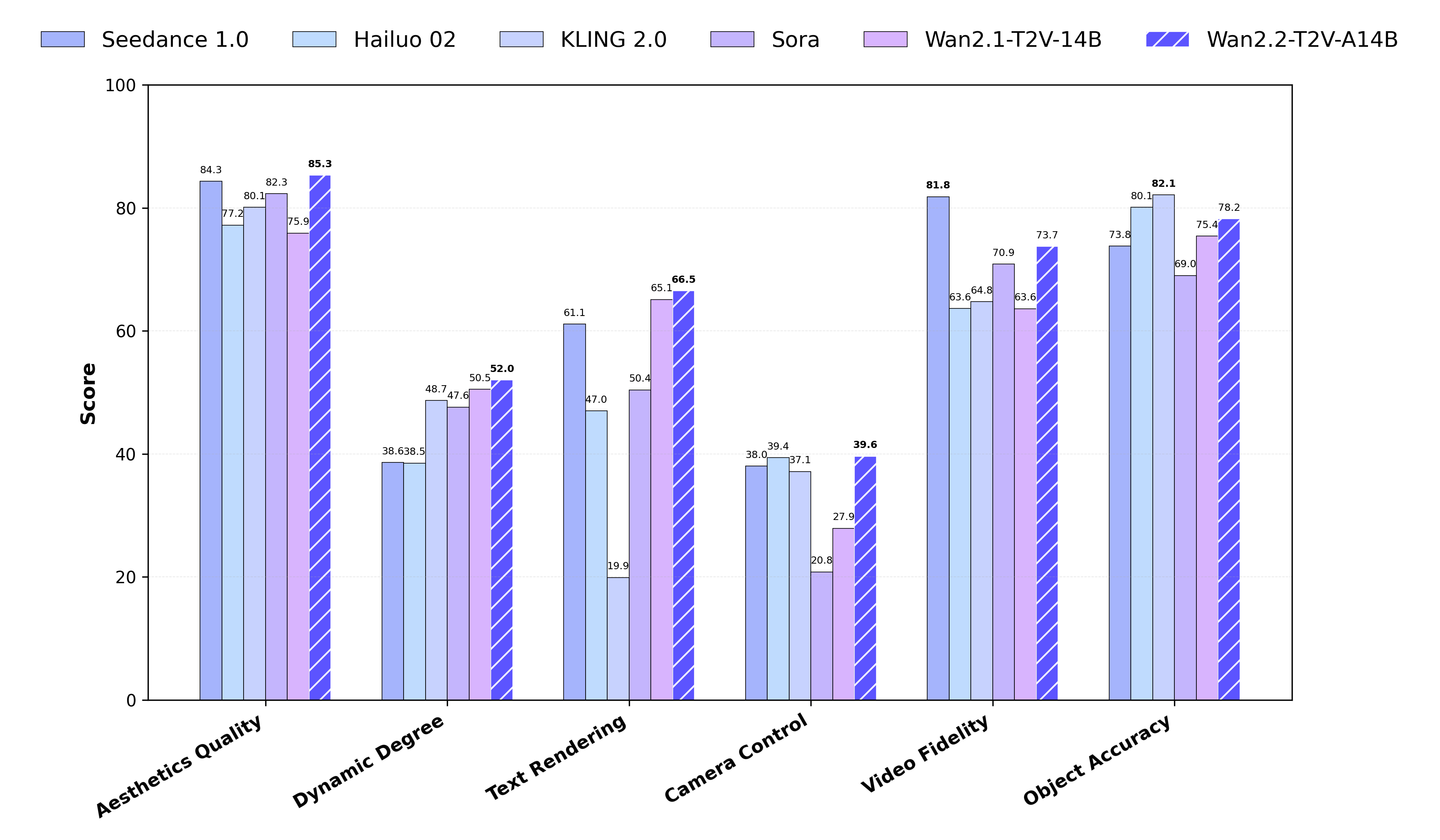
与SOTA的比较
我们在新的Wan-Bench 2.0上将Wan2.2与领先的闭源商业模型进行了比较,评估了多个关键维度的性能。结果表明,Wan2.2在这些领先模型中表现出色。