一、机器学习基础
1、定义
机器具备有学习的能力。具体来讲就是让机器具备找一个函数的能力。
2、类别
(1)回归(Regression):函数的输出是一个数值,一个标量(scalar);
(2)分类(Classification):让机器做选择题,函数的输出是从设定好的选项里面选择一个当作输出;
(3)结构化学习(Structured Learning):机器产生一个有结构的物体,比如画一张画,写一篇文章。
3、机器学习的训练的三个步骤
(1)写出一个带有未知参数的function;
- 模型(model):带有位置参数的函数;
- 特征(feature):函数里面已知的;
- 权重(weight);
- 偏置(bias);
(2)定义损失函数lost;(L越大,代表现在这组参数越不好,L越小,代表这组参数越好)
估测值与标签(label)之间的差距计算方法:
- 平均绝对误差(MAE):
;
- 均方误差(MSE):
- 交叉熵(cross entropy);
误差表面(error surface):尝试了不同的参数,计算它的损失,画出来的等高线图;
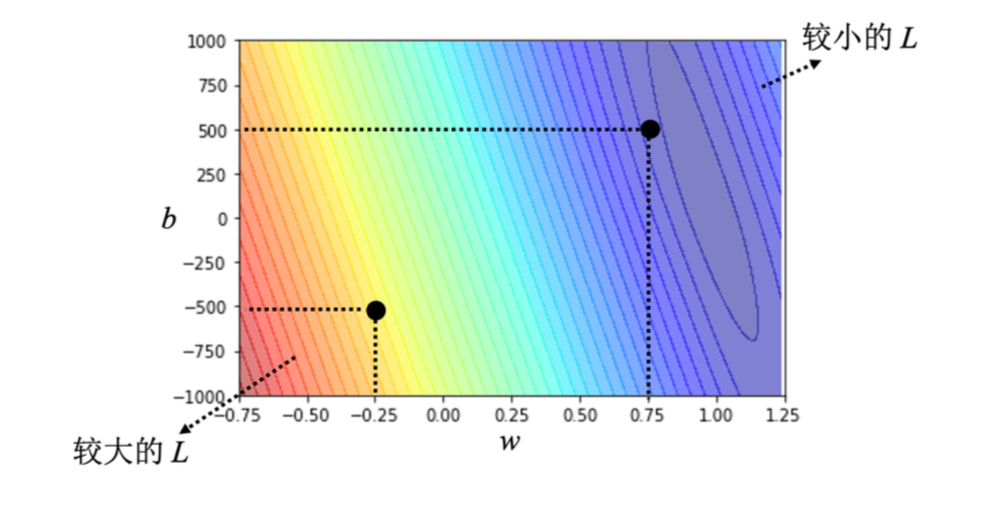
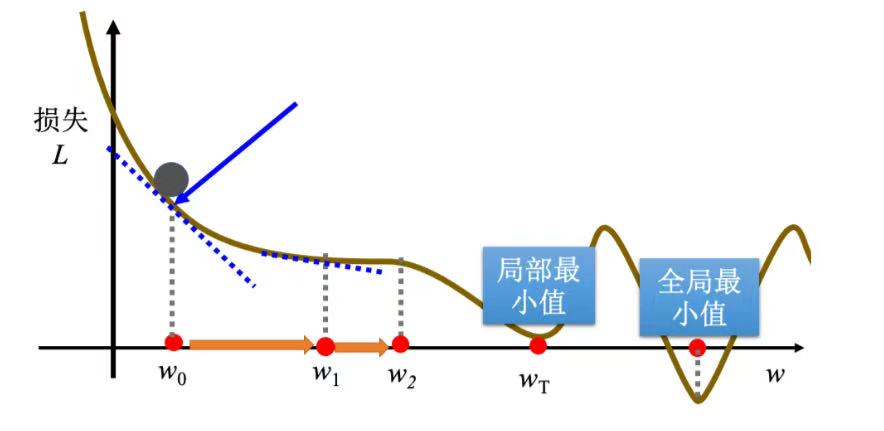
(3)最优化(optimization),找到一组最好的(w, b)让损失最小。
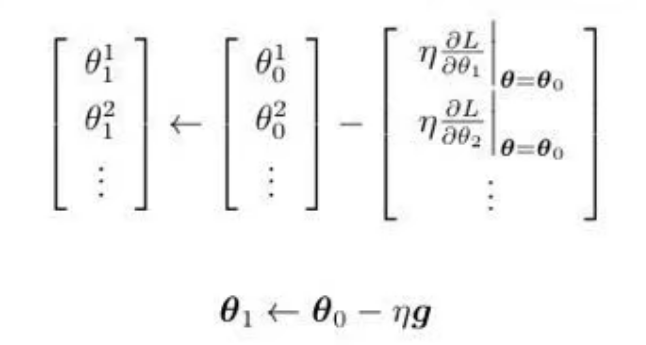
常用方法:梯度下降(gredient descent)
- 选择一个初始点
- 计算**
- 根据该点的切线斜率判断下一步往哪里走,斜率为正,w向左移,相反右移;
- 移动:
步伐大小取决于:
· 斜率。斜率大步伐大,斜率小步伐小;
· 学习率- 重复操作直到失去耐心或
4、线性模型
(1)定义:把输入的特征乘上一个权重再加上一个偏置就得到预测的结果。
(2)模型偏差(model bias):来自于模型的限制。
(3)Hard Sigmoid函数: 当 x 轴的值小于某一个阈值的时候,大于另外一个阈值的时候,中间有一个斜坡。故其图象是先水平,再斜坡,再水平。
(4)分段线性曲线(piecewise linear curve):常数+一组Hard Sigmoid函数的和。
(5)Sigmoid函数:。
可以用Sigmoid函数逼近Hard Sigmoid函数,然后把不同的Sigmoid函数叠起来就可以去逼近各种不同的分段线性函数,分段线性函数可以拿来近似各种不同的连续的函数。
如果

(6)不只用一个特征,可以用多个特征代入不同的c,b,w,组合出各种不同的函数,从而得到更有灵活性(flexibility)的函数。
- 写一个带未知数的function;
用矩阵跟向量相乘的方法表示:
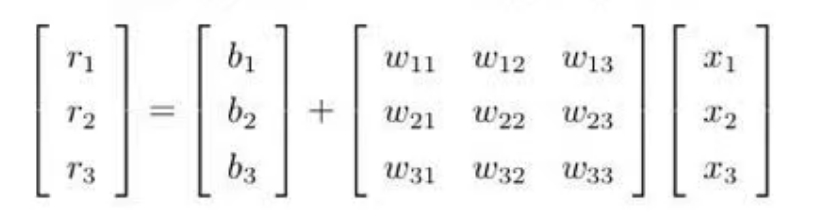
线性代数常用的表示方式:

通过Sigmoid函数计算得到:
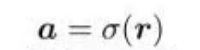
即这个比较灵活的函数为:
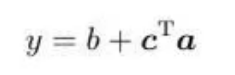
- 定义损失;
把W 的每一行或者每一列拼成一个长向量,把b , ,b"拼"上去,形成一个长向量**
** 。损失函数为L(
)。
- 优化;
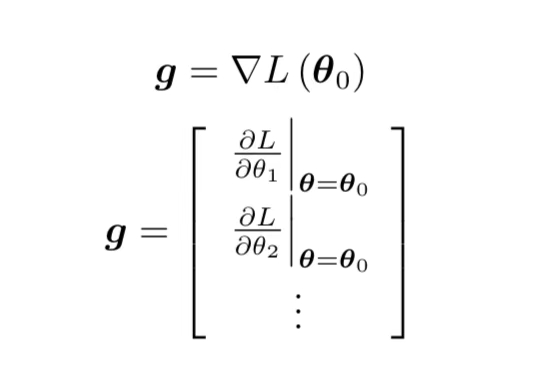
(7)批量(batch):本来有N笔数据,现在B笔数据一组,一组叫做批量。
(8)回合(epoch):把所有批量都看过一次,称为一个回合。
(9)模型变形:Hrad Sigmoid看作两个修正线性单元(ReLU)的加总。ReLU公式如下:
Sigmoid或ReLU被称为激活函数。想要使用ReLU,就把Sigmoid的地方换成
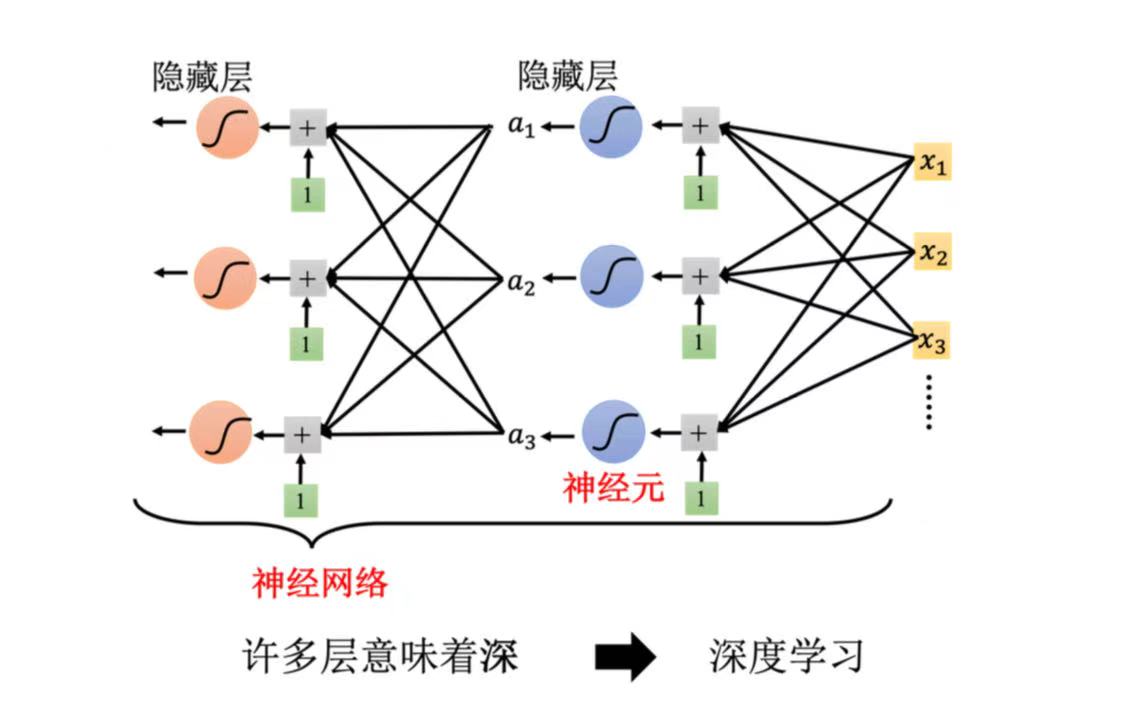
5、深度学习引入
(1)神经元===> 神经网络(neural network);
(2)隐藏层(hidden layer)===>深度学习(deep learning);
二、实践方法论
对训练结果不满意,分析路径:
(1)检查训练集上的loss,如果训练集的loss太大,则说明在训练资料上没有学好,进入第(2)步;如果训练集的loss太小,进入第(3)步,检查测试集上的loss。
(2)训练集上没有学好,有两种可能:通过比较不同模型来判断模型现在到底够不够大。
- 模型偏差(model bias):模型太过简单,需要重新设计一个模型;
- 优化做得不好:收敛在局部极限值与鞍点会导致优化失败。
临界点:梯度为零的点,包括局部极小值(local minimum)、鞍点(saddle point)、局部极大值(local maximum)。
判断临界值种类的方法:海森矩阵H ;(同时指出了参数可以更新的方向)Hessian 矩阵(海森矩阵)_hessian矩阵-CSDN博客
批量(batch)大小对梯度下降法的影响:在有并行计算的情况下,小的批量跟大的批量运算的时间并没有太大的差距。除非大的批量非常大,才会显示出差距。但是一个回合需要的时间,小的批量比较长,大的批量反而是比较快的,所以从一个回合需要的时间来看大的批量是较有优势的。而小的批量更新的方向比较有噪声的,大的批量更新的方向比较稳定。但是有噪声的更新方向反而在优化的时候有优势,而且在测试的时候也会有优势。所以大的批量跟小的批量各有优缺点,批量大小是需要去调整的超参数。
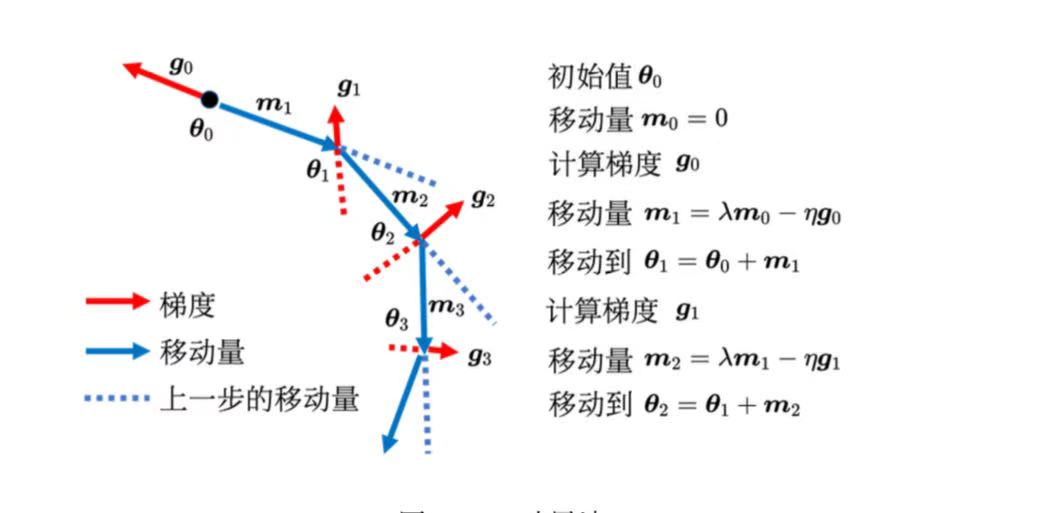
动量(Momentum)法是可以对抗鞍点或局部最小值的方法。可能走到更好的局部最小值。
自适应学习率:为每一个参数不同的学习率。如果在某一个方向上,梯度的值很小,非常平坦,希望学习率调大一点;如果在某一个方向上非常陡峭,坡度很大,希望学习率可以设得小一点。
AdaGrad、RMSProp、Adam:最强总结!神经网络中常用的九种优化技术(二)AdaGrad、RMSProp、Adam、学习率衰减、Early Stopping(非常详细)大模型入门到精通!-CSDN博客学习率调度:通过动态调整学习率来实现更好的训练效果;
学习率衰减:随着参数的不断更新,让
预热(Warm Up):让学习率先变大后变小。批量归一化(BN):
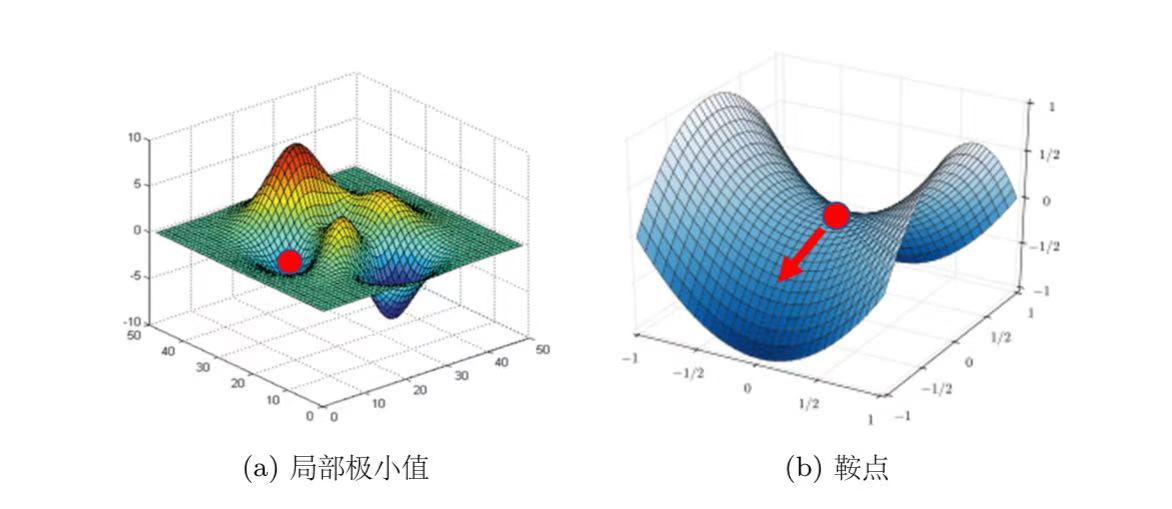


(3)如果测试集上得loss也小,那么训练是好的,如果测试集上的loss太大,有两种情况:
一是出现了过拟合(overfitting)现象,解决方法:
- 增加训练集,可以做数据增强(data augmentation);
- 给模型增加一些限制,比如给模型比较少的参数、用较少的特征、早停、正则化、丢弃法等。但是不能给太多限制,否者可能出现模型偏差问题。
交叉验证:合理选择模型的方法
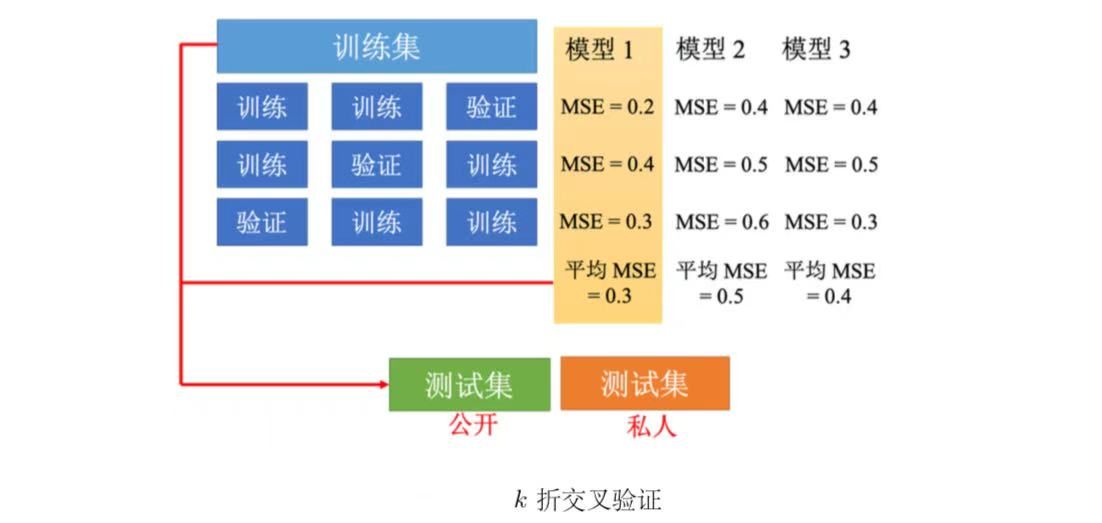
二是训练资料与测试资料不匹配的问题。

三、练习
1、Regression
(1)Dataset:https://www.kaggle.com/competitions/ml2023spring-hw1;
(2)解释
- 随机种子:确保实验的可重复性,计算机的"随机"其实是数学公式生成的伪随机数。种子的作用是固定公式的起点 。
为什么要设置"随机种子"_训练模型时需要设置随机种吗-CSDN博客 - Dtaset:可以通过继承Pytorch提供的Dataset类来构造更适合的数据集类;
def__init__(self, features, targets = None):读取数据并进行预处理;
def__getitem__(self, idx):每次提取一笔数据;
def__len__(self):返回数据的长度; - DataLoader:一个迭代器,可以多线程地读取数据,并可将几笔数据组成batch;
参数列表(待加载数据集,batch大小,是否打乱数据,是否锁页);
shuffle(是否打乱数据):Traning时设为True,Testing时设为False;
pin_memory(是否锁页):设置为True时,将数据张量固定在GPU内存中,使数据加载至GPU速度更快; - 神经网络模型:通过集成nn.Model类来构造自己的神经网络模型;
self.layers = nn.Sequential():一个序列容器,将每一layer按照被传入构造器的顺序添加到nn.Sequential()容器中;
def forward(self, x):前向传播,可理解成神经网络处理输入的过程; - 训练过程:对每个batch数据:清零梯度(optimizer.zero_grad()),前向传播计算预测值,计算损失,反向传播(loss.backward()),更新参数(optimizer.step())。
- 深度学习中有哪些超参数,都有什么作用_实验超参数配置的作用-CSDN博客
(3)代码:
python
# 数据操作
import math
import numpy as np
# 读取、写入数据
import pandas as pd
import os
import csv
# 进度条
from tqdm import tqdm
# Pytorch
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader, random_split
# 绘制图像
from torch.utils.tensorboard import SummaryWriter
'''
设置随机种子
在机器学习和深度学习实验中,由于存在随机性(如权重初始化、数据打乱等),每次运行的结果可能会有所不同。
通过设置固定的随机种子,可以使得每次运行的结果保持一致,便于调试和验证。
'''
def same_seed(seed):
# 将 cuDNN(CUDA 深度神经网络库)设置为确定性模式,以确保在 GPU 上运行时结果可重复。
torch.backends.cudnn.deterministic = True
# 禁用 cuDNN 的自动调优功能,因为该功能会根据硬件选择最优的卷积算法,但这可能导致结果不一致。
torch.backends.cudnn.benchmark = False
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
'''
划分数据集:本实验从训练集中划分验证集
data_set:要划分的数据集
valid_ratio:划分比例
seed:保证从训练集中随机的划分出验证集
'''
def train_valid_split(data_set, valid_ratio, seed):
# 计算验证集的大小
valid_data_size = int(len(data_set) * valid_ratio)
# 计算训练集的大小
train_data_size = len(data_set) - valid_data_size
'''
random_split 函数随机划分数据集:
按照计算出的训练集和验证集大小进行划分
使用指定的随机种子确保结果可重现
generator=torch.Generator().manual_seed(seed) 确保划分过程的随机性是可控的
'''
train_data, valid_data = random_split(data_set, [train_data_size, valid_data_size], generator=torch.Generator().manual_seed(seed))
return np.array(train_data), np.array(valid_data)
'''
选择特征
最后一列数据是label,x是feature,y是label
默认选择了全部的特征来做训练,后续可选择合适的特征来优化模型提高预测率
'''
def select_feat(train_data, valid_data, test_data, select_all = True):
# 分别提取训练数据和验证数据的最后一列作为目标值(即标签)
y_train = train_data[:, -1]
y_valid = valid_data[:, -1]
# 分别提取训练数据、验证数据(除了最后一列)和测试数据的所有特征列
raw_x_train = train_data[:, :-1]
raw_x_valid = valid_data[:, :-1]
raw_x_test = test_data
if select_all:
feat_idx = list(range(raw_x_train.shape[1]))
else:
feat_idx = [0, 1, 2, 3]
return raw_x_train[:, feat_idx], raw_x_valid[:, feat_idx], raw_x_test[:, feat_idx], y_train, y_valid
# 数据集
class COVID19Dataset(Dataset):
'''
数据初始化方法
festures:输入特征数据
targets:目标值(可选,默认为None)
'''
def __init__(self, features, targets = None):
if targets is None:
self.targets = targets
else:
self.targets = torch.FloatTensor(targets)
self.features = torch.FloatTensor(features)
'''
数据获取方法:根据索引返回数据项
如果没有目标值(如测试集),只返回特征
如果有目标值(如训练集、验证集),返回 (特征, 目标值) 对
'''
def __getitem__(self, index):
if self.targets is None:
return self.features[index]
else:
return self.features[index], self.targets[index]
'''
返回数据集中样本的总数
'''
def __len__(self):
return len(self.features)
# 神经网络,继承自PyTorch的 nn.Module 基类
class My_Model(nn.Module):
'''
初始化方法
input_dim:输入特征的维度
super(My_Model, self).__init__() 调用父类初始化
nn.Linear:线性变换层
nn.ReLU() - ReLU激活函数
'''
def __init__(self, input_dim):
super(My_Model, self).__init__()
self.layers = nn.Sequential(
nn.Linear(input_dim, 16),
nn.ReLU(),
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 1),
)
'''
通过 self.layers 顺序执行所有定义的层
使用 x.squeeze(1) 移除张量的第二个维度(索引为1),防止输出出现不必要的维度
'''
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1)
return x
# 参数设置
device = 'cuda' if torch.cuda.is_available() else 'cpu'
config = {
'seed': 5201314,
'select_all': True,
'valid_ratio': 0.2,
'n_epochs': 3000,
'batch_size': 256,
'learning_rate': 1e-5,
'early_stop': 400,
'save_path': './models/model.ckpt',
}
# 训练过程
def trainer(train_loader, valid_loader, model, config, device):
# 损失函数和优化器
criterion = nn.MSELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=0.7)
writer = SummaryWriter()
if not os.path.isdir('./models'):
os.mkdir('./models')
n_epochs = config['n_epochs']
best_loss = math.inf
step = 0
early_stop_count = 0
for epoch in range(n_epochs):
# 设置模型为训练模式
model.train()
loss_record = []
# 使用tqdm进度条显示训练进度
train_pbar = tqdm(train_loader, position=0, leave=True)
'''
对每个batch数据:
清零梯度(optimizer.zero_grad())
前向传播计算预测值
计算损失
反向传播(loss.backward())
更新参数(optimizer.step())
'''
for x, y in train_pbar:
optimizer.zero_grad()
x, y = x.to(device), y.to(device)
pred = model(x)
loss = criterion(pred, y)
loss.backward()
optimizer.step()
step += 1
loss_record.append(loss.detach().item())
# 显示训练过程
train_pbar.set_description(f'Epoch[{epoch + 1}/{n_epochs}]')
train_pbar.set_postfix({'loss': loss.detach().item()})
mean_train_loss = sum(loss_record) / len(loss_record)
writer.add_scalar('loss/train', mean_train_loss, step)
# 设置模型为评估模式
model.eval()
loss_record = []
# 在验证集上计算平均损失,使用torch.no_grad()避免计算梯度以节省内存
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
loss = criterion(pred, y)
loss_record.append(loss.item())
mean_valid_loss = sum(loss_record) / len(loss_record)
print(f'Epoch[{epoch + 1}/{n_epochs}]: Train loss : {mean_train_loss: .4f}, Valid loss : {mean_valid_loss: .4f}')
writer.add_scalar('loss/valid', mean_valid_loss, step)
# 如果当前验证损失低于历史最佳损失,保存模型
if mean_valid_loss < best_loss:
best_loss = mean_valid_loss
torch.save(model.state_dict(), config['save_path'])
print('Saving model with loss {: .3f}...'.format(best_loss))
early_stop_count = 0
else:
early_stop_count += 1
# 连续early_stop轮验证损失未改善则提前停止训练
if early_stop_count >= config['early_stop']:
print('\nEarly stopping')
return
# 设置随机种子
same_seed(config['seed'])
# 读取数据
train_data = pd.read_csv('./covid_train.csv').values
test_data = pd.read_csv('./covid_test.csv').values
# 划分数据集
train_data, valid_data = train_valid_split(train_data, config['valid_ratio'], config['seed'])
print(f"""train_data size: {train_data.shape}, valid_data size: {valid_data.shape}, test_data size: {test_data.shape})""")
# 选择特征
x_train, x_valid, x_test, y_train, y_valid = select_feat(train_data, valid_data, test_data, config['select_all'])
print(f'The number of features: {x_train.shape[1]}')
# 构造数据集
train_dataset = COVID19Dataset(x_train, y_train)
valid_dataset = COVID19Dataset(x_valid, y_valid)
test_dataset = COVID19Dataset(test_data)
# 准备Dataloader
train_loader = DataLoader(train_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
valid_loader = DataLoader(valid_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=config['batch_size'], shuffle=False, pin_memory=True)
# 开始训练
model = My_Model(input_dim=x_train.shape[1]).to(device)
trainer(train_loader, valid_loader, model, config, device)
# 预测
def predict(test_loader, model, device):
model.eval()
preds = []
for x in tqdm(test_loader):
x = x.to(device)
with torch.no_grad():
pred = model(x)
preds.append(pred.detach().cpu())
preds = torch.cat(preds, dim=0).numpy()
return preds
def save_pred(preds, file):
with open(file, 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['id', 'tested_positive'])
for i, p in enumerate(preds):
writer.writerow([i, p])
# 预测并保存结果
model = My_Model(input_dim=x_train.shape[1]).to(device)
model.load_state_dict(torch.load(config['save_path']))
preds = predict(test_loader, model, device)
save_pred(preds, 'pred.csv')2、Classification
(1)Dataset:https://www.kaggle.com/competitions/ml2023spring-hw2;
(2)解释
-
模块化思维:
BasicBlock:一层Linear层 + ReLu激活函数 = 一个BasicBlock;可以视作封装了一层hidden_layer;
Classfier:由许多个BasicBlock组成,构成最终要用的神经网络模型。 -
损失函数nn.CrossEntropyLoss()通常用于多类别分类任务,特别是当类别之间不平衡或样本数目不均衡时;
交叉熵(Cross-Entropy):一种用于比较两个概率分布之间的度量,对比了模型的预测结果和数据的真实标签,随着预测越来越准确,交叉熵的值越来越小,如果预测完全正确,交叉熵的值就为0。因此,训练分类模型时,可以使用交叉熵作为损失函数。 -
优化器AdamW(),集成一阶、二阶动量和weight decay正则化的优化器,区别于随机梯度下降法,它能够在训练过程中自适应的调整学习率;
(3)代码:
python
import csv
import os
import numpy as np
import torch
import random
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
from tqdm import tqdm
import gc # 回收内存,节约资源
# 设置随机种子
def same_seeds(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
# 读取pt文件(加载特征)
def load_feat(path):
return torch.load(path)
'''
拼接frame
假设我们有以下输入:输入张量 x 形状为 (4, 3),表示4个帧,每帧3个特征,concat_n = 3
初始输入 x (4个帧,每帧3个特征)
x = torch.tensor([
[1, 2, 3], # 帧0
[4, 5, 6], # 帧1
[7, 8, 9], # 帧2
[10, 11, 12] # 帧3
])
1、x.repeat(1, concat_n)
x = [
[1, 2, 3, 1, 2, 3, 1, 2, 3], # 帧0重复
[4, 5, 6, 4, 5, 6, 4, 5, 6], # 帧1重复
[7, 8, 9, 7, 8, 9, 7, 8, 9], # 帧2重复
[10, 11, 12, 10, 11, 12, 10, 11, 12] # 帧3重复
]
2、x.view(seq_len, concat_n, feature_dim),重新排列为 (4, 3, 3) 的形状:
x = [
# 帧0: [[1,2,3], [1,2,3], [1,2,3]]
# 帧1: [[4,5,6], [4,5,6], [4,5,6]]
# 帧2: [[7,8,9], [7,8,9], [7,8,9]]
# 帧3: [[10,11,12], [10,11,12], [10,11,12]]
]
3、x.permute(1, 0, 2),转置为 (3, 4, 3) 的形状,第一维表示拼接组:
x = [
# 组0: [[1,2,3], [4,5,6], [7,8,9], [10,11,12]] - 原始帧
# 组1: [[1,2,3], [4,5,6], [7,8,9], [10,11,12]] - 重复帧
# 组2: [[1,2,3], [4,5,6], [7,8,9], [10,11,12]] - 重复帧
]
4、应用 shift 函数
mid = concat_n // 2 = 1 (中间组索引)
对于 r_idx = 1:
x[mid+1, :] = shift(x[mid+1, :], 1) (向右移动1位)
x[mid-1, :] = shift(x[mid-1, :], -1) (向左移动1位)
shift(x[mid+1, :], 1) 的执行过程:
x[2, :] = [[1,2,3], [4,5,6], [7,8,9], [10,11,12]]
n = 1 > 0,所以:
left = x[1:] = [[4,5,6], [7,8,9], [10,11,12]]
right = x[-1].repeat(1, 1) = [[10,11,12]]
结果:[[4,5,6], [7,8,9], [10,11,12], [10,11,12]]
shift(x[mid-1, :], -1) 的执行过程:
x[0, :] = [[1,2,3], [4,5,6], [7,8,9], [10,11,12]]
n = -1 < 0,所以:
left = x[0].repeat(1, 1) = [[1,2,3]]
right = x[:-1] = [[1,2,3], [4,5,6], [7,8,9]]
结果:[[1,2,3], [1,2,3], [4,5,6], [7,8,9]]
最终x = [
# 组0: [[1,2,3], [1,2,3], [4,5,6], [7,8,9]] - 向左移动后的帧
# 组1: [[1,2,3], [4,5,6], [7,8,9], [10,11,12]] - 原始帧
# 组2: [[4,5,6], [7,8,9], [10,11,12], [10,11,12]] - 向右移动后的帧
]
5、x.permute(1, 0, 2).view(seq_len, concat_n * feature_dim),重新排列并展平特征维度,得到最终结果:
[
[1,2,3, 1,2,3, 4,5,6], # 帧0: [前1帧, 当前帧, 后1帧]
[1,2,3, 4,5,6, 7,8,9], # 帧1: [前1帧, 当前帧, 后1帧]
[4,5,6, 7,8,9, 10,11,12], # 帧2: [前1帧, 当前帧, 后1帧]
[7,8,9, 10,11,12, 10,11,12] # 帧3: [前1帧, 当前帧, 后1帧]
]
'''
# shift 函数用于对输入张量 x 进行移位操作
def shift(x, n):
if n < 0:
left = x[0].repeat(-n, 1)
right = x[:n]
elif n > 0:
left = x[n:]
right = x[-1].repeat(n, 1)
else:
return x
return torch.cat((left, right), dim=0)
'''
concat_feat 函数用于将特征帧进行拼接以增加上下文信息:
这个函数的主要目的是为每个时间帧添加前后帧的上下文信息, 以帮助模型更好地理解语音信号的时序特征。
'''
def concat_feat(x, concat_n):
assert concat_n % 2 == 1
if concat_n < 2:
return x
seq_len = x.size(0) # frame的个数
feature_dim = x.size(1) # 每一个frame的维度
x = x.repeat(1, concat_n)
# 重新排列张量形状为 (concat_n, seq_len, feature_dim),即[组号, 帧序号, 帧内号]
x = x.view(seq_len, concat_n, feature_dim).permute(1, 0, 2)
mid = concat_n // 2
# 对于中间帧周围的每一帧: 使用 shift 函数对称地移动帧以创建上下文
for r_idx in range(1, mid+1):
x[mid+r_idx, :] = shift(x[mid+r_idx], r_idx)
x[mid-r_idx, :] = shift(x[mid-r_idx], -r_idx)
# 最后将张量重新排列并展平特征维度, 得到拼接后的特征
return x.permute(1, 0, 2).view(seq_len, concat_n * feature_dim)
# 预处理数据
def preprocess_data(split, feat_dir, phone_path, concat_nframes, train_ratio=0.8):
class_num = 41 # 41个分类
mode = 'train' if (split == 'train' or split == 'val') else 'test'
# 将每个文件名及其对应的标签序列存储在 label_dick 字典中
label_dick = {}
if mode != 'test':
phone_file = open(os.path.join(phone_path, f'{mode}_labels.txt')).readlines()
for line in phone_file:
line = line.strip('\n').split(' ')
# temp = []
# for p in line[1:]:
# temp.append(int(p))
label_dick[line[0]] = [int(p) for p in line[1:]]
# 划分数据集
if split == 'train' or split == 'val':
usage_list = open(os.path.join(phone_path, 'train_split.txt')).readlines()
random.shuffle(usage_list)
percent = int(len(usage_list) * train_ratio)
if split == 'train':
usage_list = usage_list[:percent]
elif split == 'val':
usage_list = usage_list[percent:]
elif split == 'test':
usage_list = open(os.path.join(phone_path, 'test_split.txt')).readlines()
else:
raise ValueError('Invalid \'split\' argument for dataset: PhoneDataset!')
usage_list = [line.strip('\n') for line in usage_list]
print('[Dataset] - # phone classes: {}, # samples: {:d}'.format(class_num, len(usage_list)))
# 创建预分配的张量 x 和 y 用于存储特征和标签
max_len = 10000000
x = torch.empty(max_len, 39 * concat_nframes)
if mode != 'test':
y = torch.empty(max_len, dtype=torch.long)
'''
遍历文件列表,将特征和标签存储到预分配的张量中
使用 torch.empty 预分配内存以提高效率
通过 concat_feat 函数增加时序上下文信息
使用 tqdm 显示处理进度
最终通过切片操作 x[:idx, :] 和 y[:idx] 去除预分配的多余空间
'''
idx = 0
for i, fname in tqdm(enumerate(usage_list)):
feat = load_feat(os.path.join(feat_dir, mode, f'{fname}.pt'))
cur_len = len(feat)
feat = concat_feat(feat, concat_nframes)
if mode != 'test':
label = torch.LongTensor(label_dick[fname])
x[idx: idx + cur_len] = feat
if mode != 'test':
y[idx: idx + cur_len] = label
idx += cur_len
x = x[:idx, :]
if mode != 'test':
y = y[:idx]
print(f'[INFO]{split} set')
print(x.shape)
if mode != 'test':
print(y.shape)
return x, y
else:
return x
# Dataset
class LibriDataset(Dataset):
def __init__(self, x, y=None):
self.feature = x
if y is not None:
self.label = torch.LongTensor(y)
else:
self.label = None
def __getitem__(self, item):
if self.label is not None:
return self.feature[item], self.label[item]
else:
return self.feature[item]
def __len__(self):
return len(self.feature)
# Model
class BasicBlock(nn.Module):
def __init__(self, input_dim, output_dim):
super(BasicBlock, self).__init__()
self.block = nn.Sequential(
nn.Linear(input_dim, output_dim),
nn.ReLU(),
)
def forward(self, x):
x = self.block(x)
return x
class Classifier(nn.Module):
def __init__(self, input_dim, output_dim=41, hidden_layers=1, hidden_dim=256):
super(Classifier, self).__init__()
self.fc = nn.Sequential(
BasicBlock(input_dim, hidden_dim), # 输入层
*[BasicBlock(hidden_dim, hidden_dim) for _ in range(hidden_layers)], #hidden_layers 个 BasicBlock 作为隐藏层
nn.Linear(hidden_dim, output_dim) # 一个线性层将隐藏层映射到输出维度
)
def forward(self, x):
x = self.fc(x)
return x
# 配置
device = 'cuda' if torch.cuda.is_available() else 'cpu'
concat_nframes = 3
train_ratio = 0.8
config = {
'seed': 0,
'batch_size': 512,
'n_epoch': 5,
'learning_rate': 1e-4,
'model_path': './model.ckpt'
}
input_dim = 39 * concat_nframes
hidden_layers = 3
hidden_dim = 256
# 训练
def trainer(train_set, valid_set, train_loader, val_loader, config, model, device):
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=config['learning_rate'])
best_acc = 0.0
n_epochs = config['n_epoch']
for epoch in range(n_epochs):
train_acc = 0.0
train_loss = 0.0
model.train()
for i, batch in enumerate(tqdm(train_loader)):
features, labels = batch
features = features.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(features)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, train_pred = torch.max(outputs, dim = 1)
train_acc += (train_pred.detach() == labels.detach()).sum().item()
train_loss += loss.item()
#
if (len(valid_set)) > 0:
val_acc = 0.0
val_loss = 0.0
model.eval()
with torch.no_grad():
for i, batch in enumerate(tqdm(val_loader)):
features, labels = batch
features = features.to(device)
labels = labels.to(device)
outputs = model(features)
loss = criterion(outputs, labels)
_, val_pred = torch.max(outputs, dim=1)
val_acc += (val_pred.cpu() == labels.cpu()).sum().item()
val_loss += loss.item()
print(
'[Epoch {:03d}/{:03d}] train_loss: {:.4f}, train_acc: {:.3f}, val_loss: {:.4f}, val_acc: {:.3f}'.format(
epoch + 1, n_epochs,
train_loss / len(train_loader), train_acc / len(train_set),
val_loss / len(val_loader), val_acc / len(valid_set)))
# 保存最优模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), config['model_path'])
print('saving model with acc {:.3f}'.format(best_acc))
else:
print('[Epoch {:03d}/{:03d}] train_loss: {:.4f}, train_acc: {:.3f}'.format(
epoch + 1, n_epochs,
train_loss / len(train_loader), train_acc / len(train_set)))
if len(valid_set) == 0:
torch.save(model.state_dict(), config['model_path'])
print('saving model with acc {:.3f}'.format(best_acc))
del train_loader, val_loader
gc.collect()
return
# same_seeds(config['seed'])
# train_x, train_y = preprocess_data(split='train', feat_dir='./dataset/feature', phone_path='./dataset', concat_nframes=concat_nframes, train_ratio=train_ratio)
# val_x, val_y = preprocess_data(split='val', feat_dir='./dataset/feature', phone_path='./dataset', concat_nframes=concat_nframes, train_ratio=train_ratio)
#
# train_set = LibriDataset(train_x, train_y)
# val_set = LibriDataset(val_x, val_y)
#
# del train_x, train_y, val_x, val_y
# gc.collect()
#
# train_loader = DataLoader(train_set, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
# val_loader = DataLoader(val_set, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
#
# print('==> Building model and loading data ...')
# model = Classifier(input_dim=input_dim, hidden_layers=hidden_layers, hidden_dim=hidden_dim).to(device)
# trainer(train_set, val_set, train_loader, val_loader, config, model, device)
# Predict
def predict(model, test_loader):
# test_acc = 0.0
# test_length = 0
pred = np.array( [], dtype=np.int32)
model.eval()
with torch.no_grad():
for i, batch in enumerate(tqdm(test_loader)):
features = batch
features = features.to(device)
outputs = model(features)
_, test_pred = torch.max(outputs, dim=1)
pred = np.concatenate( (pred, test_pred.cpu().numpy()), axis=0 )
return pred
# def save_pred(preds, file):
# with open(file, 'w') as fp:
# fp.write('Id Class\n')
# for i, p in enumerate(preds):
# fp.write('{} {}\n'.format(i, p))
def save_pred(preds, file):
with open(file, 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['Id', 'Class'])
for i, p in enumerate(preds):
writer.writerow([i, p])
test_x = preprocess_data(split='test', feat_dir='./dataset/feature', phone_path='./dataset', concat_nframes=concat_nframes)
test_set = LibriDataset(test_x, None)
test_loader = DataLoader(test_set, batch_size=config['batch_size'], shuffle=False, drop_last=False, pin_memory=True)
model = Classifier(input_dim=input_dim, hidden_layers=hidden_layers, hidden_dim=hidden_dim).to(device)
model.load_state_dict(torch.load(config['model_path']))
preds = predict(model, test_loader)
save_pred(preds, 'prediction.csv')