为什么选择私有化部署嵌入模型?
- 数据隐私与合规性:企业敏感数据不能上传至第三方 API。
- 低延迟与高可用:本地部署可避免网络波动,提升响应速度。
- 定制化与可控性:可自由调整模型版本、缓存策略、批处理逻辑等。
- 成本优化:长期使用下,本地部署比调用云 API 更经济。
而 Qwen3-Embedding-0.6B 是通义千问系列中专为中文优化的 轻量级嵌入模型 ,参数量仅 0.6B,适合在普通服务器甚至高性能 PC 上运行,是私有化部署的理想选择。
部署环境准备(Windows 服务器)
- 操作系统:Windows (开发测试)
- Python 版本:
≥ 3.9,本文使用Python 3.13.5 - Conda环境:本文使用
conda 25.11.0 - 网络环境:国内,无法直连
huggingface.co
由于 Hugging Face 官方站点在国内访问受限,我们将借助 HF-Mirror 这一公益镜像加速下载。
步骤一:安装必要依赖(Conda环境)
首先,安装 Hugging Face 官方工具库:
shell
pip install -U huggingface_hub接着,安装用于加载和推理嵌入模型的 sentence-transformers 库(注意版本要求):
shell
# 要求 transformers >= 4.51.0, sentence-transformers >= 2.7.0
pip install sentence_transformers步骤二:配置 Hugging Face 镜像与缓存目录
为实现高速、稳定的模型下载,需设置两个关键环境变量:
| 环境变量 | 作用 |
|---|---|
HF_ENDPOINT |
指定 Hugging Face 的镜像地址 |
HF_HOME |
指定模型缓存根目录 |
在 Windows 中,可通过以下方式设置
-
临时方案(以 PowerShell 为例):
powershell$env:HF_ENDPOINT = "https://hf-mirror.com" $env:HF_HOME = "D:\HuggingFaceRepo" # 自定义 -
永久方案:
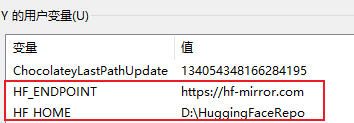
建议:将上述命令写入系统环境变量,或在启动脚本中自动设置,确保每次运行都生效。
验证环境变量是否配置成功:
python
import os
print("HF_ENDPOINT env:", os.environ.get('HF_ENDPOINT'))
print('HF_HOME env :', os.environ.get('HF_HOME'))预期输出:
HF_ENDPOINT env: https://hf-mirror.com
HF_HOME env : D:\HuggingFaceRepo步骤三:下载并加载 Qwen3-Embedding-0.6B 模型
使用 sentence-transformers 自动从镜像站下载模型:
python
from sentence_transformers import SentenceTransformer
# 自动从 hf-mirror.com 下载(因 HF_ENDPOINT 已配置)
qwen3_embedding = SentenceTransformer("Qwen/Qwen3-Embedding-0.6B")
# 测试推理
resp = qwen3_embedding.encode("你好")
print(resp)
print(len(resp))输出示例:
[-0.01935214 -0.00704146 -0.01177389 ... 0.03707496 0.01386148 0.0450698 ]
1024⚠️ 默认使用 CPU 推理。若服务器配备 NVIDIA GPU 且已安装 CUDA,可添加
device="cuda"参数加速:
pythonqwen3_embedding = SentenceTransformer("Qwen/Qwen3-Embedding-0.6B", device="cuda")
模型存储位置说明
下载完成后,模型文件将缓存在:
D:\HuggingFaceRepo\Qwen_Qwen3-Embedding-0.6B该路径结构由 sentence-transformers 自动生成。后续所有对该模型的调用都会直接读取本地缓存,无需重复下载。
在langchain中整合
python
from langchain_core.embeddings import Embeddings
from sentence_transformers import SentenceTransformer
class CustomQwen3Embedding(Embeddings):
"""
自定义Qwen3-Embedding模型
"""
def __init__(self, model_name="Qwen/Qwen3-Embedding-0.6B"):
self.model = SentenceTransformer(model_name)
def embed_documents(self, texts: list[str]) -> list[list[float]]:
return self.model.encode(texts).tolist()
def embed_query(self, text: str) -> list[float]:
return self.embed_documents([text])[0]
if __name__ == '__main__':
qwen3_embedding = CustomQwen3Embedding()
resp = qwen3_embedding.embed_query("你好")
print(resp)
print(len(resp))参考资料
自此,本文分享到此结束!!!