一般方法(基础的写法):
1.url:
2.解析获取数据
3.翻页
4.下一页继续采集【下一页数据与上一页是否完全相同】
具体代码如下:
import time
import subprocess
from playwright.sync_api import sync_playwright
'''
先采集一页
翻页
'''
# 启动浏览器
path = r"C:\Users\six\AppData\Local\ms-playwright\chromium-1187\chrome-win\chrome.exe"
params = "--remote-debugging-port=7899"
cmd = f'"{path}" {params}'
subprocess.Popen(cmd)
# 等待浏览器启动完毕
time.sleep(2)
# 连接浏览器
with sync_playwright() as pw:
browser = pw.chromium.connect_over_cdp("http://127.0.0.1:7899")
context = browser.contexts[0]
page = context.pages[0]
# 访问目标网站
page.goto('https://movie.douban.com/top250?start=200&filter=')
for page_no in range(15):
page.wait_for_timeout(1000)
# 定位所有电影信息
li_list = page.locator('//*[@id="content"]/div/div[1]/ol/li').all()
# print(li_list)
for li in li_list:
num = li.locator('xpath=./div/div[1]/em').inner_text()
title = li.locator('xpath=./div/div[2]/div[1]/a/span[1]').inner_text()
score = li.locator('xpath=./div/div[2]/div[2]/div/span[2]').inner_text()
img_url = li.locator('xpath=./div/div[1]/a/img').get_attribute("src")
print(num, title, score, img_url)
page.wait_for_timeout(1000)
# 定位 后页 按钮
next_ele = page.locator('//*[@id="content"]/div/div[1]/div[2]/span[3]/a')
if next_ele.count() != 0:(即存在的情况下)
# 滚动到下一页按钮所在位置
next_ele.scroll_into_view_if_needed()
#滚动到当前页面可见
page.wait_for_timeout(1000)
#停顿一下
# 存在下一页
print("存在下一页")
next_ele.click()
else:
print("不存在下一页了!!")
break
input("...")如何判断是否采集完毕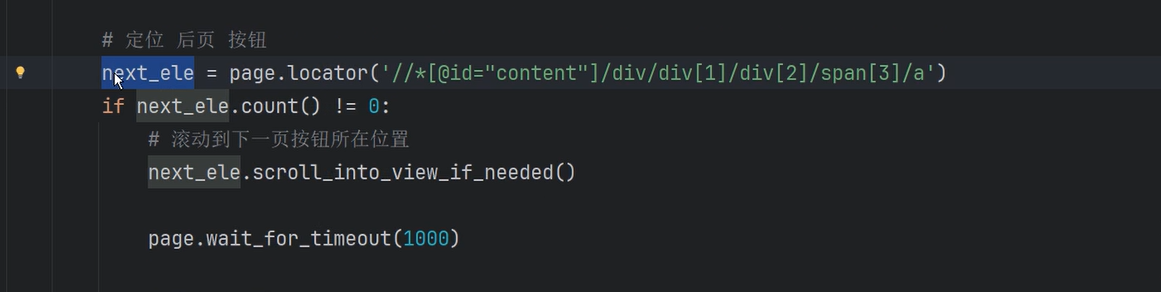
通过这个按钮是否存在来判断的,但如果是其他网站呢,因为这个案例可以做,其他不一定
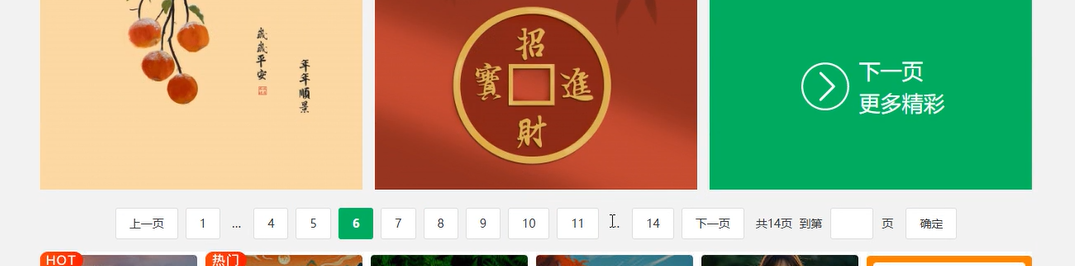
像这样...的情况用这种方法可能会出错
接下来进行网易云的数据提取分析,要保证登陆状态,用本地启动的方式
具体的代码(完整代码)
import time
import subprocess
from playwright.sync_api import sync_playwright
'''
注意事项:
1. 评论数据存在于 iframe 中,需要先切换到 iframe
2. 页面中的 id 值有产生变化,定位的时候需要找固定的值定位
'''
# 启动浏览器
path = r"C:\Users\six\AppData\Local\ms-playwright\chromium-1187\chrome-win\chrome.exe"
params = "--remote-debugging-port=7899"
cmd = f'"{path}" {params}'
subprocess.Popen(cmd)
# 等待浏览器启动完毕
time.sleep(2)
# 连接浏览器
with sync_playwright() as pw:
browser = pw.chromium.connect_over_cdp("http://127.0.0.1:7899")
context = browser.contexts[0]
page = context.pages[0]
# 访问目标网站
page.goto('https://music.163.com/#/song?id=204072')
# # 测试,查看页面数据
# with open("wyy.html", "w", encoding="utf-8") as f:
# f.write(page.content())
# 切换 iframe
frame = page.frame("contentFrame")
# # 测试,查看页面数据
# with open("wyy.html", "w", encoding="utf-8") as f:
# f.write(frame.content())
# 定位评论数据
div_list = frame.locator('//div[@class="cmmts j-flag"]/div').all()
for div in div_list:
content = div.locator('xpath=.//div[@class="cnt f-brk"]').all_inner_texts()
print(content)
# if div.count() != 0:
# print("存在div")
# else:
# print("不存在div!!")
# # 定位 下一页 按钮
# # next_ele = frame.locator('//*[@id="auto-id-oWpR0XOSkKJpJFBE"]')
# next_ele = frame.locator('//a[text()="下一页"]')
#
# if next_ele.count() != 0:
# # 滚动到下一页按钮所在位置
# next_ele.scroll_into_view_if_needed()
# page.wait_for_timeout(1000)
# # 存在下一页
# print("存在下一页")
# # next_ele.click()
# else:
# print("不存在下一页了!!")
input("...")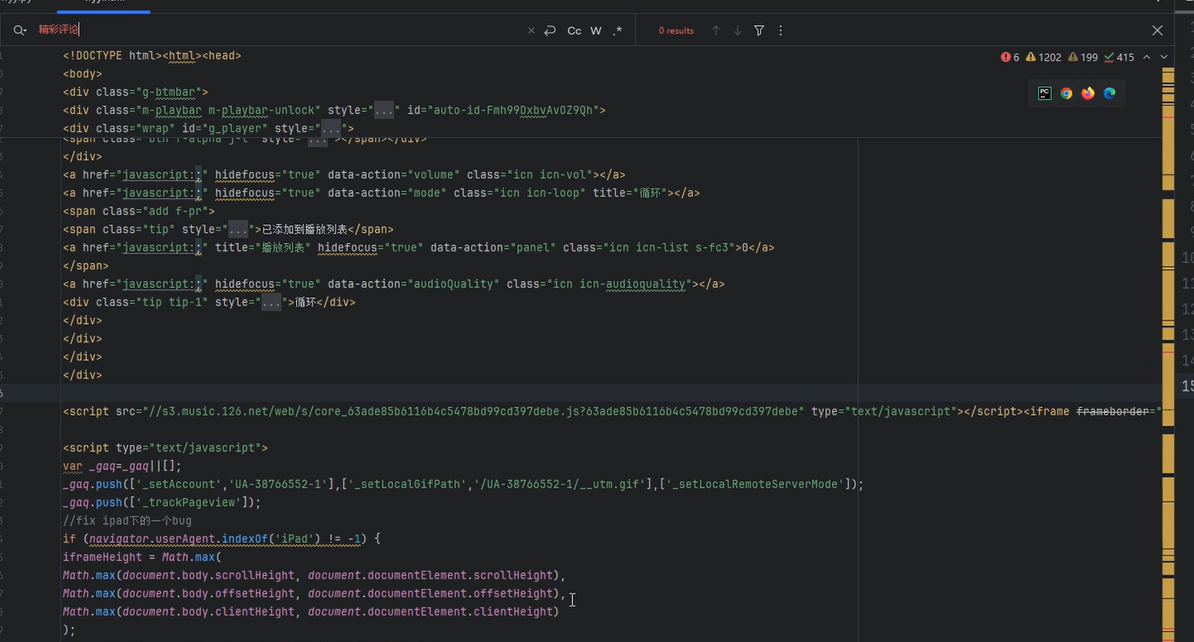
采集到的数据中进行搜索,却发现找不到内容,可能是iframe,因为这也可能导致找不到这个元素,在网页中进行搜索iframe,发现找到了好几个iframe,说明其存在于iframe,z在iframe中进行搜索
切换到iframe但是还没有,可能是定位的问题,看看是否变成iframe中的数据
涉及页面数据的变化
那怎么办?通过ID之外进行定位
在这里发现class的znxt没有发生变化(定位不到一定要看相应的文本)
在复制中完整的xpath如果发生变化,就不能再用
最后得到,这里其实是同级关系