一、动机 & 问题背景
作者提出了一个可扩展的数据科学知识平台 KGLiDS,借助机器学习和知识图谱,把数据科学流程中所有这些数据、步骤、函数之间的语义和关联都抽象出来,形成一个能直接用来自动化处理的知识结构。
近年来,学术界和工业界对应用数据科学技术分析海量数据的兴趣日益浓厚。在此过程中,产生了大量的工件(数据集、pipeline脚本等)。然而,目前还没有系统地尝试全面收集和利用这些工件中隐含的所有知识和经验。因此,本文提出了一种可扩展的数据科学知识图谱平台,KGLiDS。
二、KGLiDS 方法概览
这套平台分成 三大核心模块:
KG Governor:知识获取与语义抽象(KGLiDS的核心大脑)
KGLiDS Storage:知识存储与模型存储
KGLiDS Interfaces:面向用户的自动化接口

图1 KGLiDS主要组件概述
1)KG Governor,用于执行管线抽象、数据分析与知识图谱构建;
2)KGLiDS Storage,用于存储RDF-star格式的知识图谱、各种嵌入表示以及GNN等模型;
3)KGLiDS Interfaces,一个面向不同使用场景(如数据发现、数据清洗与转换等)的 Python 接口库。
1、KG Governor --- KGLiDS 的核心大脑
KG Governor 是整个平台中最关键的部分,负责 把来自代码与数据的 artefacts 解析、理解、抽象为统一的语义图。
它包含 三大组件:
(A) Pipeline Abstraction
从Kaggle Notebooks / Python 代码中抽取结构化语义图(Pipeline Graph);即通过分析Pipeline脚本、编程库文档以及数据集的使用方式,提取并建模Pipeline的语义结构。
(B) Data Profiling
收集数据集的元数据,并为数据集中的列与表学习语义表示(embeddings);即为每一列、每一表、每个数据集生成标准化的embedding表示与类型和统计信息。
© Knowledge Graph Construction(知识图谱构建)
把上一步得到的 pipeline 语义 + data profiling 结果合并成 RDF-star 知识图谱。构建和维护知识图谱及各种嵌入。在知识图谱构建过程中,Global Graph Linker 会执行节点间的链接预测,例如识别某个pipeline中使用的表是否在实际数据集中存在,并建立对应链接。
2、KGLiDS Storage --- 知识存储中心
KGLiDS Storage 是存储层,负责持久化:
1、RDF-star 格式的知识图谱(LiDS Graph)
- 统一模型:Dataset Graph + Pipeline Graph + Library Graph
- 支持 RDF-star triple(可在边上存 metadata)
- 支持 SPARQL 查询
- 支持 schema-based 推理
2、Embedding 存储
- Column embedding
- Table embedding
- Dataset embedding
- Pipeline embedding(可选,对 Statement 进行聚合)
3、模型存储
- 数据清洗预测模型(cleaning model)
- 数据转换预测模型(transformation model)
- AutoML 模型与超参推荐模型
应用阶段直接调用。
3、KGLiDS Interfaces --- 系统的对外接口层
接口层基于上一层的知识与模型,支持多种自动化功能。
分为以下功能模块:
- Dataset Discovery(搜索数据集)
- Library Discovery(搜索库)
- Pipeline Discovery (搜索Pipeline)
- Data Transformation Recommendation(数据预处理推荐)
- Classifier Recommendation(分类器推荐)
- Hyperparameter Recommendation (超参数推荐)
下面会详细介绍这三大组成部分。
三、KG Governor --- KGLiDS 的核心大脑
KG Governor 是 KGLiDS 的核心模块,负责捕捉数据集、数据科学 Pipeline、以及程序库(libraries)的语义信息,从而构建三类知识图谱:
- Pipeline Graph(管道图)
- Library Graph(库图)
- Dataset Graph(数据集图)
并通过语义关联将三者联通,形成统一的数据科学知识图谱(LiDS Graph)。
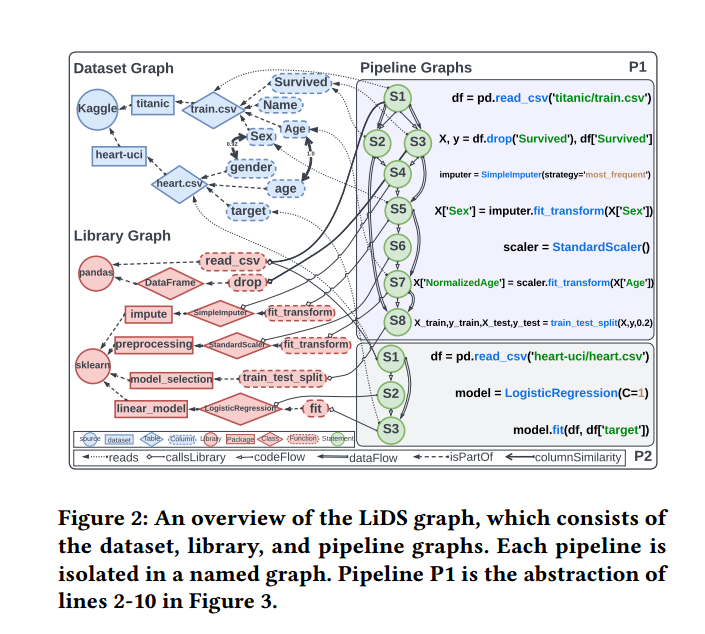
图2 LiDS图 概述
1. Pipeline 图(Pipeline Graphs)
抽象 pipeline 代码,捕捉其语义、结构和对数据的操作。
KGLiDS 对数据科学pipeline(即代码或脚本)进行抽象,以捕捉其语义。一个pipeline可以执行一个或多个数据科学任务,例如数据分析、可视化或建模。
pipeline可以抽象为 控制流图(control flow graph),其中代码语句是节点,边表示指令或数据的流动。
pipeline抽象的目标是获得一种 语言无关的语义表示,包括pipeline内部的代码与数据流、对内置或第三方库的调用,以及调用中使用的参数。这些信息可以通过 动态或静态程序分析 获得。

图3 KGLiDS 数据科学Pipeline的示例
抽象目标
构建一种 语言无关(language-agnostic) 的语义表示,包含:
- 控制流(Control Flow)
- 数据流(Data Flow)
- 库调用与参数
- 输入输出关系
每个 Pipeline 生成一个独立的 Named Graph。
抽象技术
动态分析 :通过执行pipeline并在运行时检查每条语句的内存痕迹,获取详细而准确的信息。(需搭建运行环境,如库已废弃等情况时不可行)
静态分析 :无需执行pipeline即可分析,适合大规模pipeline。(在动态语言如 Python、R中准确性较低)
KGLiDS 结合静态分析、库文档和数据集使用情况分析,形成丰富的语义抽象,捕捉数据科学pipeline的核心概念。将pipeline抽象分解为若干独立任务,每个任务生成一个抽象图(每条pipeline脚本对应一个named graph)。
(1) 静态代码分析
- 使用 Python AST / R CodeDepends 等轻量工具提取:
- 语句(节点)
- 代码流:语句执行顺序
- 数据流:变量读写链路,读取或操作同一变量的语句
- 控制结构:if / for / while / import / 函数调用
- 语句文本:每条语句的源代码
- 忽略无关语句(print、head、summary 等)。
(2) 文档增强(Doc-driven Enhancement)
静态分析无法识别返回类型(如 pd.read_csv 返回 DataFrame)。
KGLiDS 利用library文档补全:
用于构建 library graph 和更准确的 pipeline 语义。
(3) 数据集使用预测(Dataset Usage Prediction)
将pipeline语句与使用的数据表或列关联,实现数据科学平台的新用例。
包括:预测数据集使用、图链接验证
2. Library 图(Library Graph)
利用库文档对静态分析结果进行丰富:记录调用库、参数名与参数值(包括默认值)、返回变量的数据类型、为每个类与方法生成 JSON 文档,包含输入参数、默认参数、返回数据类型
library图(library graph)也由此生成,可用于分析库使用频率等数据科学洞察
3. Dataset 图(Dataset Graph)
提供全局数据模式,描述所有数据集(表/列)的语义与关系。
构建过程分为:
(1)Dataset Profiling(特征分析)
对每个列生成 profile,包含:
- 细粒度数据类型 T(7 类)
- 列嵌入(CoLR Embedding)
- 统计信息 S
- 元数据 M
- 利用 PySpark 支持大规模并行处理。
(2)数据类型推断(7 类)
仅同类型列之间才比较,降低误报:
整数(integer)
浮点数(float)
布尔值(boolean)
日期(date)
命名实体(named entities, 如人名、地点、语言)
自然语言文本(natural language texts, 如评论、产品评价)
通用字符串( generic strings, 不属于前述类别,如邮政编码或 ID)
NER 模型基于 OntoNotes 5(18 类实体)。
(3)CoLR 列嵌入生成(Column Learned Representation)
根据列的细粒度类型和实际内容,通过预训练的 embedding 模型为每列生成对应的CoLR。
对列(column)随机抽样约 10% 的数据值以及列名(column name)作为语义输入得到CoLR编码。
CoLR 优势:
(1)在列内容相似度预测上比人工设计的元特征更准确。
(2)可以进行数据发现,而无需暴露数据的原始内容(对企业很重要)。
(3)固定长度小向量降低存储与内存需求,与数据规模无关。
(4)列相似性判定
两列被认为存在相似性关系的条件是:相似度得分高于预定义阈值。
仅在同类型列中进行 pairwise 计算(MapReduce):
相似性由两个部分组成:
① 标签语义相似(Label Similarity)
- 使用 GloVe embedding
- 使用 semantic similarity 算法
即基于列名的相似性,使用 GloVe 词向量与语义相似性方法;用于检测列名相似(如"age" vs "Age_years")
② 内容相似(Content Similarity)
对非布尔列:Cosine similarity(使用 CoLR embeddings)即基于列嵌入的余弦相似度
对布尔列:True ratio 之差
用户设置 3 个阈值:α(标签)、β(内容)、θ(联合阈值)
影响 precision/recall:
阈值高 → 更准确但更少边
阈值低 → 更多边但可能有误匹配
(5)表嵌入(Table Embedding)
数据集被分解为独立的表。每个表被分解为一组列,其中大多数计算都是在列中完成的。
Table Embedding(表级嵌入)定义方式:
Avg(数值列 int\&float) \| Avg(类别列) \| Avg(日期列) \| Avg(文本列) \| Avg(NER列) \| Avg(其他类型列)
将表的所有列按 6 种细粒度类型分组,每组聚合(average)CoLR embeddings,平均池化后再将所有类型的 embedding 拼接得到 table embedding
(6) Dataset Graph 构建
LiDS 图依据我们设计的本体(ontology)构建与维护。
表的可联合性与可连接性
KGLiDS 利用列之间预测的相似性关系识别可 union 或 join 的表:
Unionable:至少有一对列具有高标签相似性
Joinable:至少有一对列具有高内容相似性
两表之间的相似度得分基于:
相似列的数量
列之间的相似度得分
数据集图基于这些关系构建完成,使得pipline图中的操作能够与数据集图中的列和表准确关联,为进一步的数据科学任务(如数据清洗、集成和发现)提供基础。
最终:
Dataset Graph 由 列节点 + 表节点 + 相似性边 组成。
| 实体类型 (Entity) | 向量化方法 (Method) | 使用模型/技术 (Model/Tech) | 向量维度 (Dim) | 维度是否固定 | 说明 |
|---|---|---|---|---|---|
| 列(Column) | 深度模型学习列值语义 + 列名嵌入 | CoLR(hθ) | 300 维 | 固定 | 通过列值采样 + 列名 embedding 生成 300 维列向量 |
| 表(Table) | 按列类型分桶 → 逐桶平均池化 → 拼接 | type-bucket pooling | 1800 维 | 固定 | 6 类列类型 × 每类 300 维;缺失类型使用零向量填充 |
| 数据集(Dataset) | 多表 embedding 聚合(平均池化 / attention 等) | pooling over table embeddings | 1800 维 | 固定 | 所有表 embedding 维度一致,聚合后仍为固定维度 |
4. pipeline / library / dataset 三图的联通
KG Governor 通过两类关系将三图联通:
Pipeline → Library(调用关系)
Pipeline → Dataset(数据访问关系)
Dataset → Dataset(列级相似)
Library → Library(文档结构、类方法)
最终形成统一的 LiDS graph
最终结构
KG Governor(KGLiDS大脑)
| 图类型 (Graph Type) | 内容 (Content) | 构建方法 (Construction Method) |
|---|---|---|
| Pipeline Graph | pipeline 抽象、控制流、数据流、库调用 | 静态分析 · 文档解析 · 数据使用分析 |
| Library Graph | 库、类、方法、参数、类型、使用频率 | 文档分析 · pipeline 调用关系抽取 |
| Dataset Graph | 表与列的语义结构、列相似性、表间联结关系 | Profiling · CoLR 嵌入 · 相似性预测 |
三图互联 → 构成 LiDS Graph
→ 支撑 KGLiDS 的数据发现、EDA、AutoML、推荐与自动化能力。
四、KGLiDS Storage --- 知识存储中心
KGLiDS 为关联式数据科学(Linked Data Science)构建了一个统一的知识存储中心,其核心是作者设计的 LiDS Ontology(LiDS 本体)。该本体用于对数据科学平台中的主要实体及其关系进行结构化、语义化建模,最终存储为可查询的知识图谱 LiDS Graph。
1. LiDS Ontology:概念模型层
LiDS 本体是对数据科学生态中各类对象进行概念化建模的结构,包括:
主要实体类型(13 个类)
数据类
- datasets
- tables
- columns
编程库类(libraries)
管线脚本类(pipeline scripts)包括与管线语句(statements)相关的辅助节点
这些类一起覆盖了一个数据科学平台中最关键的资产:
数据 → 操作流程 → 代码依赖 → 可执行步骤。
2. 对象属性与数据属性
本体中定义了:
19 个对象属性
→ 表示实体之间的语义关系,例如
"table 属于 dataset"、
"column 使用某个库函数生成"、
"某条 statement 引用了某个 column"。
22 个数据属性
→ 描述每个实体的特征,如列的数据类型、统计信息、脚本节点的代码片段等。
3. 使用 OWL 2
LiDS Ontology 使用 OWL 2 (Web Ontology Language) 定义:
具有跨平台、跨系统的互操作性
自然支持数据共享
能将结构化数据、代码分析结果以及机器学习语义统一到一个知识框架中
OWL 的标准化结构使 LiDS 本体:
→ 可被广泛的三元组存储、知识图谱系统解析
→ 可通过 SPARQL 等标准查询接口进行访问
4. 实例化本体:LiDS Graph
当 KGLiDS 将实际的数据科学资源填充进本体后,就生成了 LiDS Graph(LiDS 图)。
KGLiDS 使用 RDF 标准 来表示 LiDS Graph,并且:
为所有节点和边都分配 URI(统一资源标识符)
保证图结构可 Web 访问、可跨平台共享
支持数据、代码、管线之间的联动查询和语义推理
例如:
某数据列(column)节点会链接到其统计特征
某 pipeline step 会链接到它所操作的数据列
libraries 节点会连接到脚本调用的库函数
数据集间的 join/union 关系也会以图形式呈现
5. 存储中心的核心作用
LiDS Storage 作为知识存储中心实现了:
数据资源的全局结构化索引
数据 → 操作 → 代码之间的跨实体关联链接
为上层模块(数据发现、管线推荐、EDA 等)提供知识基础
通过统一的 RDF/OWL 规范实现跨系统可移植性
五、KGLiDS Interfaces --- 系统的对外接口层
KGLiDS 的接口层负责向数据科学家提供可直接使用的能力,在不暴露底层知识图和嵌入细节的情况下,实现从数据探索到模型训练的全流程支持。接口设计强调 可编程性、可交互性、可重用性。
接口层主要由下面件构成:
1. 数据集搜索与联合(Dataset Search & Union)
按列搜索表
通过关键词在 LiDS 图中搜索数据集
支持 AND/OR 组合条件
table_info = search_keywords([['heart','disease'], 'patients'])返回相关数据集,如 heart-failure-prediction、heart-failure-clinical-data
发现可合并列(Unionable Columns)
自动推荐不同表中可以匹配的列,形成合并表的 schema
find_unionable_columns(table_info.iloc[0], table_info.iloc[1])连接路径发现(Join Path Discovery)
当目标表不可直接 join 时,推荐中间表并展示可能的 join 路径
get_path_to_table(table_info.iloc[0], hops=2)支持更复杂操作,如寻找两表之间的最短路径
2. 库发现(Library Discovery)
统计最常用库
使用库图(library graph)统计调用次数
get_top_k_library_used(k)
get_top_used_libraries(k=10, task='classification')可快速了解分类任务中最常用的库,如 Pandas、Scikit-learn、XGBoost
生成可视化柱状图
3. 管道发现(Pipeline Discovery)
查找包含特定库或方法的示例管道
get_pipelines_calling_libraries(
'pandas.read_csv',
'xgboost.XGBClassifier',
'sklearn.metrics.f1_score'
)返回匹配管道列表及相关元数据,帮助数据科学家参考现有实践
4. 数据转换推荐(Transformation Recommendation)
在建模前推荐适合的数据预处理和转换操作
recommend_transformations(dataset='heart-failure-prediction')返回如 MinMaxScaler、OneHotEncoder 等转换操作,便于生成更具代表性的数据集
5. 分类器推荐(Classifier Recommendation)
根据数据集和任务类型推荐可用的分类模型及评分
model_info = recommend_ml_models(dataset='heart-failure-prediction', task='classification')帮助数据科学家快速选择合适模型进行训练
6. 超参数推荐(Hyperparameter Recommendation)
提供选定分类器的超参数配置参考
recommend_hyperparameters(model_info.iloc[0])基于成千上万管道的最佳实践进行优化,降低手动调参成本
KGLiDS Interfaces 将底层知识图、嵌入搜索和 GNN 自动化模型封装为高可用的 Python API,使数据科学家能够以交互式方式完成从数据探索、管道分析到自动建模的全流程任务,同时确保企业级的互操作性与可管理性。
原文链接
KGLiDS: A Platform for Semantic Abstraction, Linking, and Automation of Data Science
kglids-GitHub