| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文名称 | π0 |
| 2 | 发表时间/位置 | 2024 |
| 3 | Code | Our First Generalist Policy |
| 4 | 创新点 | 1:混合专家 (MoE) 风格的 VLA 设计 VLM 基座(大脑): 基于 PaliGemma (3B),继承互联网规模的视觉和语义知识。 Action Expert 动作专家(小脑): 引入一组独立的权重(300M),专门处理机器人的本体感知(输入)和动作生成(输出)。 混合 Loss 训练: 文本 Token(离散): 使用交叉熵损失(Cross-Entropy),负责理解指令和推理。 动作 Token(连续): 使用流匹配损失(Flow Matching),负责生成精确轨迹。 在同一个 Transformer 骨干中,同时优化这两种性质完全不同的目标。 2:Flow Matching (流匹配) 替代 Diffusion 传统的 Diffusion 推理慢(需几十步去噪)、轨迹抖动。Flow Matching 学习从噪声到数据的"直线路径",推理仅需 10步 (相比 Diffusion 的 50+ 步),实现了 50Hz 的高频控制。而且,基于常微分方程(ODE),生成的动作轨迹天然平滑,适合叠衣服等精细操作。能很好地建模多种可能的动作分布(比如既能左手拿也能右手拿)。 3:预训练与后训练的分离 Pre-training (预训练),海量(10,000小时)、多样、含噪声(包含失败和纠正)。 学习通用的物理规律,最重要的是学会 Recovery(从错误中恢复),让模型变鲁棒。 Post-training (后训练),少量、高质量、专家级演示。 学习 Fluency(流畅性),让模型动作像专家一样。 4:跨具身大一统 使用了 10,000+ 小时** 的机器人操作数据,是目前已知最大的机器人预训练数据集。通过使用 Max Padding(最大化填充)。统一设定为最大维度(18维),不够的补零。一个模型权重,可以控制 7 种不同构型的机器人。 定义了如 "Bussing"(清理餐桌)这种包含数十个子步骤的长程任务,并通过引入 High-level VLM 辅助规划,证明了模型处理 5-20 分钟长任务的能力。 |
| 5 | 引用量 | 基于PaliGemma 模型,感觉全身通用才是现阶段的论文走向。动作生成也就是两种方式,1,扩散模型方式。2,flow matching方式。 |
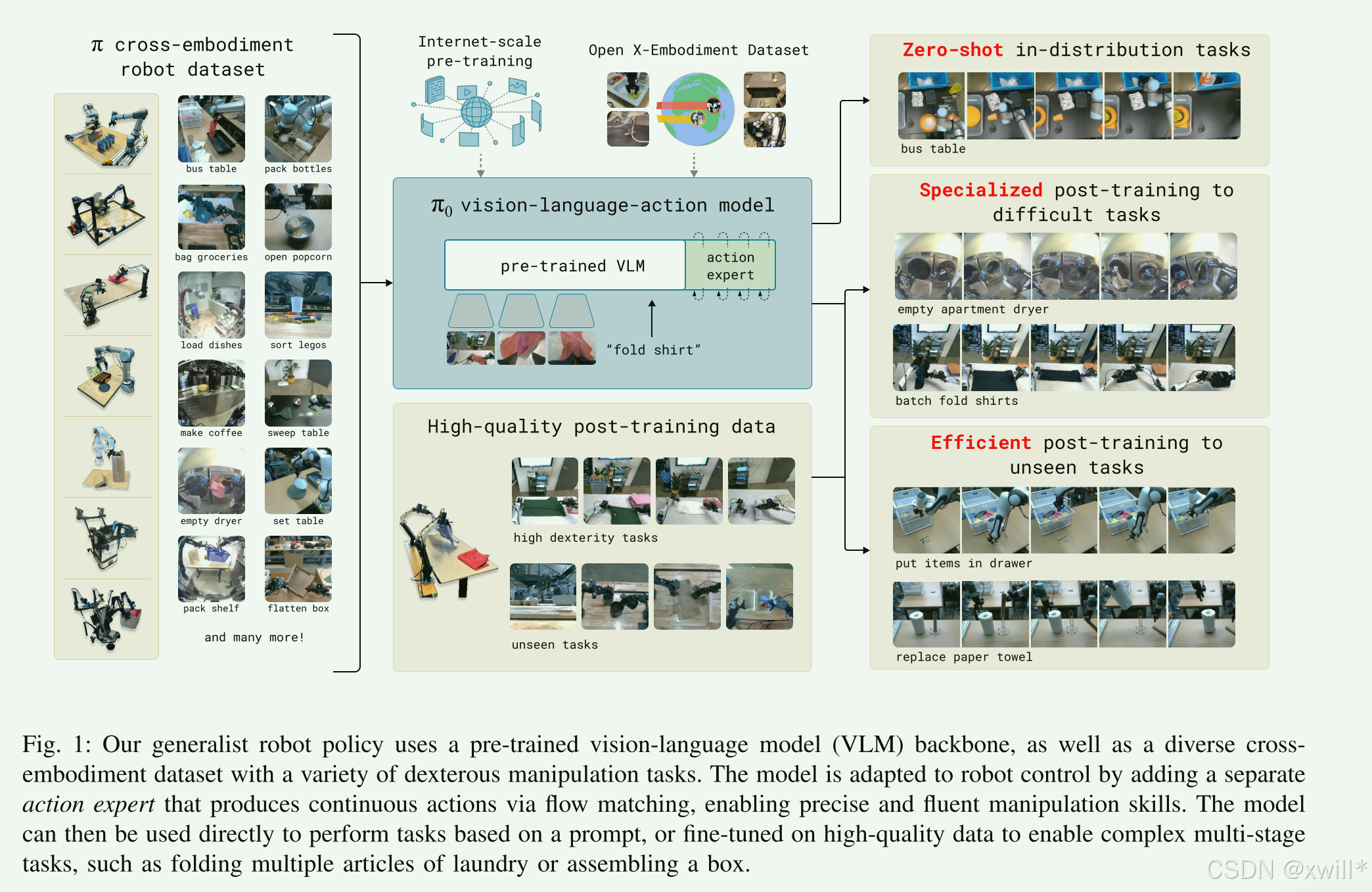
一:提出问题
要将机器人学习提升到构建有效现实世界系统所需的通用水平,在数据 、泛化能力 和鲁棒性 方面仍面临重大障碍。要走**Generalist Robot Policies(通用机器人策略)*的路子,也就是打造所谓的*Robot Foundation Models(机器人基础模型) 。这意味着不再为每一个任务单独训练一个小模型,而是训练一个大模型来解决所有问题。本文提出了一种建立在预训练视觉语言模型的基础上,动作生成则采用流匹配的架构(Flow Matching Architecture,是一个生成式AI的概念。以往的机器人动作生成常用Diffusion(扩散模型),而Flow Matching是比Diffusion更新、效率通常更高的一种生成范式。)
Flow Matching(流匹配) 是最近生成式 AI 领域非常火的一个概念,很多人认为它是 Diffusion Model(扩散模型)的强力竞争者,甚至是"下一代"生成范式。--总结了这么多的论文,其实目前也就这两种主流的方式来生成动作。
如果说 Diffusion(扩散模型) 是把一堆无序的沙子(噪声)通过"一步步剔除杂质"慢慢还原成一座沙雕(图像/动作); 那么 Flow Matching(流匹配) 就是直接计算出了每一粒沙子从"沙堆状态"移动到"沙雕状态"的最佳直线路径和速度,然后推着它们走过去。对比一下两种方式:
Diffusion (扩散模型) ------ "醉汉回家"
原理: 扩散模型通常模拟的是一个去噪过程。它像是一个醉汉,虽然大致知道家的方向,但走起路来摇摇晃晃(随机性强)。它需要走很多很多小步,每一步都要修正一下方向(去噪),最后也能到家。
缺点: 路径是弯弯曲曲的,推理步数多(计算慢),生成的动作轨迹有时候会抖动。
Flow Matching (流匹配) ------ "老司机导航"
原理: Flow Matching 不去模拟"去噪"的过程,而是直接学习一个**"流(Flow)"**。你可以把这个流想象成一条河流的水流,或者风洞里的气流。
做法: 模型会学习一个向量场(Vector Field),也就是告诉空间中每一个点:"如果你在这里,你应该往哪个方向走,速度是多少"。
优势: Flow Matching 倾向于学习笔直的路径。它就像老司机开车,方向盘打得很稳,直接走直线从起点(噪声)开到终点(有效动作)。
在数学上,Flow Matching 试图解决的是"如何把简单的概率分布(如高斯噪声)变成复杂的概率分布(如机器人动作数据)"。
定义"流": 想象时间 t 从 0 到 1。t=0 时是噪声,t=1时是数据。
定义"速度": 模型不仅仅预测下一步在哪,而是预测当前时刻粒子的速度向量(Velocity Vector)。这其实就是一个常微分方程(ODE)。
Matching(匹配): 训练的时候,我们强行让模型去"模仿"一条从噪声直达数据的直线。
如果不加约束,从噪声变到数据有无数种路径(甚至可以绕地球一圈再变回来)。
Flow Matching 使用了一种叫做 Optimal Transport(最优传输) 的思想,强制模型学习那条最短、最直的路径。

1:本文的核心逻辑还是效仿NLP、CV领域去做预训练,不要一个专才,而是一个通才。 大规模多样化预训练 + 针对性微调 > 针对性数据从头训练。
以前的做法是 只有叠衣服的数据,就只训练叠衣服的模型。结果:数据太少,换件衣服就不会叠了。π0的做法: 不管是叠衣服、拧螺丝还是端盘子,所有机器人的数据一股脑拿来预训练 。然后只用一点点叠衣服的高质量数据来微调。这样做可以解决数据稀缺 (大家的数据凑一起就多了)和鲁棒性(见多识广,不容易翻车)。
2: π0的核心点
在规模上, 大力出奇迹。如果数据不够多,模型不够大,这种"通用智能"是涌现不出来的。π0 用了 10,000+ 小时 的机器人数据,这在学术界是非常惊人的量级。
在架构上,VLA + Flow Matching的方式。
-
大脑 (VLM): 继承了互联网知识。比如模型看到"把苹果放进微波炉",它得先认识什么是苹果,什么是微波炉,这部分知识不需要机器人数据教,VLM已经懂了。
-
小脑/手 (Action Expert with Flow Matching):
-
Cross-embodiment(跨具身): 模型能够控制单臂、双臂、移动底盘。这意味着模型理解的是"操作逻辑"而不是死记硬背电机的转动。
-
Flow Matching & Action Chunking: 为了实现 50 Hz 的高频控制和 Dexterity(灵巧性) 。叠衣服这种软体操作需要极其细腻的动作,传统的简单策略做不到,Flow Matching 生成的平滑轨迹在这里起了决定性作用。
-
3:训练-采用预训练和微调(后训练)两步骤的方法。
**只用高质量数据(全是成功的演示),机器人变成了温室里的花朵。一旦它稍微偏离了路线,因为它从来没见过"失败"和"修正"的数据,它就不知道怎么救回来(Recover)。**只用低质量/多样化数据(包含各种尝试和失败):** 机器人变得很皮实,但也变得很笨拙、效率低。
π0 **的策略:**先看海量数据(包含低质量的、失败的),学会世界是咋回事,学会跌倒了怎么爬起来(Recovery behaviors)。再看少量高质量数据:学会怎么做才是最完美、最高效的。
二:解决方案
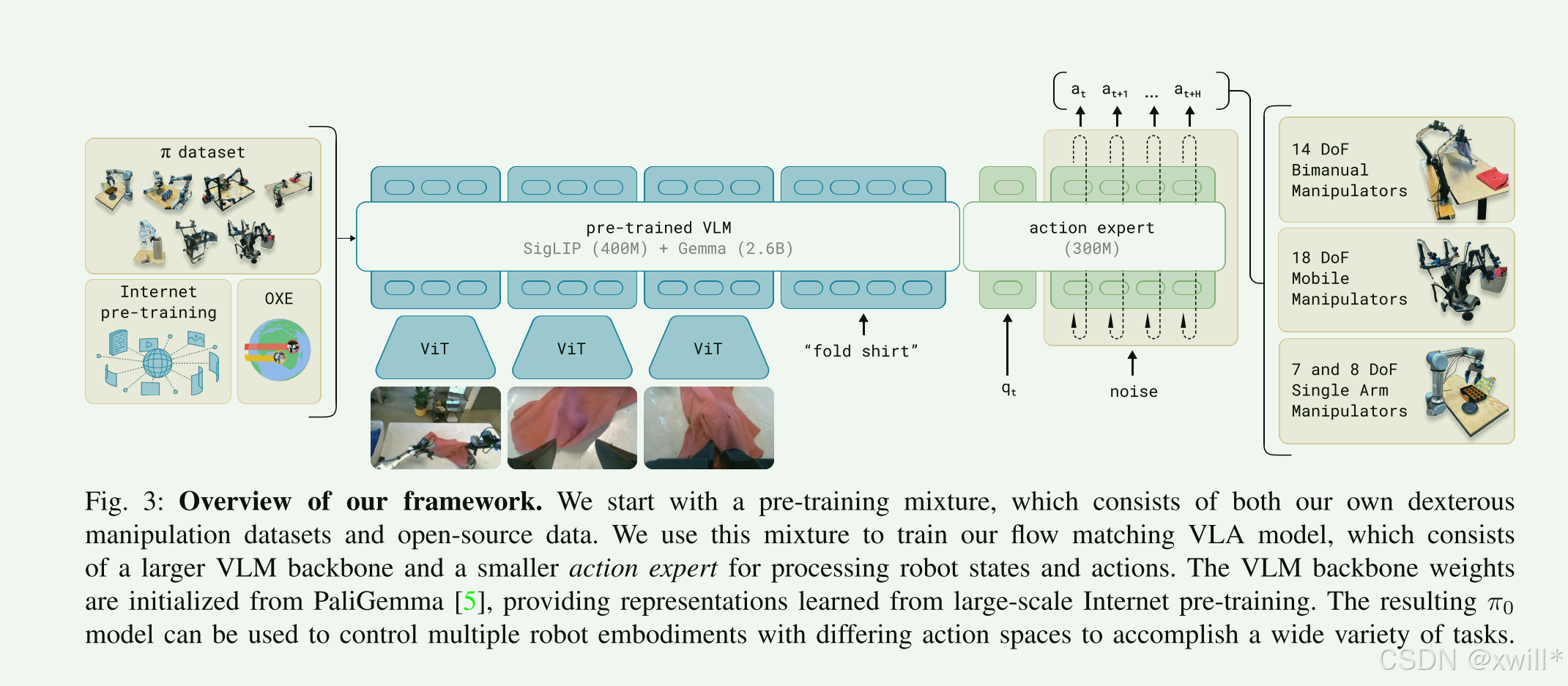
作者先构建了预训练混合数据集,在与训练阶段使用了多样化的语言标签,结合了任务名称和片段注释。对于复杂的任务,采用后训练的方式,利用高质量数据针对特定下游任务进行微调。模型基于PaliGemma 视觉-语言模型,添加了流匹配来生成动作分布,从而经过预训练后变为π0。
1:π0模型
PaliGemma (3B) 是一个30亿参数在LLM里算"小模型"。但在机器人领域,实时性 (Real-time control) 是命门。如果用 GPT-4 这种级别的模型,推理一次可能要几秒钟,机器人早就撞墙了。3B 是智能和速度的平衡点。因此选为基座模型。
而语言/图像(离散的、语义的)和机器人动作(连续的、精确的电机控制)是两种完全不同的数据模态。如果强行用同一组神经网络权重去处理,可能会"顾此失彼"。因此本文采用的是类似于MoEt混合专家的思想,为机器人的特定任务和动作状态Token使用一组单独的权重来提升性能。大脑(通用部分,也就是 PaliGemma**)用来处理图像和文本(继承自 PaliGemma),小脑 (Action Expert,专用部分), 专门有一组独立的权重(300M参数),只负责处理 qt (身体状态) 和 At (动作)。**
1.1 动作生成机制
受Transfusion 架构 启发,即使用多个目标训练单个 Transformer。离散 Token(文本,而视觉只是被读取(encode),不会被生成(decode),所以不需要用任何生成损失函数。)的处理都使 用 Cross-Entropy Loss(像 ChatGPT 一样预测下一个词)。而连续Token(动作输出) 用 Flow Matching Loss(预测向量场)。可以在同一个 Transformer 里同时训练这两种完全不同的损失函数。
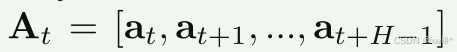
对于动作块 At中的每个动作 at′,有一个对应的动作 Token 输入到动作专家中。在训练期间,使用条件流匹配损失 Lτ(θ)来监督这些动作 Token。
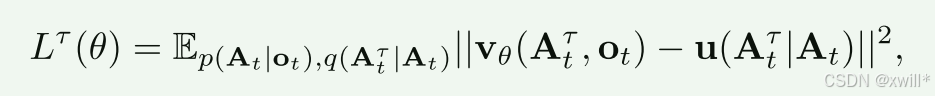
实践中,网络的训练方式是:采样随机噪声 ϵ∼N(0,I) ,计算"噪声动作" Atτ=τAt+(1−τ)ϵ ,然后训练网络输出 vθ(Atτ,ot)以匹配去噪向量场 u(Atτ∣At)=ϵ−At。动作专家使用全双向注意力掩码,以便所有动作 Token 互相关注 。在训练期间,从一个强调较低(较多噪声)时间步的 Beta 分布中采样流匹配时间步 τ。
在推理(Inference)**时,通过从 τ=0 到 τ=1 对学习到的向量场进行积分来生成动作,起始点为随机噪声 At0∼N(0,I)。使用前向欧拉积分规则
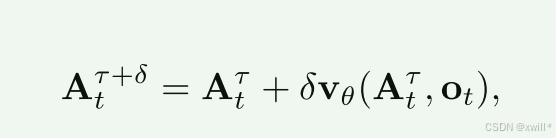
其中 δ是积分步长。在实验中使用 10个积分步(对应 δ=0.1)。值得注意的是,推理可以通过缓存前缀 ot的注意力键(Key)和值(Value)并仅重新计算每个积分步对应的动作 Token 后缀来高效实现。
**Optimal Transport (最优传输路径):**文中提到 u(Atτ∣At)=ϵ−At。
直觉解释: 这就是强迫模型学习一条直线。从噪声 ϵ到目标动作 At的最短路径。因为路径直,所以推理时走的步数少。
**Action Chunking (动作分块):**H=50。模型一次预测未来 50 个时间步(比如未来1秒)的动作。这保证了动作的连贯性,不会出现"帕金森"式的抖动。
推理加速 (Inference Efficiency):
10步积分 (10 integration steps): 相比于 Diffusion 动辄 50-100 步,Flow Matching 只需 10 步就能算出高质量动作。
KV Cache (键值缓存): 原理:** 机器人的眼睛看到的图像(ot)在生成那 10 步动作的过程中是不变 的。做法: 图像和文 本的特征只算一次,存起来 。在这 10 步的去噪过程 中,只重复计算动作部分的特征。这大大降低了计算量。
"integration steps" 指的是 Flow Matching(或 ODE-based 生成模型)在推理时对动作生成轨迹进行数值积分时所用的步骤数。 也就是说一次动作生成要沿着 learned vector field 积分 10 次(Euler/Heun/ODE solver steps)才能得到最终动作 chunk。 integration step = ODE 求解器的步数
π0 的 Transformer 输出的是动作的 vector field 然后使用一个固定步数的数值积分器(一般是 Euler 或 Heun)来合成动作序列。模型每生成一次动作 chunk,需要做 10 次 ODE 积分步骤。
2:DATA COLLECTION AND TRAINING RECIPE
作者总结了 Pre-training(预训练) 和 Post-training(后训练/微调) 的不同方式。这也是 π0 能够既鲁棒又灵巧的关键。
预训练(Pre-training):
-
数据来源: 9.1% 的开源数据(低频、简单)+ 90.9% 的自有数据(高频、复杂)。
-
特点: 数据可以比较"脏"(Lower quality)。比如机器人可能尝试了三次才抓起杯子,或者中途手滑了。
-
目的: Recovery(恢复能力)。这非常反直觉。正是因为预训练数据里包含了很多"失败"和"纠正"的过程,模型才学会了:"如果我手滑了,该怎么救回来"。
后训练(Post-training):
-
数据来源: 针对特定任务(如叠衣服)精心录制的 5~100 小时数据。
-
特点: 极高的高质量,动作行云流水,没有多余动作。
-
目的: Fluency(流畅性)。让机器人的动作像专家一样丝滑。
2.1有了这些数据,又如何适配到不同形态的机器人上呢?

π0 采用了一种简单粗暴但有效的工程方法:Max Padding(最大化填充) 。找出所有机器人里最复杂的那个(这里是 Mobile Fibocom,加上躯干共 18 维)。统一制式: 把模型的输出强制设定为 18 维。
填空:
-
对于 Mobile Fibocom:18 个格子填满数据。
-
对于 单臂 UR5e (只有7个关节):前 7 个格子填真实数据,后面 11 个格子全部填 0(Zero-pad)。
-
训练时: 告诉模型,对于单臂机器人,后面那 11 个 0 你不用管,只管把前 7 个预测准就行。
这样,同一个大脑(π0)就可以同时控制单臂、双臂和移动机器人了。而且π0不再水任务,例如拿红色杯子和蓝色杯子就算两个任务。π0定义 "Bussing"(清理餐桌) 算作一个任务。并且使用大小脑子的结构:
π0 (VLA): 负责执行。比如听到"把餐巾扔掉",它负责控制手臂去抓餐巾扔进桶里。
High-level VLM (GPT-4V 等): 负责规划。它看到桌子很乱,会思考:"第一步先收餐巾,第二步收盘子...",然后把"收餐巾"这个指令发给 π0。
三:实验

实验评估由两部分组成:
-
开箱即用(Out-of-box)评估实验: 通过直接提示(Direct prompting),将我们的基础(预训练)模型与其他替代模型设计进行比较。
-
详细的微调(Fine-tuning)实验: 在具有挑战性的下游任务上评估我们的模型,将其与针对灵巧操作提出的其他方法进行比较。
主要研究以下问题:
-
π0在预训练数据中包含的各种任务上,预训练后的表现如何?
-
π0 跟随语言指令的能力如何?
-
π0 与专门针对灵巧操作任务提出的方法相比如何?
-
π0能否适应复杂的多阶段任务?
四:总结
以前大家做机器人是"一个任务一个模型",现在是"所有任务一个模型"。π0 证明了机器人预训练模型是可行的方案。
π0 的逻辑类似于LLM:
-
机器人先看海量杂乱数据(预训练)= 学会了物理规律,学会了怎么抓东西不掉,学会了失败了怎么救回来(物理世界的"知识")。
-
然后通过高质量数据(后训练)= 学会了怎么像专家一样丝滑地叠衣服(物理世界的"对齐")。
但是也存在局限性:
配方是个黑盒: 作者说"我们把所有数据都扔进去了(combined all data)"。但到底是因为加了 OXE 数据变强了,还是因为加了自家数据变强了?如果多加点单臂数据,双臂任务会不会变差?这些**Data Composition(数据配比)**的问题,目前还没搞清楚。
Scaling Law(缩放定律)还没摸透: 在 LLM 里,我们知道数据加倍,性能大概提升多少。但在机器人领域,要把叠衣服成功率从 90% 提升到 99%,到底还需要录 100 小时还是 1000 小时?目前还是未知数。
通用性的边界: 目前 π0 主要还是控制"手臂"(Manipulation)。它能不能控制"腿"(Legged Locomotion,如波士顿动力的狗)或者"轮子"(自动驾驶)?这篇论文没做,留给未来探索。