书目信息 :《大数据平台架构》
章节 :第6章 分布式数据库HBase
主编:吕欣、黄宏斌
在大数据技术栈中,HBase是横跨在Hadoop HDFS之上的高性能数据库,也是架构师面试和系统设计中的高频考点。最近细读了国防科技大学吕欣教授等人编著的**《大数据平台架构》**第六章,书中不仅系统梳理了从RDBMS到NoSQL的演进逻辑,更深入剖析了HBase的内核架构。
本文提炼了全章精华,从技术选型(优缺点) 、数据模型 、体系架构 到读写流程,带你一次性彻底搞懂HBase。
一、 为什么选择HBase?(技术选型必读)
在6.1节中,作者首先回顾了数据库的发展史。传统关系型数据库(RDBMS)在面对海量数据时面临着扩展性差、对非结构化数据支持弱等挑战。而HBase作为Google BigTable的开源实现,属于NoSQL 阵营,它遵循BASE原则(基本可用、软状态、最终一致性),放弃了ACID的强一致性约束,换取了分布式的高可用与扩展性。
✅ HBase的六大特性
- 容量巨大:单表支持千亿行、百万列,数据规模可达PB级。
- 稀疏性(Sparsity) :这是与RDBMS最大的区别之一。 在HBase中,空列不占用存储空间。这使得它非常适合存储那些字段很多但大部分为空的"稀疏数据"。
- 多版本(Multi-version):一个单元格(Cell)可以存储数据的多个版本,通过时间戳区分 。
- 支持过期(TTL):原生支持数据生存时间设置,过期自动清理,无需写代码维护。
- 良好的可扩展性:基于HDFS(存储)和RegionServer(计算)的水平扩展。
- Hadoop原生支持:与MapReduce、Spark等组件无缝集成。
❌ HBase的局限性
当然,HBase不是万能的。书中明确指出了它的短板:
- 不支持复杂聚合:原生不支持Join、GroupBy等复杂SQL操作(需要结合Phoenix或Spark)。
- 无二级索引:原生只支持RowKey索引(查找非RowKey字段效率低)。
- 无跨行事务:只支持单行事务模型。
二、 颠覆认知的"四维"数据模型
HBase看起来像一张表,但本质上是一个**稀疏、多维、持久化的排序映射(Sorted Map)。
1. 逻辑视图:四维坐标系
要定位HBase中的一个数据,你需要"四维坐标":
Value=Map(RowKey,ColumnFamily,ColumnQualifier,Timestamp)Value = Map(RowKey, ColumnFamily, ColumnQualifier, Timestamp)Value=Map(RowKey,ColumnFamily,ColumnQualifier,Timestamp)
- 行键(Row Key) :唯一标识一行。数据按照行键的字典序排序存储 。
- 实战Tip:设计RowKey时要利用排序特性,把经常一起读的数据放在一起。
- 列族(Column Family) :权限控制和物理存储的最小单元。建表时必须定义,列名以列族为前缀(如
details:name)。 - 列限定符(Column Qualifier):即具体的列,动态添加,无需预定义。
- 时间戳(Timestamp):数据的版本号,默认是64位整型,降序排列(最新的在最前面)。
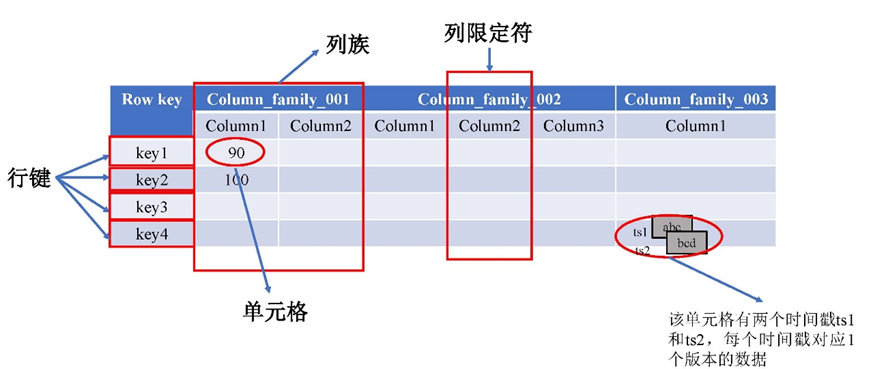
2. 案例图解:电商商品表
书中以电商平台的Products表为例(见书表6-8),直观展示了模型结构:
图6-1清晰地展示了HBase表结构。RowKey是
key1、key2...,列族是Column_family_001等。注意看右下角的单元格,它存储了ts1和ts2两个版本的数据,这就是HBase的多版本特性。*
3. 物理视图:列式存储
虽然逻辑上是一张大表,但在底层物理存储上,不同的列族是分开存储的。
details列族存一个文件。pricing列族存另一个文件。- 优势 :如果你只想统计价格,HBase只需要扫描
pricing列族的文件,完全不需要读取冗长的商品描述,IO效率极高。
三、 俄罗斯套娃般的体系架构
HBase采用标准的主从架构(Master/Slave),依赖ZooKeeper和HDFS。
1. ZooKeeper的核心作用
cite_start在HBase中,ZooKeeper不仅仅是协调者,它扮演了四个关键角色:
- Master高可用:当Master宕机时,ZK协助选举新Master。
- 管理元数据 :保存
hbase:meta表所在的RegionServer地址。 - 宕机检测:感知RegionServer的状态,通知Master处理故障。
- 分布式表锁:防止多用户同时修改表结构。
2. 核心存储单元:Region与Store
- Region(分区):表按RowKey范围切分的数据片,是负载均衡的最小单位。
- Store :一个Region由多个Store组成,一个Store对应一个列族 。
- 这也是为什么建议列族不要太多,否则Store太多会消耗内存。
四、 硬核原理:LSM树与读写流程
HBase的高性能得益于其LSM树(Log-Structured Merge-tree)的设计思想:将随机写转换为顺序写。
1. 极速写入流程(Write Path)
HBase的写入操作非常快,因为它不需要移动磁盘磁头去寻找位置,而是直接"追加"。
详细步骤 :
- Client处理:查元数据,定位RegionServer。
- 写WAL (HLog):先写预写日志。这是顺序写磁盘,速度极快,用于防止断电丢数据。
- 写MemStore :写入内存中的排序缓冲区。注意:只要写入内存,对客户端来说操作就成功了!
- Flush(刷写):当MemStore满了(默认128M),系统异步将其刷写成HFile文件。
2. 读取流程(Read Path)
读取时,HBase需要合并"内存"和"磁盘"中的数据,以保证读到最新的版本。
详细步骤:
- BlockCache:读缓存(LRU策略),热点数据直接返回。
- MemStore:写缓存,数据可能刚写进去还没刷盘。
- HFile:如果缓存没有,才去HDFS读取磁盘文件。
- Merge:合并多版本数据,返回结果。
📖 总结
读完《大数据平台架构》第六章,我最大的感触是HBase设计的**"平衡之道"**:
-
用最终一致性换取了高可用性(BASE理论)。
-
用空间换时间(多版本存储、LSM树追加写)换取了极高的写入性能。
-
用列族分离换取了高效的IO读取。
如果你正在构建一个需要存储海量日志、交易记录或用户画像的系统,HBase绝对是你的不二之选。希望这篇图文并茂的笔记能帮你快速推开HBase的大门!
📚 互动话题:你在实际业务中遇到过哪些HBase的坑?(比如RowKey设计热点问题?)欢迎在评论区交流!
作者:栗子同学