🎓 作者:计算机毕设小月哥 | 软件开发专家
🖥️ 简介:8年计算机软件程序开发经验。精通Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等技术栈。
🛠️ 专业服务 🛠️
需求定制化开发
源码提供与讲解
技术文档撰写(指导计算机毕设选题【新颖+创新】、任务书、开题报告、文献综述、外文翻译等)
项目答辩演示PPT制作
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
🍅 ↓↓主页获取源码联系↓↓🍅
基于大数据的中式早餐店订单数据分析与可视化系统-功能介绍
本系统是一个基于Hadoop与Spark大数据技术栈构建的,针对中式早餐店订单数据的深度分析与可视化平台。系统首先利用Python的数据处理库对原始的breakfast_orders.csv订单数据进行清洗、转换和特征工程,处理后的数据被上传至Hadoop分布式文件系统(HDFS)中进行持久化存储。核心分析引擎采用Apache Spark框架,通过其高效的内存计算能力对海量订单数据进行多维度、深层次的挖掘。系统实现了四大核心分析模块:整体销售业绩分析,通过计算总销售额、订单量及每日销售趋势,宏观把握经营状况;商品销售分析,深入挖掘热销品类、单品排行及商品间的关联性,为精准营销和套餐设计提供数据支持;顾客消费行为分析,洞察订单金额分布、下单高峰时段以及工作日与周末的消费差异,帮助优化运营策略;门店运营对比分析,从销售额、订单量、客单价等维度评估各门店表现,实现精细化管理。最终,所有分析结果通过Python后端框架(如Django)提供的API接口,传递给前端。前端采用Vue结合Echarts,将复杂的数据以直观、动态的图表形式进行可视化呈现,为早餐店管理者提供一个清晰、易懂的数据决策支持界面。
基于大数据的中式早餐店订单数据分析与可视化系统-选题背景意义
选题背景 随着城市生活节奏的不断加快,中式早餐作为满足人们日常基本需求的重要一环,其市场竞争也日趋激烈。大大小小的早餐店遍布街头巷尾,但多数传统店铺的经营模式仍然较为粗放,依赖于店主的经验和直觉进行决策。他们每天产生大量的订单数据,这些数据里其实隐藏着关于顾客消费习惯、商品受欢迎程度、经营高峰时段等极具价值的信息。然而,很多店主缺乏有效的工具和方法去利用这些数据,导致在菜品调整、库存管理和营销活动策划上常常感到力不从心,难以在激烈的竞争中脱颖而出。因此,如何利用现代信息技术,帮助这些传统餐饮企业,特别是中式早餐店,将沉睡的数据转化为有价值的商业洞察,提升其运营效率和盈利能力,成为了一个值得探索的现实问题。 选题意义 本课题的实际意义在于,它为中小型餐饮企业提供了一套低成本、高效率的数据分析解决方案。对于早餐店店主而言,通过本系统,他们可以清晰地看到哪些是真正的"明星产品",哪些是"滞销品",从而优化菜单结构,减少食材浪费。系统分析出的高峰时段信息,能够指导店主合理安排员工班次,提高服务效率,避免顾客流失。而商品关联性分析的结果,则可以直接用于设计搭配套餐或进行交叉推荐,有效提升客单价。虽然这只是一个毕业设计项目,但它完整地展示了如何将大数据技术应用于一个具体的、接地气的商业场景,证明了数据分析在提升传统行业运营水平方面的巨大潜力。对于开发者本人来说,这个项目涵盖了从数据采集、清洗、分布式计算到数据可视化的完整流程,是一次对大数据技术栈的综合性实践,能够极大地锻炼解决实际问题的能力,为未来从事相关工作打下坚实的基础。
基于大数据的中式早餐店订单数据分析与可视化系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制) 开发语言:Python+Java(两个版本都支持) 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持) 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy 数据库:MySQL
基于大数据的中式早餐店订单数据分析与可视化系统-视频展示
基于大数据的中式早餐店订单数据分析与可视化系统-图片展示
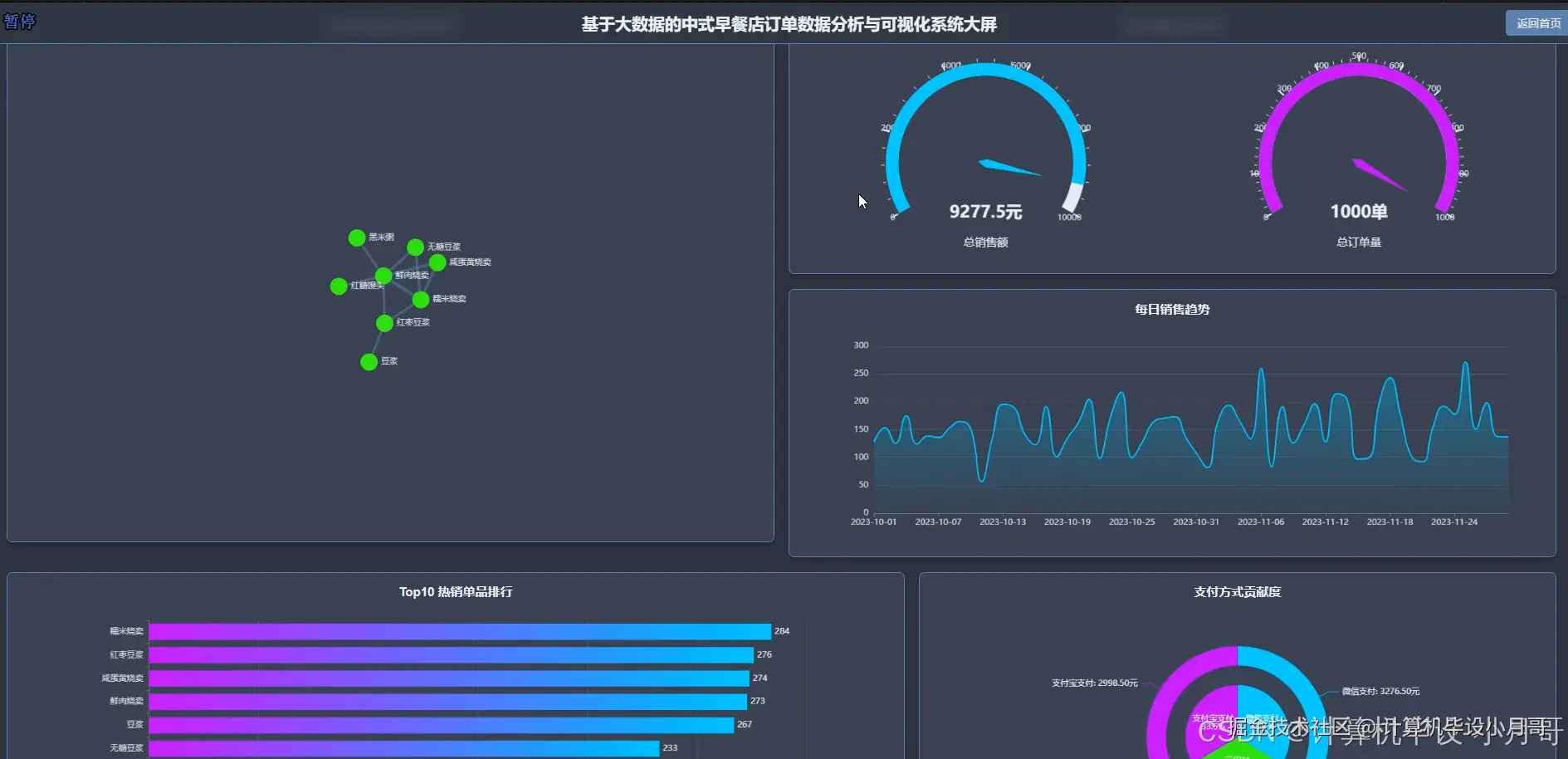
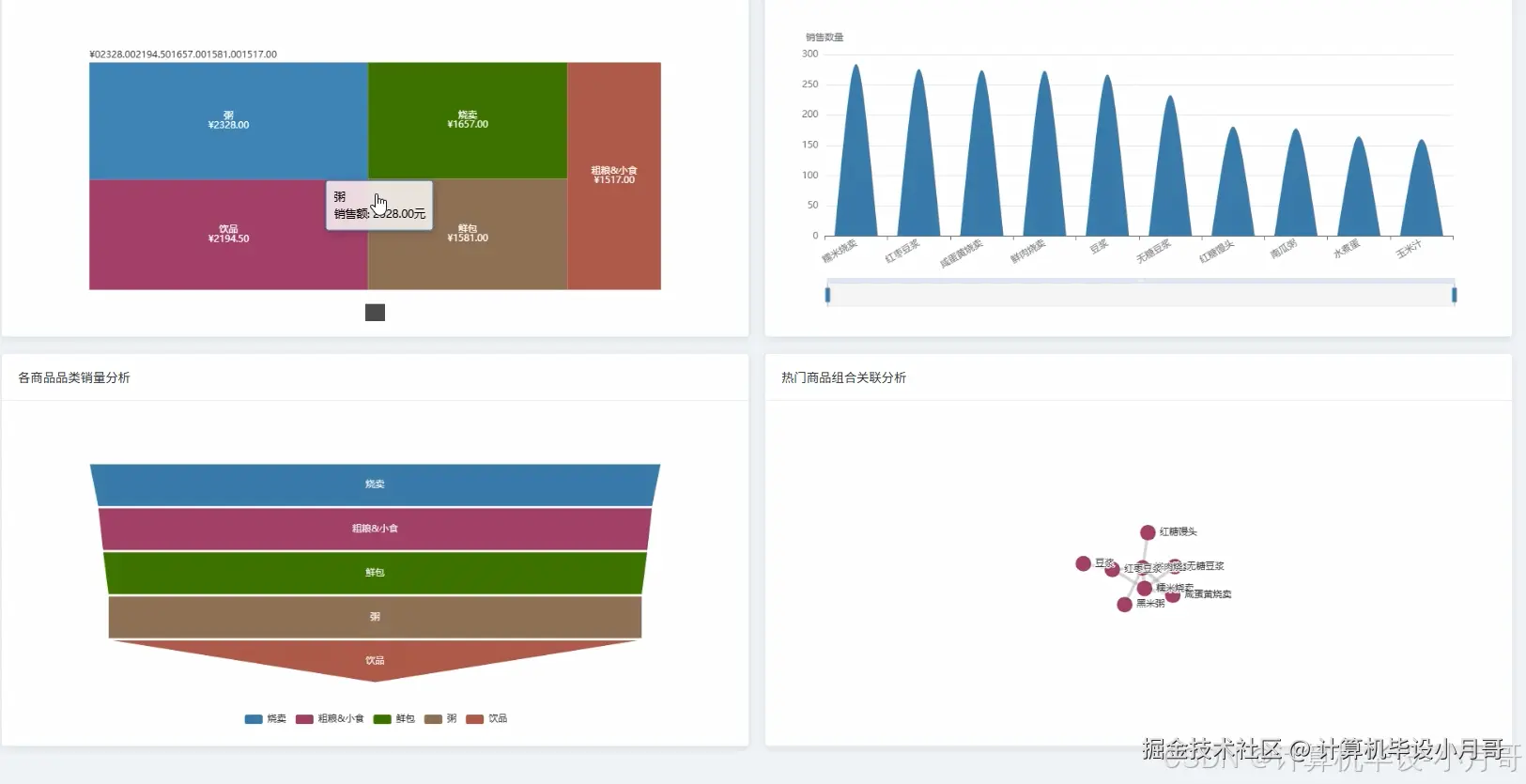
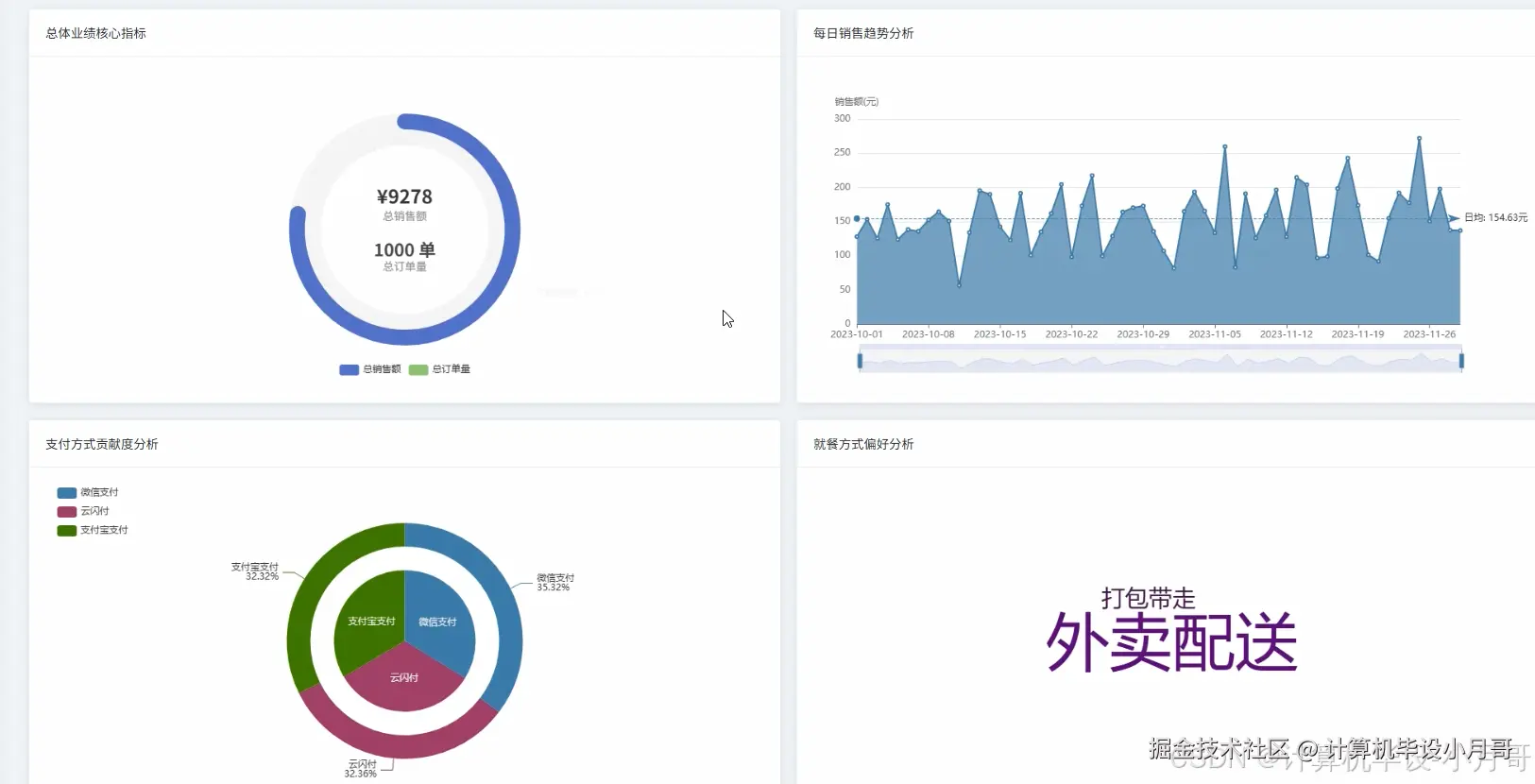
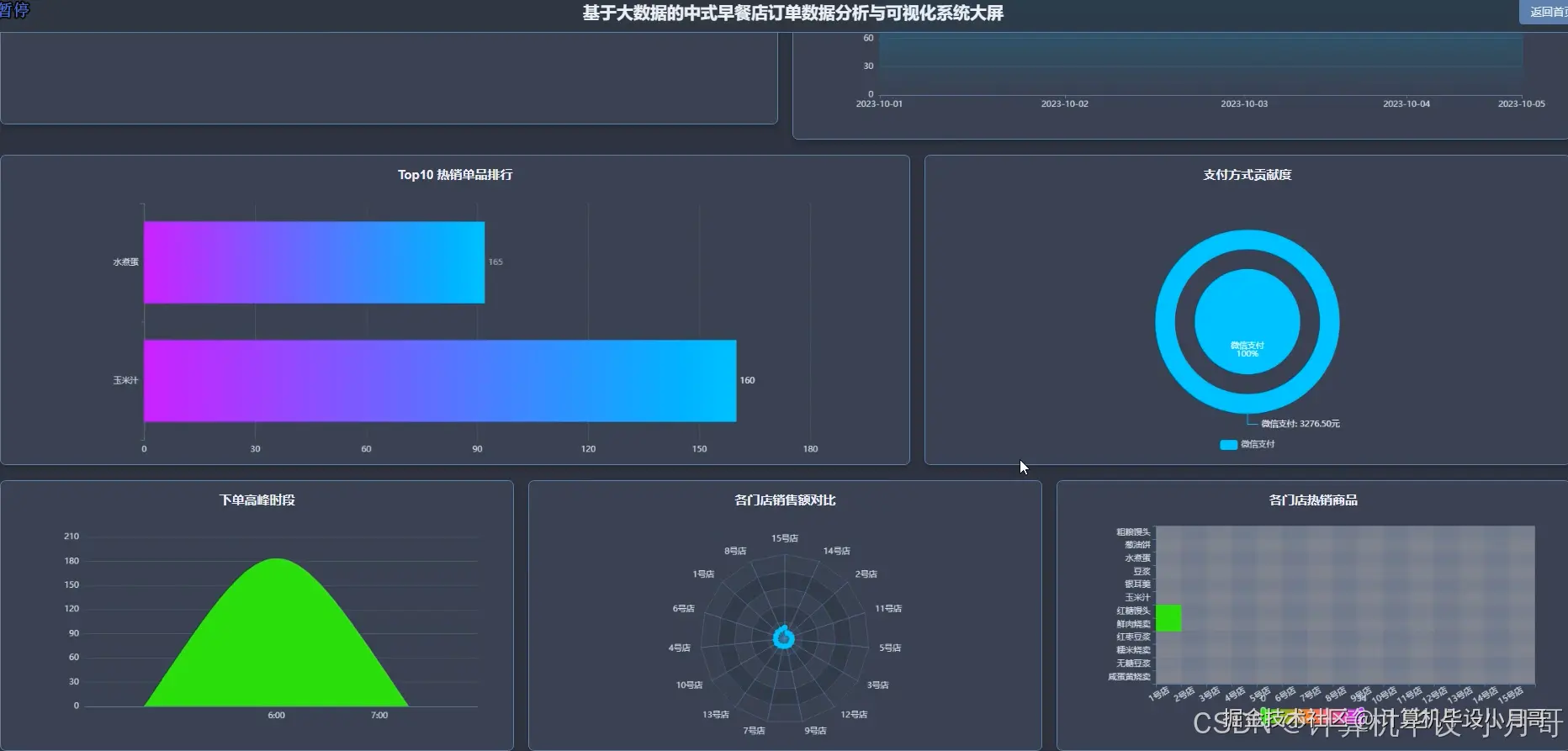
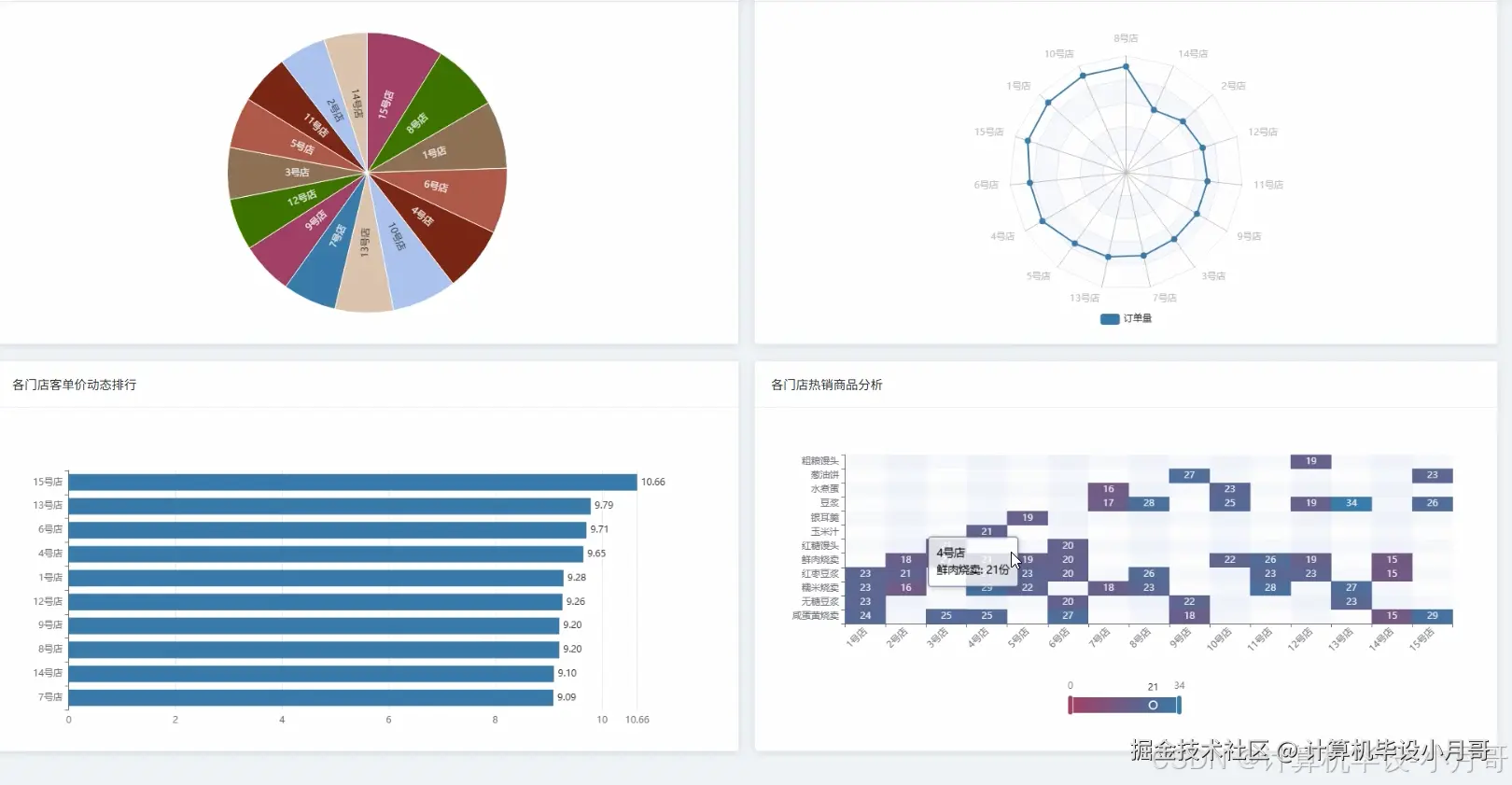
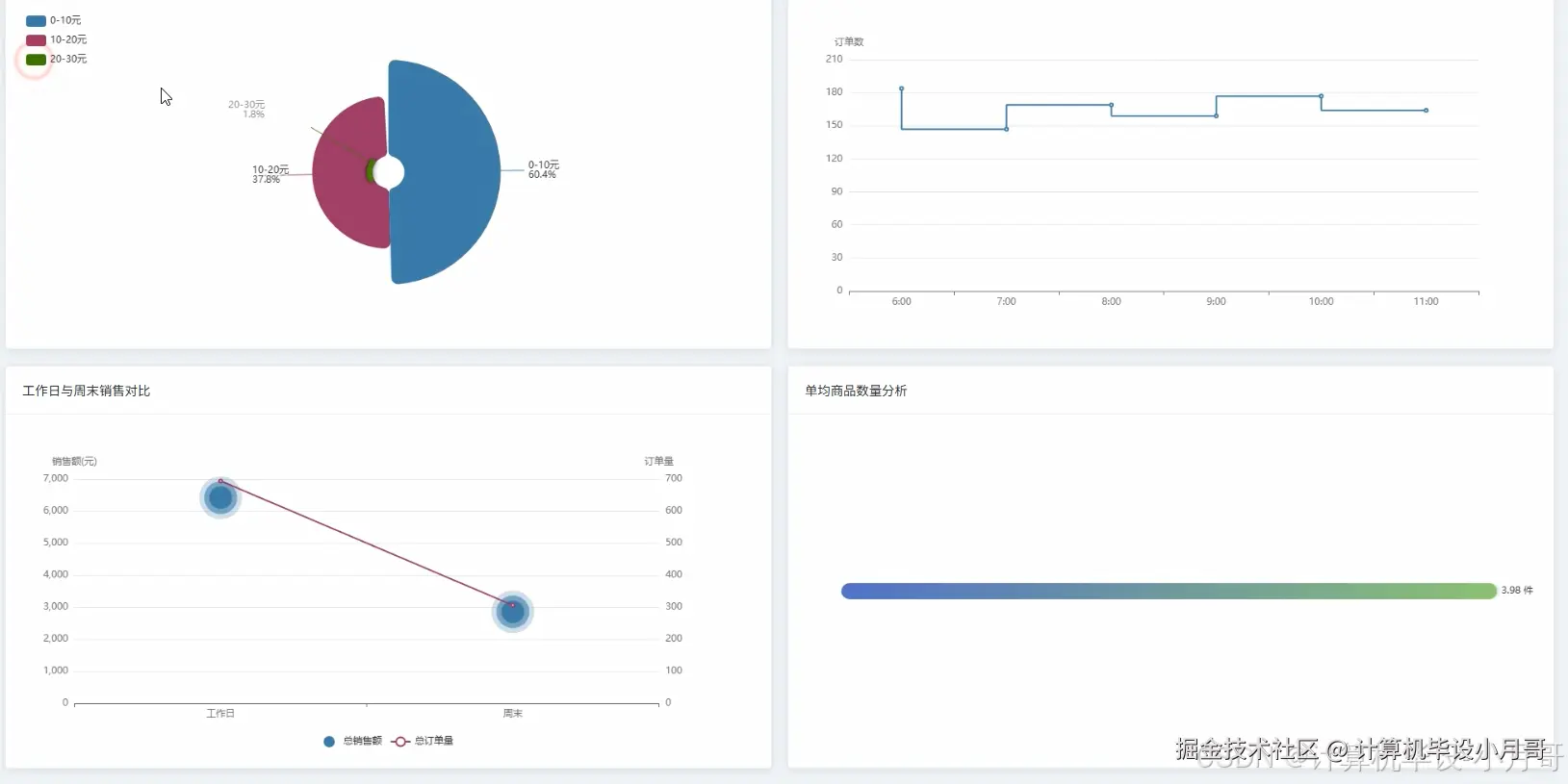
基于大数据的中式早餐店订单数据分析与可视化系统-代码展示
python
from pyspark.sql import SparkSession, functions as F
from pyspark.sql.types import ArrayType, StringType
# 初始化SparkSession,这是所有Spark功能的入口点
spark = SparkSession.builder.appName("BreakfastDataAnalysis").getOrCreate()
# 假设df是一个已经加载好的Spark DataFrame,包含breakfast_orders.csv的数据
# df = spark.read.csv("hdfs://path/to/breakfast_orders.csv", header=True, inferSchema=True)
# 核心功能1: 计算每日销售总额与订单量趋势
def analyze_daily_sales_trend(df):
# 将字符串类型的下单时间转换为时间戳格式,并提取日期部分
df_with_date = df.withColumn("order_date", F.to_date(F.col("下单时间"), "yyyy-MM-dd HH:mm:ss"))
# 按订单ID和日期分组,计算每个订单的总金额,避免一个订单多个商品行重复计算
daily_order_revenue = df_with_date.groupBy("订单编号", "order_date").agg(F.sum("小计金额").alias("order_total_revenue"))
# 按日期分组,汇总当天的总销售额和总订单数
daily_summary = daily_order_revenue.groupBy("order_date").agg(
F.sum("order_total_revenue").alias("daily_total_revenue"),
F.count("订单编号").alias("daily_order_count")
)
# 按日期升序排序,以便观察趋势
daily_summary = daily_summary.orderBy("order_date")
return daily_summary
# 核心功能2: 分析顾客下单高峰时段(按小时统计)
def analyze_peak_hours(df):
# 将字符串类型的下单时间转换为时间戳格式
df_with_timestamp = df.withColumn("order_timestamp", F.to_timestamp(F.col("下单时间"), "yyyy-MM-dd HH:mm:ss"))
# 从时间戳中提取小时部分
df_with_hour = df_with_timestamp.withColumn("order_hour", F.hour("order_timestamp"))
# 按小时分组,统计每个小时的订单数量(使用订单编号去重)
hourly_orders = df_with_hour.select("订单编号", "order_hour").distinct()
peak_hour_analysis = hourly_orders.groupBy("order_hour").agg(F.count("订单编号").alias("order_count"))
# 按小时升序排序
peak_hour_analysis = peak_hour_analysis.orderBy("order_hour")
return peak_hour_analysis
# 核心功能3: 使用Apriori思想进行商品关联性分析(简化版)
def analyze_product_association(df):
# 按订单ID分组,将每个订单中的商品收集到一个列表中
# 这里使用RDD操作,因为它在处理这种非结构化转换时更灵活
order_items_rdd = df.select("订单编号", "商品名称").rdd.map(lambda row: (row.订单编号, row.商品名称))
# 对同一个订单的商品进行去重并分组
order_items_grouped = order_items_grouped = order_items_rdd.distinct().groupByKey().mapValues(set)
# 生成所有可能的商品对(项集)
def generate_pairs(items):
items_list = list(items)
pairs = []
for i in range(len(items_list)):
for j in range(i + 1, len(items_list)):
# 确保对的顺序一致,便于后续计数
pair = tuple(sorted((items_list[i], items_list[j])))
pairs.append(pair)
return pairs
# 将每个订单的商品对展开,并计数
pairs_rdd = order_items_grouped.flatMap(lambda x: generate_pairs(x[1]))
pair_counts = pairs_rdd.map(lambda pair: (pair, 1)).reduceByKey(lambda a, b: a + b)
# 计算每个单品的总出现次数(支持度计算的分母)
single_item_counts = order_items_grouped.flatMap(lambda x: x[1]).map(lambda item: (item, 1)).reduceByKey(lambda a, b: a + b)
total_orders = df.select("订单编号").distinct().count()
# 计算置信度(这里简化处理,主要看支持度)
# 将RDD转换回DataFrame以便展示
association_rules = pair_counts.map(lambda x: (x[0][0], x[0][1], x[1])).toDF(["item_A", "item_B", "pair_count"])
return association_rules.orderBy(F.col("pair_count").desc())基于大数据的中式早餐店订单数据分析与可视化系统-结语
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
🍅 ↓↓主页获取源码联系↓↓🍅