摘要:
DeepSeek 刚刚发布的 Math-V2 模型凭借 7B 参数量在 IMO 级数学测试中击败了 GPT-4。这标志着大模型训练正在从"结果导向(ORM)"向"过程导向(PRM)"跃迁。本文深度解析 DeepSeek 的"元验证"架构,并探讨在这一新范式下,面对指数级增长的推理过程数据,企业应如何构建适配的高吞吐存储基础设施。
引言:为什么 AI 总是"一本正经地胡说八道"?
过去两年,我们在落地大模型(LLM)时面临的最大梦魇就是"幻觉(Hallucination) "。
这背后的根源在于传统的 RLHF(人类反馈强化学习)大多采用 ORM(Outcome Reward Model,结果奖励模型) 。简单说,只要 AI 给出的最终答案是对的,它就会得到奖励。这导致模型学会了"走捷径"、"背答案",甚至在中间推理步骤完全错误的情况下蒙对结果。
DeepSeek-Math-V2 的发布,可能终结这个时代。
它引入了 GRPO(Group Relative Policy Optimization) 和 PRM(Process Reward Model,过程奖励模型) ,让 AI 不仅要"做对题",还要"想得对"。但对于架构师而言,这种从"黑盒"到"白盒"的进化,意味着数据处理量级和 I/O 压力的指数级爆发 。
本文将拆解这一架构变革,并给出基础设施层面的应对方案。
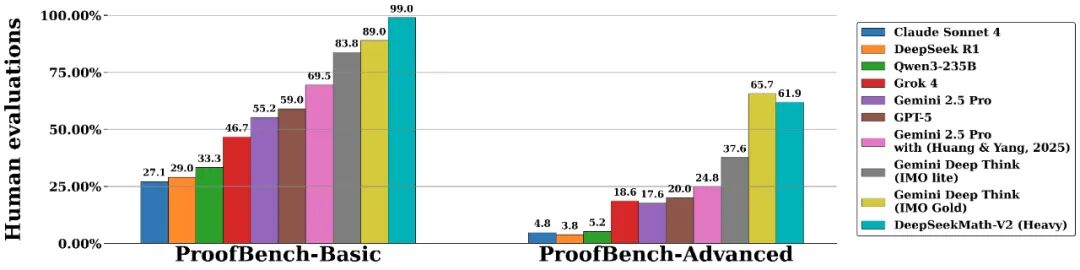
一、 架构深潜:学生、老师与督导的"三角博弈"
DeepSeek-Math-V2 的核心突破在于它构建了一套严密的"自我验证闭环 "。传统的模型是单向生成的,而 Math-V2 在生成答案之前,内部上演了一场精密的博弈。
我们可以将其架构抽象为三个角色:
1.生成器(Student): 负责生成解题步骤。不仅生成最终答案,还要生成详细的思维链(CoT)。
2.验证器(Teacher/Verifier) : 这是一个专门训练的评分模型。它不再只给最终结果打分,而是对 Student 的每一个推理步骤 进行打分(Process Reward)。
技术点: 验证器会将步骤分为"完美、小瑕疵、根本错误"三档。
3.元验证器(Guide/Meta-Verifier) : 这是 DeepSeek 的杀手锏 。 验证器也可能犯错(产生幻觉)。元验证器负责"监考"老师,通过分析验证器的评分逻辑,剔除那些"盲目自信"的评分。
二、 核心选型对比:ORM vs PRM
对于正在进行技术选型的 AI 团队,是否要跟进 DeepSeek 这种"过程奖励"路线?
我们整理了以下对比表格,这是你做决策的关键依据:
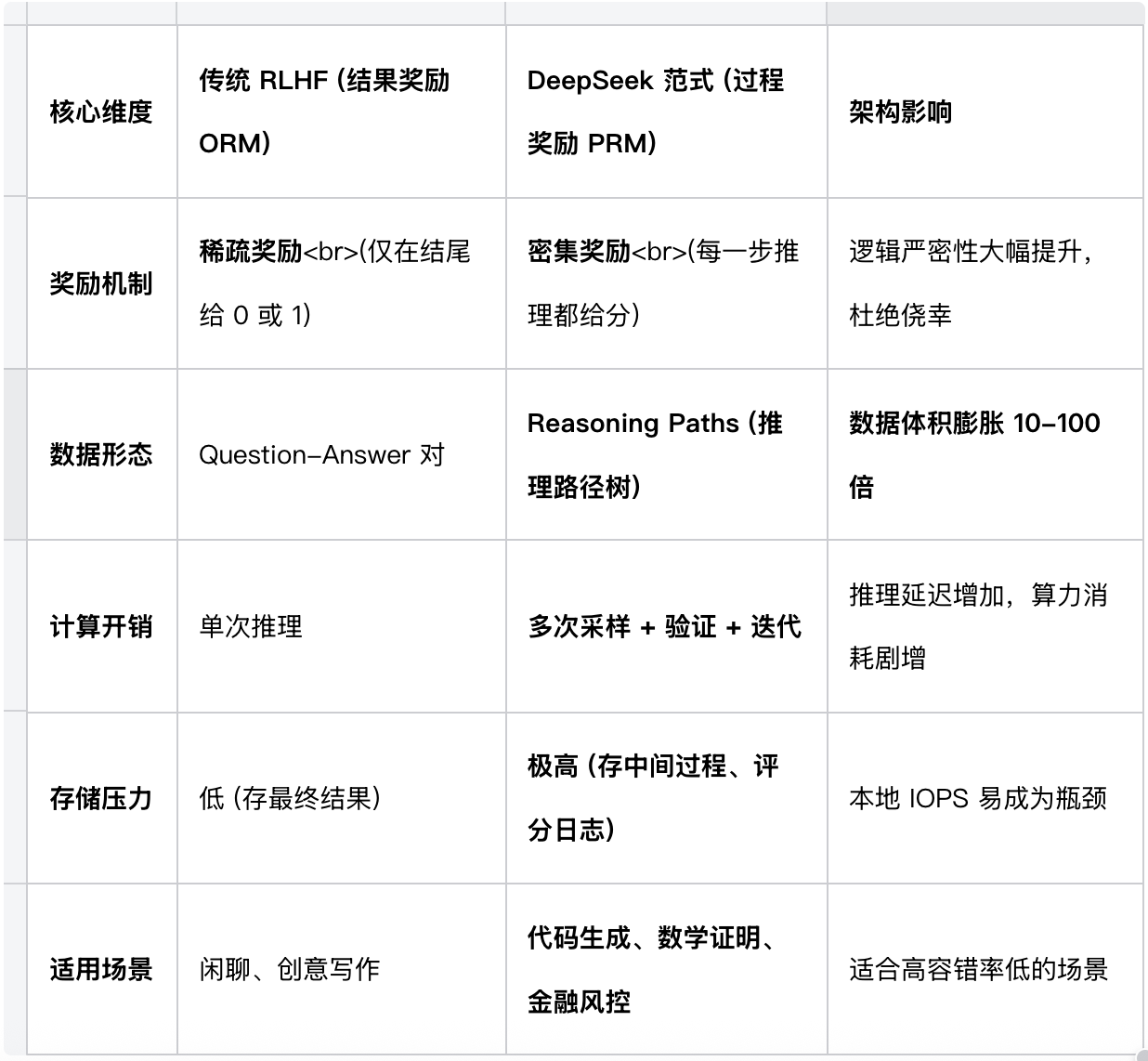
决策建议 : 如果你的业务场景涉及复杂逻辑推理 (如自动写代码、自动审计),拥抱 PRM 架构是必然趋势,但前提是你得搞定随之而来的数据风暴。
三、 基础设施的新挑战:当推理变成"数据风暴"
DeepSeek 的论文中提到一个关键细节:"以战养战 "。模型需要生成海量的解题路径,通过集体投票和验证来清洗数据。
这意味着,推理不再是一个简单的 Request -> Response 过程,而变成了一个高并发的数据生产过程 。
1. 存储 I/O 的"击穿"风险
在 PRM 架构下,针对一个问题,模型可能需要生成 64 条甚至更多的推理路径,每条路径包含数十个步骤。
●传统 NAS/本地盘: 面对这种海量小文件(JSON/Log)的瞬间并发写入,inode 锁竞争会导致严重的 I/O Wait,进而拖慢昂贵的 GPU 推理速度。
●数据孤岛: 分布式训练中,每台机器产生的"优质思维链"数据如果存在本地,很难汇聚起来进行下一轮的微调(Fine-tuning)。
2. 数据的生命周期管理
这些中间推理数据(Reasoning Logs)非常有价值,但价值密度随时间衰减极快。如果全部存入高性能 SSD,成本将是天文数字。
四、 解决方案:构建基于对象存储的"推理数据湖"
针对 DeepSeek 这种 High-Throughput Reasoning(高吞吐推理)场景,七牛云(Qiniu Cloud) 提供了适配的架构解法。我们建议将七牛云 Kodo 作为 AI 推理的"数据物流中心 ",而非简单的硬盘。
架构优化方案
1.绕过文件系统,内存直落对象存储 :
利用 Python SDK,将生成的思维链(CoT)数据直接从内存异步推送到七牛云 Kodo,彻底消除本地磁盘 I/O 瓶颈。
2.存算分离与数据汇聚 :
无论你有多少台 GPU 服务器在跑推理,所有产生的"过程数据"统一汇聚到云端 Bucket。这为后续训练"验证器(Verifier)"提供了现成的、清洗好的数据集。
代码实战:异步上传推理日志
以下是一个基于 Python concurrent.futures 和七牛云 SDK 的设计模式,用于在不阻塞 GPU 推理的情况下,保存海量中间验证数据:
code Python
python
import json
import time
from concurrent.futures import ThreadPoolExecutor
from qiniu import Auth, put_data
# 初始化七牛云鉴权 (配置你的 AccessKey/SecretKey)
q = Auth('YOUR_AK', 'YOUR_SK')
bucket = 'deepseek-reasoning-logs'
# 线程池,专门处理 IO,不抢占 GPU 线程
executor = ThreadPoolExecutor(max_workers=8)
def save_reasoning_log(question_id, reasoning_steps, verification_scores):
"""
将推理步骤和评分打包,异步上传到对象存储
"""
# 1. 结构化数据
data = {
"q_id": question_id,
"timestamp": time.time(),
"steps": reasoning_steps, # 这里可能包含几十个步骤
"scores": verification_scores, # 对应的过程评分
"model_version": "math-v2"
}
json_bytes = json.dumps(data).encode('utf-8')
# 2. 生成对象键值 (建议按日期/ID分层)
key = f"logs/{time.strftime('%Y%m%d')}/{question_id}.json"
# 3. 异步提交上传任务
executor.submit(_upload_task, key, json_bytes)
def _upload_task(key, data):
token = q.upload_token(bucket, key, 3600)
ret, info = put_data(token, key, data)
if info.status_code != 200:
print(f"[Error] Log upload failed: {info.error}")
# 在推理主循环中调用:
# save_reasoning_log(qid, steps, scores)
# GPU 继续跑下一个 Batch,完全无感成本与效率的平衡
利用七牛云的生命周期管理 规则,我们可以设置策略:
●热数据(0-7天): 存储在标准存储,供 Data Scientist 随时分析 bad case。
●温数据(7-30天): 转入低频存储,用于下个版本的批量微调。
●冷数据(30天+): 自动转入归档存储或删除,将存储成本降低 60% 以上。
结语:迈向 System 2 的基础设施建设
DeepSeek-Math-V2 的成功证明了 AI 正在从 System 1(快思考、凭直觉)向 System 2(慢思考、重逻辑)进化。
在这个过程中,算法变得越来越复杂,产生的数据也越来越庞大。作为架构师,我们不能只盯着模型参数,更要关注底座的承载能力。算力决定了推理的上限,而存储(七牛云)决定了数据闭环的效率 。
拥抱过程奖励,拥抱云原生存储,这是通往 AGI 的必经之路。