之前分享过很多关于机载智能软件的开发方法,今天的分享主题是飞控算法。目前人工智能算法应用广泛,应用场景更多的用在了感知、决策等方向。想必很多搞飞控的人都会思考,传统的控制算法亘古不变,如何求得创新,如何结合时兴的人工智能搞一搞。今天就来分享下这个主题。
人工智能和飞控结合,有几个方向可选,比如
思路 1:AI 增强传统控制,用 AI 解决传统控制的 "建模难、抗干扰弱" 问题,保留传统控制的稳定性(如 PID、MPC);
思路 2:强化学习(RL)端到端控制,无需系统模型,通过强化学习训练智能体(Agent)直接从 "传感器输入→控制输出" 映射,适合复杂环境(如动态避障、多机协作);
思路 3:感知 - 控制一体化,跳过单独的感知模块(如目标检测、障碍物分割),直接用视觉 / 激光雷达原始数据作为 AI 输入,输出控制指令,减少模块间延迟。
思路1做的比较多,用神经网络补偿PID,这个大家看的也比较多了。思路2这两年开始兴起,苏黎世大学做的很成功还发了顶刊,大家可以下载下来看看。
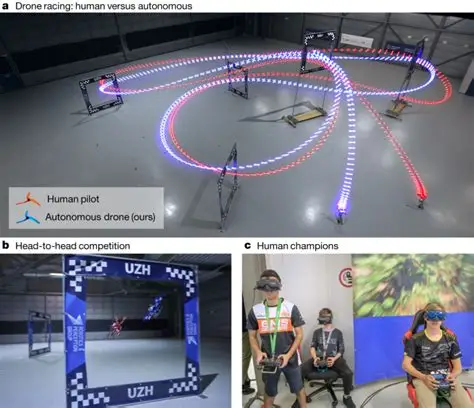
下面我们对这种基于强化学习的无人机端到端飞行控制算法开发方法给大家分享一下。
一、核心技术栈(纯C++)
| 模块 | 工具/框架 | 作用 |
|---|---|---|
| 机器人框架 | ROS2 Humble(C++ API) | 传感器/执行器通信、节点管理、实时调度 |
| 强化学习框架 | LibTorch 2.1.0(CUDA 11.4) | TD3算法实现、网络训练、模型导出 |
| 模型加速 | TensorRT 8.5(C++ API) | 模型量化、推理引擎构建、GPU/DLA加速 |
| 仿真环境 | Gazebo 11 + ros2_control(C++接口) | 无人机动力学仿真、传感器模拟、避障场景 |
| 数据处理 | Eigen 3.4、OpenCV 4.5、PCL 1.10 | 状态向量构建、点云/图像预处理 |
| 编译构建 | CMake 3.20+、ament_cmake | 跨平台编译、依赖管理、优化编译选项 |
二、环境准备(Orin NX专属)
1. 系统与依赖安装
(1)基础依赖
bash
# ROS2 Humble核心依赖(已安装可跳过)
sudo apt install ros-humble-ros2-control ros-humble-ros2-controllers ros-humble-gazebo-ros2-control
# 数据处理与编译依赖
sudo apt install libeigen3-dev libopencv-dev libpcl-dev cmake gcc-9 g++-9
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 50
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-9 50(2)LibTorch(C++ PyTorch)安装
Orin NX为ARM64架构,需下载对应CUDA版本的LibTorch:
bash
# 下载LibTorch 2.1.0(CUDA 11.4,ARM64)
wget https://download.pytorch.org/libtorch/cu114/libtorch-cxx11-abi-shared-with-deps-2.1.0%2Bcu114.zip
unzip libtorch-cxx11-abi-shared-with-deps-2.1.0+cu114.zip -d /opt/
echo "export Torch_DIR=/opt/libtorch/share/cmake/Torch" >> ~/.bashrc
source ~/.bashrc(3)TensorRT依赖(JetPack预装,验证即可)
bash
# 验证TensorRT安装
dpkg -l | grep TensorRT
# 确保库路径正确
echo "export LD_LIBRARY_PATH=/usr/lib/aarch64-linux-gnu/:$LD_LIBRARY_PATH" >> ~/.bashrc
source ~/.bashrc2. ROS2功能包创建
bash
cd ~/ros2_ws/src
ros2 pkg create drone_rl_cpp --build-type ament_cmake --dependencies \
rclcpp sensor_msgs geometry_msgs std_msgs gazebo_ros2_control ros2_control \
Eigen3 opencv4 pcl_common pcl_io
cd drone_rl_cpp
# 创建目录结构
mkdir -p include/drone_rl_cpp src config launch models src/networks src/env src/utils三、核心模块设计(纯C++实现)
1. 模块划分
drone_rl_cpp/
├── include/drone_rl_cpp/
│ ├── env/DroneEnv.hpp # ROS2环境封装(传感器+动作+状态+奖励)
│ ├── networks/TD3Networks.hpp # TD3网络(Actor/Critic)
│ ├── utils/ReplayBuffer.hpp # 经验回放缓冲区
│ ├── utils/TrtInfer.hpp # TensorRT推理封装
│ └── TD3Agent.hpp # TD3智能体(训练+推理)
├── src/
│ ├── env/DroneEnv.cpp # 环境实现
│ ├── networks/TD3Networks.cpp
│ ├── utils/ReplayBuffer.cpp
│ ├── utils/TrtInfer.cpp
│ ├── TD3Agent.cpp
│ ├── train_node.cpp # 训练节点(ROS2)
│ └── infer_node.cpp # 推理控制节点(ROS2)
├── config/ # 控制配置、模型参数
├── launch/ # Gazebo仿真、硬件启动launch文件
└── models/ # 训练好的模型、TensorRT引擎2. 核心模块实现
(1)ROS2环境封装(include/drone_rl_cpp/env/DroneEnv.hpp)
封装传感器订阅、动作发布、状态构建、奖励计算,替代Python Gym:
cpp
#ifndef DRONE_ENV_HPP_
#define DRONE_ENV_HPP_
#include <rclcpp/rclcpp.hpp>
#include <sensor_msgs/msg/imu.hpp>
#include <sensor_msgs/msg/laser_scan.hpp>
#include <geometry_msgs/msg/pose_stamped.hpp>
#include <geometry_msgs/msg/twist_stamped.hpp>
#include <std_msgs/msg/float64_multi_array.hpp>
#include <Eigen/Dense>
#include <vector>
#include <mutex>
#include <atomic>
namespace drone_rl_cpp
{
class DroneEnv : public rclcpp::Node
{
public:
using Ptr = std::shared_ptr<DroneEnv>;
// 状态维度(22维)、动作维度(4维)
static constexpr int STATE_DIM = 22;
static constexpr int ACTION_DIM = 4;
// 动作范围(电机转速:500-2000 RPM)
static constexpr double ACTION_LOW = 500.0;
static constexpr double ACTION_HIGH = 2000.0;
DroneEnv(const std::string& node_name = "drone_env_node");
~DroneEnv() = default;
// 环境重置(对应Gym reset)
Eigen::VectorXd reset();
// 执行动作(对应Gym step)
std::tuple<Eigen::VectorXd, double, bool, std::string> step(const Eigen::VectorXd& action);
// 检查环境是否就绪(传感器数据齐全)
bool is_ready() const { return is_ready_.load(); }
private:
// 传感器数据回调
void imu_callback(const sensor_msgs::msg::Imu::SharedPtr msg);
void gps_pose_callback(const geometry_msgs::msg::PoseStamped::SharedPtr msg);
void gps_twist_callback(const geometry_msgs::msg::TwistStamped::SharedPtr msg);
void lidar_callback(const sensor_msgs::msg::LaserScan::SharedPtr msg);
// 构建状态向量(22维)
Eigen::VectorXd build_state();
// 计算奖励函数
double compute_reward(const Eigen::VectorXd& state);
// 检查终止条件
bool check_done(const Eigen::VectorXd& state);
// ROS2订阅者/发布者
rclcpp::Subscription<sensor_msgs::msg::Imu>::SharedPtr imu_sub_;
rclcpp::Subscription<geometry_msgs::msg::PoseStamped>::SharedPtr gps_pose_sub_;
rclcpp::Subscription<geometry_msgs::msg::TwistStamped>::SharedPtr gps_twist_sub_;
rclcpp::Subscription<sensor_msgs::msg::LaserScan>::SharedPtr lidar_sub_;
rclcpp::Publisher<std_msgs::msg::Float64MultiArray>::SharedPtr motor_pub_;
// 数据缓存(带互斥锁,保证线程安全)
std::mutex data_mutex_;
Eigen::VectorXd imu_data_; // 6维(角速度3+线加速度3)
Eigen::Vector3d gps_pose_; // 3维(x,y,z)
Eigen::Vector3d gps_twist_; // 3维(vx,vy,vz)
Eigen::Vector5d lidar_data_; // 5维(前、后、左、右、上)
std::atomic<bool> is_ready_; // 数据是否就绪
// 目标点(正方形轨迹)
std::vector<Eigen::Vector3d> target_points_;
int current_target_idx_;
std::atomic<bool> collision_; // 碰撞标志
};
} // namespace drone_rl_cpp
#endif // DRONE_ENV_HPP_(2)环境实现(src/env/DroneEnv.cpp)
cpp
#include "drone_rl_cpp/env/DroneEnv.hpp"
#include <cmath>
#include <algorithm>
namespace drone_rl_cpp
{
DroneEnv::DroneEnv(const std::string& node_name)
: Node(node_name)
, imu_data_(Eigen::VectorXd::Zero(6))
, gps_pose_(Eigen::Vector3d::Zero())
, gps_twist_(Eigen::Vector3d::Zero())
, lidar_data_(Eigen::Vector5d::Ones() * 10.0) // 初始距离设为10m
, is_ready_(false)
, current_target_idx_(0)
, collision_(false)
{
// 初始化目标点(正方形轨迹:(2,0,1)→(2,2,1)→(0,2,1)→(0,0,1))
target_points_ = {
Eigen::Vector3d(2.0, 0.0, 1.0),
Eigen::Vector3d(2.0, 2.0, 1.0),
Eigen::Vector3d(0.0, 2.0, 1.0),
Eigen::Vector3d(0.0, 0.0, 1.0)
};
// 订阅传感器数据(队列大小10,确保实时性)
imu_sub_ = this->create_subscription<sensor_msgs::msg::Imu>(
"/drone/imu", 10, std::bind(&DroneEnv::imu_callback, this, std::placeholders::_1)
);
gps_pose_sub_ = this->create_subscription<geometry_msgs::msg::PoseStamped>(
"/drone/gps/pose", 10, std::bind(&DroneEnv::gps_pose_callback, this, std::placeholders::_1)
);
gps_twist_sub_ = this->create_subscription<geometry_msgs::msg::TwistStamped>(
"/drone/gps/twist", 10, std::bind(&DroneEnv::gps_twist_callback, this, std::placeholders::_1)
);
lidar_sub_ = this->create_subscription<sensor_msgs::msg::LaserScan>(
"/drone/lidar", 10, std::bind(&DroneEnv::lidar_callback, this, std::placeholders::_1)
);
// 发布电机控制指令(QoS设置为可靠传输)
motor_pub_ = this->create_publisher<std_msgs::msg::Float64MultiArray>(
"/drone/motor_vel_cmd", 10
);
// 等待传感器数据就绪(1秒超时)
auto start = this->now();
while (rclcpp::ok() && !is_ready_ && (this->now() - start).seconds() < 1.0) {
rclcpp::spin_some(this->get_node_base_interface());
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
if (is_ready_) {
RCLCPP_INFO(this->get_logger(), "Drone environment is ready");
} else {
RCLCPP_ERROR(this->get_logger(), "Sensor data not ready, environment init failed");
}
}
Eigen::VectorXd DroneEnv::reset()
{
std::lock_guard<std::mutex> lock(data_mutex_);
// 重置状态
current_target_idx_ = 0;
collision_ = false;
imu_data_.setZero();
gps_pose_.setZero();
gps_twist_.setZero();
lidar_data_.setOnes() * 10.0;
// 发布零动作(电机停转)
auto zero_cmd = std_msgs::msg::Float64MultiArray();
zero_cmd.data = {500.0, 500.0, 500.0, 500.0};
motor_pub_->publish(zero_cmd);
// 等待数据更新
std::this_thread::sleep_for(std::chrono::milliseconds(50));
rclcpp::spin_some(this->get_node_base_interface());
return build_state();
}
std::tuple<Eigen::VectorXd, double, bool, std::string> DroneEnv::step(const Eigen::VectorXd& action)
{
if (action.size() != ACTION_DIM) {
RCLCPP_ERROR(this->get_logger(), "Action dimension mismatch: expected %d, got %ld", ACTION_DIM, action.size());
return {Eigen::VectorXd::Zero(STATE_DIM), -1000.0, true, "action_dim_error"};
}
// 动作裁剪(确保在[500,2000]范围内)
Eigen::VectorXd clipped_action = action.cwiseMax(ACTION_LOW).cwiseMin(ACTION_HIGH);
// 发布电机控制指令
auto motor_cmd = std_msgs::msg::Float64MultiArray();
motor_cmd.data.resize(ACTION_DIM);
for (int i = 0; i < ACTION_DIM; ++i) {
motor_cmd.data[i] = clipped_action(i);
}
motor_pub_->publish(motor_cmd);
// 等待传感器数据更新(5ms,匹配200Hz控制频率)
std::this_thread::sleep_for(std::chrono::milliseconds(5));
rclcpp::spin_some(this->get_node_base_interface());
// 构建状态、计算奖励、检查终止
Eigen::VectorXd state = build_state();
double reward = compute_reward(state);
bool done = check_done(state);
std::string info = collision_ ? "collision" : (done ? "task_completed" : "running");
// 切换目标点(到达当前目标,误差≤0.05m)
Eigen::Vector3d current_target = target_points_[current_target_idx_];
double dist_to_target = (gps_pose_ - current_target).norm();
if (dist_to_target <= 0.05) {
current_target_idx_ = (current_target_idx_ + 1) % target_points_.size();
RCLCPP_INFO(this->get_logger(), "Switch to target %d (pos: %.2f, %.2f, %.2f)",
current_target_idx_, current_target.x(), current_target.y(), current_target.z());
}
return {state, reward, done, info};
}
void DroneEnv::imu_callback(const sensor_msgs::msg::Imu::SharedPtr msg)
{
std::lock_guard<std::mutex> lock(data_mutex_);
imu_data_(0) = msg->angular_velocity.x;
imu_data_(1) = msg->angular_velocity.y;
imu_data_(2) = msg->angular_velocity.z;
imu_data_(3) = msg->linear_acceleration.x;
imu_data_(4) = msg->linear_acceleration.y;
imu_data_(5) = msg->linear_acceleration.z;
is_ready_ = true;
}
void DroneEnv::gps_pose_callback(const geometry_msgs::msg::PoseStamped::SharedPtr msg)
{
std::lock_guard<std::mutex> lock(data_mutex_);
gps_pose_(0) = msg->pose.position.x;
gps_pose_(1) = msg->pose.position.y;
gps_pose_(2) = msg->pose.position.z;
is_ready_ = true;
}
void DroneEnv::gps_twist_callback(const geometry_msgs::msg::TwistStamped::SharedPtr msg)
{
std::lock_guard<std::mutex> lock(data_mutex_);
gps_twist_(0) = msg->twist.linear.x;
gps_twist_(1) = msg->twist.linear.y;
gps_twist_(2) = msg->twist.linear.z;
is_ready_ = true;
}
void DroneEnv::lidar_callback(const sensor_msgs::msg::LaserScan::SharedPtr msg)
{
std::lock_guard<std::mutex> lock(data_mutex_);
const auto& ranges = msg->ranges;
size_t n = ranges.size();
// 提取5个方向的最小障碍物距离(前、后、左、右、上)
lidar_data_(0) = *std::min_element(ranges.begin() + n*350/360, ranges.begin() + n*10/360); // 前
lidar_data_(1) = *std::min_element(ranges.begin() + n*170/360, ranges.begin() + n*190/360); // 后
lidar_data_(2) = *std::min_element(ranges.begin() + n*80/360, ranges.begin() + n*100/360); // 左
lidar_data_(3) = *std::min_element(ranges.begin() + n*260/360, ranges.begin() + n*280/360); // 右
lidar_data_(4) = *std::min_element(ranges.begin(), ranges.end(), [](float a, float b) { // 上
return a < b && a > 0.1; // 过滤无效值
});
// 检测碰撞(任意方向距离<0.1m)
collision_ = std::any_of(lidar_data_.data(), lidar_data_.data() + 5, [](double d) {
return d < 0.1;
});
is_ready_ = true;
}
Eigen::VectorXd DroneEnv::build_state()
{
std::lock_guard<std::mutex> lock(data_mutex_);
Eigen::VectorXd state(STATE_DIM);
Eigen::Vector3d current_target = target_points_[current_target_idx_];
// 1. GPS位置 (0-2)
state.segment(0, 3) = gps_pose_;
// 2. GPS速度 (3-5)
state.segment(3, 3) = gps_twist_;
// 3. IMU数据 (6-11)
state.segment(6, 6) = imu_data_;
// 4. 目标点相对位置 (12-14)
state.segment(12, 3) = current_target - gps_pose_;
// 5. 激光雷达距离 (15-19)
state.segment(15, 5) = lidar_data_;
// 6. 轨迹跟踪误差 (20-21)
state(20) = (current_target.head(2) - gps_pose_.head(2)).norm(); // 水平误差
state(21) = std::abs(current_target.z() - gps_pose_.z()); // 垂直误差
return state;
}
double DroneEnv::compute_reward(const Eigen::VectorXd& state)
{
double err_xy = state(20);
double err_z = state(21);
const Eigen::VectorXd& lidar_dist = state.segment(15, 5);
const Eigen::VectorXd& angular_vel = state.segment(6, 3);
// 1. 轨迹跟踪奖励(稠密):误差越小奖励越高
double track_reward = -0.5 * (err_xy * err_xy + err_z * err_z);
// 2. 避障奖励(稠密):安全距离≥0.5m奖励,否则惩罚
double obstacle_reward = 0.0;
for (int i = 0; i < 5; ++i) {
obstacle_reward += (lidar_dist(i) >= 0.5) ? 1.0 : -10.0;
}
// 3. 姿态平稳奖励(稠密):角速度越小奖励越高
double smooth_reward = -0.1 * angular_vel.norm();
// 4. 终端奖励(稀疏):到达目标点
double terminal_reward = (std::sqrt(err_xy*err_xy + err_z*err_z) <= 0.05) ? 100.0 : 0.0;
// 5. 碰撞惩罚(稀疏)
double collision_penalty = collision_ ? -200.0 : 0.0;
// 总奖励
return track_reward + obstacle_reward + smooth_reward + terminal_reward + collision_penalty;
}
bool DroneEnv::check_done(const Eigen::VectorXd& state)
{
double err_xy = state(20);
double err_z = state(21);
const Eigen::Vector3d& gps_pos = state.segment(0, 3);
// 1. 碰撞终止
if (collision_) return true;
// 2. 飞出边界(x/y/z超出±10m)
if (gps_pos.cwiseAbs().maxCoeff() > 10.0) return true;
// 3. 任务完成(遍历所有目标点)
if (current_target_idx_ == 0 && std::sqrt(err_xy*err_xy + err_z*err_z) <= 0.05) {
RCLCPP_INFO(this->get_logger(), "Task completed! All targets reached");
return true;
}
return false;
}
} // namespace drone_rl_cpp(3)TD3网络定义(include/drone_rl_cpp/networks/TD3Networks.hpp)
用LibTorch实现Actor(策略网络)和Critic(价值网络):
cpp
#ifndef TD3_NETWORKS_HPP_
#define TD3_NETWORKS_HPP_
#include <torch/torch.h>
#include <Eigen/Dense>
namespace drone_rl_cpp
{
// Actor网络:输入状态(22维)→输出动作(4维,连续值)
class ActorNetwork : public torch::nn::Module
{
public:
ActorNetwork(int state_dim, int action_dim, double action_low, double action_high);
torch::Tensor forward(torch::Tensor x);
// Eigen向量转Tensor(推理用)
torch::Tensor eigen_to_tensor(const Eigen::VectorXd& x);
// Tensor转Eigen向量(推理用)
Eigen::VectorXd tensor_to_eigen(const torch::Tensor& x);
private:
torch::nn::Linear fc1_{nullptr}, fc2_{nullptr}, fc3_{nullptr};
double action_low_;
double action_high_;
};
// Critic网络:输入(状态+动作)→输出Q值(单输出)
class CriticNetwork : public torch::nn::Module
{
public:
CriticNetwork(int state_dim, int action_dim);
torch::Tensor forward(torch::Tensor x, torch::Tensor a);
private:
torch::nn::Linear fc1_{nullptr}, fc2_{nullptr}, fc3_{nullptr};
};
// TD3双Critic网络(避免过估计)
class TwinCriticNetworks : public torch::nn::Module
{
public:
TwinCriticNetworks(int state_dim, int action_dim);
std::pair<torch::Tensor, torch::Tensor> forward(torch::Tensor x, torch::Tensor a);
// 获取两个Critic网络
std::shared_ptr<CriticNetwork> get_critic1() { return critic1_; }
std::shared_ptr<CriticNetwork> get_critic2() { return critic2_; }
private:
std::shared_ptr<CriticNetwork> critic1_;
std::shared_ptr<CriticNetwork> critic2_;
};
} // namespace drone_rl_cpp
#endif // TD3_NETWORKS_HPP_(4)网络实现(src/networks/TD3Networks.cpp)
cpp
#include "drone_rl_cpp/networks/TD3Networks.hpp"
namespace drone_rl_cpp
{
// Actor网络实现
ActorNetwork::ActorNetwork(int state_dim, int action_dim, double action_low, double action_high)
: action_low_(action_low), action_high_(action_high)
{
// 三层MLP:state_dim→256→128→action_dim
fc1_ = register_module("fc1", torch::nn::Linear(state_dim, 256));
fc2_ = register_module("fc2", torch::nn::Linear(256, 128));
fc3_ = register_module("fc3", torch::nn::Linear(128, action_dim));
// 初始化权重(Xavier均匀分布)
torch::nn::init::xavier_uniform_(fc1_->weight);
torch::nn::init::xavier_uniform_(fc2_->weight);
torch::nn::init::xavier_uniform_(fc3_->weight);
torch::nn::init::constant_(fc1_->bias, 0.01);
torch::nn::init::constant_(fc2_->bias, 0.01);
torch::nn::init::constant_(fc3_->bias, 0.01);
}
torch::Tensor ActorNetwork::forward(torch::Tensor x)
{
// 激活函数:ReLU + Tanh(将输出映射到[-1,1],再缩放至动作范围)
x = torch::relu(fc1_->forward(x));
x = torch::relu(fc2_->forward(x));
x = torch::tanh(fc3_->forward(x)); // [-1,1]
// 缩放至动作范围[action_low, action_high]
return (x + 1.0) * (action_high_ - action_low_) / 2.0 + action_low_;
}
torch::Tensor ActorNetwork::eigen_to_tensor(const Eigen::VectorXd& x)
{
return torch::from_blob(const_cast<double*>(x.data()), {1, x.size()}, torch::kFloat32).to(torch::kCUDA);
}
Eigen::VectorXd ActorNetwork::tensor_to_eigen(const torch::Tensor& x)
{
auto cpu_tensor = x.detach().cpu().squeeze();
Eigen::VectorXd eigen_vec(cpu_tensor.size(0));
std::memcpy(eigen_vec.data(), cpu_tensor.data_ptr(), cpu_tensor.numel() * sizeof(float));
return eigen_vec;
}
// Critic网络实现
CriticNetwork::CriticNetwork(int state_dim, int action_dim)
{
// 三层MLP:state_dim+action_dim→256→128→1(Q值)
fc1_ = register_module("fc1", torch::nn::Linear(state_dim + action_dim, 256));
fc2_ = register_module("fc2", torch::nn::Linear(256, 128));
fc3_ = register_module("fc3", torch::nn::Linear(128, 1));
// 初始化权重
torch::nn::init::xavier_uniform_(fc1_->weight);
torch::nn::init::xavier_uniform_(fc2_->weight);
torch::nn::init::xavier_uniform_(fc3_->weight);
torch::nn::init::constant_(fc1_->bias, 0.01);
torch::nn::init::constant_(fc2_->bias, 0.01);
torch::nn::init::constant_(fc3_->bias, 0.01);
}
torch::Tensor CriticNetwork::forward(torch::Tensor x, torch::Tensor a)
{
// 拼接状态和动作
torch::Tensor cat = torch::cat({x, a}, 1);
cat = torch::relu(fc1_->forward(cat));
cat = torch::relu(fc2_->forward(cat));
return fc3_->forward(cat); // Q值输出
}
// 双Critic网络实现
TwinCriticNetworks::TwinCriticNetworks(int state_dim, int action_dim)
{
critic1_ = std::make_shared<CriticNetwork>(state_dim, action_dim);
critic2_ = std::make_shared<CriticNetwork>(state_dim, action_dim);
register_module("critic1", critic1_);
register_module("critic2", critic2_);
}
std::pair<torch::Tensor, torch::Tensor> TwinCriticNetworks::forward(torch::Tensor x, torch::Tensor a)
{
return {critic1_->forward(x, a), critic2_->forward(x, a)};
}
} // namespace drone_rl_cpp(5)经验回放缓冲区(include/drone_rl_cpp/utils/ReplayBuffer.hpp)
cpp
#ifndef REPLAY_BUFFER_HPP_
#define REPLAY_BUFFER_HPP_
#include <Eigen/Dense>
#include <vector>
#include <mutex>
#include <random>
namespace drone_rl_cpp
{
struct Transition
{
Eigen::VectorXd state;
Eigen::VectorXd action;
double reward;
Eigen::VectorXd next_state;
bool done;
};
class ReplayBuffer
{
public:
ReplayBuffer(int capacity, int state_dim, int action_dim);
~ReplayBuffer() = default;
// 添加经验
void push(const Transition& transition);
// 采样批次经验(返回Tensor,用于训练)
std::tuple<torch::Tensor, torch::Tensor, torch::Tensor, torch::Tensor, torch::Tensor> sample_batch(int batch_size);
// 缓冲区大小
int size() const { return static_cast<int>(buffer_.size()); }
// 缓冲区是否已满
bool is_full() const { return size() >= capacity_; }
private:
int capacity_; // 缓冲区最大容量
int state_dim_; // 状态维度
int action_dim_; // 动作维度
std::vector<Transition> buffer_; // 经验缓冲区
std::mutex buffer_mutex_; // 线程安全锁
std::mt19937 rng_; // 随机数生成器
int write_idx_; // 写入索引
};
} // namespace drone_rl_cpp
#endif // REPLAY_BUFFER_HPP_(6)缓冲区实现(src/utils/ReplayBuffer.cpp)
cpp
#include "drone_rl_cpp/utils/ReplayBuffer.hpp"
#include <torch/torch.h>
namespace drone_rl_cpp
{
ReplayBuffer::ReplayBuffer(int capacity, int state_dim, int action_dim)
: capacity_(capacity)
, state_dim_(state_dim)
, action_dim_(action_dim)
, write_idx_(0)
, rng_(std::random_device{}())
{
buffer_.reserve(capacity_);
}
void ReplayBuffer::push(const Transition& transition)
{
std::lock_guard<std::mutex> lock(buffer_mutex_);
if (buffer_.size() < capacity_) {
buffer_.emplace_back(transition);
} else {
buffer_[write_idx_] = transition;
}
write_idx_ = (write_idx_ + 1) % capacity_;
}
std::tuple<torch::Tensor, torch::Tensor, torch::Tensor, torch::Tensor, torch::Tensor> ReplayBuffer::sample_batch(int batch_size)
{
std::lock_guard<std::mutex> lock(buffer_mutex_);
int current_size = buffer_.size();
if (current_size < batch_size) {
throw std::runtime_error("Replay buffer size (" + std::to_string(current_size) + ") < batch size (" + std::to_string(batch_size) + ")");
}
// 随机采样索引
std::uniform_int_distribution<> dist(0, current_size - 1);
std::vector<int> indices(batch_size);
for (int i = 0; i < batch_size; ++i) {
indices[i] = dist(rng_);
}
// 初始化Tensor(GPU存储)
torch::Tensor states = torch::zeros({batch_size, state_dim_}, torch::kFloat32).to(torch::kCUDA);
torch::Tensor actions = torch::zeros({batch_size, action_dim_}, torch::kFloat32).to(torch::kCUDA);
torch::Tensor rewards = torch::zeros({batch_size, 1}, torch::kFloat32).to(torch::kCUDA);
torch::Tensor next_states = torch::zeros({batch_size, state_dim_}, torch::kFloat32).to(torch::kCUDA);
torch::Tensor dones = torch::zeros({batch_size, 1}, torch::kFloat32).to(torch::kCUDA);
// 填充数据
for (int i = 0; i < batch_size; ++i) {
const auto& t = buffer_[indices[i]];
states[i] = torch::from_blob(const_cast<double*>(t.state.data()), {state_dim_}, torch::kFloat32);
actions[i] = torch::from_blob(const_cast<double*>(t.action.data()), {action_dim_}, torch::kFloat32);
rewards[i] = t.reward;
next_states[i] = torch::from_blob(const_cast<double*>(t.next_state.data()), {state_dim_}, torch::kFloat32);
dones[i] = t.done ? 1.0f : 0.0f;
}
return {states, actions, rewards, next_states, dones};
}
} // namespace drone_rl_cpp(7)TD3智能体(include/drone_rl_cpp/TD3Agent.hpp)
整合网络、缓冲区、训练逻辑:
cpp
#ifndef TD3_AGENT_HPP_
#define TD3_AGENT_HPP_
#include "drone_rl_cpp/networks/TD3Networks.hpp"
#include "drone_rl_cpp/utils/ReplayBuffer.hpp"
#include <torch/torch.h>
#include <Eigen/Dense>
#include <vector>
namespace drone_rl_cpp
{
class TD3Agent
{
public:
TD3Agent(
int state_dim,
int action_dim,
double action_low,
double action_high,
int buffer_capacity = 1000000,
int batch_size = 256,
double gamma = 0.99,
double tau = 0.005,
double lr_actor = 3e-4,
double lr_critic = 3e-4,
double policy_noise = 0.1,
double noise_clip = 0.2,
int policy_freq = 2
);
~TD3Agent() = default;
// 选择动作(训练时加噪声,推理时不加)
Eigen::VectorXd select_action(const Eigen::VectorXd& state, bool is_training = true);
// 训练智能体
double train();
// 保存模型
void save_model(const std::string& path);
// 加载模型
void load_model(const std::string& path);
// 获取经验回放缓冲区
ReplayBuffer& get_replay_buffer() { return replay_buffer_; }
private:
// 网络相关
std::shared_ptr<ActorNetwork> actor_;
std::shared_ptr<ActorNetwork> target_actor_;
std::shared_ptr<TwinCriticNetworks> critics_;
std::shared_ptr<TwinCriticNetworks> target_critics_;
// 优化器
torch::optim::Adam actor_optimizer_;
torch::optim::Adam critics_optimizer_;
// 经验回放缓冲区
ReplayBuffer replay_buffer_;
// TD3超参数
int state_dim_;
int action_dim_;
double action_low_;
double action_high_;
int batch_size_;
double gamma_; // 折扣因子
double tau_; // 目标网络软更新系数
double policy_noise_; // 动作噪声标准差
double noise_clip_; // 噪声裁剪范围
int policy_freq_; // Actor更新频率(每N步更新一次)
int update_count_; // 更新计数器
// 随机数生成器(动作噪声)
std::mt19937 rng_;
std::normal_distribution<> noise_dist_;
};
} // namespace drone_rl_cpp
#endif // TD3_AGENT_HPP_(8)智能体实现(src/TD3Agent.cpp)
cpp
#include "drone_rl_cpp/TD3Agent.hpp"
#include <torch/torch.h>
#include <fstream>
namespace drone_rl_cpp
{
TD3Agent::TD3Agent(
int state_dim,
int action_dim,
double action_low,
double action_high,
int buffer_capacity,
int batch_size,
double gamma,
double tau,
double lr_actor,
double lr_critic,
double policy_noise,
double noise_clip,
int policy_freq
)
: state_dim_(state_dim)
, action_dim_(action_dim)
, action_low_(action_low)
, action_high_(action_high)
, batch_size_(batch_size)
, gamma_(gamma)
, tau_(tau)
, policy_noise_(policy_noise)
, noise_clip_(noise_clip)
, policy_freq_(policy_freq)
, update_count_(0)
, rng_(std::random_device{}())
, noise_dist_(0.0, policy_noise)
, replay_buffer_(buffer_capacity, state_dim, action_dim)
, actor_(std::make_shared<ActorNetwork>(state_dim, action_dim, action_low, action_high))
, target_actor_(std::make_shared<ActorNetwork>(state_dim, action_dim, action_low, action_high))
, critics_(std::make_shared<TwinCriticNetworks>(state_dim, action_dim))
, target_critics_(std::make_shared<TwinCriticNetworks>(state_dim, action_dim))
, actor_optimizer_(actor_->parameters(), torch::optim::AdamOptions(lr_actor))
, critics_optimizer_(critics_->parameters(), torch::optim::AdamOptions(lr_critic))
{
// 移动网络到GPU
actor_->to(torch::kCUDA);
target_actor_->to(torch::kCUDA);
critics_->to(torch::kCUDA);
target_critics_->to(torch::kCUDA);
// 目标网络初始参数与主网络一致
target_actor_->load_state_dict(actor_->state_dict());
target_critics_->load_state_dict(critics_->state_dict());
// 冻结目标网络梯度(只通过软更新更新)
for (auto& param : target_actor_->parameters()) {
param.requires_grad_(false);
}
for (auto& param : target_critics_->parameters()) {
param.requires_grad_(false);
}
}
Eigen::VectorXd TD3Agent::select_action(const Eigen::VectorXd& state, bool is_training)
{
// 推理模式(禁用梯度计算)
torch::NoGradGuard no_grad;
torch::Tensor state_tensor = actor_->eigen_to_tensor(state);
torch::Tensor action_tensor = actor_->forward(state_tensor);
// 训练时添加动作噪声(探索)
if (is_training) {
Eigen::VectorXd noise(action_dim_);
for (int i = 0; i < action_dim_; ++i) {
noise(i) = noise_dist_(rng_);
}
// 噪声裁剪
noise = noise.cwiseMax(-noise_clip_).cwiseMin(noise_clip_);
// 动作添加噪声后裁剪到有效范围
Eigen::VectorXd action = actor_->tensor_to_eigen(action_tensor) + noise;
return action.cwiseMax(action_low_).cwiseMin(action_high_);
}
// 推理时直接返回确定性动作
return actor_->tensor_to_eigen(action_tensor);
}
double TD3Agent::train()
{
// 采样批次经验
auto [states, actions, rewards, next_states, dones] = replay_buffer_.sample_batch(batch_size_);
// ---------------------- 训练Critic网络 ----------------------
critics_optimizer_.zero_grad();
// 目标动作(添加噪声,提高稳定性)
torch::Tensor target_actions = target_actor_->forward(next_states);
torch::Tensor noise = torch::randn_like(target_actions) * policy_noise_;
noise = noise.clamp(-noise_clip_, noise_clip_);
target_actions = (target_actions + noise).clamp(action_low_, action_high_);
// 目标Q值(取两个Critic的最小值,避免过估计)
auto [target_q1, target_q2] = target_critics_->forward(next_states, target_actions);
torch::Tensor target_q = torch::min(target_q1, target_q2);
torch::Tensor target_q_values = rewards + (1.0 - dones) * gamma_ * target_q;
// 主Critic的Q值
auto [q1, q2] = critics_->forward(states, actions);
// Critic损失(MSE)
torch::Tensor critic_loss = torch::mse_loss(q1, target_q_values) + torch::mse_loss(q2, target_q_values);
critic_loss.backward();
critics_optimizer_.step();
// ---------------------- 训练Actor网络(每policy_freq步更新一次) ----------------------
if (update_count_ % policy_freq_ == 0) {
actor_optimizer_.zero_grad();
// Actor损失(最大化Critic1的Q值)
torch::Tensor actor_actions = actor_->forward(states);
torch::Tensor actor_loss = -critics_->get_critic1()->forward(states, actor_actions).mean();
actor_loss.backward();
actor_optimizer_.step();
// ---------------------- 软更新目标网络 ----------------------
for (auto& [target_param, param] : std::make_pair(target_actor_->parameters(), actor_->parameters())) {
target_param.data().copy_(tau_ * param.data() + (1.0 - tau_) * target_param.data());
}
for (auto& [target_param, param] : std::make_pair(target_critics_->parameters(), critics_->parameters())) {
target_param.data().copy_(tau_ * param.data() + (1.0 - tau_) * target_param.data());
}
}
update_count_++;
return critic_loss.item<double>();
}
void TD3Agent::save_model(const std::string& path)
{
// 保存网络参数
torch::save(actor_, path + "/actor.pt");
torch::save(critics_, path + "/critics.pt");
torch::save(actor_optimizer_, path + "/actor_optimizer.pt");
torch::save(critics_optimizer_, path + "/critics_optimizer.pt");
RCLCPP_INFO(rclcpp::get_logger("TD3Agent"), "Model saved to %s", path.c_str());
}
void TD3Agent::load_model(const std::string& path)
{
// 加载网络参数
torch::load(actor_, path + "/actor.pt");
torch::load(critics_, path + "/critics.pt");
torch::load(actor_optimizer_, path + "/actor_optimizer.pt");
torch::load(critics_optimizer_, path + "/critics_optimizer.pt");
// 同步目标网络
target_actor_->load_state_dict(actor_->state_dict());
target_critics_->load_state_dict(critics_->state_dict());
// 移动到GPU
actor_->to(torch::kCUDA);
target_actor_->to(torch::kCUDA);
critics_->to(torch::kCUDA);
target_critics_->to(torch::kCUDA);
RCLCPP_INFO(rclcpp::get_logger("TD3Agent"), "Model loaded from %s", path.c_str());
}
} // namespace drone_rl_cpp(9)TensorRT推理封装(include/drone_rl_cpp/utils/TrtInfer.hpp)
cpp
#ifndef TRT_INFER_HPP_
#define TRT_INFER_HPP_
#include <tensorrt/NvInfer.h>
#include <cuda_runtime_api.h>
#include <Eigen/Dense>
#include <string>
#include <memory>
#include <vector>
namespace drone_rl_cpp
{
class TrtInfer
{
public:
TrtInfer(const std::string& engine_path);
~TrtInfer();
// 推理:输入Eigen向量(22维),输出Eigen向量(4维)
Eigen::VectorXd infer(const Eigen::VectorXd& input);
private:
// 资源释放辅助类
class TrtDeleter
{
public:
void operator()(nvinfer1::ICudaEngine* engine) const { engine->destroy(); }
void operator()(nvinfer1::IExecutionContext* context) const { context->destroy(); }
void operator()(nvinfer1::IRuntime* runtime) const { runtime->destroy(); }
};
std::unique_ptr<nvinfer1::IRuntime, TrtDeleter> runtime_;
std::unique_ptr<nvinfer1::ICudaEngine, TrtDeleter> engine_;
std::unique_ptr<nvinfer1::IExecutionContext, TrtDeleter> context_;
// GPU缓冲区
void* d_input_ = nullptr;
void* d_output_ = nullptr;
// 输入输出维度
static constexpr int INPUT_DIM = 22;
static constexpr int OUTPUT_DIM = 4;
size_t input_size_;
size_t output_size_;
};
} // namespace drone_rl_cpp
#endif // TRT_INFER_HPP_(10)TensorRT推理实现(src/utils/TrtInfer.cpp)
cpp
#include "drone_rl_cpp/utils/TrtInfer.hpp"
#include <fstream>
#include <iostream>
#include <rclcpp/rclcpp.hpp>
using namespace nvinfer1;
namespace drone_rl_cpp
{
TrtInfer::TrtInfer(const std::string& engine_path)
{
// 1. 读取TensorRT引擎文件
std::ifstream engine_file(engine_path, std::ios::binary);
if (!engine_file) {
throw std::runtime_error("Failed to open TRT engine file: " + engine_path);
}
engine_file.seekg(0, std::ios::end);
const size_t engine_size = engine_file.tellg();
engine_file.seekg(0, std::ios::beg);
std::vector<char> engine_data(engine_size);
engine_file.read(engine_data.data(), engine_size);
// 2. 初始化TensorRT运行时
IRuntime* runtime = createInferRuntime(Logger(Logger::WARNING));
if (!runtime) {
throw std::runtime_error("Failed to create TRT runtime");
}
runtime_.reset(runtime);
// 3. 反序列化引擎
ICudaEngine* engine = runtime->deserializeCudaEngine(engine_data.data(), engine_size, nullptr);
if (!engine) {
throw std::runtime_error("Failed to deserialize TRT engine");
}
engine_.reset(engine);
// 4. 创建执行上下文
IExecutionContext* context = engine->createExecutionContext();
if (!context) {
throw std::runtime_error("Failed to create TRT execution context");
}
context_.reset(context);
// 5. 计算缓冲区大小并分配GPU内存
input_size_ = INPUT_DIM * sizeof(float);
output_size_ = OUTPUT_DIM * sizeof(float);
cudaMalloc(&d_input_, input_size_);
cudaMalloc(&d_output_, output_size_);
RCLCPP_INFO(rclcpp::get_logger("TrtInfer"), "TRT engine initialized successfully (input dim: %d, output dim: %d)",
INPUT_DIM, OUTPUT_DIM);
}
TrtInfer::~TrtInfer()
{
cudaFree(d_input_);
cudaFree(d_output_);
}
Eigen::VectorXd TrtInfer::infer(const Eigen::VectorXd& input)
{
if (input.size() != INPUT_DIM) {
throw std::runtime_error("Input dimension mismatch: expected " + std::to_string(INPUT_DIM) +
", got " + std::to_string(input.size()));
}
// 1. 输入数据预处理(double→float,CPU→GPU)
std::vector<float> input_host(INPUT_DIM);
for (int i = 0; i < INPUT_DIM; ++i) {
input_host[i] = static_cast<float>(input(i));
}
cudaMemcpy(d_input_, input_host.data(), input_size_, cudaMemcpyHostToDevice);
// 2. 执行推理
void* bindings[] = {d_input_, d_output_};
context_->executeV2(bindings);
// 3. 输出数据后处理(GPU→CPU,float→double)
std::vector<float> output_host(OUTPUT_DIM);
cudaMemcpy(output_host.data(), d_output_, output_size_, cudaMemcpyDeviceToHost);
Eigen::VectorXd output(OUTPUT_DIM);
for (int i = 0; i < OUTPUT_DIM; ++i) {
output(i) = static_cast<double>(output_host[i]);
}
return output;
}
} // namespace drone_rl_cpp3. ROS2训练节点(src/train_node.cpp)
cpp
#include "drone_rl_cpp/env/DroneEnv.hpp"
#include "drone_rl_cpp/TD3Agent.hpp"
#include <rclcpp/rclcpp.hpp>
#include <chrono>
#include <iomanip>
using namespace drone_rl_cpp;
using namespace std::chrono;
int main(int argc, char* argv[])
{
// 初始化ROS2
rclcpp::init(argc, argv);
auto node = std::make_shared<rclcpp::Node>("td3_train_node");
// 初始化环境和智能体
auto env = std::make_shared<DroneEnv>();
if (!env->is_ready()) {
RCLCPP_FATAL(node->get_logger(), "Environment not ready, exit");
return -1;
}
TD3Agent agent(
DroneEnv::STATE_DIM,
DroneEnv::ACTION_DIM,
DroneEnv::ACTION_LOW,
DroneEnv::ACTION_HIGH,
1000000, // 缓冲区容量
256, // 批次大小
0.99, // gamma
0.005, // tau
3e-4, // lr_actor
3e-4, // lr_critic
0.1, // policy_noise
0.2, // noise_clip
2 // policy_freq
);
// 训练参数
const int total_episodes = 500; // 总回合数
const int max_steps_per_episode = 1000; // 每回合最大步数
const int start_train_steps = 10000; // 前N步随机探索,不训练
double total_steps = 0;
RCLCPP_INFO(node->get_logger(), "Start TD3 training (total episodes: %d)", total_episodes);
// 训练主循环
for (int ep = 0; ep < total_episodes && rclcpp::ok(); ++ep) {
Eigen::VectorXd state = env->reset();
double ep_reward = 0.0;
bool ep_done = false;
auto ep_start = high_resolution_clock::now();
for (int step = 0; step < max_steps_per_episode && !ep_done; ++step) {
// 选择动作(前start_train_steps步随机探索)
Eigen::VectorXd action;
if (total_steps < start_train_steps) {
// 随机动作
std::uniform_real_distribution<> dist(DroneEnv::ACTION_LOW, DroneEnv::ACTION_HIGH);
action.resize(DroneEnv::ACTION_DIM);
for (int i = 0; i < DroneEnv::ACTION_DIM; ++i) {
action(i) = dist(agent.get_replay_buffer().rng_);
}
} else {
// 智能体动作(带噪声)
action = agent.select_action(state, true);
}
// 执行动作,获取经验
auto [next_state, reward, done, info] = env->step(action);
ep_reward += reward;
ep_done = done;
// 存储经验到缓冲区
Transition transition{state, action, reward, next_state, done};
agent.get_replay_buffer().push(transition);
// 训练智能体(达到最小探索步数后)
if (total_steps >= start_train_steps) {
double loss = agent.train();
if (step % 100 == 0) {
RCLCPP_INFO(node->get_logger(), "Episode %d, Step %d, Critic Loss: %.4f",
ep, step, loss);
}
}
// 更新状态和步数
state = next_state;
total_steps++;
}
// 回合结束统计
auto ep_end = high_resolution_clock::now();
double ep_duration = duration_cast<duration<double>>(ep_end - ep_start).count();
RCLCPP_INFO(node->get_logger(),
"Episode [%d/%d] | Reward: %.2f | Steps: %d | Duration: %.2fs | Info: %s | Total Steps: %.0f",
ep + 1, total_episodes, ep_reward, step, ep_duration, info.c_str(), total_steps);
// 每50回合保存一次模型
if ((ep + 1) % 50 == 0) {
std::string model_path = "./models/td3_ep" + std::to_string(ep + 1);
agent.save_model(model_path);
}
}
// 训练结束,保存最终模型
agent.save_model("./models/td3_final");
RCLCPP_INFO(node->get_logger(), "Training completed! Final model saved to ./models/td3_final");
rclcpp::shutdown();
return 0;
}4. ROS2推理控制节点(src/infer_node.cpp)
cpp
#include "drone_rl_cpp/env/DroneEnv.hpp"
#include "drone_rl_cpp/utils/TrtInfer.hpp"
#include <rclcpp/rclcpp.hpp>
#include <chrono>
#include <sched.h>
using namespace drone_rl_cpp;
using namespace std::chrono;
int main(int argc, char* argv[])
{
// 初始化ROS2
rclcpp::init(argc, argv);
auto node = std::make_shared<rclcpp::Node>("td3_infer_node");
// 设置实时优先级(Orin NX实机必须,确保控制延迟)
struct sched_param param;
param.sched_priority = 99;
if (sched_setscheduler(0, SCHED_FIFO, ¶m) == -1) {
RCLCPP_WARN(node->get_logger(), "Failed to set real-time priority: %s", strerror(errno));
}
// 读取TensorRT引擎路径参数
std::string engine_path = node->declare_parameter<std::string>("engine_path", "./models/td3_final_fp16.engine");
// 初始化环境和TensorRT推理器
auto env = std::make_shared<DroneEnv>();
if (!env->is_ready()) {
RCLCPP_FATAL(node->get_logger(), "Environment not ready, exit");
return -1;
}
std::unique_ptr<TrtInfer> trt_infer;
try {
trt_infer = std::make_unique<TrtInfer>(engine_path);
} catch (const std::exception& e) {
RCLCPP_FATAL(node->get_logger(), "Failed to initialize TRT infer: %s", e.what());
return -1;
}
// 推理统计
int total_steps = 0;
double total_delay = 0.0;
const int stat_window = 100; // 每100步统计一次延迟
RCLCPP_INFO(node->get_logger(), "Start TD3 inference (control frequency target: 200Hz)");
// 推理主循环
Eigen::VectorXd state = env->reset();
while (rclcpp::ok()) {
// 记录推理开始时间
auto start = high_resolution_clock::now();
// 1. 推理获取动作
Eigen::VectorXd action = trt_infer->infer(state);
// 动作裁剪(确保在有效范围)
action = action.cwiseMax(DroneEnv::ACTION_LOW).cwiseMin(DroneEnv::ACTION_HIGH);
// 2. 执行动作
auto [next_state, reward, done, info] = env->step(action);
// 3. 计算推理延迟
auto end = high_resolution_clock::now();
double delay = duration_cast<duration<double, std::milli>>(end - start).count();
total_delay += delay;
total_steps++;
// 4. 状态更新
state = next_state;
// 5. 统计输出(每stat_window步)
if (total_steps % stat_window == 0) {
double avg_delay = total_delay / stat_window;
double freq = 1000.0 / avg_delay;
RCLCPP_INFO(node->get_logger(),
"Step: %d | Avg Delay: %.2fms | Control Freq: %.1fHz | Reward: %.2f | Info: %s",
total_steps, avg_delay, freq, reward, info.c_str());
total_delay = 0.0;
}
// 6. 重置环境(任务完成或碰撞)
if (done) {
RCLCPP_INFO(node->get_logger(), "Episode done, reset environment");
state = env->reset();
}
}
rclcpp::shutdown();
return 0;
}四、模型转换(LibTorch→ONNX→TensorRT)
1. LibTorch模型导出为ONNX(C++代码)
创建src/utils/export_onnx.cpp:
cpp
#include "drone_rl_cpp/networks/TD3Networks.hpp"
#include <torch/torch.h>
#include <fstream>
int main(int argc, char* argv[])
{
if (argc != 3) {
std::cerr << "Usage: " << argv[0] << " <libtorch_model_path> <output_onnx_path>" << std::endl;
return -1;
}
std::string model_path = argv[1];
std::string onnx_path = argv[2];
// 初始化Actor网络
int state_dim = 22;
int action_dim = 4;
double action_low = 500.0;
double action_high = 2000.0;
auto actor = std::make_shared<drone_rl_cpp::ActorNetwork>(state_dim, action_dim, action_low, action_high);
actor->to(torch::kCUDA);
// 加载LibTorch模型
torch::load(actor, model_path + "/actor.pt");
actor->eval(); // 推理模式
// 构建虚拟输入(batch_size=1)
torch::Tensor dummy_input = torch::randn({1, state_dim}, torch::kFloat32).to(torch::kCUDA);
// 导出ONNX
torch::onnx::export_to_onnx(
*actor,
dummy_input,
onnx_path,
torch::onnx::ExportConfig(),
{torch::onnx::OperatorExportTypes::ONNX_ATEN_FALLBACK}
);
std::cout << "ONNX model exported to: " << onnx_path << std::endl;
return 0;
}2. ONNX转换为TensorRT引擎(C++代码)
创建src/utils/convert_trt.cpp:
cpp
#include <tensorrt/NvInfer.h>
#include <tensorrt/NvOnnxParser.h>
#include <cuda_runtime_api.h>
#include <fstream>
#include <iostream>
using namespace nvinfer1;
using namespace nvonnxparser;
int main(int argc, char* argv[])
{
if (argc != 3) {
std::cerr << "Usage: " << argv[0] << " <onnx_path> <output_engine_path>" << std::endl;
return -1;
}
std::string onnx_path = argv[1];
std::string engine_path = argv[2];
// 创建Logger
Logger logger(Logger::WARNING);
// 1. 创建Builder和Network
IBuilder* builder = createInferBuilder(logger);
INetworkDefinition* network = builder->createNetworkV2(1U << static_cast<int>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
// 2. 解析ONNX模型
IParser* parser = createParser(*network, logger);
if (!parser->parseFromFile(onnx_path.c_str(), static_cast<int>(Logger::WARNING))) {
std::cerr << "Failed to parse ONNX model" << std::endl;
return -1;
}
// 3. 配置Builder
IBuilderConfig* config = builder->createBuilderConfig();
config->setMaxWorkspaceSize(1ULL << 30); // 1GB工作空间
config->setFlag(BuilderFlag::kFP16); // 启用FP16量化
// 4. 构建引擎
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
if (!engine) {
std::cerr << "Failed to build TensorRT engine" << std::endl;
return -1;
}
// 5. 序列化并保存引擎
IHostMemory* serialized_engine = engine->serialize();
std::ofstream engine_file(engine_path, std::ios::binary);
engine_file.write(reinterpret_cast<const char*>(serialized_engine->data()), serialized_engine->size());
// 6. 释放资源
serialized_engine->destroy();
engine->destroy();
config->destroy();
network->destroy();
parser->destroy();
builder->destroy();
std::cout << "TensorRT engine saved to: " << engine_path << std::endl;
return 0;
}五、CMakeLists.txt配置
c
cmake_minimum_required(VERSION 3.20)
project(drone_rl_cpp)
if(CMAKE_COMPILER_IS_GNUCXX OR CMAKE_CXX_COMPILER_ID MATCHES "Clang")
add_compile_options(-Wall -Wextra -Wpedantic -O3 -std=c++17)
endif()
# 查找依赖包
find_package(ament_cmake REQUIRED)
find_package(rclcpp REQUIRED)
find_package(sensor_msgs REQUIRED)
find_package(geometry_msgs REQUIRED)
find_package(std_msgs REQUIRED)
find_package(gazebo_ros2_control REQUIRED)
find_package(ros2_control REQUIRED)
find_package(Eigen3 REQUIRED)
find_package(OpenCV REQUIRED)
find_package(PCL REQUIRED COMPONENTS common io)
# LibTorch依赖(自动查找)
find_package(Torch REQUIRED)
message(STATUS "LibTorch found: ${Torch_FOUND}, Version: ${Torch_VERSION}")
# TensorRT和CUDA依赖
find_package(CUDAToolkit REQUIRED)
find_library(NVINFER_LIB nvinfer HINTS /usr/lib/aarch64-linux-gnu/)
find_library(NVONNXPARSER_LIB nvonnxparser HINTS /usr/lib/aarch64-linux-gnu/)
message(STATUS "TensorRT libs: ${NVINFER_LIB}, ${NVONNXPARSER_LIB}")
# 包含目录
include_directories(
include
${EIGEN3_INCLUDE_DIRS}
${OpenCV_INCLUDE_DIRS 以上就是关于强化学习与飞控的结合的示例分享。大家可以尝试一下。有想沟通学习无人机开发知识,包括但不限于飞控、导航、规划、仿真、大疆PSDK等开发,看我主页。可以加入群聊,一起讨论学习。
