一、词向量(词嵌入)
将自然语言文本转化成机器可以处理的向量形式。
1 编码
- OneHot独热编码
OneHot,独热编码,是一种用离散符号来表示词向量的方法。向量的长度为词汇表中总的词数。每个词有一个编号,这个位置的值为1,其余位置都为0。
缺点:词向量维度过大,词之间相当于是独立的,无法表示词之间的关系。 - 分布式语义表示
分布式语义表示:每个单词不再是完全正交的0-1向量,而是在多维实数空间中的一个点,具体表现为一个实数向量。在向量空间中距离越近表示词义越相似。
2 构建词向量
上下文越接近,表示这个词语义也接近。
(1)Word2Vec
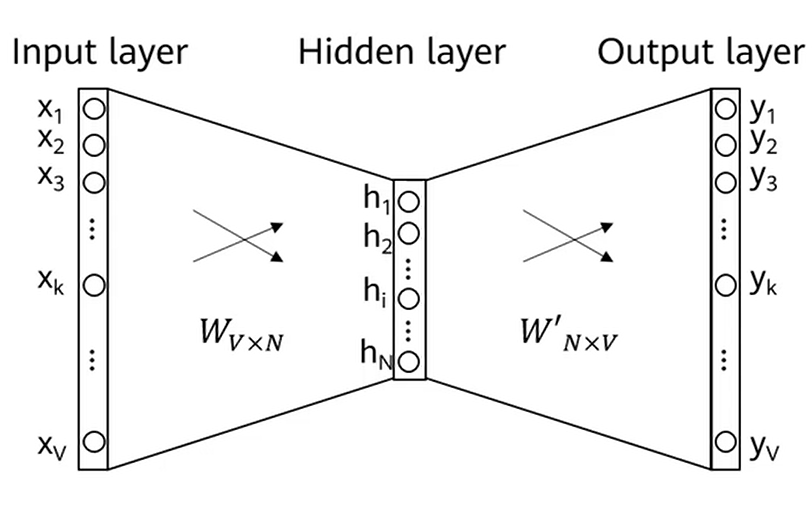
准备一个大的语料库,词汇表中每个词都有对应的向量表示。遍历语料库中的每篇文章的每个位置,这个位置有个中心词ccc,然后固定一个窗口大小,窗口中的这些词记为上下文词ooo。如上图所示,假如使用中心词来预测上下文词,输入层只有一个位置为1,然后通过N条边与隐藏层连接,再通过softmax得到V维的输出层,表示V个可能的上下文词概率,通过训练使得正确的上下文词概率最大。这里就有两个词向量分别记为U和V,维度是N,值是X到H的权重和H到Y的权重。概率表示为这两个词向量的内积。
缺点:输入向量计算量较小,每次只需点亮一个x,对于输出向量计算量较大,需计算V个y。
(2)Glove
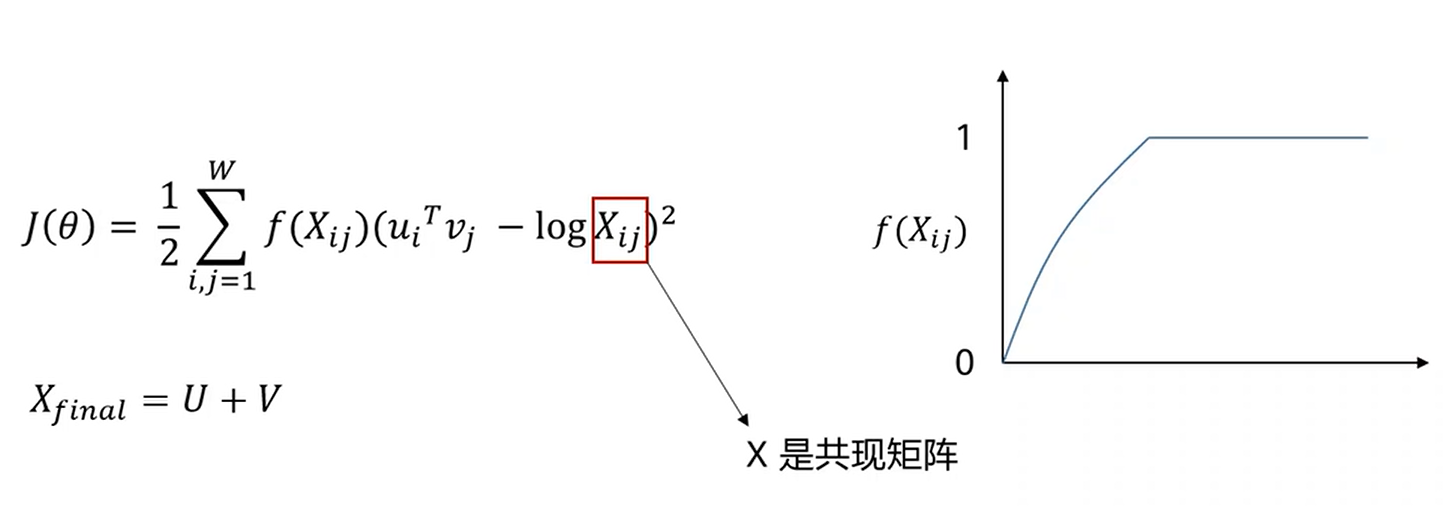
拟合一个共现矩阵。使用统计的方法,固定一个窗口,假如这个窗口中两个词距离小于一个阈值,就认为共同出现,就让矩阵中的位置为1,这个矩阵是对称的,第ij个值表示第i个词和第j个词是否共现。
两个词的向量的乘积要尽可能和共现频率接近,前面的f表示一个权重函数,当贡献频率越大这个权重越大,认为这种关系更值得去学习。最后词向量定义为u和v的和。
缺点:不能处理未登录的词,即词汇表之外的词。
(3)fastText
充分利用字符的ngram信息,将词拆分为各个子词,然后最终的词向量为各个子词的向量之和。可以处理未登录词。
3 词向量评估
- 内部评估
1 相似度,可以通过词向量的乘积或者空间中的夹角表示。
2 类比任务:比如:King−Queen=Man−WomanKing-Queen=Man-WomanKing−Queen=Man−Woman - 外部评估
以实际任务的指标来评价词向量的好坏。如命名实体识别、机器翻译、文本分类等。
二、文本分类
- 定义:
输入:一篇文章d,固定的类别集合C=C1,C2,...CjC={C_1,C_2,...C_j}C=C1,C2,...Cj
输出:预测出该文章的类别 - 应用:情感分析,意图识别,内容审核等
深度学习方法:
1 TextCNN
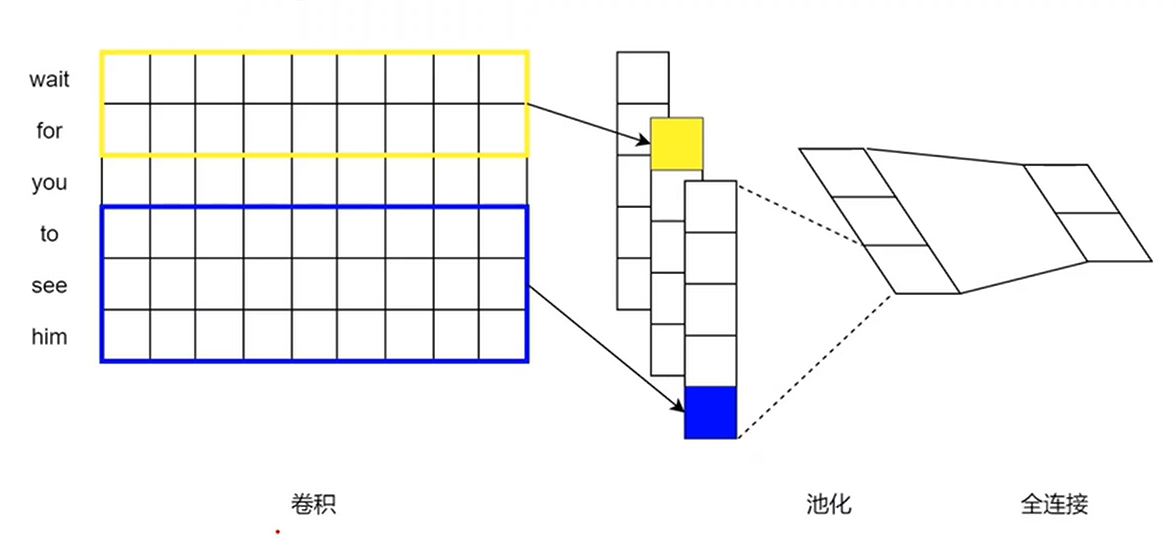
与图像中的CNN不同,这里卷积操作在一维数据上,即卷积核只会在不同词之间滑动,不会在向量这个方向上滑动。
2 TextRNN
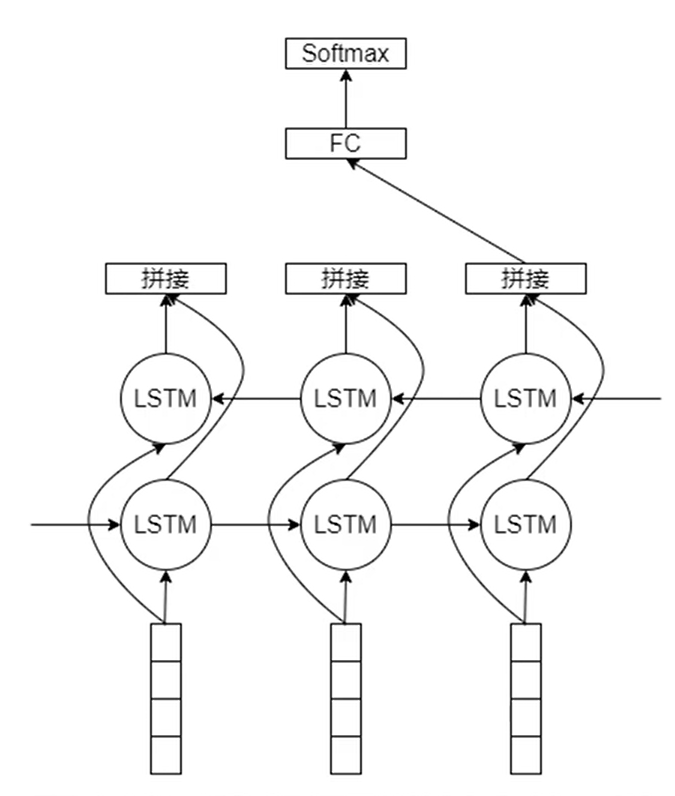
这里以双向LSTM为例,两层的LSTM输入的数据是一样的,两层对应时间步的特征进行拼接。
三、序列标注
对每一个输入xix_ixi都有对应的标签yiy_iyi
- 中文分词
Chinese Word Segmentation:指的是将一个汉字序列切分成一个个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。

B表示一个新词,I表示延续前面的词。 - 词性标注
Part-Of-Speech tagging,POS tagging:是指为句子的分词结果中的每个单词标注一个正确的词性的程序,也即确定每个词是名词、动词、形容词或者其他词性的过程。词性标注是很多NLP任务的预处理步骤,如句法分析、信息抽取,经过词性标注后的文本会带来很大的便利性,但不是不可或缺的步骤。
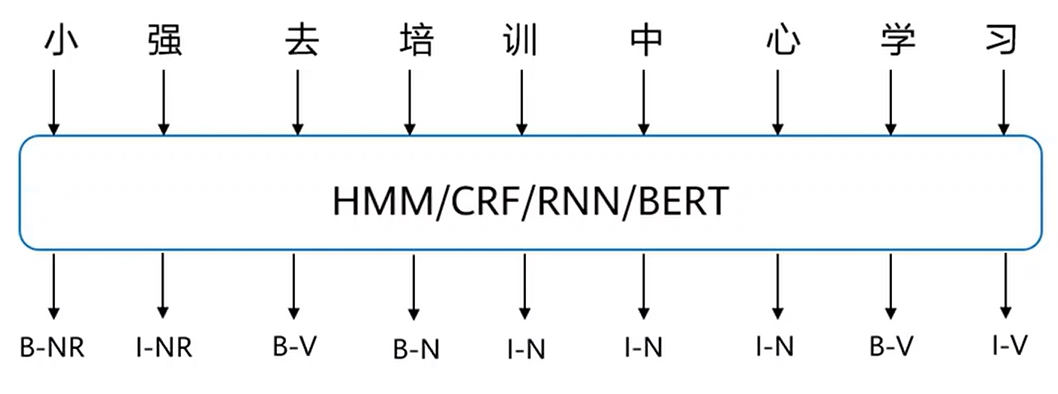
N表示名词,V表示动词。 - 命名实体识别
命名实体识别(Named Entity Recognition,NER)为自然语言处理(NLP)的基础任务之一,其目标是提取文本中的命名实体并对这些实体进行分类,比如人名、地名、机构时间、货币和百分比等。
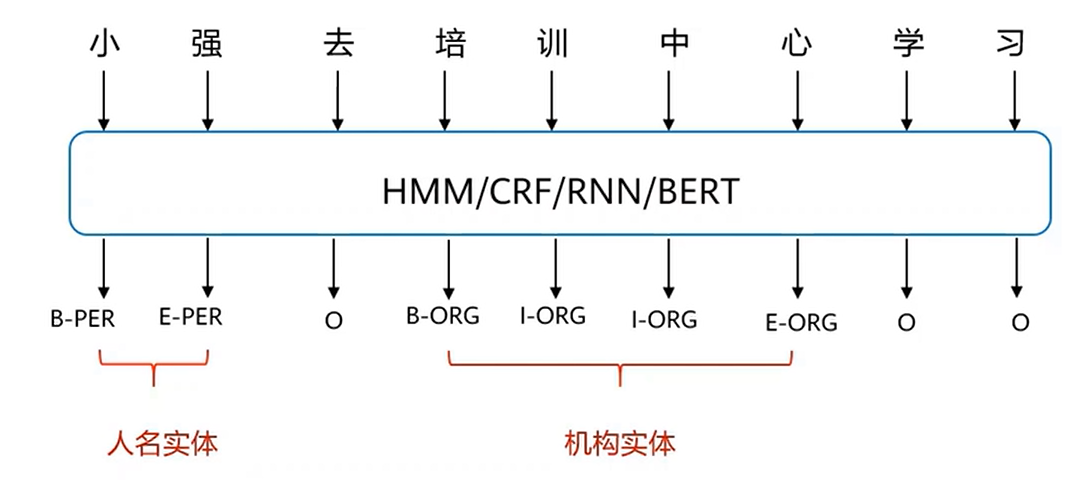
B表示感兴趣实体的开始,E表示感兴趣实体的结束,I表示B与E之间,O表示不感兴趣的。
1 CRF
条件随机场(Conditional Random Field,CRF),取消了隐马尔科夫模型(HiddenMarkov Model,HMM)的两个独立假设,把标签转移和上下文输入都当做全局特征之一,再全局进行概率归一化,解决了HMM的标签偏置和上下文特征缺失问题。
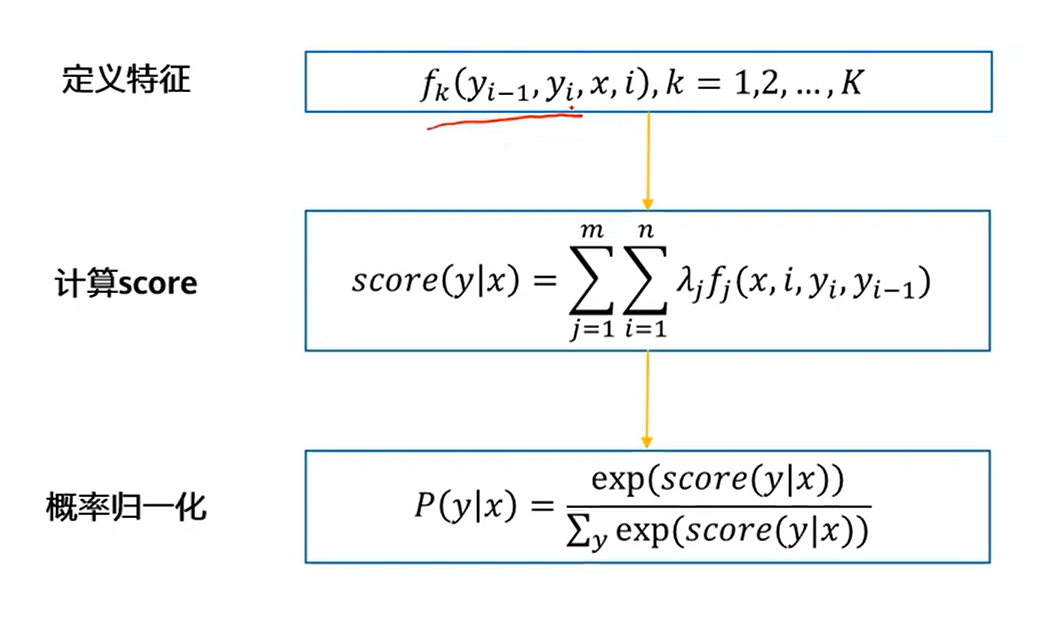
特征函数f的输入,x是序列标注中的文本,y为序列标注结果的标签,这里y取了连续的两个位置。x是整个文本,因此解决了全局特征的缺失问题。
计算score时,λ为模型的训练参数,然后两层循环,分别遍历文本的位置,以及遍历不同的特征类型。
最后进行概率归一化,将所有可能得y序列的情况加起来作为分母,找出最大概率的y序列。
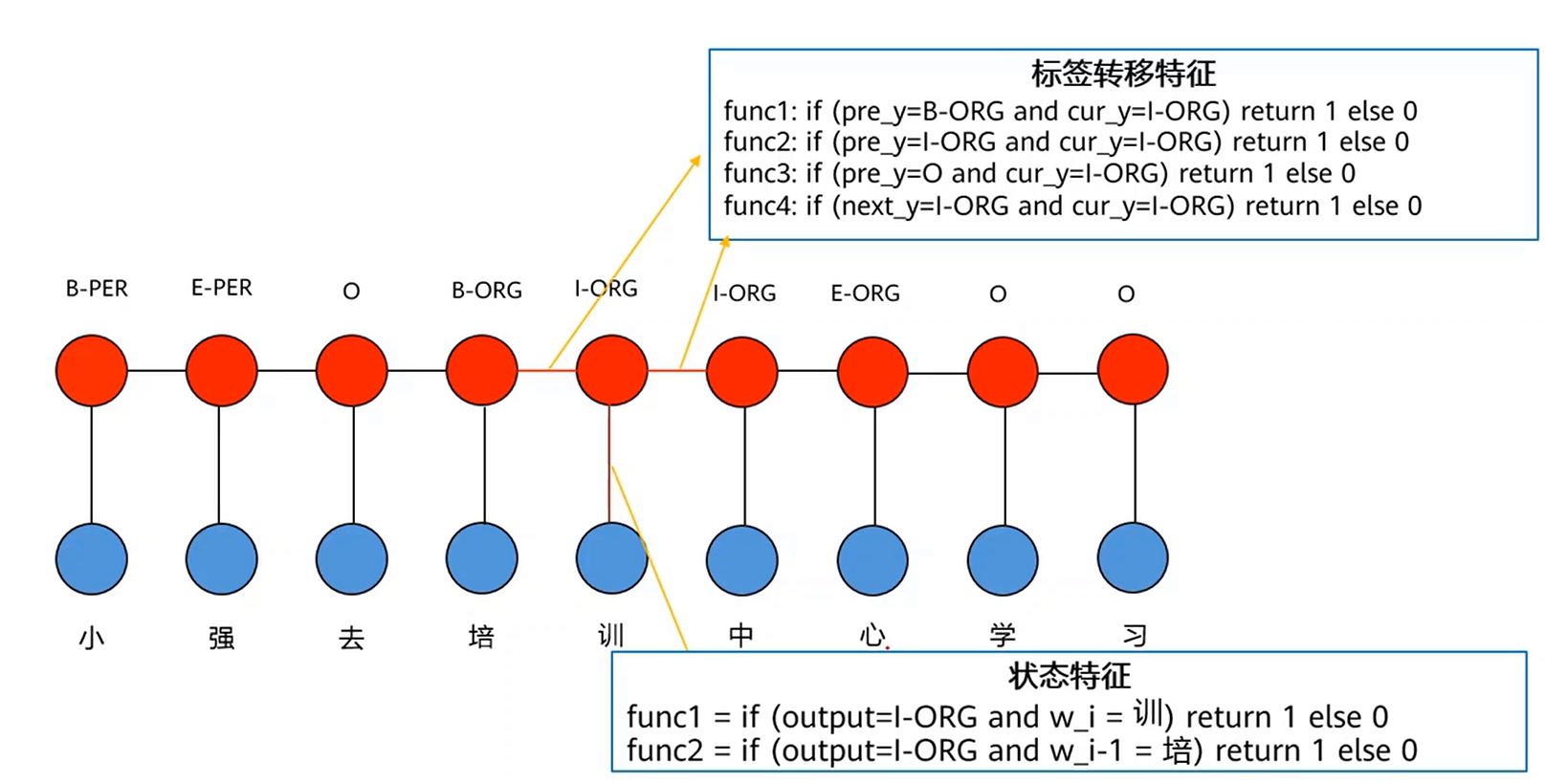
特征函数分为,
标签转移特征:强调前后标签之间的关系。
状态特征:强调特定输入输出时应该给多少分数。
2 BiLSTM+CRF
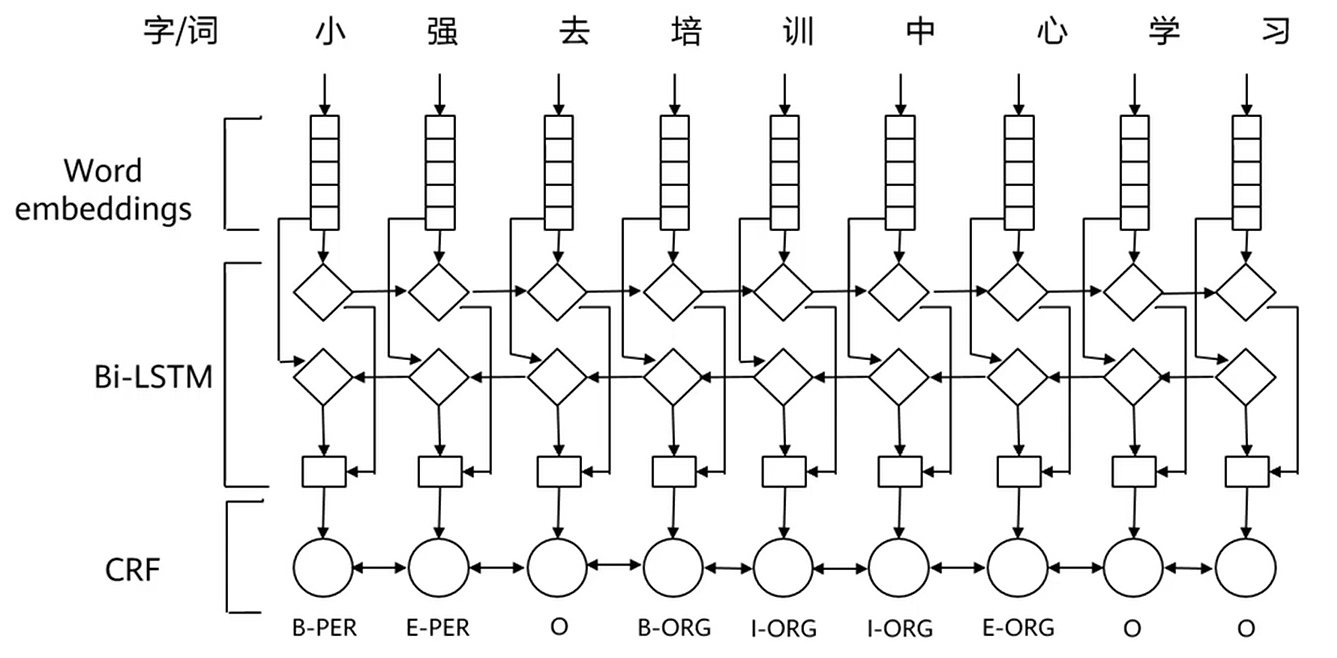
BiLSTM输出得到分数后通过CRF可以增强标签之间的状态转移的信息。
四、语言模型和文本生成
语言模型就是给定一个词序列来预测最有可能的下一个词是什么。给定词序列w1,w2,...,wi−1w_1,w_2,...,w_{i-1}w1,w2,...,wi−1,计算下一个词wiw_iwi的概率分布:
P(wi∣w1,w2,...,wi−1) P(w_i|w_1,w_2,...,w_{i-1}) P(wi∣w1,w2,...,wi−1)
1. N-Gram语言模型
利用n元模型(n-gram model)估算条件概率,即忽略距离大于等于n的上文词的影响,因此若用频数计数的比例来计算n元条件概率可表示为:
P(wi∣w1,w2,...,wi−1)≈P(wi∣wi−(n−1),wi−(n−2),...,wi−1)=count(wi−(n−1),wi−(n−2),...,wi−1,wi)count(wi−(n−1),wi−(n−2),...,wi−1) P(w_i|w_1,w_2,...,w_{i-1}) \approx P(w_i|w_{i-(n-1)},w_{i-(n-2)},...,w_{i-1}) \\=\frac{count(w_{i-(n-1)},w_{i-(n-2)},...,w_{i-1},w_i)}{count(w_{i-(n-1)},w_{i-(n-2)},...,w_{i-1})} P(wi∣w1,w2,...,wi−1)≈P(wi∣wi−(n−1),wi−(n−2),...,wi−1)=count(wi−(n−1),wi−(n−2),...,wi−1)count(wi−(n−1),wi−(n−2),...,wi−1,wi)
当n=1时称为一元模型,n等于2时称为二元模型。
2. 固定窗口神经网络语言模型
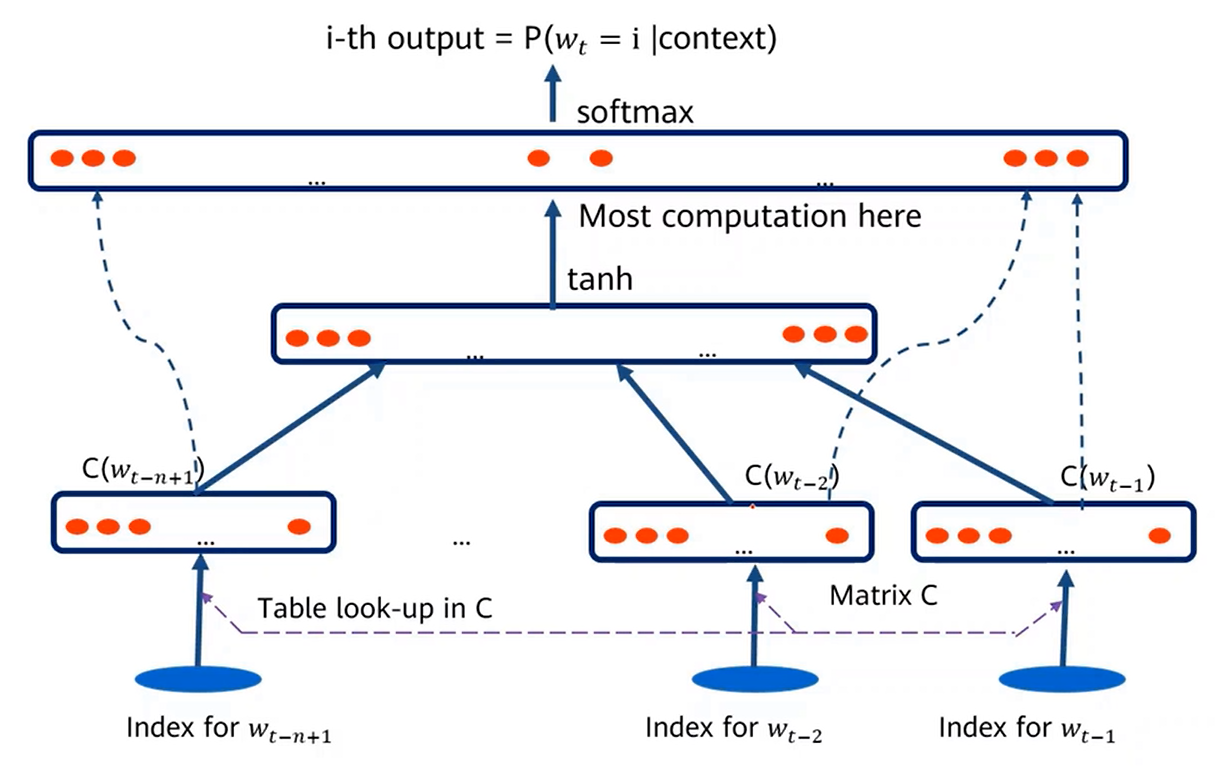
对于窗口内的不同词,先转成词向量,然后首尾拼接在一起输入隐藏层,这个输出再与所有输入词向量一起通过softmax得到预测概率。
3. RNN语言模型
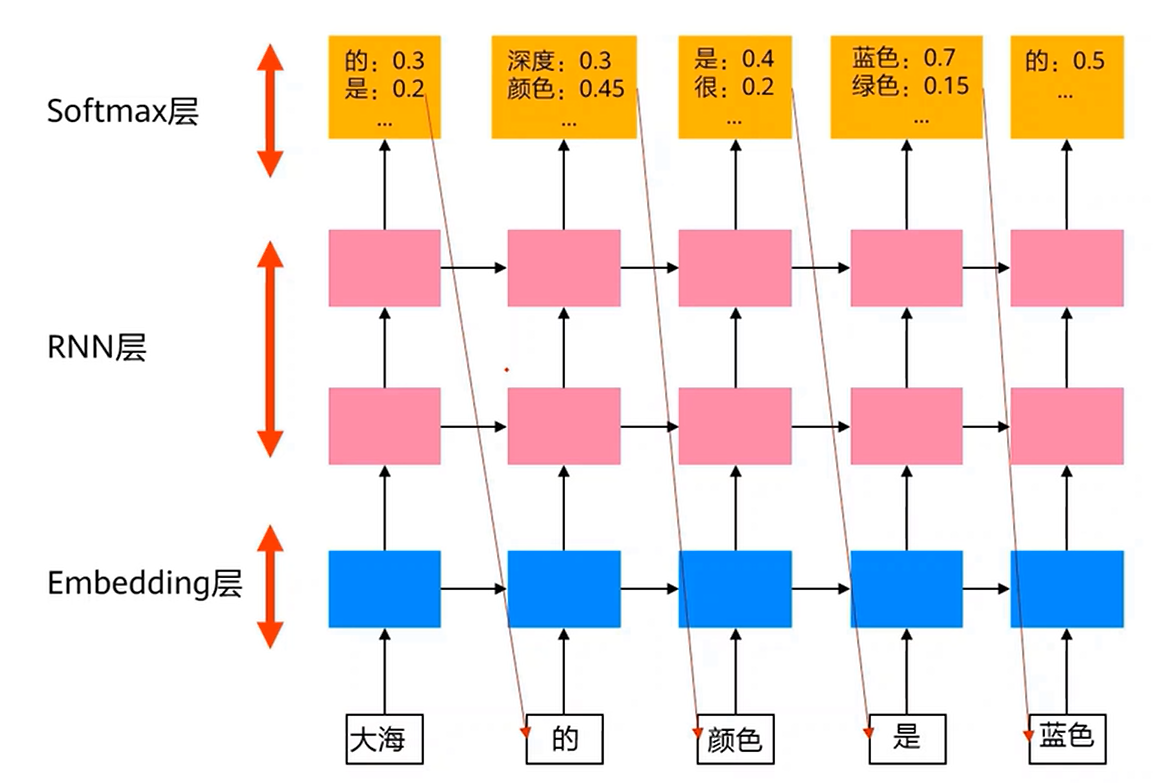
这里要使用单向RNN,因为双向会让模型看到要预测的词。这里下一个词刚好是当前词的输出概率应该最大的标签。
语言模型生成词向量
可以让词向量由静态转为动态,即包含多种含义而不是局限于一种意思。
1. ELMo-Embeddings from Language Model
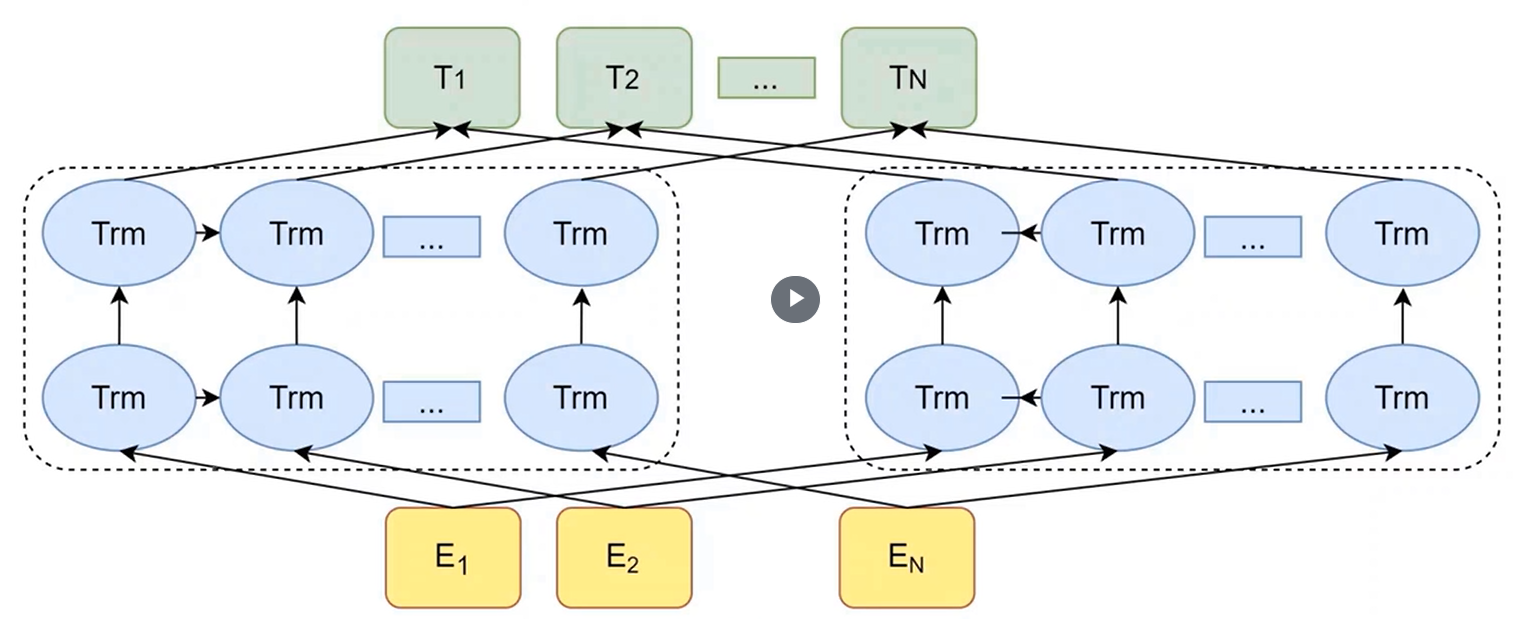
由两个双向LSTM组成,但每个当中还是使用同一个方向进行,保证语言预测的先后逻辑。
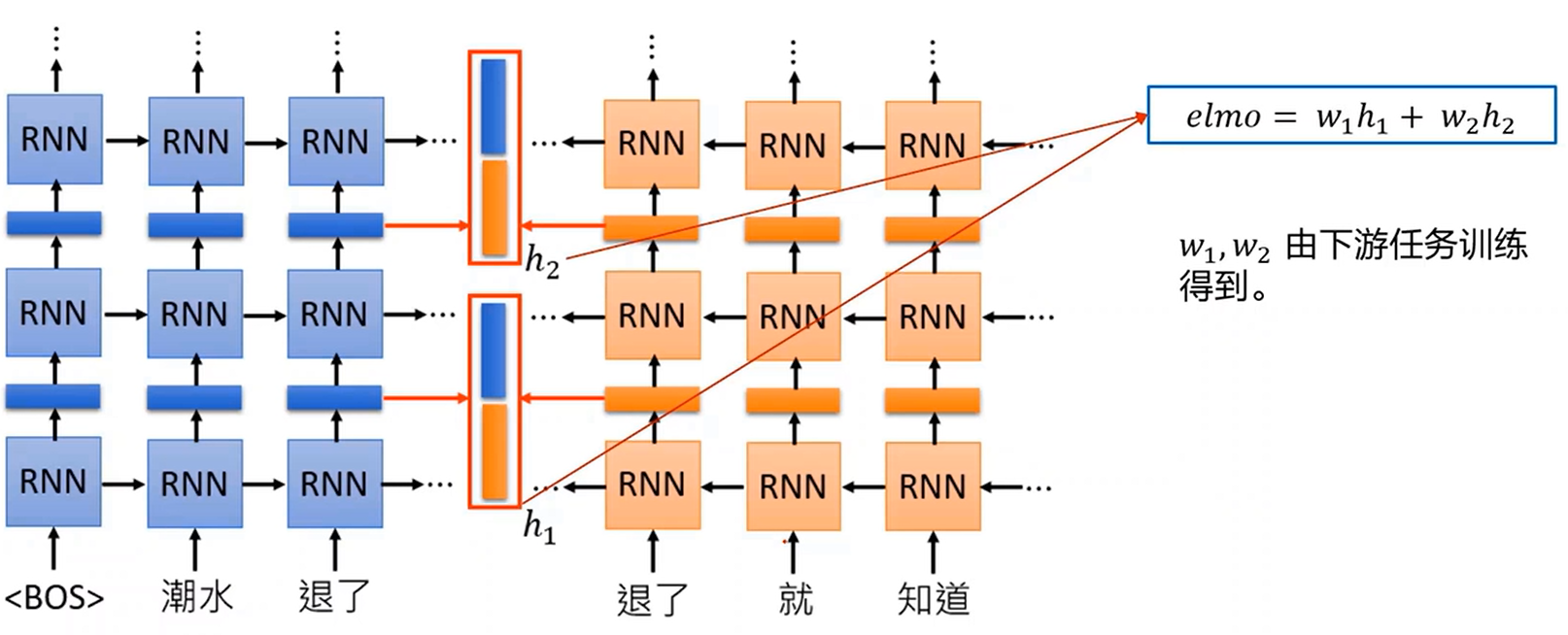
两边分别从两个方向读句子,两层结构,第一层 LSTM(h₁)侧重句法特征(比如词性、语法),第二层 LSTM(h₂)侧重语义特征(比如词义、上下文)。
对句子中的每个词(比如图中的 "退了"),提取双向 LSTM 各层的隐状态,左右拼接。
最终的词向量通过两个可训练的权重系数加权得到。
2. Bert
将多个Transformer Encoder堆叠起来。
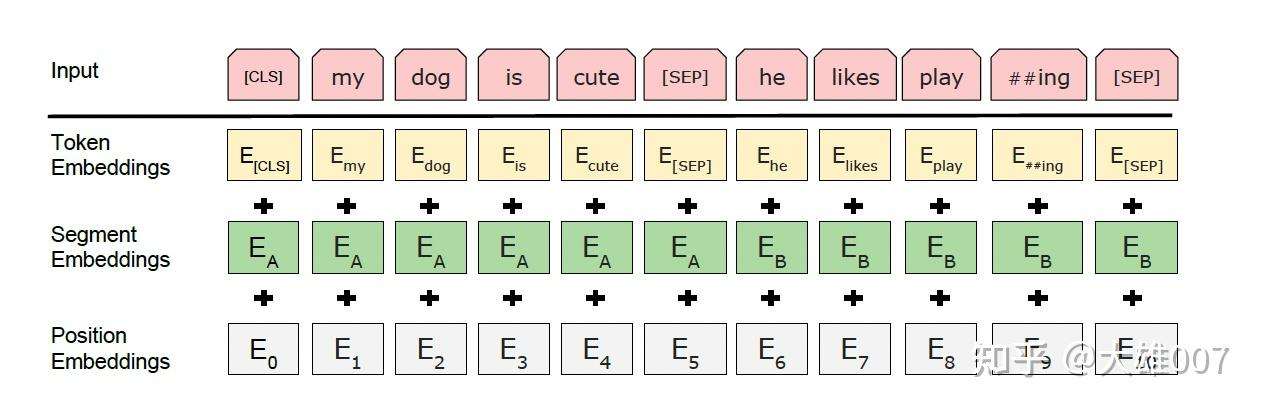
其Embedding是将三种Embedding加起来。
Token Embeddings是词向量,第一个单词是CLS标志(最后一层该位对应向量可以作为整句话的语义表示),模型输入为字向量表的一维向量,Token Embeddings 层会将每个词转换成 768 维向量。
Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务,即要判断出两个句子是否有关联。
Position Embeddings用来表示句子中词的位置对语义的影响。
五、序列到序列
序列到序列(Sequence-to-sequence,简称Seq2Seq )是一种由双向 RNN组成的encoder-decoder神经网络结构,从而满足输入输出序列长度不相同的情况,实现一个序列到另一个序列之间的转换。
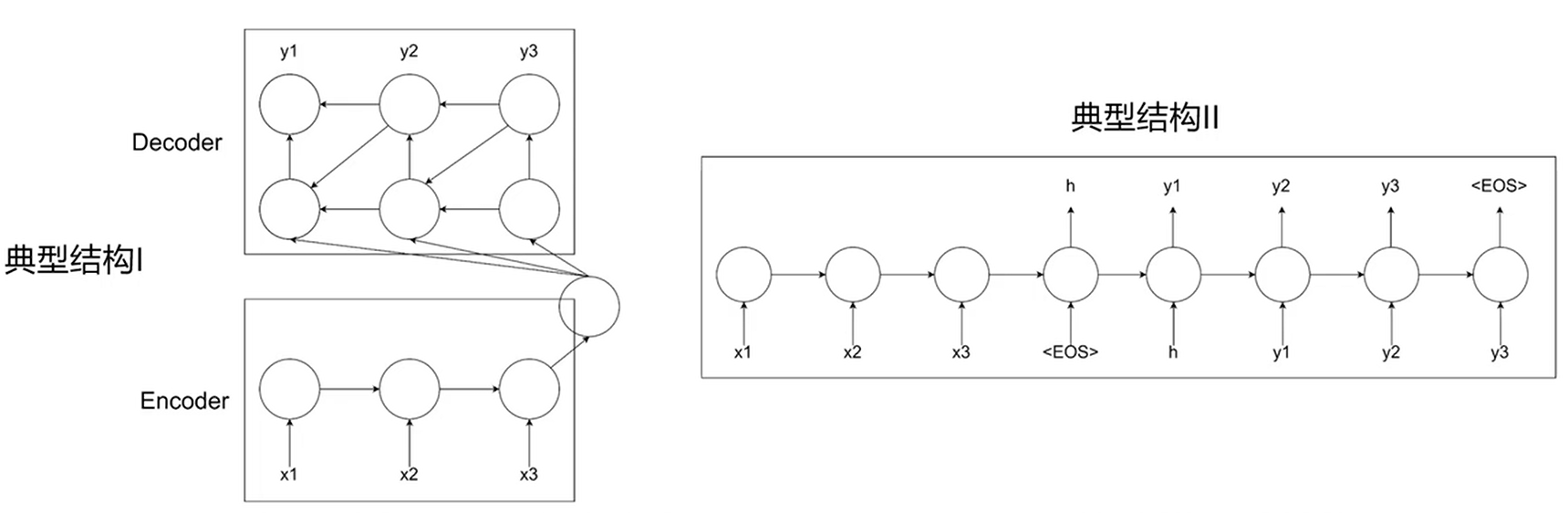
Encoder提取,Decoder生成。典型结构1的Encoder提取的信息应用与Decoder的每一个位置,典型结构2只作用于第一个位置。
缺点:所有输入的信息都经由最后一个输入对应的隐层向量传递给解码器,在遇到较长的上下文输入时,特征的表达能力有限。