一、导读
视频超分辨率(Video Super-Resolution, VSR)的目标是从低分辨率视频中恢复出高分辨率画面,广泛应用于监控、高清电视等领域。
传统方法在处理快速运动或复杂细节时,往往难以有效利用时间信息,导致重建质量不佳。事件相机(Event Camera)能捕捉像素级的亮度变化,提供高频运动信息,但如何将其与普通视频帧有效融合仍是一个挑战。
本文提出了一种名为 MamEVSR 的新型网络,它首次将状态空间模型(State Space Model)引入事件视频超分辨率任务。该模型通过两个核心模块------iMamba 和 cMamba,分别处理帧间特征融合和跨模态信息交互,在保持线性计算复杂度的同时,显著提升了重建质量。
二、论文基本信息

-
论文标题:Event-based Video Super-Resolution via State Space Models
-
作者:Zeyu Xiao, Xinchao Wang
-
单位:National University of Singapore
-
会议/来源:CVPR 2025
三、主要贡献与创新
-
首次将选择性状态空间模型(Mamba)应用于事件视频超分辨率任务。
-
提出 iMamba 模块,实现双向帧间特征融合,保持线性复杂度。
-
提出 cMamba 模块,有效融合事件与图像模态,提升细节重建能力。
-
在多个数据集上取得最优性能,验证了方法的有效性与高效性。
四、研究方法与原理
MamEVSR 的核心思路是:利用状态空间模型(SSM)处理视频帧与事件数据,实现高效的双向特征融合与跨模态信息交互,从而提升超分辨率重建质量。
-
状态空间模型回顾状态空间模型用于建模序列数据,其连续时间系统表示为:
其中 是输入, 是隐藏状态, 是输出。通过零阶保持离散化,得到离散形式:
进一步简化后,隐藏状态更新为:
-
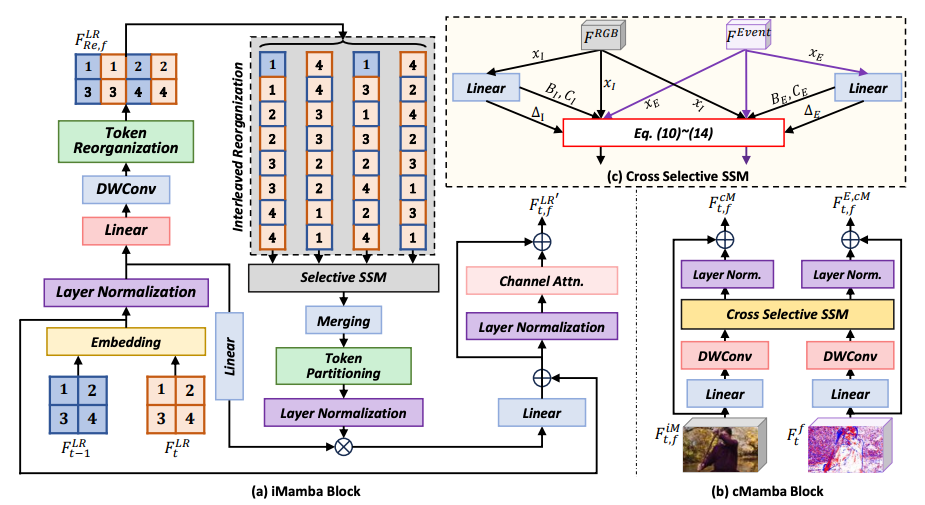
iMamba 模块该模块将相邻两帧的特征拼接为一个序列,通过交错重组(interleaved reorganization)和多向选择性扫描(selective scan)实现帧间信息融合。结构上类似 Transformer,但用 SSM 替换注意力机制,并用通道注意力(channel attention)替代 MLP,增强局部建模能力。
-
cMamba 模块该模块用于融合图像特征 和事件特征 。通过交叉选择性状态空间建模(Cross Selective SSM),实现跨模态信息交互:
其中 和 为跨模态矩阵,用于从隐藏状态中解码输出。
五、实验设计与结果分析
-
实验设置使用 REDS 和 CED 数据集进行训练与测试。事件数据通过 ESIM 模拟生成,并转换为体素网格(voxel grid)。评估指标为 PSNR 和 SSIM,训练时使用 Charbonnier 损失函数。
-
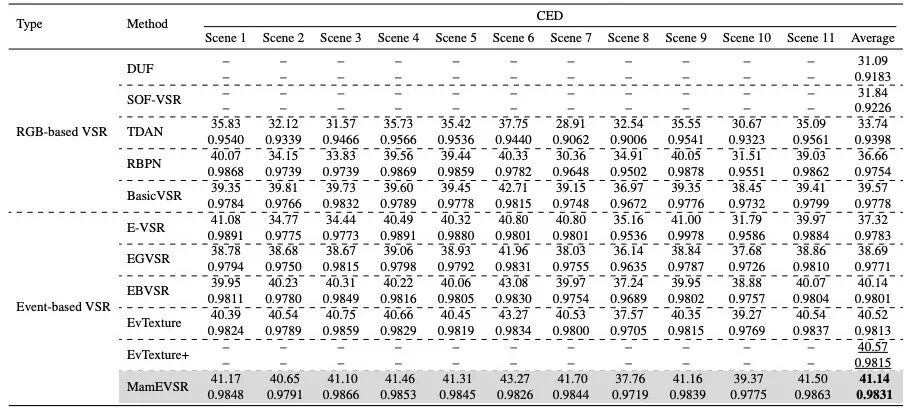
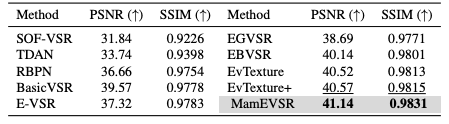
对比实验在 CED 数据集上(见表1、表3),MamEVSR 在 任务中取得 PSNR 41.14 dB 和 SSIM 0.9831,优于所有对比方法。在 REDS4 数据集上(见表2),MamEVSR 在 任务中也取得最优表现。
- 可视化对比图5和图6展示了 MamEVSR 在细节恢复(如车轮纹理、车牌)上优于其他方法,重建结果更接近真实图像。

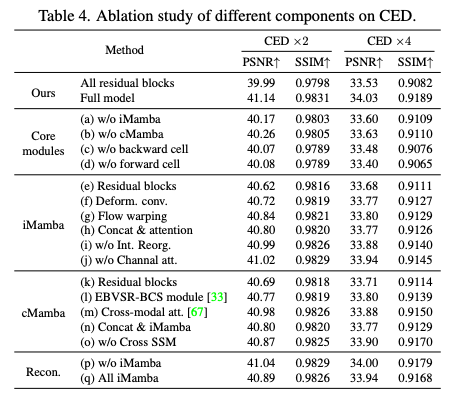
- 消融实验表4展示了各模块的贡献。移除 iMamba 或 cMamba 模块均导致性能下降,说明两者对模型性能至关重要。双向结构也显著提升了重建质量。
六、论文结论与评价
总结
MamEVSR 通过引入状态空间模型,有效融合事件与图像信息,在多个数据集上实现了最优的视频超分辨率重建效果,同时保持了线性计算复杂度。
评价
该方法在理论和实验上均表现出色,为事件视频超分辨率任务提供了新思路。其优点在于全局感受野 和高效计算,缺点是在处理极细纹理时仍有局限。未来可考虑引入更强的感知损失(如 VGG Loss)或更长的时序信息,以进一步提升纹理恢复能力。