博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
- 技术栈:后端(Python+Django+django-simpleui+MySQL)、前端(Node.js+Vue3+Element Plus+Element Plus Admin+Tailwind CSS+Vite+TypeScript)、数据爬虫(Python+Scrapy+requests+XPath)、推荐算法(协同过滤)
- 核心功能:智能商品推荐(协同过滤驱动)、完整购物流程(商品检索-详情查看-购物车-订单管理)、用户中心(信息修改/历史订单)、后台数据管理(商品/用户数据维护)、电商数据采集(Scrapy爬虫支撑)
- 研究背景:电商平台商品海量增长,用户面临"找货难"痛点------传统浏览筛选效率低,缺乏贴合个人偏好的精准推荐;同时平台需通过个性化服务提升用户留存与转化率,协同过滤算法因"基于用户行为、推荐精度高"成为核心解决方案。
- 研究意义:技术层面,实现前后端分离(Django+Vue3)与爬虫、推荐算法的深度整合,构建完整电商推荐链路;应用层面,为用户提供"精准推荐+便捷购物"体验,为平台提升商业价值;学习层面,适合作为全栈+推荐算法方向毕业设计,覆盖企业级技术栈与业务场景。
2、项目界面
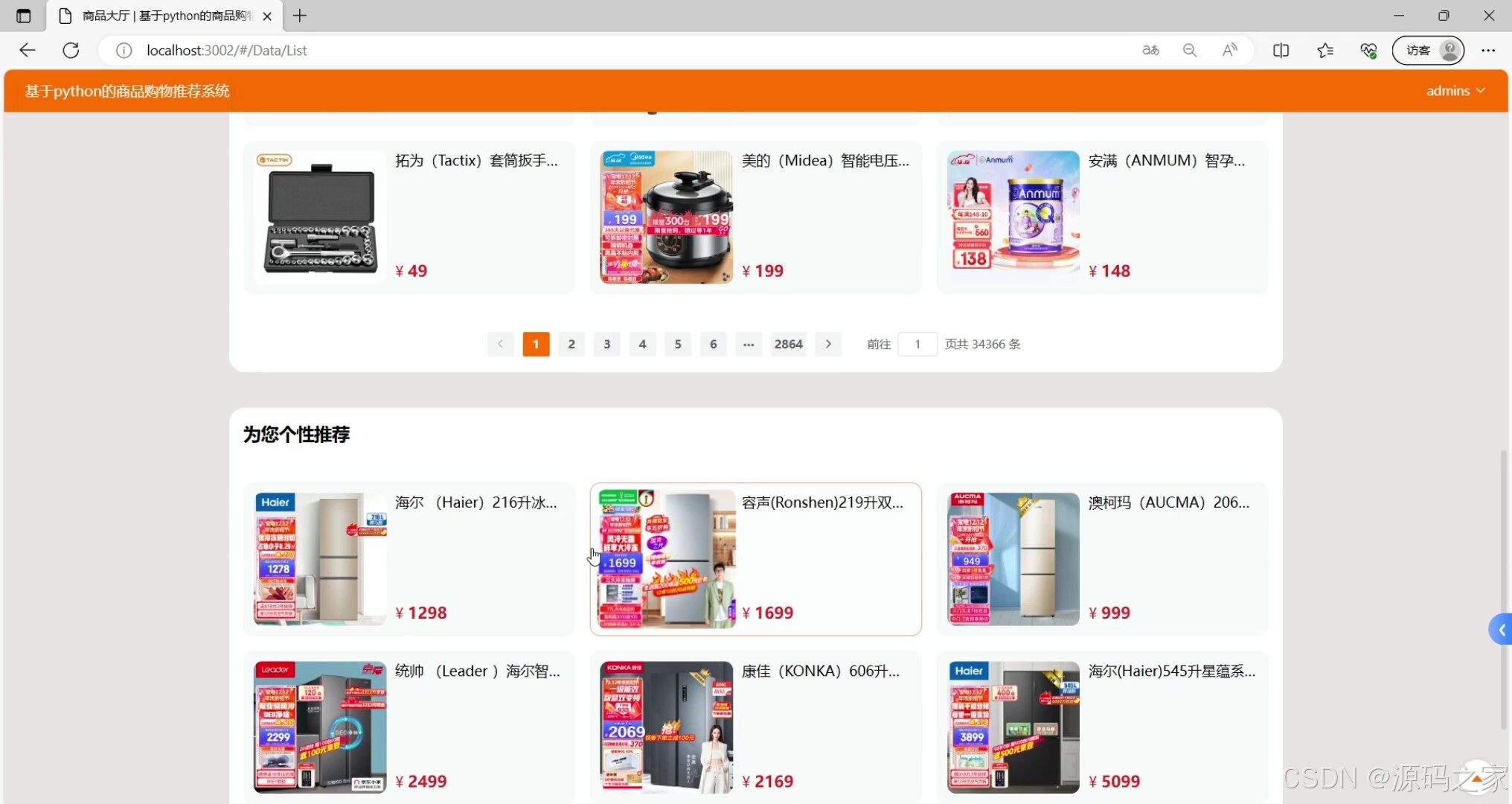
- 系统首页(功能导航、热门商品展示、个性化推荐入口)
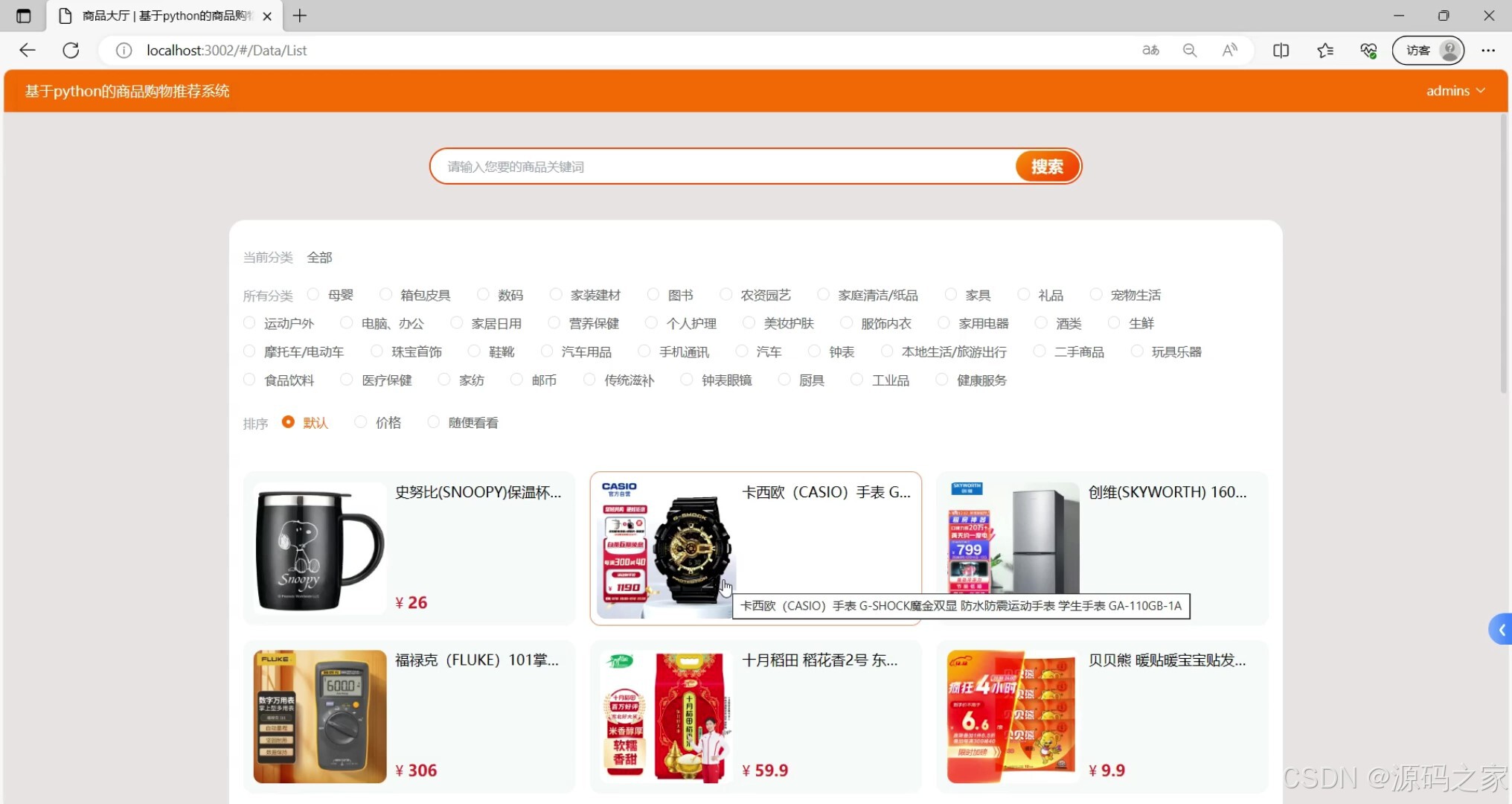
- 商品详情页(商品参数、图文介绍、用户评价、推荐商品列表)
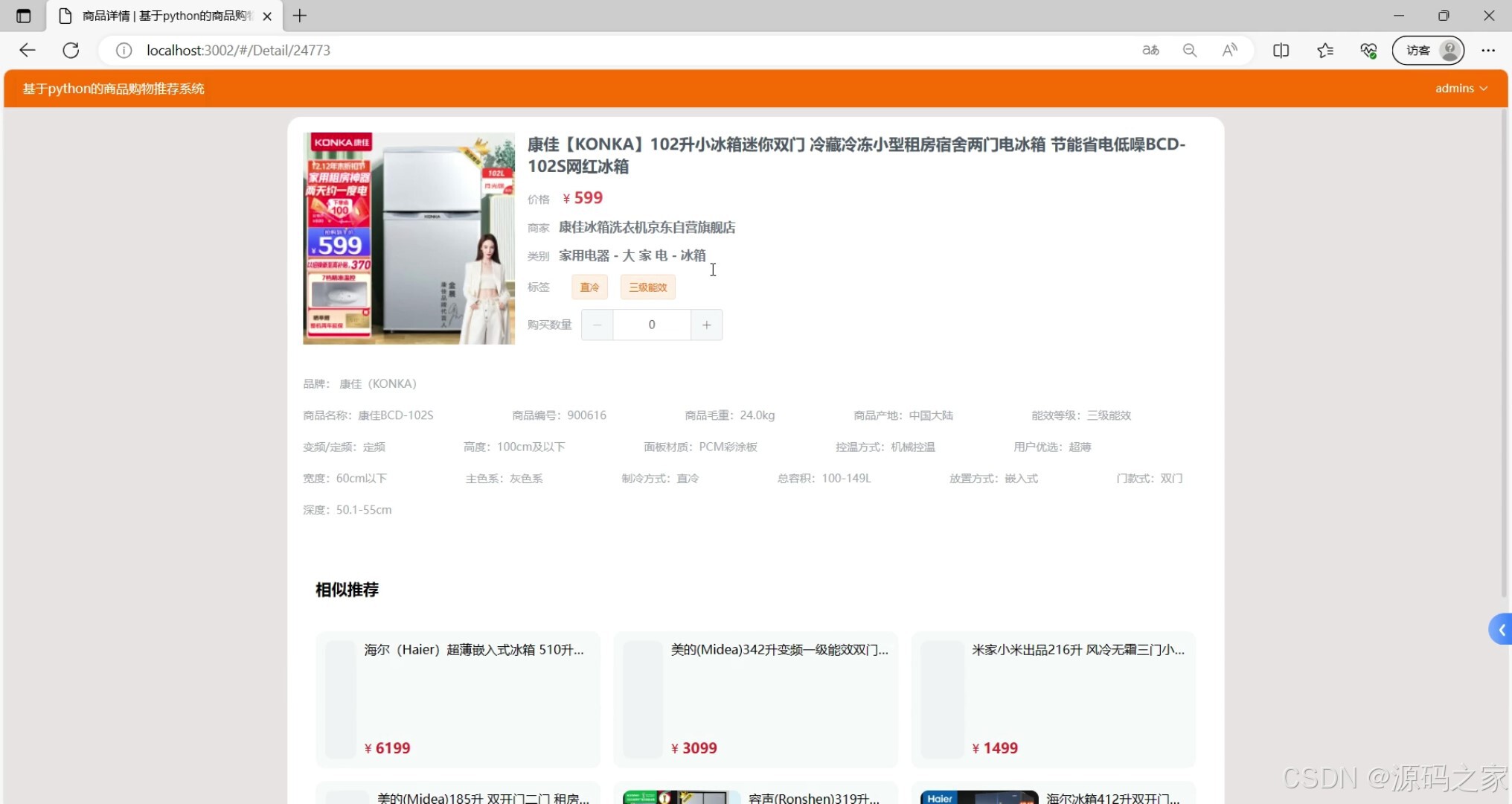
- 购物车功能(已选商品列表、数量调整、价格计算、结算入口)
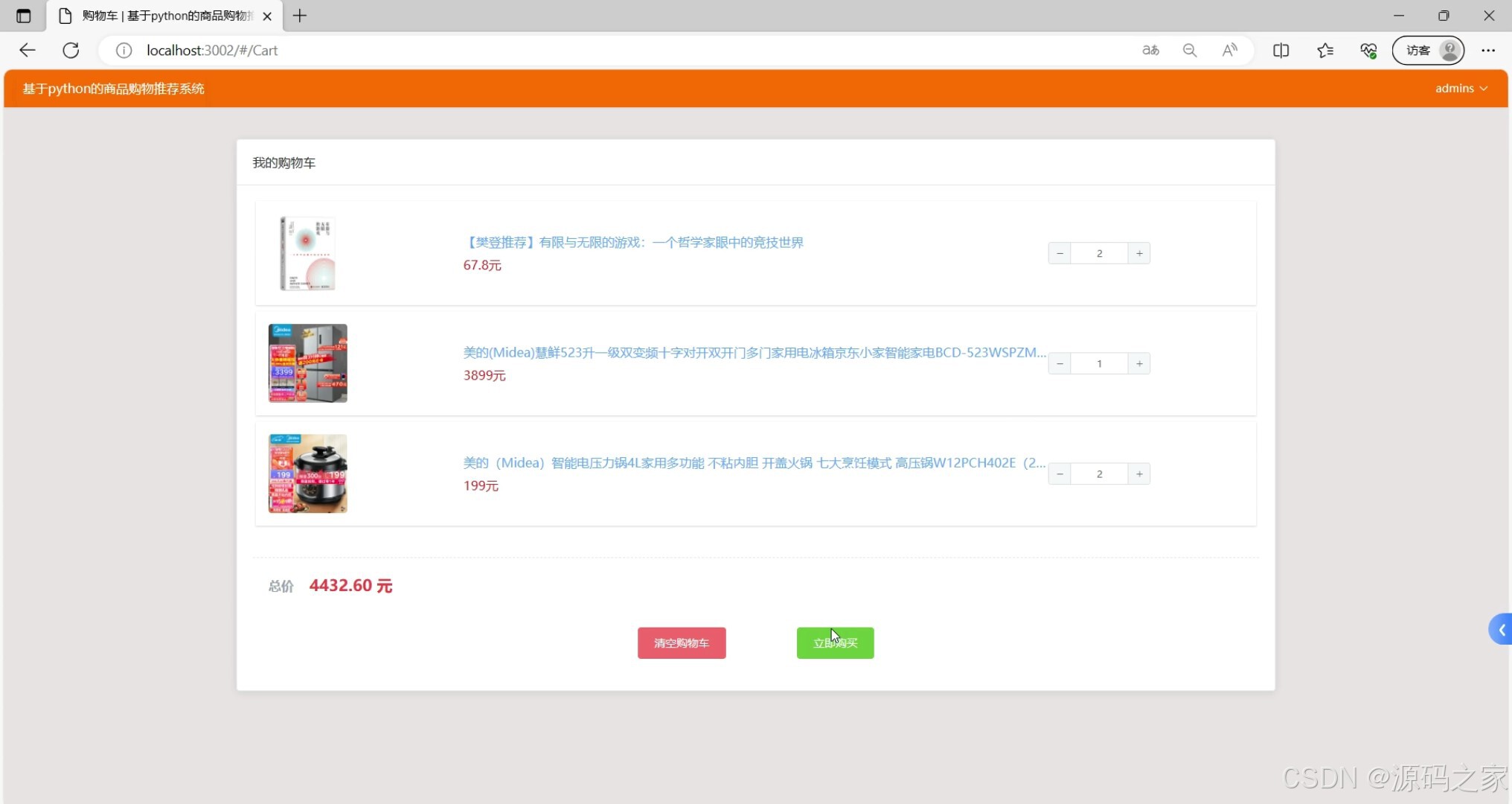
- 推荐模块(基于协同过滤的"为你推荐"商品列表,含匹配度标注)
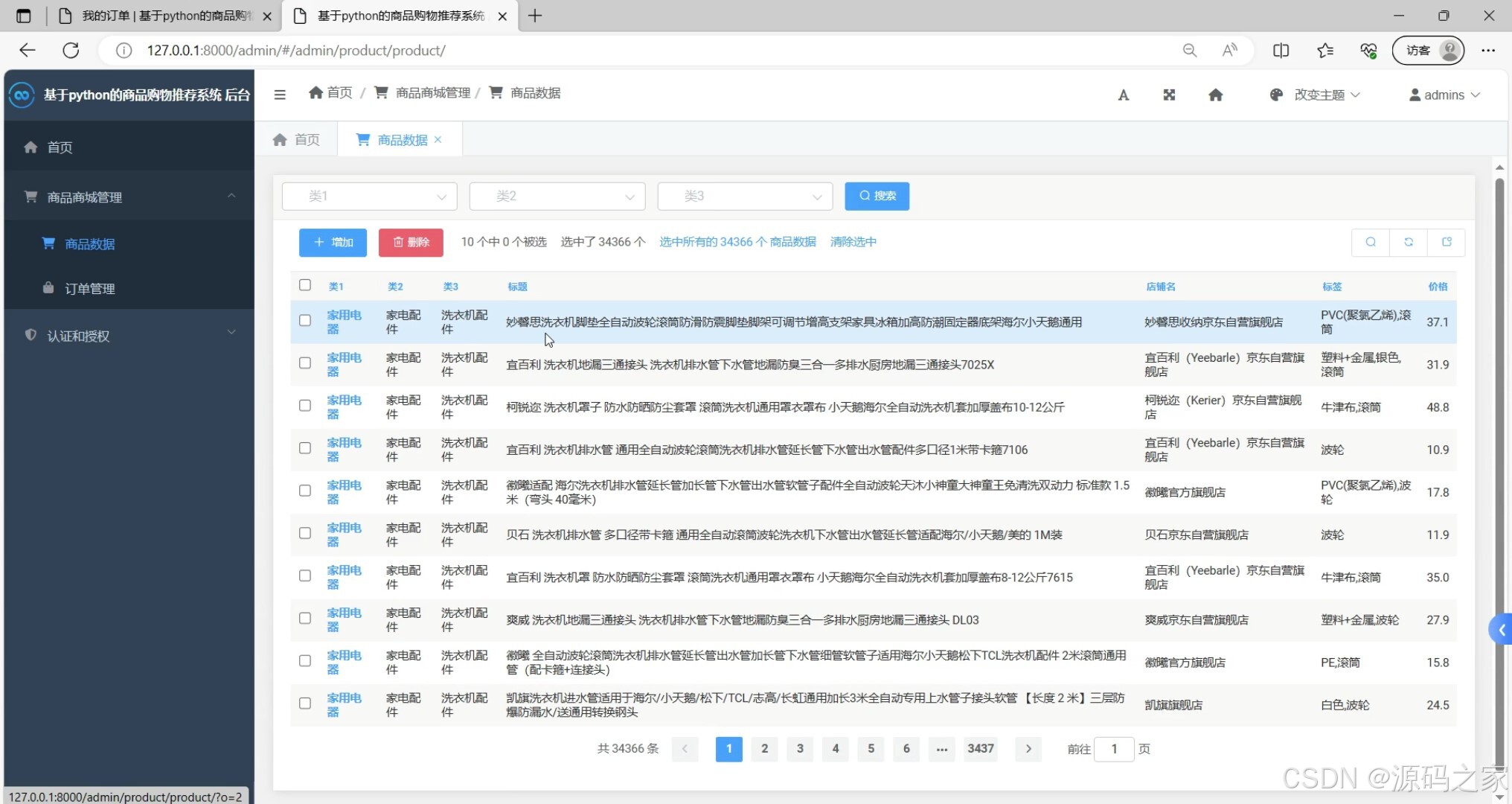
- 后台数据管理(商品信息维护、用户管理、订单查询、数据统计界面)
6.注册登录
3、项目说明
在电商行业竞争白热化的背景下,"精准推荐"与"便捷购物"成为用户核心需求,传统电商平台因推荐同质化、操作流程繁琐难以满足需求。本项目设计并实现基于协同过滤的智能推荐购物平台,通过全栈技术整合与算法应用解决上述痛点。系统采用前后端分离架构:后端以Python+Django为核心,搭建稳定的业务逻辑层,通过django-simpleui快速构建后台管理界面,MySQL数据库存储商品、用户、订单等核心数据;前端基于Vue3生态,结合Element Plus组件库、Tailwind CSS与Vite打包工具,打造响应式购物界面,TypeScript保障代码可维护性。数据支撑层面,通过Scrapy爬虫框架与requests工具,配合XPath页面解析,定向采集电商平台商品数据(如参数、价格、评价),经清洗后补充至数据库,为推荐算法与商品展示提供丰富素材。核心推荐功能依托协同过滤算法实现:系统收集用户浏览、购买、评价等行为数据,计算用户间偏好相似度(如余弦相似度),筛选相似用户群体的高兴趣商品,同时结合商品关联度分析,为用户生成个性化推荐列表,有效提升推荐精准度与用户点击转化。业务流程上,系统覆盖完整电商场景:用户通过首页检索或推荐模块发现商品,进入详情页了解信息后加入购物车,结算生成订单,个人中心可查看历史订单与修改信息;管理员通过后台管理商品上下架、维护用户权限、统计销售数据,保障平台稳定运行。整体而言,该平台实现了"数据采集-精准推荐-购物转化-后台管理"的闭环,既提升用户购物效率与满意度,也为电商运营提供数据驱动的决策支持,同时其企业级技术栈配置使其成为全栈开发与推荐算法方向的优质实践项目,兼具实用价值与学习意义。
4、核心代码
python
from .models import *
import json
from django.http.response import HttpResponse
from django.shortcuts import render
from django.http import JsonResponse
from datetime import datetime, time
from django.core.paginator import Paginator
from django.db.models import Q
import simplejson
from collections import Counter
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts.charts import Map, Grid, Bar, Line, Pie, TreeMap, WordCloud
from pyecharts.faker import Faker
from pyecharts.commons.utils import JsCode
from pyecharts.options.charts_options import MapItem
from django.db.models import Q, Count, Avg, Min, Max
from pyecharts.globals import SymbolType
from .recommend import collaborative_filtering_recommend
def to_dict(l, exclude=tuple()):
# 将数据库模型 变为 字典数据 的工具类函数
def transform(v):
if isinstance(v, datetime):
return v.strftime("%Y-%m-%d %H:%M:%S")
return v
def _todict(obj):
j = {
k: transform(v)
for k, v in obj.__dict__.items()
if not k.startswith("_") and k not in exclude
}
return j
return [_todict(i) for i in l]
def get_list(request):
# 商品列表
body = request.json
pagesize = body.get("pagesize", 10)
page = body.get("page", 1)
orderby = body.get("orderby", "-id")
notin = ["pagesize", "page", "total", "cateName", "orderby", "id__ne"]
query = {
k: v for k, v in body.items() if k not in notin and (v != "" and v is not None)
}
q = Q(**query)
objs = Product.objects.filter(q).order_by(orderby)
if body.get("id__ne"):
objs = objs.exclude(id=body["id__ne"])
breadcrumb = []
for i in range(1, 4):
cat = query.get(f"cat{i}")
if cat:
breadcrumb.append(cat)
cateNames = []
if not query.get("cat1"):
cateNames = [
i[0] for i in Product.objects.filter(q).values_list("cat1").distinct()
]
elif not query.get("cat2"):
cateNames = [
i[0] for i in Product.objects.filter(q).values_list("cat2").distinct()
]
elif not query.get("cat3"):
cateNames = [
i[0] for i in Product.objects.filter(q).values_list("cat3").distinct()
]
paginator = Paginator(objs, pagesize)
pg = paginator.page(page)
result = to_dict(pg.object_list)
return JsonResponse(
{
"total": paginator.count,
"result": result,
"cateNames": cateNames,
"breadcrumb": breadcrumb,
}
)
def get_detail(request):
# 商品详情
body = request.json
id = body.get("id")
o = Product.objects.get(pk=id)
his = (
ProductHistory.objects.filter(userId=request.user.id)
.order_by("-createTime")
.first()
)
if not (his and his.productId == o.id):
ProductHistory(userId=request.user.id, productId=o.id).save()
return JsonResponse(to_dict([o])[0])
def history_recommand(request):
topK = 9
try:
produces = collaborative_filtering_recommend(request.user.id, topK)
except:
productIds = (
ProductHistory.objects.filter(userId=request.user.id)
.values_list("productId")
.order_by("-id")
.distinct()
)[:5]
produces = []
# 根据历史查看记录推荐
if productIds:
productIds = [i[0] for i in productIds]
cates = [
i[0]
for i in Product.objects.filter(id__in=productIds).values_list("cat3")
]
most_common_cates = list(dict(Counter(cates).most_common(2)).keys())
produces = Product.objects.filter(cat3__in=most_common_cates).order_by("?")[
:topK
]
# 没有记录则随机推荐
else:
produces = Product.objects.order_by("?")[:topK]
return JsonResponse(to_dict(produces), safe=False)
def make_order(request):
# 新增订单
data = request.json
o = Order.objects.create(
userId=request.user.id,
name=data.get("name"),
phone=data.get("phone"),
address=data.get("address"),
remark=data.get("remark"),
price=float(data.get("price")),
total=int(data.get("total")),
products=json.loads(data.get("products")),
)
return JsonResponse({"ok": o.id})
def order_list(request):
# 订单列表
data = request.json
not_q = ("total", "page", "pagesize", "orderby")
pagesize = data.get("pagesize", 12)
page = data.get("page", 1)
orderby = data.get("orderby", "-id")
params = {k: v for k, v in data.items() if k not in not_q and v}
params_q = Q(userId=request.user.id)
for item in params.items():
params_q &= Q(**dict([item]))
objs = Order.objects.filter(params_q).order_by(orderby).all()
pg = Paginator(objs, pagesize)
page = pg.page(page)
object_list = page.object_list
for i in object_list:
products = eval(i.products)
i.products = eval(i.products)
# 取出订单包括的所有商品
i.product_list = to_dict(Product.objects.filter(id__in=list(products.keys())))
return JsonResponse({"total": pg.count, "result": to_dict(object_list)})🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻