2025 年 NeurIPS 人工智能大会(加利福尼亚州圣地亚哥举办)上,英伟达发布的 Alpamayo-R1 模型,被业内称为 "自动驾驶领域首个视觉语言动作模型"。这款开源工具的核心目标,正是解决自动驾驶长期面临的 "常识判断" 难题 ------ 而这一切技术落地,都离不开 GPU 服务器的算力支撑。

一、Alpamayo-R1:给自动驾驶装 "会推理的大脑"
作为英伟达 Cosmos 模型系列的进阶产物(基于 2025 年 1 月发布的 Cosmos-Reason 推理模型构建,同年 8 月推出扩展版本),Alpamayo-R1 的核心优势集中在 "感知 - 决策" 的逻辑闭环:
- 双模态信息处理能力:区别于传统仅能识别图像的模型,它可同时解析 "视觉信号"(如行人、障碍物)与 "文本信息"(如交通标识、施工牌文字),让车辆不仅 "看见",更能 "读懂" 环境 ------ 比如看到 "学校区域" 标识时,自动关联 "减速慢行" 的驾驶规则。
- 因果推理式决策:依托 Cosmos-Reason 模型的逻辑推演能力,它能避免 "机械反应"。例如面对 "路口行人驻足观望",会先推演 "行人是否准备横穿→当前车速能否安全避让→是否需要打转向灯提示后车",而非直接急刹,这正是 L4 级自动驾驶(特定区域、限定条件下完全自动驾驶)的关键技术需求。
- 开源生态降低研发门槛:模型已在 GitHub、Hugging Face 双平台开源,同时配套发布 "Cosmos Cookbook" 开发资源包 ------ 包含数据整理指南、合成数据生成工具、模型评估流程等,让中小团队也能基于标准化流程开展研发。
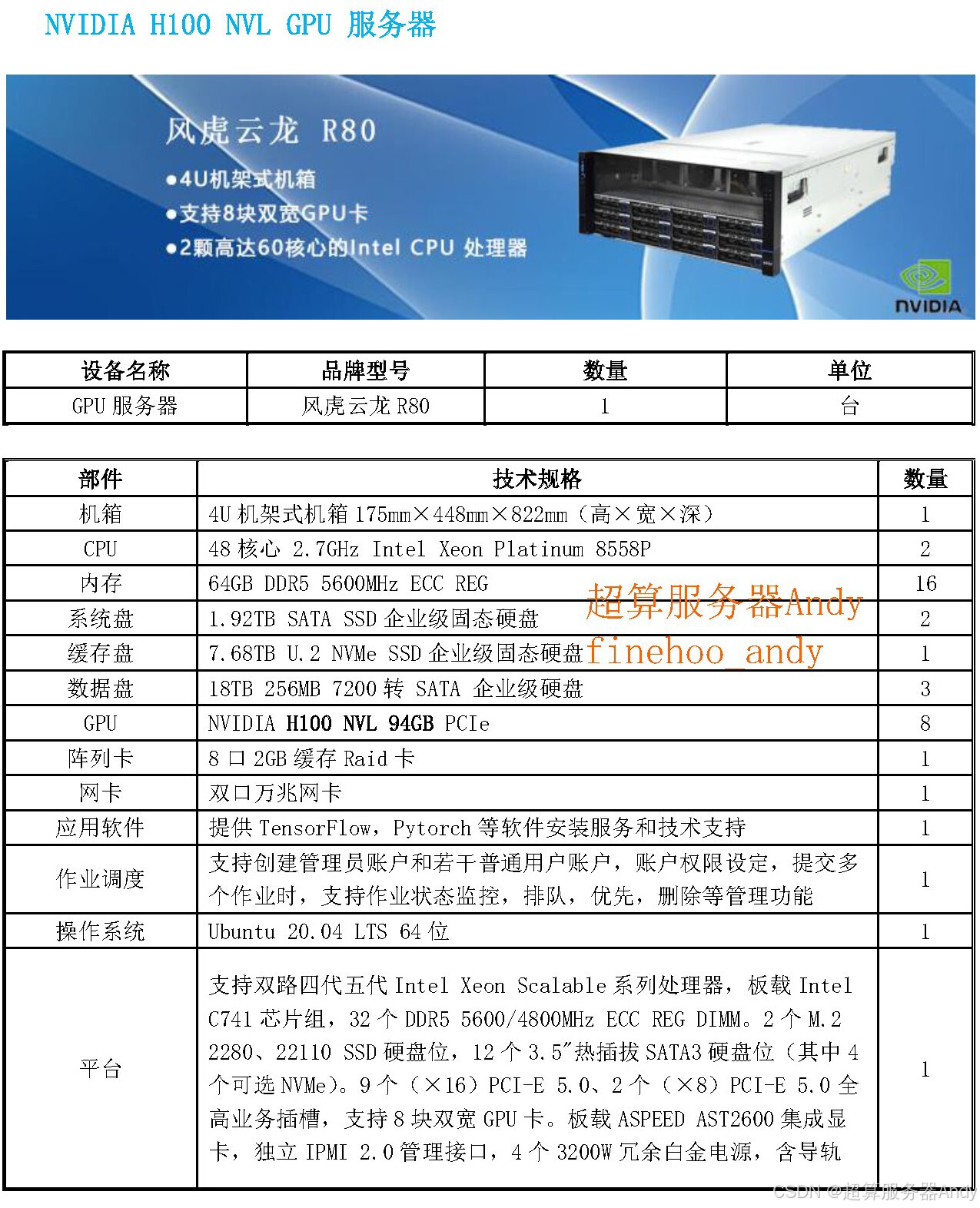
二、深度绑定:Alpamayo-R1 为何离不开 GPU 服务器?
这款 "驾驶大脑" 的运转,本质是 "算力密集型任务",而 GPU 服务器是其不可或缺的硬件基础:
- 实时数据处理的 "算力引擎":自动驾驶需实时处理摄像头、激光雷达等多传感器数据,单帧图像解析就需数十亿次计算。目前 Alpamayo-R1 需基于英伟达 Blackwell 架构 GPU(如 RTX A6000 Pro)运行,其 4000 TOPS 的 INT8 算力(约为前代 Thor 芯片的 6 倍),可实现毫秒级推理,满足驾驶场景的实时性要求。
- 模型训练的 "数据中枢":训练 Alpamayo-R1 需 PB 级路测数据(单辆车每天产生 TB 级数据),且需对数据进行清洗、标注、合成。GPU 服务器的高带宽特性(卡间传输速率可达 100GB/s 以上),能支撑多模态数据并行处理,将数据预处理周期缩短 50% 以上,同时其多卡协同能力可加速模型训练,原本需 3 个月的训练任务,依托 8 卡 GPU 服务器可压缩至 1 个月。
- 具身智能的 "落地载体":英伟达将 "具身智能"(机器人、自动驾驶等与现实世界互动的智能形态)视为 GPU 技术的新增长方向,而 Alpamayo-R1 正是具身智能在自动驾驶领域的实践。这类应用需同时运行视觉识别、逻辑推理、动作规划等多任务,需 GPU 服务器提供 "高算力 + 低延迟" 的双重保障,目前 Jetson Thor 等嵌入式 GPU 设备(2070 TFLOPS 算力)已成为相关研发的标配硬件。
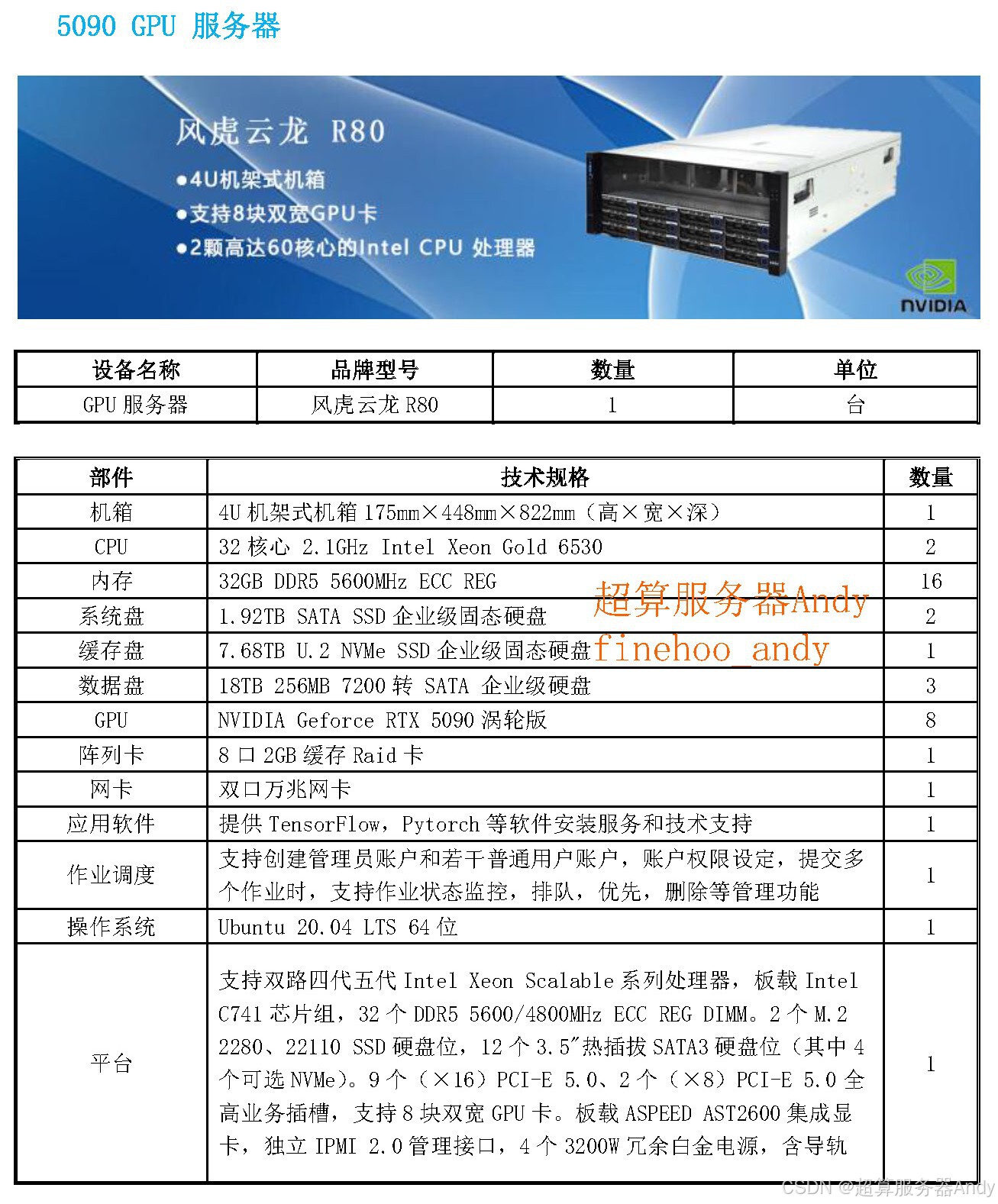
三、科研服务器:自动驾驶研究的 "刚需装备"
对高校、科研机构而言,GPU 科研服务器的价值体现在三个核心维度,完美适配 Alpamayo-R1 相关研究需求:
- 低成本复现前沿成果:Alpamayo-R1 开源后,科研团队无需从零搭建模型,依托科研服务器可快速复现其核心功能。同时,通过 LoRA(低秩适配)等轻量化技术,可在科研服务器上对模型进行微调(如针对雨雪天气场景优化),算力成本仅为企业级数据中心的 1/3。
- 支撑高风险场景仿真:自动驾驶研究需大量极端场景数据(如暴雨、突发交通事故),真实路测不仅成本高,还存在安全风险。科研服务器可运行 Cosmos 模型生成高保真合成数据(如模拟 "行人突然横穿高速公路" 场景),且可通过多轮仿真测试验证模型稳定性,大幅降低研发风险与成本。
- 保障研究连续性:模型训练、数据处理常需连续运行数十天,科研服务器的 "长稳运行" 能力(平均无故障时间可达 30 天以上)及智能故障恢复机制(如断电后自动重启并恢复任务),能避免硬件故障导致的研究中断 ------ 这对依赖 deadlines 的科研项目至关重要。
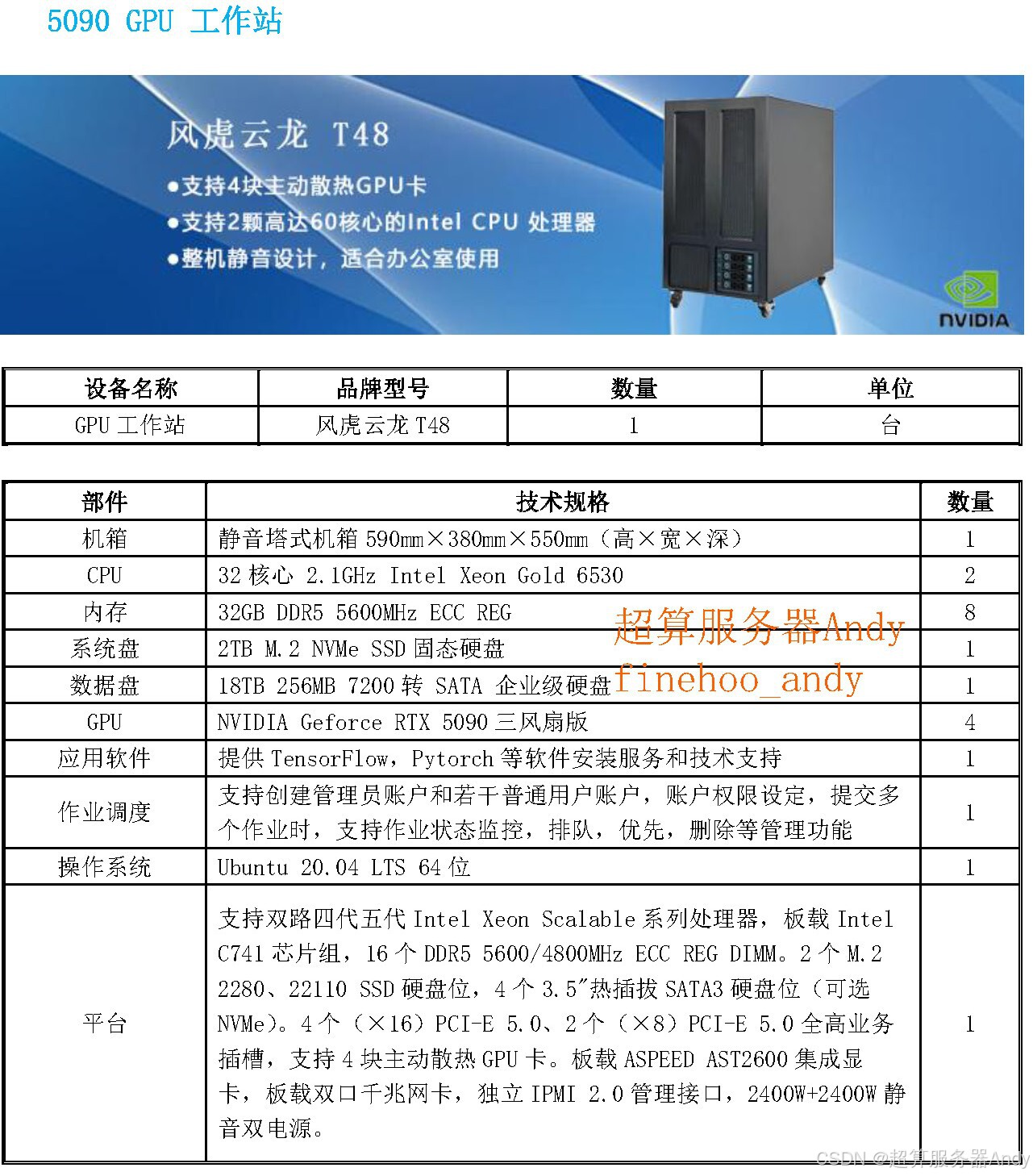
从 Alpamayo-R1 解决 "常识判断" 难题,到 GPU 服务器提供算力支撑,不难发现:自动驾驶的技术突破,始终与硬件算力的升级同频。对科研人员而言,选对 GPU 科研服务器,不仅能降低研发门槛,更能抢占 L4 级自动驾驶技术落地的 "先机"。