TL;DR
- 场景:在单机或小集群环境,完成索引 CRUD、健康检查与 IK 远程词典配置。
- 结论:IK 必须与 ES 版本匹配;重启后用 _analyze 校验;索引观测用 _cat/indices 更稳。
- 产出:可直接复用的命令清单、远程词典部署要点、常见故障定位与修复表。

版本矩阵
| 组件/特性 | 版本/命令 | 已验证 | 说明 |
|---|---|---|---|
| Elasticsearch | 7.3.0 | 是(作者环境) | 索引 CRUD、_cat/indices?v、健康度含义一致;IK 需用 7.3.0 匹配包。 |
| Elasticsearch | 8.15.0 | 是(作者环境) | IK 目录为 plugins/analysis-ik;远程词典通过 IKAnalyzer.cfg.xml 加载后重启生效。 |
| IK 分词器 | 7.3.0 | 是(作者环境) | ik_max_word/ik_smart _analyze 通过。 |
| IK 分词器 | 8.x(与 ES 同 minor) | 建议对齐 | 跨大/小版本可能加载失败;以对应 release 为准。 |
| 远程扩展词典 | Nginx 静态托管 | 是(作者环境) | ext_dict.dic、stop_dict.dic 以 UTF-8 无 BOM 提供,HTTP 可达。 |
| 查询所有索引 | GET _all / _cat/indices?v |
部分 | 实战更推荐 _cat/indices;_all 在部分版本不稳定/不推荐。 |
注意事项
- 代码相关部分(如命令、文件名)使用反引号 ````` 包裹。
- 表格对齐通过调整列宽和文本换行优化可读性。
- 版本号与命令混合的单元格通过分行或括号注明保持清晰。
索引操作
创建索引库
Elasticsearch采用Rest风格API,因此其API就是一次HTTP请求,你可以用任何工具来发起HTTP请求。 语法:
shell
PUT /索引名称
{
"settings": {
"属性名": "属性值"
}
}settings:就是索引库设置,其中可以索引库的各种属性,比如分片数、副本数等。目前我们不设置,先默认即可。 示例:
shell
PUT /wzkicu-index执行结果如下图: 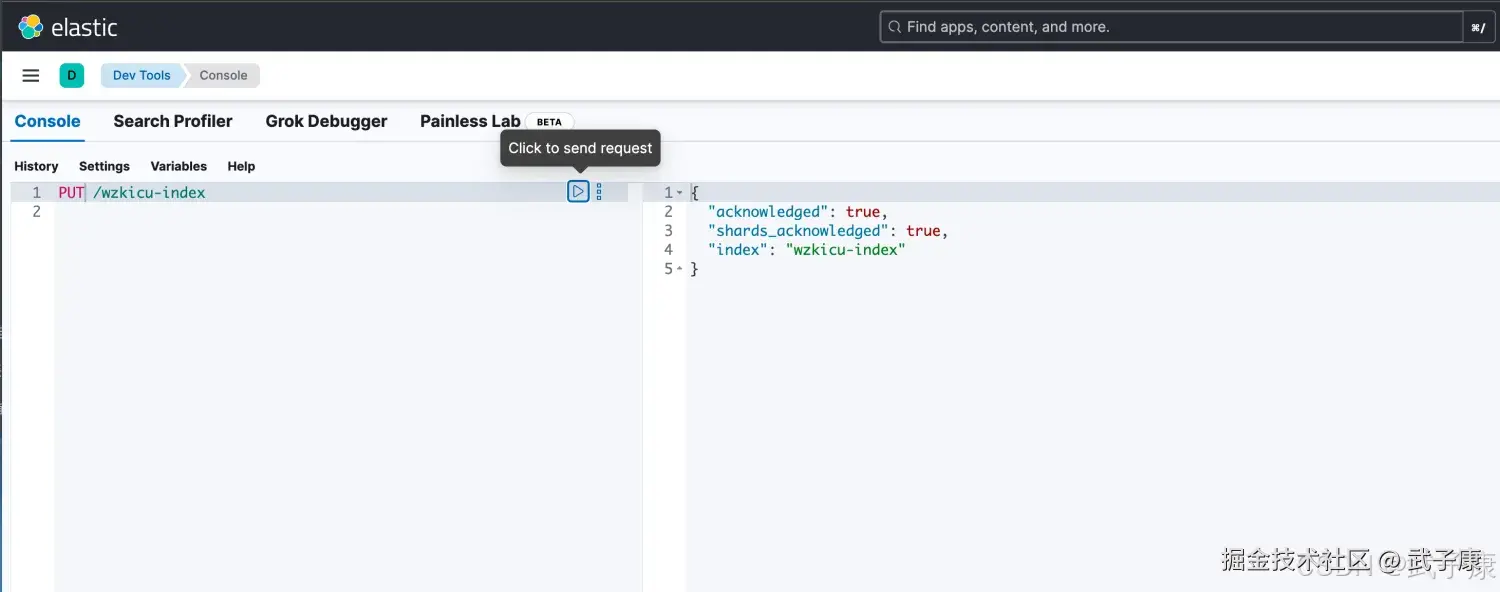
判断索引是否存在
单个索引
语法:
shell
GET /索引名称示例:
shell
GET /wzkicu-index执行结果如下图所示: 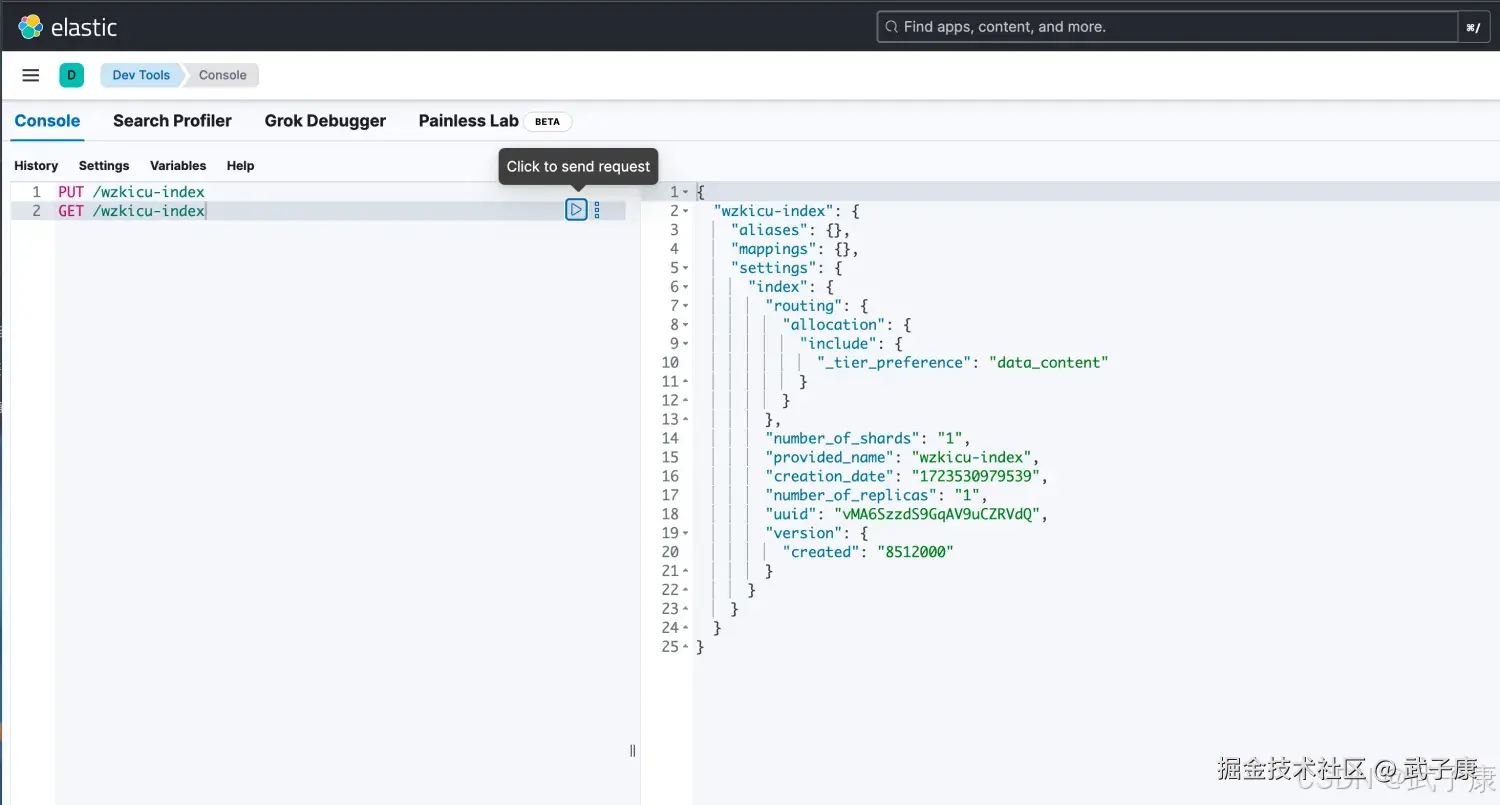
多个索引
语法:
shell
GET /索引名称1,2,3,4,5...示例:
shell
GET /wzkicu-index,wzkicu,wzk执行结果如下图所示:(这里有不存在的索引,所以404了) 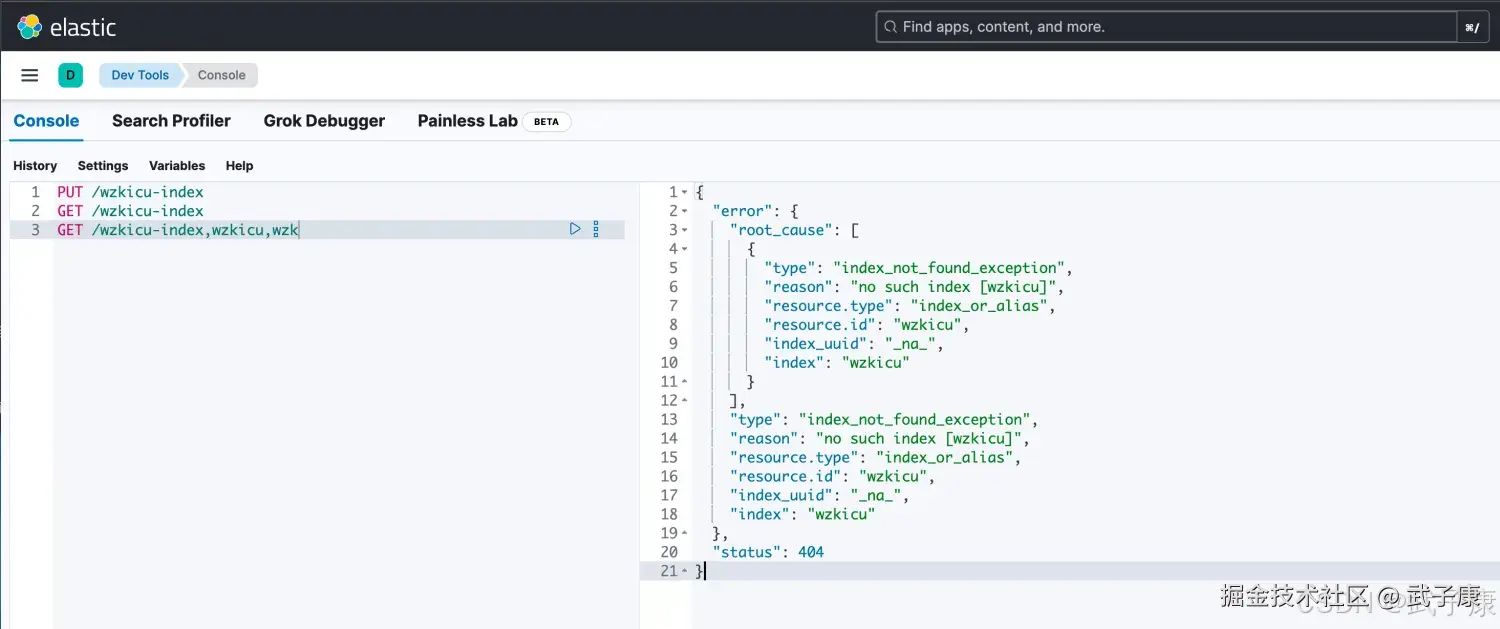
所有索引
方式1:
shell
GET _all执行结果如下图所示: 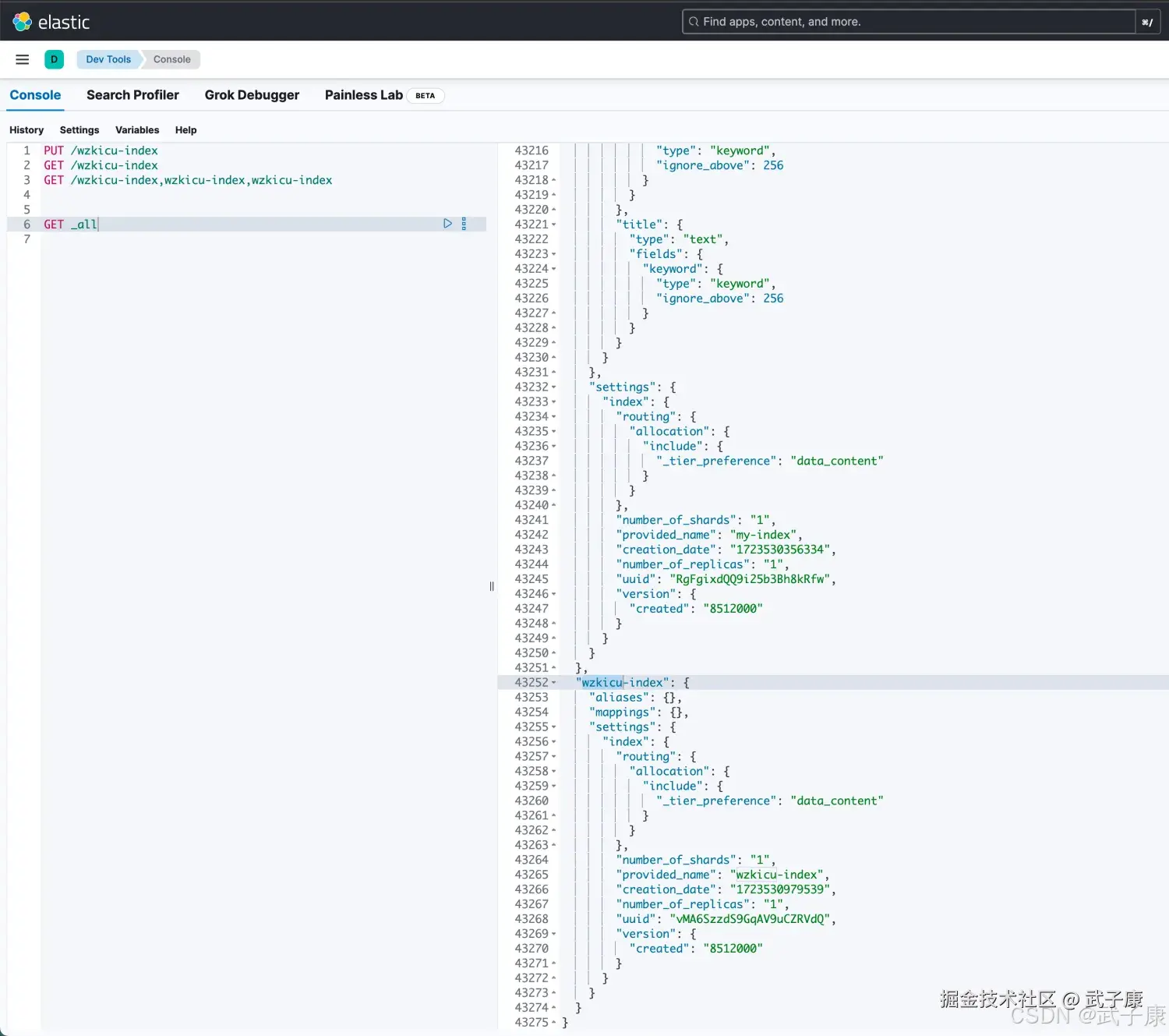 方式2:
方式2:
shell
GET /_cat/indices?v执行结果如下图所示: 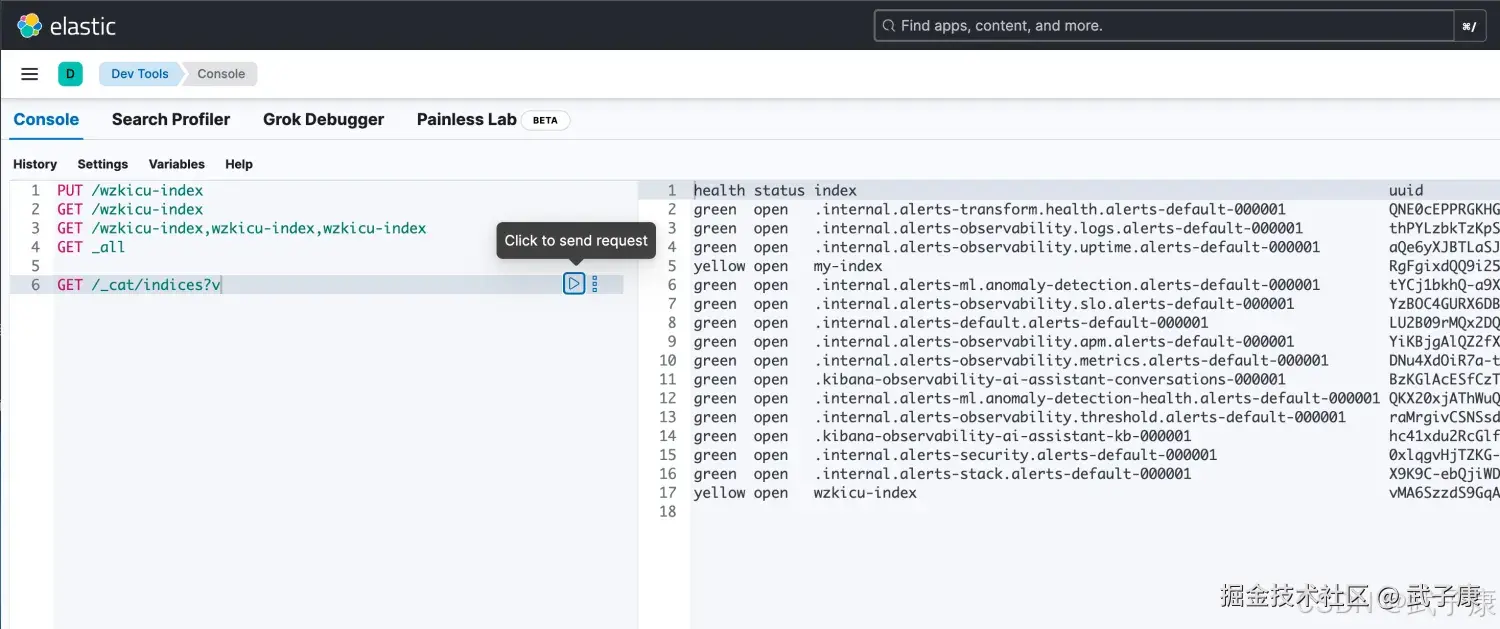 这里的health列,表示:
这里的health列,表示:
- 绿色:索引的所有分片都正常分配
- 黄色:至少有一个副本没有得到正确的分配
- 红色:至少有一个主分片没有得到正常的分配
打开索引
语法:
shell
POST /索引名称/_open示例:
shell
POST /wzkicu-index/_open执行结果如下图: 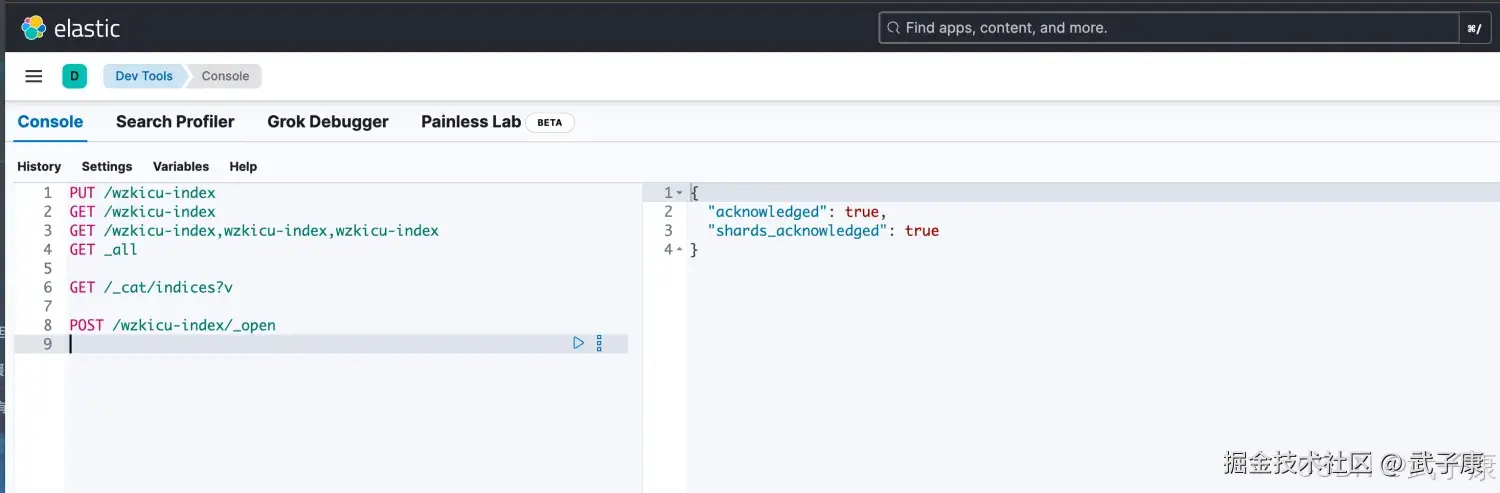
关闭索引
语法:
shell
POST /索引名称/_close示例:
shell
POST /wzkicu-index/_close执行结果如下图: 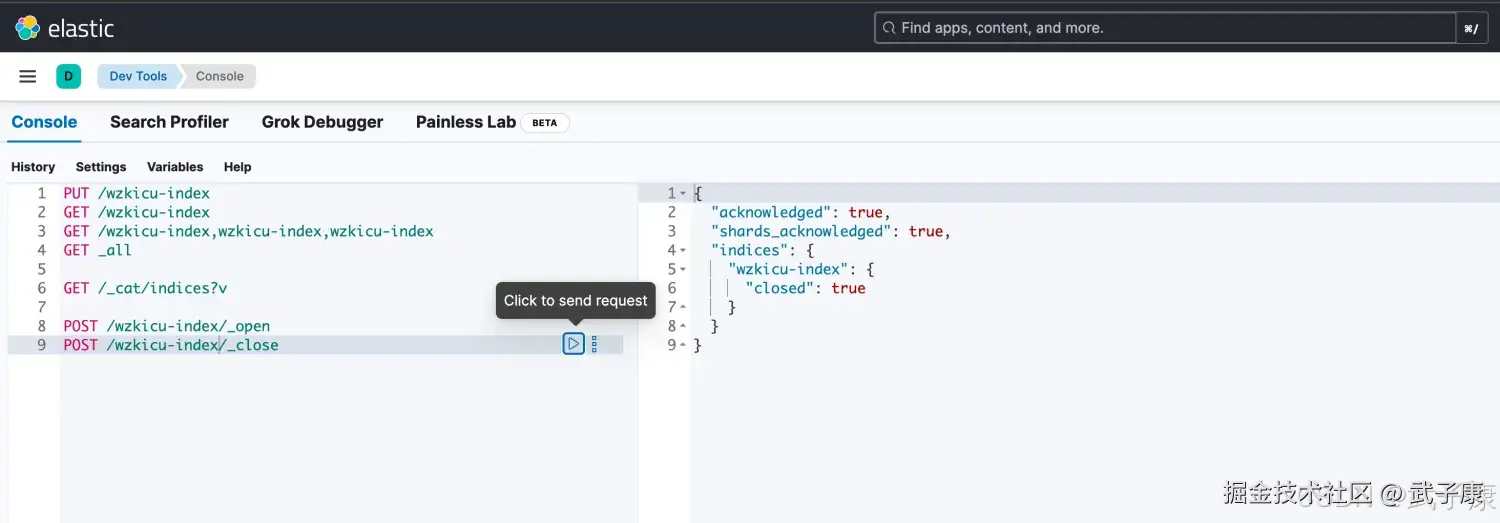
删除索引
语法:
shell
DELETE /索引名称1,2,3,4,5...示例:
shell
DELETE /wzkicu-index执行结果如下图所示: 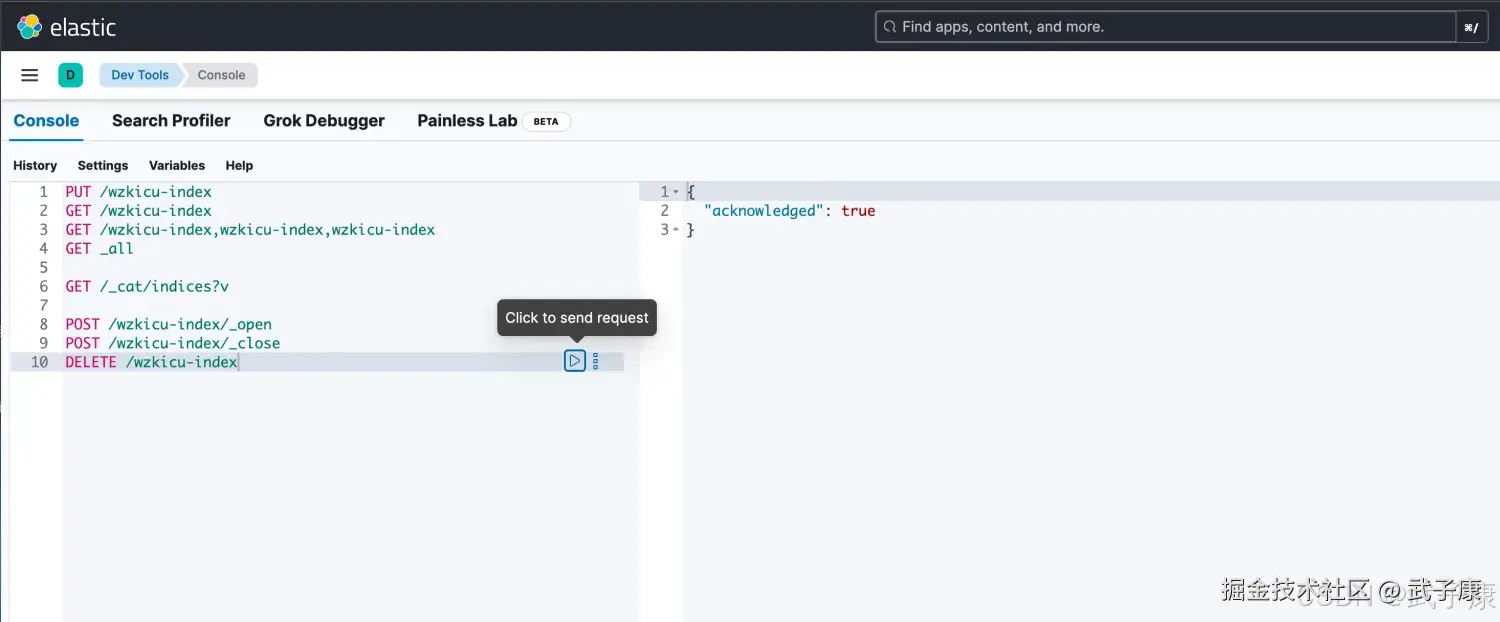
IK分词器
下载项目
官方地址在这里,是GitHub开源的项目,安装方式很多,我这里就直接用官方的方式安装了:
shell
https://github.com/infinilabs/analysis-ik/releases/tag/Latest页面是这样的: 
安装插件
shell
cd /opt/servers/elasticsearch-7.3.0/
bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/7.3.0执行结果如下图所示,我们需要重启ES: 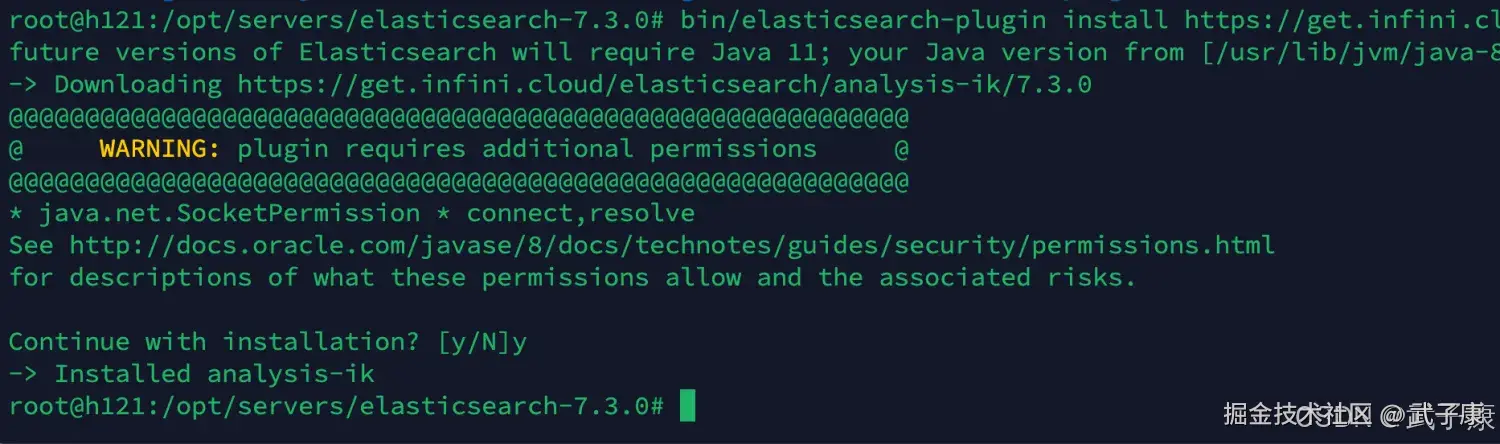
重启ES
重启过程,启动完毕: 
分词测试
IK分词器两种分词模式:
- ik_max_word 模式 (最常用)(会将文本最细粒度的拆分)
- ik_smart 模式 (会做最粗粒度的拆分)
暂时不细追究语法,先学习测试,再后续研究。
ik_max_word
shell
POST _analyze
{
"analyzer": "ik_max_word",
"text": "山东省青岛市黄岛区"
}我们的到的结果是:
shell
{
"tokens": [
{
"token": "山东省",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "山东",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "省",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "青岛市",
"start_offset": 3,
"end_offset": 6,
"type": "CN_WORD",
"position": 3
},
{
"token": "青岛",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
},
{
"token": "市",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 5
},
{
"token": "黄岛区",
"start_offset": 6,
"end_offset": 9,
"type": "CN_WORD",
"position": 6
},
{
"token": "黄岛",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 7
},
{
"token": "区",
"start_offset": 8,
"end_offset": 9,
"type": "CN_CHAR",
"position": 8
}
]
}执行的结果如下图所示: 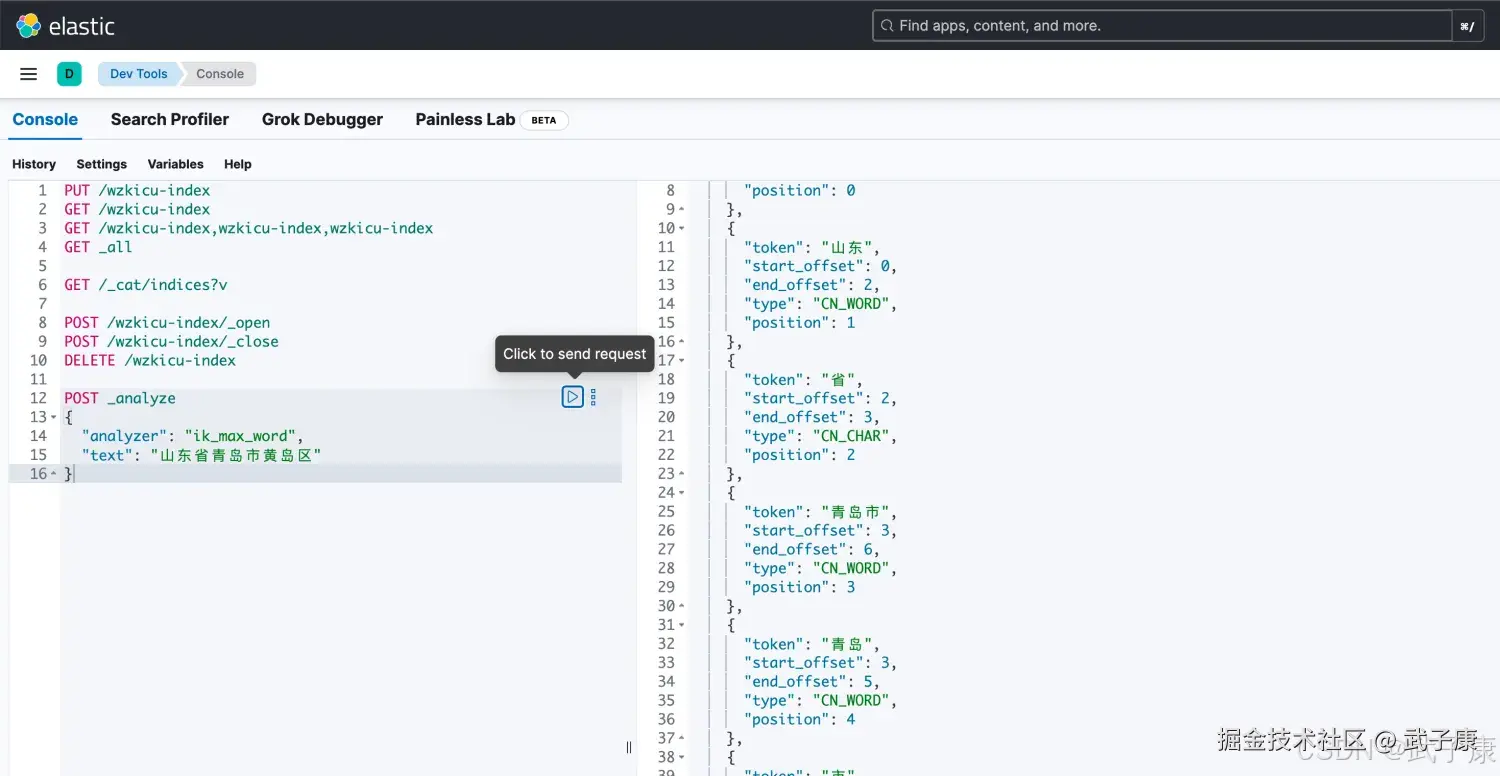
ik_smart
shell
POST _analyze
{
"analyzer": "ik_smart",
"text": "山东省青岛市黄岛区"
}执行的结果是:
json
{
"tokens": [
{
"token": "山东省",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "青岛市",
"start_offset": 3,
"end_offset": 6,
"type": "CN_WORD",
"position": 1
},
{
"token": "黄岛区",
"start_offset": 6,
"end_offset": 9,
"type": "CN_WORD",
"position": 2
}
]
}执行的结果如下图所示: 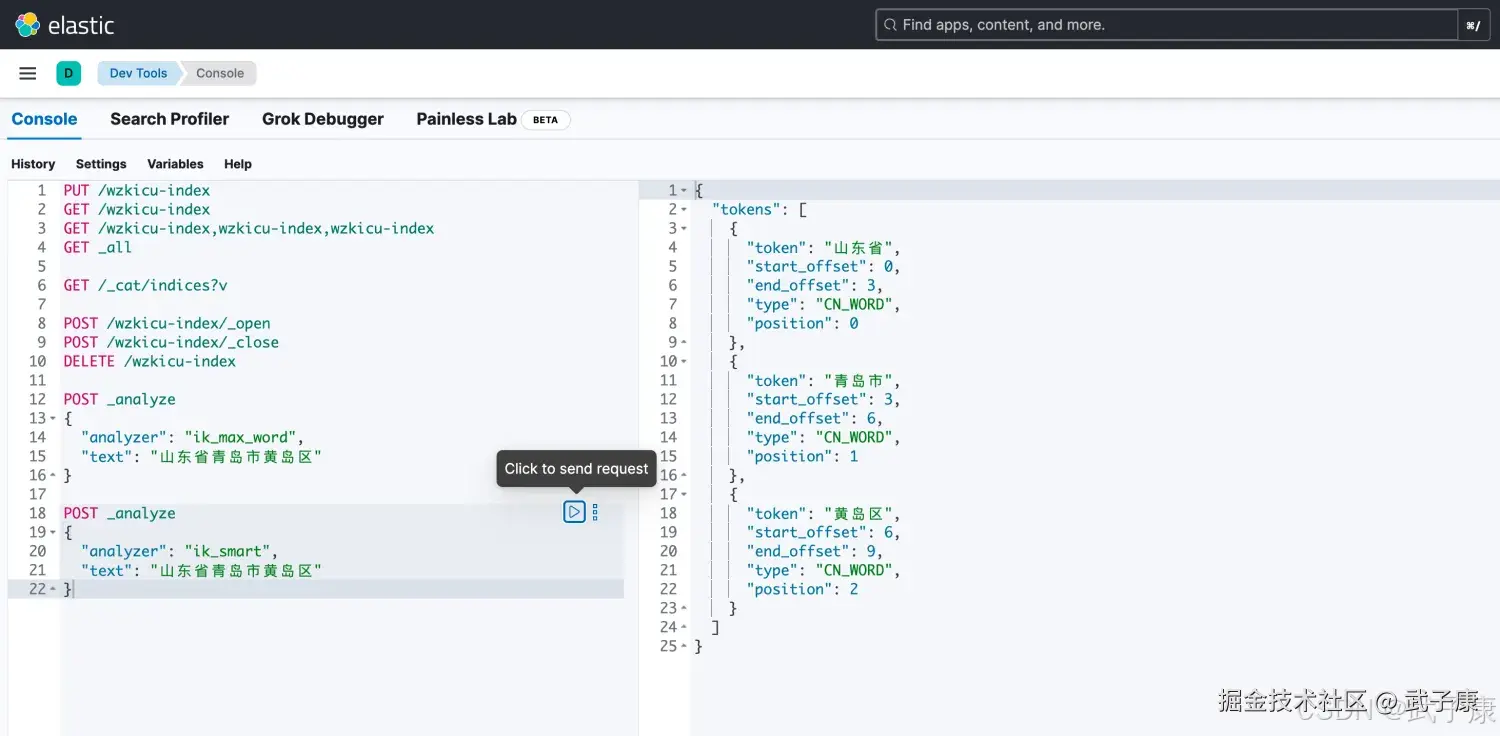
提出问题
在实际环境中,有很多时候并不能够准确的理解我们断词断句,有时候有些词我们想要它拆分,有些词我们希望它不拆分。 那我们怎么办呢?
词典使用
扩展词
不进行分词,告诉引擎这是一个词。
停用词
有些词在文本中出现的频率非常高,但对本文的语义会产生很大的影响,例如:呢、了、啊等等,英语中也有类似于 a 、the、of 等等。这样的词称为停用词。 停用词经常会过滤掉,不会被索引,在检索过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。 停用词可以加快索引的速度、减少索引库的大小。
扩展词、停用词应该统一维护,避免集群中多台导致节点各自维护自己的一份。这里我们计划使用Web的方式,将dict词库共享给分词器等。
分词服务
配置Web 我这里使用 Nginx,你也可以使用 Tomcat:
shell
apt install nginx安装过程如下图所示:  访问页面:h121.wzk.icu,可以看到Nginx顺利运行:
访问页面:h121.wzk.icu,可以看到Nginx顺利运行:  编写dict内容:
编写dict内容:
shell
vim /var/www/html/stop_dict.dic向其中写入的内容如下:
shell
的
了
啊
呢同理,我们写入 ext_dict.dic:
shell
vim /var/www/html/ext_dict.dic我们访问对应的页面,可以拿到对应的Web文件: 
配置分词器
shell
# 这里看自己的版本 我选了好几个
cd /opt/servers/elasticsearch-8.15.0/plugins/analysis-ik
mkdir config
vim IKAnalyzer.cfg.xml写入如下的内容:
xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://h121.wzk.icu/ext_dict.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://h121.wzk.icu/stop_dict.dic</entry>
</properties>对应的截图如下所示: 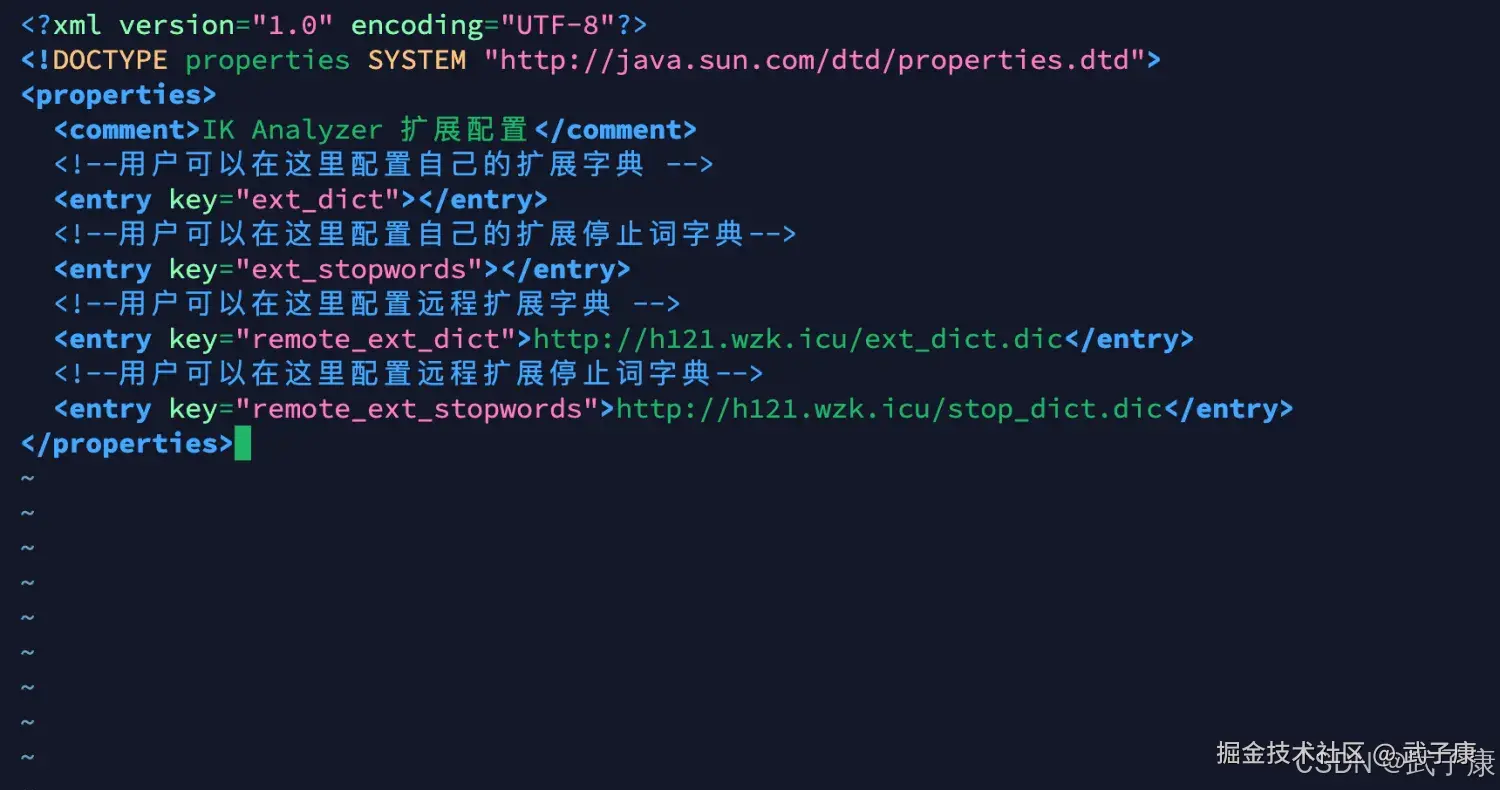
重启服务
重启ES服务,测试效果。
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
_analyze 报 unknown analyzer [ik_max_word] |
未安装IK或版本不匹配/未重启 | 查看plugins/analysis-ik、ES启动日志;安装与ES对齐的IK;重启ES |
| 分词结果无变化(远程词典改了不生效) | 词典URL不可达/缓存未刷新/编码问题 | curl访问词典;查ES日志是否加载成功;确认200可达;UTF-8无BOM;重启ES触发加载 |
| 安装IK报"was built for ES version ..." | 插件与ES版本不一致 | 读取安装报错行;换用与ES完全匹配的IK版本包 |
| 多索引查询404(部分存在、部分不存在) | 请求里包含不存在索引 | _cat/indices?v核对清单;仅保留存在的索引或先创建缺失索引 |
| 集群健康yellow | 单节点副本未分配 | _cluster/health;开发环境将副本数设0,或增加节点 |
| 集群健康red(主分片未分配) | 磁盘阈值/路径错误/节点宕机 | _cluster/allocation/explain、ES日志;释放磁盘、修正path.data、恢复节点并触发分配 |
对已关闭索引操作报index_closed_exception |
索引处于关闭状态 | _cat/indices看status;POST /{index}/_open后再操作 |
| 远程词典加载失败(超时/403/404) | 网络、防火墙或权限限制 | curl -I、Nginx访问日志;放通内网/白名单;保证URL稳定可达 |
| 词典中文显示为乱码 | 文件编码非UTF-8 | 本地查看文件编码;统一保存为UTF-8无BOM |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解