目录
[3.1、集成 Stream](#3.1、集成 Stream)
[4、Redis Stream vs 其他方案](#4、Redis Stream vs 其他方案)
前沿
"我用 Redis 做消息队列好多年了 ,**不就是 LPUSH + BRPOP 吗?**Stream 是什么?有必要用吗?"
如果你也曾这样想,那你并不孤单。但在云原生时代,当系统对可靠性、可观测性、容错能力的要求越来越高时,传统的 Redis List 队列正暴露出越来越多的短板。
而 Redis Stream------这个自 2018 年 Redis 5.0 引入的原生数据类型 ------正在成为中小团队构建可靠事件驱动架构的秘密武器。
如下所示:
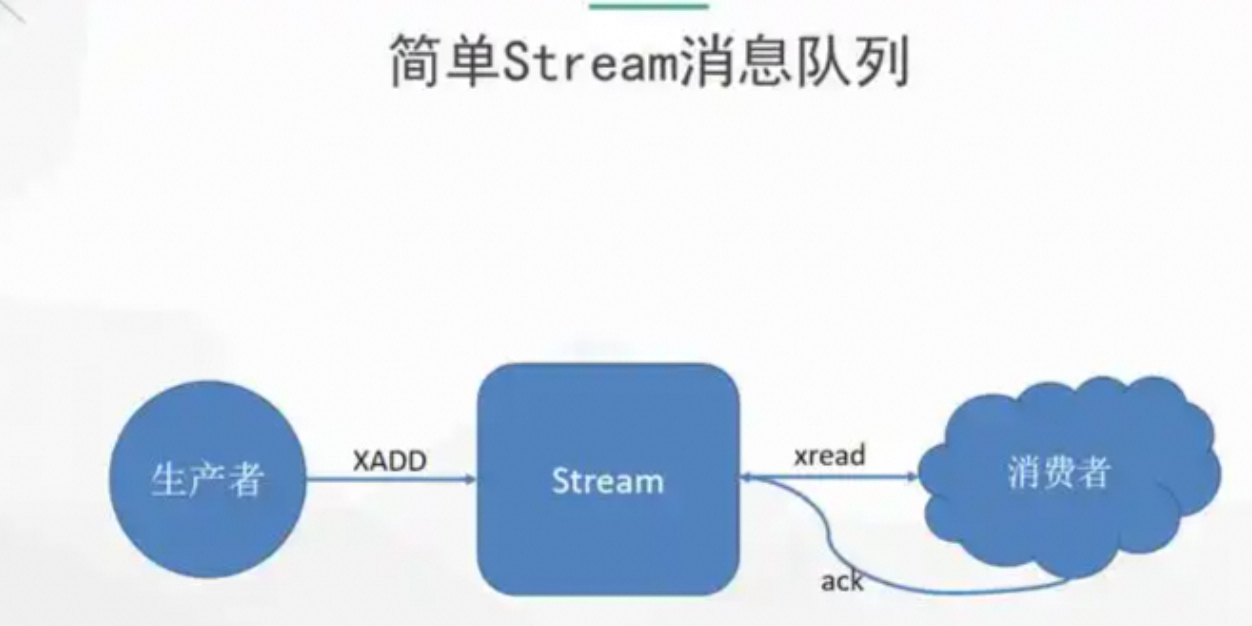
在大多数电商/交易系统中,订单事件具有以下关键属性:

订单事件 ≠ 日志流。它更像"可靠的消息队列",而非"海量数据管道"。
我们选择 Redis Stream,不是因为 Kafka 不好,而是因为:
在订单事件这个"中等吞吐、强顺序、低延迟、少消费者"的场景下,Redis Stream 以 10% 的复杂度,提供了 90% 的能力,让团队能把精力聚焦在业务创新,而非基础设施运维。
这正是 云原生时代"适度架构"(Appropriate Architecture) 的体现------不追求技术先进性,而追求交付效率与系统稳定性的最优平衡。
💡 最后建议 :如果未来业务增长到 单日亿级订单 ,再考虑将核心事件链路迁移到 Kafka。
但在那之前,让简单的事情保持简单。
1、订单事件
1.1、介绍
为什么 Redis 需要 Stream?
传统方案的痛点
多年来,开发者习惯用 Redis 的 List 实现简单队列:
java
LPUSH order_queue "event"
BRPOP order_queue 0看似完美,实则暗藏危机:
- 消息一旦弹出即消失 → 消费者崩溃 = 消息永久丢失
- 无 ACK 机制 → 无法实现"至少一次"投递
- 多消费者竞争消费 → 无法保证同订单只被一个实例处理
- 无法回溯历史 → 排查问题如盲人摸象
更糟的是,PUB/SUB 虽然支持广播,但不持久化,客户端离线即丢消息。
如下所示:
Redis 官方意识到 :社区需要一个"内置的、可靠的、可追溯的消息系统",而不是让每个团队自己造轮子。
于是,Redis Stream 应运而生。
1.2、实现方式
如下:
| 特性 | List(LPUSH / RPOP) | Stream(XADD / XREADGROUP) |
|---|---|---|
| 设计初衷 | 双端队列(Deque),用于栈/队列等基础数据结构 | 专为消息队列设计(类似 Kafka 轻量版) |
| 消息 ID | 无(只有值) | 自动生成唯一 ID(时间戳+序列号) |
| 消费者组 | 不支持 | 原生支持(负载均衡 + ACK + Pending List) |
| 消息持久化 | 随 Redis 持久化 | (更强,支持范围查询) |
| 历史消息回溯 | 只能顺序消费,无法按 ID 查询 | XRANGE 支持任意范围回溯 |
| ACK 机制 | 无(弹出即消失) | 必须显式 ACK,失败可重试 |
| 多消费者协作 | 竞争消费(谁抢到是谁的) | 协作消费(组内负载均衡) |
场景:订单创建后,通知库存服务扣减库存
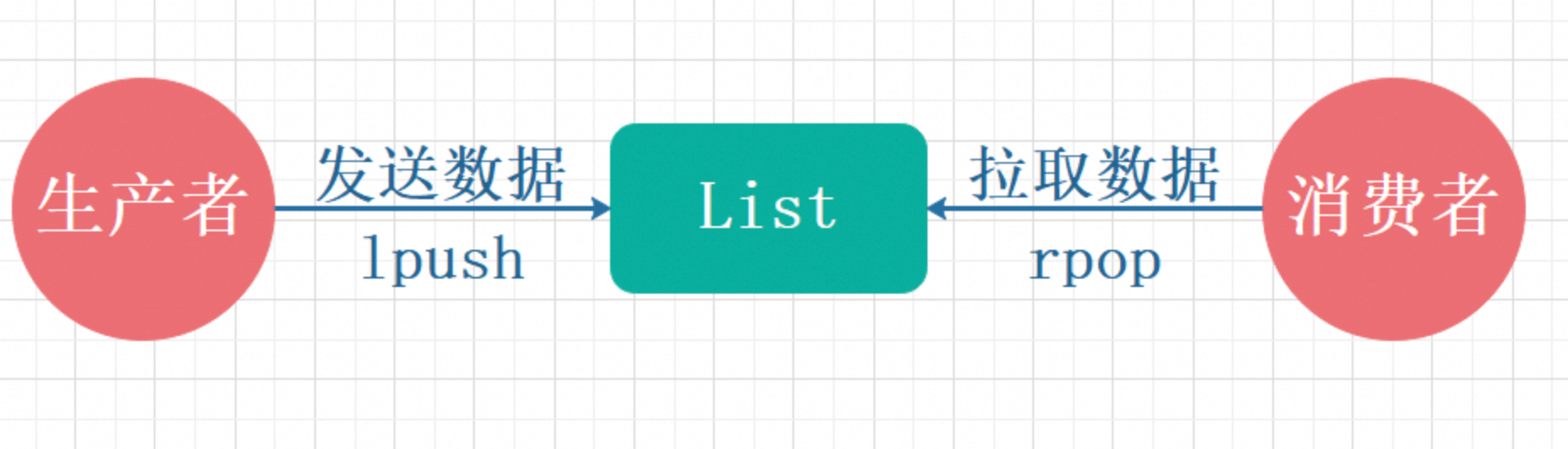
方案 1:用 List(传统方式)
如下所示:
bash
# 生产者:推送消息
LPUSH order_events '{"order_id":"1001","event":"created"}'
# 消费者:阻塞弹出
BRPOP order_events 0问题:
- 消息被弹出后立即消失 ,如果消费者处理失败 → 消息永久丢失
- 多个库存服务实例会竞争消费,无法保证每个实例处理不同订单
- 无法查看历史事件(如排查"为什么没扣库存?")
List 做消息队列的致命缺陷
- 无 ACK 机制 → 消息易丢失
-
消费者 BRPOP 后,消息立即从 List 移除
-
如果消费者在处理中崩溃 → 消息永久丢失
-
无法满足"至少一次"投递语义
- 无消费者组 → 无法水平扩展
-
多个消费者同时 BRPOP,属于竞争消费(Competing Consumers)
-
无法实现"一个订单只被一个实例处理"的语义(需额外加分布式锁)
- 无消息元数据 → 难以运维
-
消息只有 value,没有 ID、时间戳、生产者信息
-
无法追踪消息生命周期,排查问题困难
📌 真实事故案例:某电商用 List 做支付回调队列,因消费者 OOM 导致 2000+ 订单未发货,且无法重放。
**什么时候还能用 List?**虽然 Stream 是更优选择,但 List 在以下场景仍有价值:
| 场景 | 说明 |
|---|---|
| 瞬时任务队列 | 如图片缩略图生成,失败可丢弃 |
| 极简场景 | 单消费者、无可靠性要求 |
| 性能极致敏感 | List 操作略快于 Stream(微秒级差异) |
但只要涉及"业务关键事件"(如订单、支付、用户行为),必须用 Stream!
方案 2:用 Stream(推荐方式)
bash
# 生产者:写入 Stream
XADD order_events * order_id 1001 event created
# 创建消费者组(首次)
XGROUP CREATE order_events inventory_group $
# 消费者:拉取并处理
XREADGROUP GROUP inventory_group service1 COUNT 1 STREAMS order_events >
# 处理成功后
XACK order_events inventory_group 1717020800000-0优势:
-
消息不会丢失:未 ACK 前一直存在 Pending List
-
多个库存服务实例自动分摊消息(消费者组负载均衡)
-
可随时 XPENDING 查看积压消息,
XRANGE回溯历史
1.3、迁移建议
从 List 到 Stream,如果你已有基于 List 的队列,可平滑迁移:
- 双写阶段:同时写 List 和 Stream
- 消费者切换:新消费者从 Stream 消费,旧消费者继续用 List
- 下线 List:确认无积压后停用
如下所示:
Redis 5.0+ 之后,Stream 就是 Redis 官方推荐的消息队列方案。
List 应仅用于其本职工作------作为基础数据结构。
2、Stream
2.1、设计目标
Redis Stream 的设计目标非常明确:
在保持 Redis 简洁性的同时,提供接近 Kafka 的核心消息能力。
具体来说,它解决了:
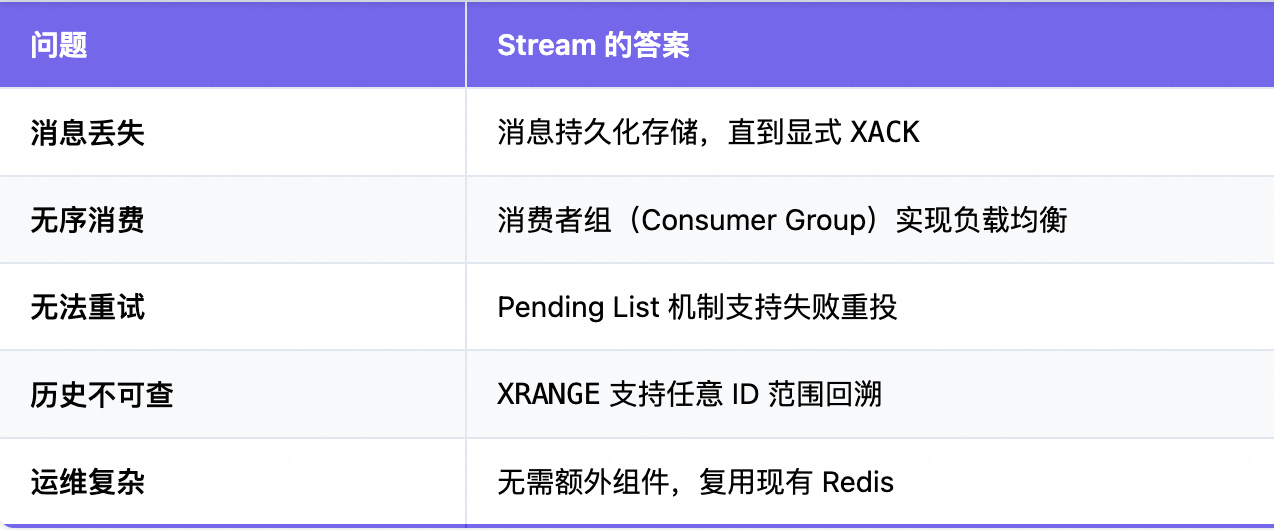
一句话总结:Stream 让 Redis 从"缓存数据库"升级为"轻量级事件总线"。
在日常开发中很少见到,为什么现实中很少看到 Redis Stream?
真相:不是"没人用",而是"场景匹配度决定曝光率"
- 历史惯性:List / PubSub 已满足简单需求
-
很多老系统用 LPUSH + BRPOP 或 PUBLISH/SUBSCRIBE 实现了基础队列
-
"能跑就行",缺乏动力迁移(尤其无消息丢失痛点时)
- Kafka / RocketMQ 主导高可靠场景
-
大厂有专职中间件团队,天然选择 Kafka
-
Redis Stream 被视为"轻量级替代",在中小团队更常见
- Redis Stream 是 2018 年才发布(Redis 5.0)
-
技术普及需要时间(对比 Kafka 2011 年)
-
很多公司 Redis 版本仍停留在 4.x(不支持 Stream)
- 文档与生态滞后
-
Spring Data Redis 对 Stream 的支持直到 2.2+(2019)才完善
-
早期缺乏生产级最佳实践(如死信队列、监控)
现实情况:
- 互联网中后台系统(订单、通知、日志):Redis Stream 使用率快速上升
- 超大规模数据管道:仍用 Kafka
- 传统企业:可能还在用 RabbitMQ
2.2、组成及原理
如下所示:
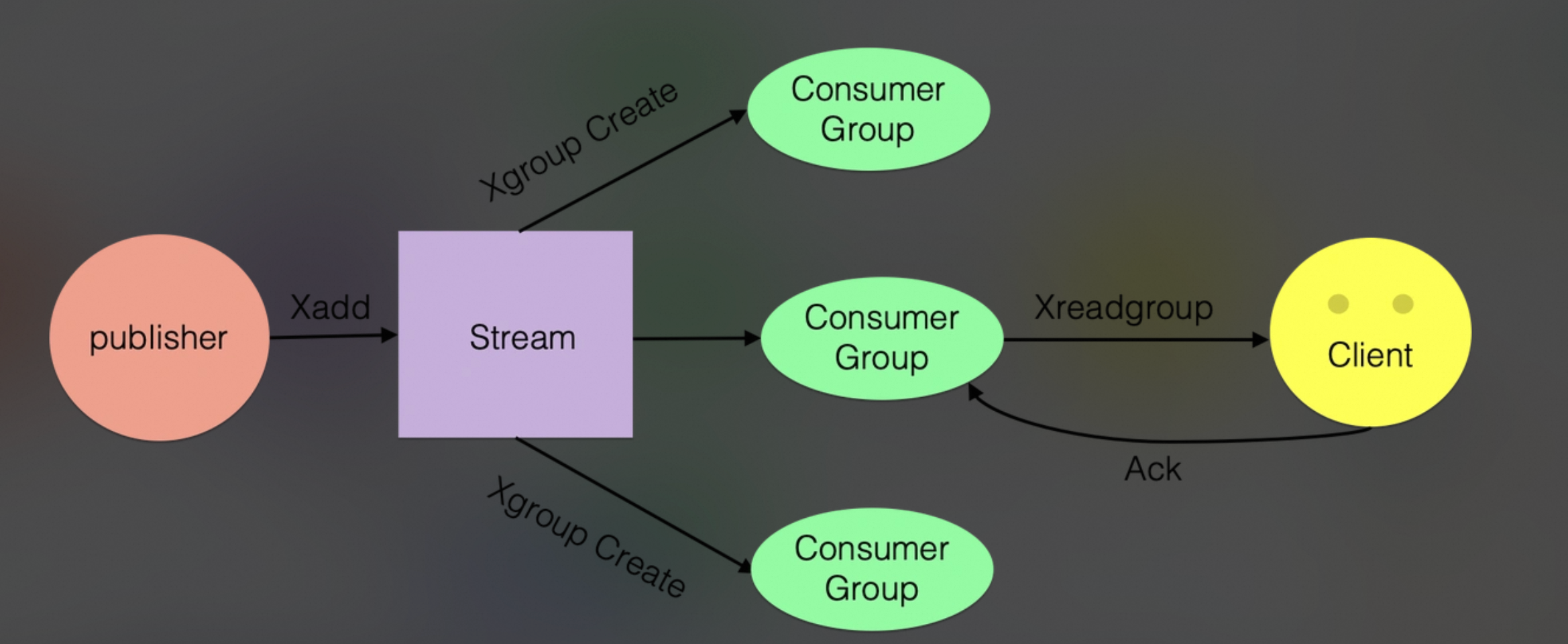
由以下核心角色组成:

由图可知:内置消费者组,无需额外组件,支持按 ID 范围查询历史消息,消息自动持久化(随 RDB/AOF)。
如下所示:
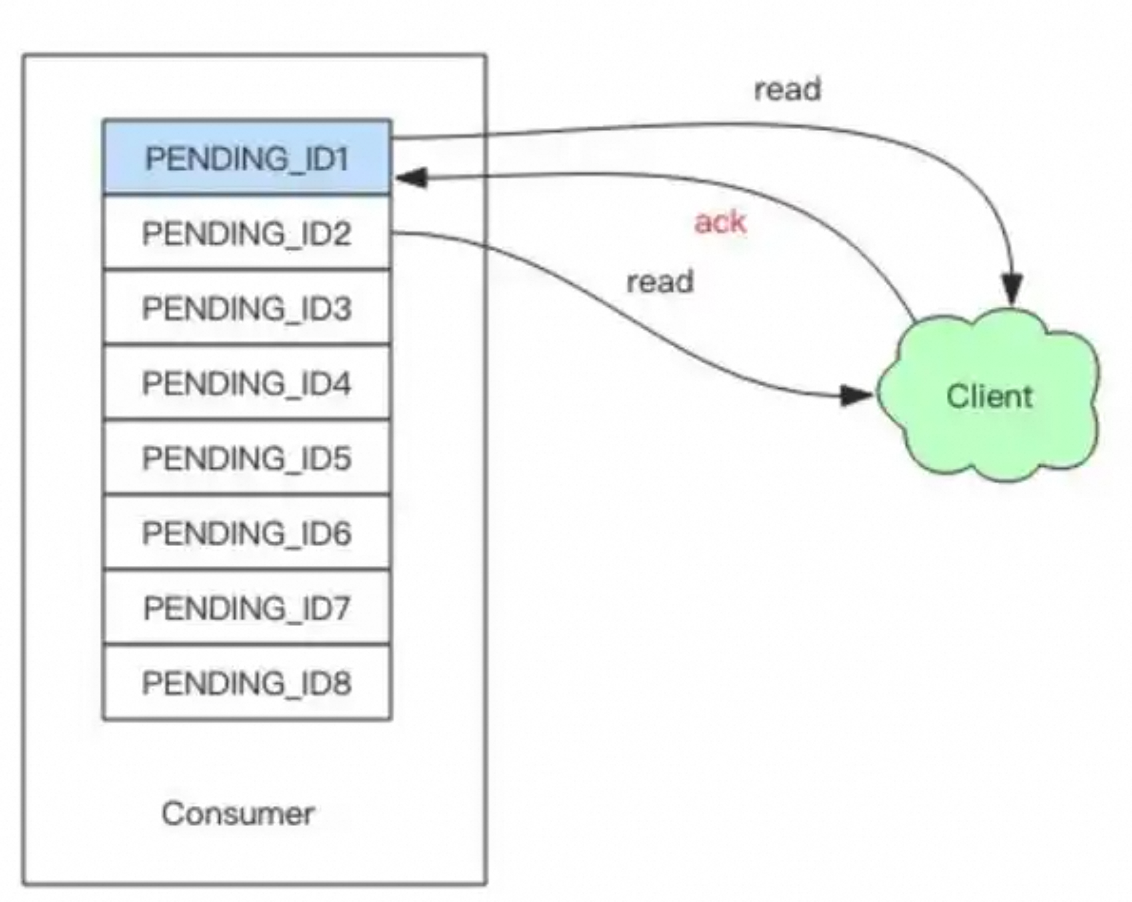
它是一种全新的 Redis 数据类型(Data Type)
如下所示:

关键特征:
- 通过 XADD, XREAD, XGROUP 等专属命令操作
- 内存结构为 Radix Tree + Rax(高效范围查询)
- 持久化方式与其他类型一致(RDB/AOF)
工作原理:Stream 是如何工作的?
数据结构
-
底层使用 Radix Tree + Rax 存储消息
-
每条消息有唯一 ID:
<毫秒时间戳>-<序列号>(如1717020800000-0)
消费者组机制
-
创建组 :XGROUP CREATE stream group
$ -
拉取消息 :XREADGROUP GROUP group consumer STREAMS stream
>-
>表示只拉新消息 -
消息进入 Pending List
-
-
确认消息 :XACK stream
group id- ACK 后从 Pending List 移除
-
处理积压:XPENDING + XCLAIM 实现死信转移
💡 这正是 Kafka Consumer Group 的简化版!
2.3、基础操作
以下是一个简单的生产与消费模型:
1、创建 Stream 并写入消息
bash
# XADD stream_name * field1 value1 field2 value2
XADD orders * order_id 1001 event_type "created" user_id "alice"
XADD orders * order_id 1002 event_type "paid" amount "99.9"
# 返回自动生成的 ID(如 1717020800000-0)*表示自动生成 ID(基于毫秒时间戳 + 序列号)- 也可指定 ID:XADD
orders 1717020800000-0 ...
2、读取消息(简单模式)
bash
# 读取所有消息
XRANGE orders - +
# 读取最近 10 条
XRANGE orders - + COUNT 10
# 从某个 ID 之后读取(用于增量拉取)
XRANGE orders 1717020800000-0 + -表示最小 ID,+表示最大 ID
2.4、局限性
当然,Redis Stream 并非完美,需正视其限制并制定对策:
| 局限 | 应对方案 |
|---|---|
| 内存存储,容量有限 | - 设置 Stream 最大长度:XADD orders MAXLEN~1000000 * ... - 冷数据归档到 DB 或 Kafka(仅用于分析) |
| 无内置 Schema 管理 | - 用 JSON 格式 + 代码校验 - 或引入轻量级 Schema(如 Avro) |
| 集群模式下 Stream 不分片 | - 单 Shard 承载足够(10k QPS) - 超高吞吐时按业务分多个 Stream key(如 orders_shard_1, orders_shard_2) |
| 消息堆积影响 Redis 性能 | - 监控 XLEN orders - 消费者异常时自动告警 + 降级 |
3、实际操作
3.1、常用命令
如下所示:
bash
# 写入
XADD orders * order_id 1001 event created
# 创建消费者组
XGROUP CREATE orders order_group $
# 消费
XREADGROUP GROUP order_group service1 COUNT 10 STREAMS orders >
# ACK
XACK orders order_group 1717020800000-0
# 查看积压
XPENDING orders order_group3.1、集成 Stream
下面是一个 开箱即用 的 Spring Boot 3.x + Redis Stream 示例,包含 生产者、消费者组、ACK、异常处理。
步骤 1:添加依赖(Maven)
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 如果用 Lettuce(默认),无需额外依赖 -->步骤 2:配置 Redis 连接(application.yml)
bash
spring:
redis:
host: localhost
port: 6379
lettuce:
pool:
max-active: 8步骤 3:定义事件模型
java
public class OrderEvent {
private String orderId;
private String eventType;
private String userId;
// constructors, getters, setters
}步骤 4:创建 Stream 生产者
java
@Service
public class OrderEventProducer {
private final RedisTemplate<String, Object> redisTemplate;
public OrderEventProducer(RedisTemplate<String, Object> redisTemplate) {
this.redisTemplate = redisTemplate;
}
public void sendOrderEvent(OrderEvent event) {
Map<String, String> payload = new HashMap<>();
payload.put("orderId", event.getOrderId());
payload.put("eventType", event.getEventType());
payload.put("userId", event.getUserId());
redisTemplate.opsForStream().add(
StreamRecords.newRecord()
.ofObject(payload)
.withStreamKey("order_events")
);
}
}步骤 5:创建 Stream 消费者(核心!)
java
@Component
public class OrderEventConsumer implements ApplicationRunner {
private static final String STREAM_KEY = "order_events";
private static final String CONSUMER_GROUP = "order_group";
private static final String CONSUMER_NAME = "inventory_service";
private final RedisConnectionFactory connectionFactory;
private final ObjectMapper objectMapper; // 用于 JSON 反序列化
public OrderEventConsumer(RedisConnectionFactory connectionFactory,
ObjectMapper objectMapper) {
this.connectionFactory = connectionFactory;
this.objectMapper = objectMapper;
}
@Override
public void run(ApplicationArguments args) {
// 1. 创建消费者组(如果不存在)
createConsumerGroup();
// 2. 启动消费者监听
StreamMessageListenerContainer.StreamMessageListenerContainerOptions<String, MapRecord<String, String, String>> options =
StreamMessageListenerContainer.StreamMessageListenerContainerOptions
.builder()
.pollTimeout(Duration.ofSeconds(1))
.build();
StreamMessageListenerContainer<String, MapRecord<String, String, String>> container =
StreamMessageListenerContainer.create(connectionFactory, options);
Consumer consumer = Consumer.from(CONSUMER_GROUP, CONSUMER_NAME);
StreamOffset<String> offset = StreamOffset.create(STREAM_KEY, ReadOffset.lastConsumed());
container.receive(consumer, offset, this::handleMessage);
container.start();
}
private void handleMessage(Message<MapRecord<String, String, String>> message) {
try {
MapRecord<String, String, String> record = message.getRecord();
Map<String, String> payload = record.getValue();
// 转换为业务对象
OrderEvent event = new OrderEvent();
event.setOrderId(payload.get("orderId"));
event.setEventType(payload.get("eventType"));
event.setUserId(payload.get("userId"));
// 处理业务逻辑(如扣库存)
processOrderEvent(event);
// 手动 ACK(关键!)
message.acknowledge();
} catch (Exception e) {
log.error("Failed to process order event", e);
// 不 ACK,消息会留在 Pending List,后续可重试
}
}
private void createConsumerGroup() {
try (RedisConnection connection = connectionFactory.getConnection()) {
// XGROUP CREATE order_events order_group $ MKSTREAM
connection.streamCommands().xGroupCreate(
STREAM_KEY.getBytes(),
CONSUMER_GROUP.getBytes(),
ReadOffset.from("0-0").getOffset().getBytes(),
true // MKSTREAM
);
} catch (Exception e) {
if (!e.getMessage().contains("BUSYGROUP")) {
throw new RuntimeException("Failed to create consumer group", e);
}
// BUSYGROUP 表示组已存在,忽略
}
}
private void processOrderEvent(OrderEvent event) {
// 你的业务逻辑
System.out.println("Processing: " + event);
}
}步骤 6:测试发送事件
java
@RestController
public class TestController {
@Autowired
private OrderEventProducer producer;
@PostMapping("/test")
public String test() {
producer.sendOrderEvent(new OrderEvent("1001", "created", "user123"));
return "Sent!";
}
}关键配置说明:
| 配置项 | 作用 | 建议值 |
|---|---|---|
| pollTimeout | 拉取消息的阻塞时间 | 1--5 秒 |
| autoAcknowledge | 是否自动 ACK | false(必须手动控制) |
| ReadOffset.lastConsumed() | 从上次消费位置开始 | 生产环境必选 |
| MKSTREAM | 自动创建 Stream | 首次启动时需要 |
3.3、生产实践
- 死信队列(DLQ)
- 消息重试 3 次后转入 order_events_dlq
- 用 XPENDING + XCLAIM 实现
- 监控积压
bash
# 查看未 ACK 消息数
XPENDING order_events order_group- 配合 Prometheus + Grafana 告警
3. Stream 长度限制
java
// 发送时限制长度
redisTemplate.opsForStream().add(
StreamRecords.newRecord()
.ofObject(payload)
.withStreamKey("order_events")
.withMaxLength(1_000_000) // 保留 100 万条
);✅ 核心要点:
- 手动 ACK 是可靠性的基石
- 消费者组名 + 消费者名 决定消息分配
- ReadOffset.lastConsumed() 确保断点续传
- 限制 Stream 长度(防内存爆炸)
bash
# 保留最近 100 万条
XADD orders MAXLEN ~ 1000000 * order_id 1003 event_type "shipped"~表示"大约",性能更高(不精确删除)
- 监控 Pending Entries
-
定期检查 XPENDING,避免消息堆积
-
设置告警:XPENDING orders order_group | awk '{if($1>1000) print "ALERT"}'
- 消费者异常处理
-
消费失败时不要 ACK,让消息重回 Pending List
-
可结合 XCLAIM 实现死信队列(重试 N 次后转入 error_stream)
- 高可用部署
-
Redis Stream 数据随主从复制
-
消费者组状态不复制 !故障切换后需重建消费者组(用
0而非$从头消费)
4、Redis Stream vs 其他方案
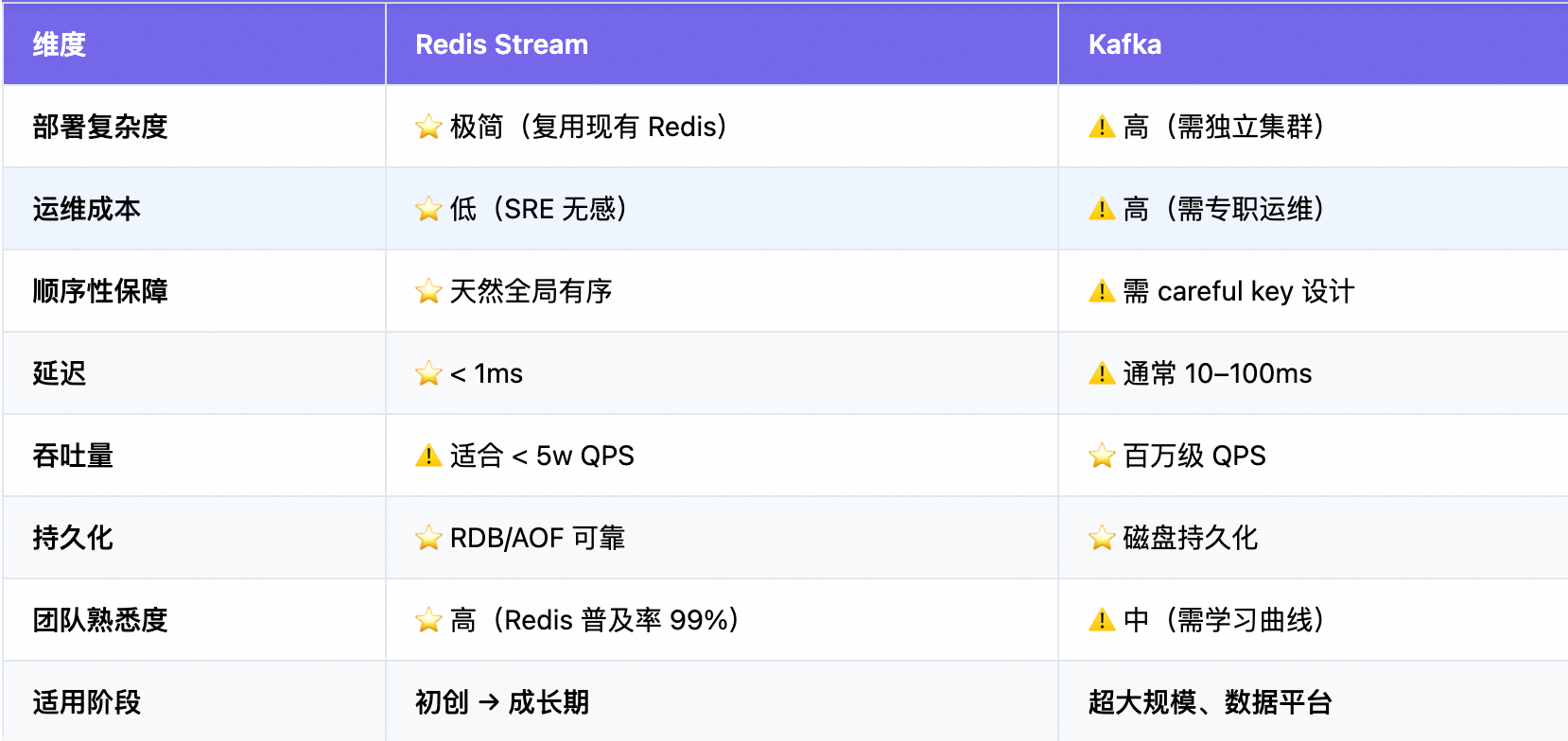
Stream vs Kafka ------ 不是替代,而是互补。
推荐方案如下:
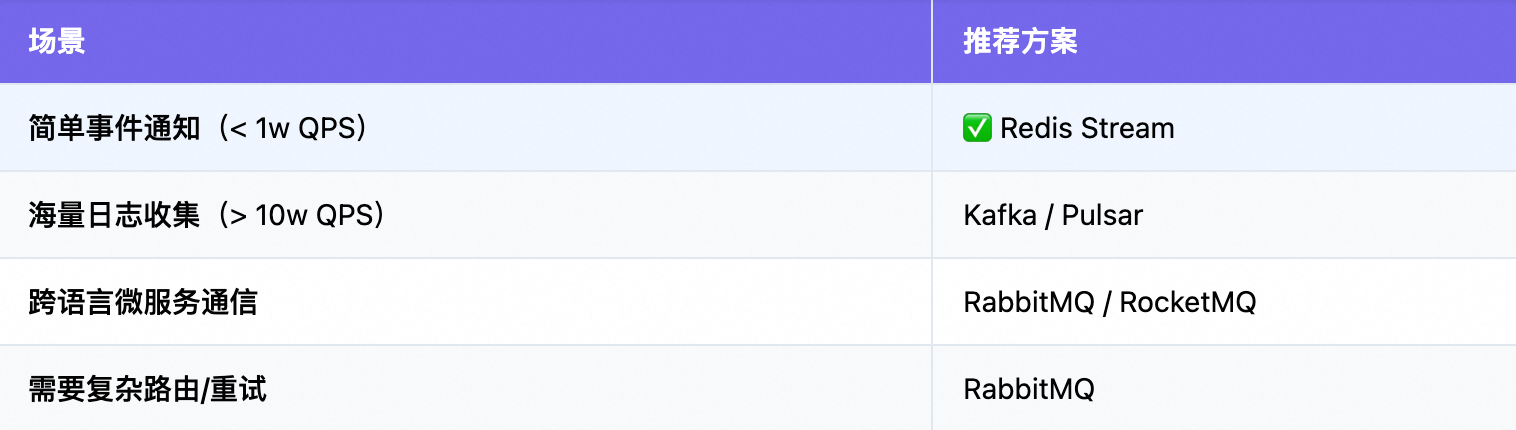
关于stream和kafka的对比,如下所示:
前沿:Stream 的未来演进,Redis 社区并未止步:
- Redis 7.0+ :支持 Stream 自动过期 (XADD
...NOMKSTREAM) - Redis Stack :集成 Search & Query,可对 Stream 内容全文检索
- Redis Streams on Flash:大容量低成本存储(企业版)
💡 趋势 :Stream 正从"消息队列"向"实时事件数据库"演进。
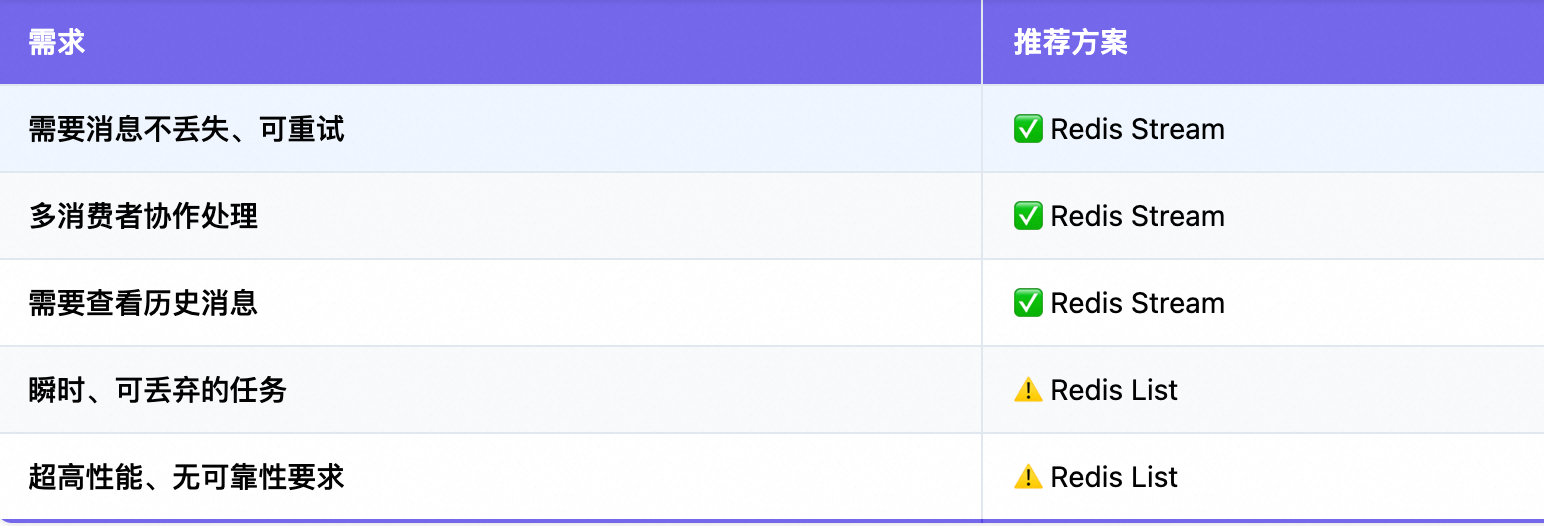
总结:什么时候该用 Redis Stream?
强烈推荐使用,如果你的场景满足:
-
吞吐量 < 10w QPS
-
需要消息不丢失、可重试
-
团队无 Kafka 运维能力
-
已在使用 Redis(零新增依赖)
不要使用,如果:
-
需要百万级吞吐
-
要求跨数据中心复制
-
需要复杂流处理(如窗口聚合)
技术选型不是"最新最好",而是"恰到好处" 。Redis Stream 不是 Kafka 的廉价替代品,而是为特定场景量身定制的优雅解。
参考文章: