在数据驱动的时代,掌握数据分析技能至关重要。本文将带你使用 Python 中的 pandas、numpy 和 matplotlib 库,对地铁客流、网约车订单、体检中心健康和健身房运动四类真实场景的数据进行完整分析。每个案例都包含数据清洗、统计计算、可视化呈现和结果解读。
一、地铁客流数据分析
代码
python
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 1. 读取 CSV 文件数据,计算每个站点的总客流(进站人数 + 出站人数),添加为新列。
df = pd.read_csv("地铁客流数据.csv")
df['总客流'] = df['进站人数'] + df['出站人数']
print(df)
total = df.groupby('站点名称')['总客流'].sum()
print(total)
# 2. 按 "线路" 和 "时段" 双重分组,统计不同线路、不同时段的平均进站人数。
avg_in = df.groupby(['线路', '时段 (早高峰/平峰/晚高峰)'])['进站人数'].mean()
print(avg_in)
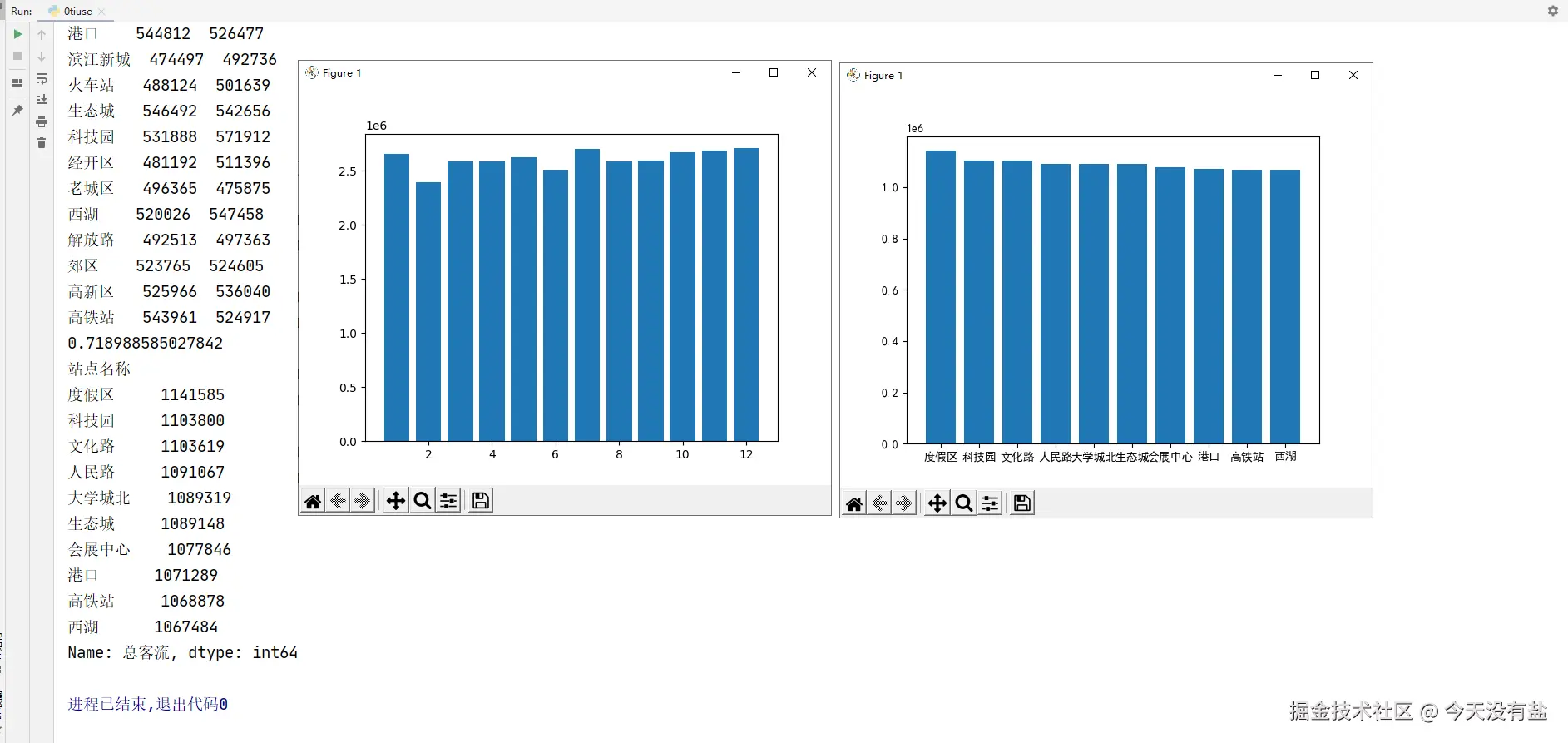
# 3. 提取 "日期" 中的月份,统计每月的总客流(所有站点进出站之和),绘制柱状图。
df['日期'] = pd.to_datetime(df['日期']) # 字符串转换为datetime
df['月份'] = df['日期'].dt.month
total_month = df.groupby('月份')['总客流'].sum()
plt.bar(total_month.index, total_month)
plt.show()
# 4. 计算每个站点进站人数与出站人数的相关系数。
station = df.groupby('站点名称').agg({
'进站人数':'sum',
'出站人数':'sum'
}).sort_index()
print(station)
corr = station['进站人数'].corr(station['出站人数'])
print(corr)
# 5. 筛选出总客流前 10 的站点,绘制水平柱状图展示结果。
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
total = total.sort_values(ascending=False) # 降序排序
top10 = total[:10]
print(top10)
plt.bar(top10.index, top10)
plt.show()代码结果
代码分析
- 数据预处理 :使用
pd.read_csv读取数据,通过列运算添加"总客流"列。 - 分组统计 :利用
groupby实现单分组和双重分组统计,结合sum()、mean()完成聚合计算。 - 时间处理 :通过
pd.to_datetime转换日期格式,提取月份进行月度统计。 - 相关性分析 :先按站点聚合进出站人数,再使用
corr()计算相关系数。 - 可视化 :使用
plt.bar绘制柱状图,并设置中文字体防止乱码。 - 数据筛选 :通过
sort_values和切片获取 Top10 数据。
二、网约车订单数据分析
代码
python
import pandas as pd
import matplotlib.pyplot as plt
# 1. 读取 CSV 文件数据,计算订单总费用(起步价 + 行程距离 × 里程费 + 附加费),添加为新列。
data = pd.read_csv(
"网约车订单数据.csv",
index_col="订单ID"
)
data['订单量'] = [1 for i in range(data.shape[0])]
data['总费用'] = data['起步价 (元)'] + data['行程距离 (km)']*data['里程费 (元/km)'] + data['附加费 (元)']
print(data)
# 2. 按 "出发时间" 提取小时信息,统计各小时的订单量和平均行程距离。
data['出发时间'] = pd.to_datetime(data['出发时间'])
data['小时'] = data['出发时间'].dt.hour
state = data.groupby('小时').agg({
'订单量':'sum',
'行程距离 (km)':'mean'
})
print(state)
# 3. 计算总费用的最大值、最小值、均值和标准差。
total_sales_state = data['总费用'].agg(['max', 'min', 'mean', 'std'])
print(total_sales_state)
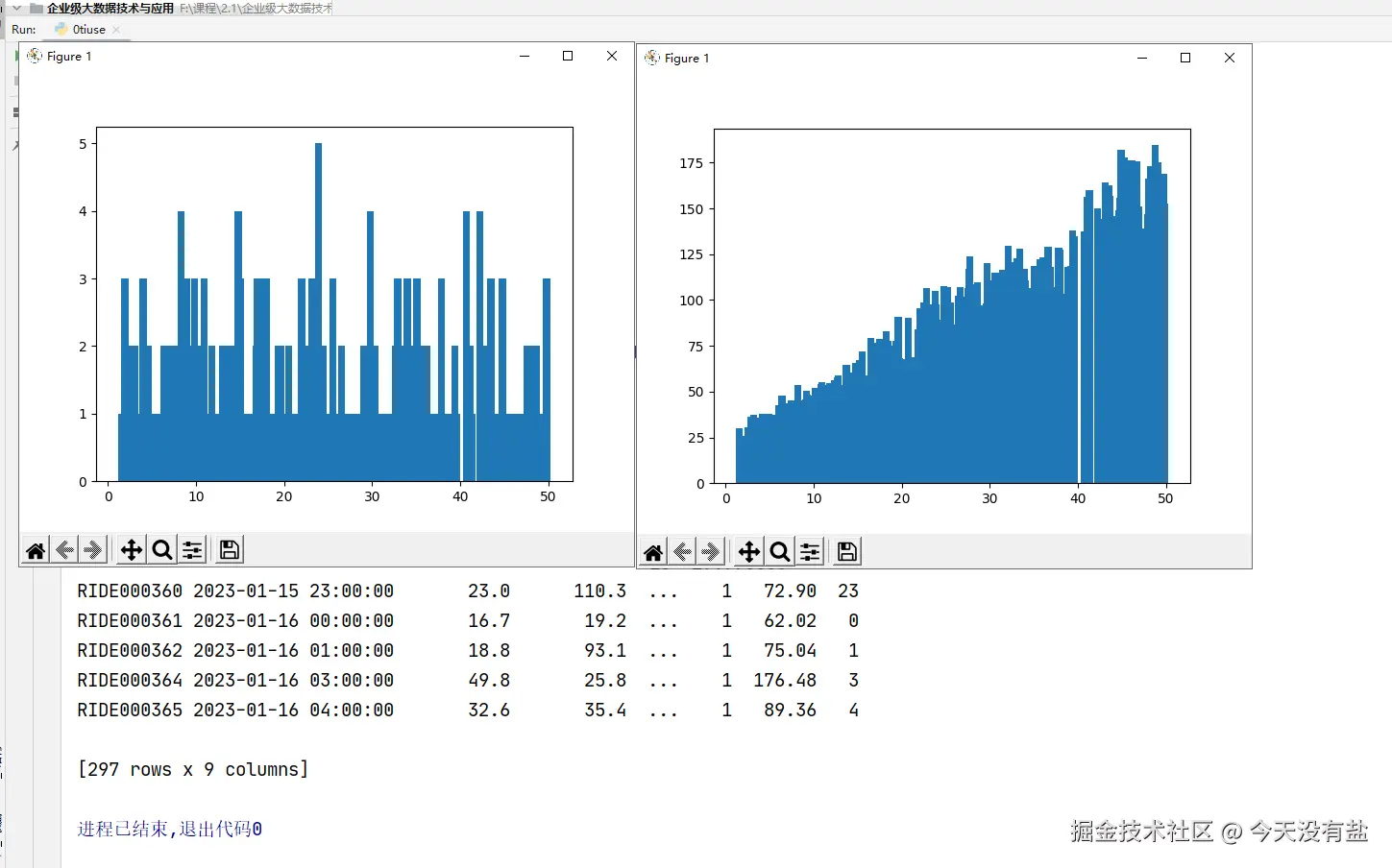
# 4. 按行程距离分组(0-5km、5-10km、10km+),统计每组的订单数和平均总费用,绘制柱状图。
data_taxi = data.groupby('行程距离 (km)').agg({
'订单量':'sum',
'总费用':'mean'
})
plt.bar(data_taxi.index, data_taxi['订单量'])
plt.show()
plt.bar(data_taxi.index, data_taxi['总费用'])
plt.show()
# 5. 保存行程距离 ≥10km 的订单数据为 "长途订单.csv"(不含索引)。
new_data = data[data['行程距离 (km)'] >= 10]
print(new_data)
new_data.to_csv("长途订单.csv")代码结果
代码分析
- 费用计算:通过列运算实现总费用公式,注意单位为元。
- 时间提取 :使用
dt.hour提取小时信息,便于按小时聚合。 - 多指标聚合 :在
groupby后使用agg同时计算多个统计量。 - 分组统计 :直接按数值列分组,但更佳做法是使用
pd.cut进行区间分组。 - 数据筛选与导出 :使用布尔索引筛选长途订单,
to_csv导出时设置index=False可省略索引。
三、体检中心健康数据分析
代码
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 1. 读取 CSV 文件数据,判断是否为高血压(收缩压 ≥140 或舒张压 ≥90),添加 "是否高血压" 列(是 / 否)。
df = pd.read_csv(
"体检数据.csv",
index_col="体检编号"
)
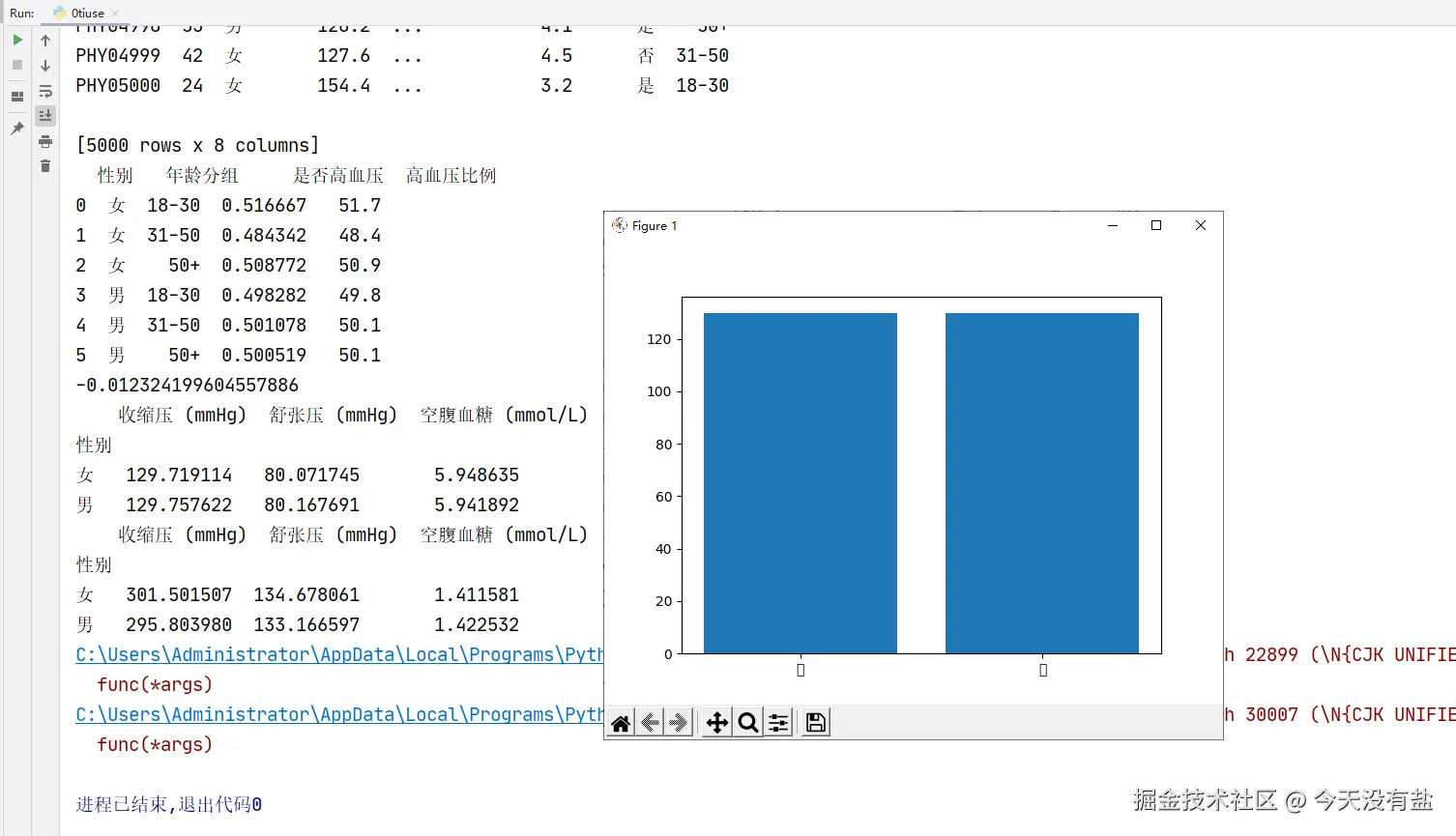
df['是否高血压'] = np.where((df['收缩压 (mmHg)']>=140)|(df['舒张压 (mmHg)'] >= 90), '是', '否')
print(df)
# 2. 按 "性别" 和 "年龄分组"(18-30、31-50、50+)双重分组,统计每组的高血压比例。
df['年龄分组'] = pd.cut(
df['年龄'],
bins=[17, 30, 50, np.inf],
labels=['18-30', '31-50', '50+'],
right=False
)
print(df)
state = df.groupby(['性别', '年龄分组'])['是否高血压'].apply(lambda x:(x == '是').mean()).reset_index()
state['高血压比例'] = state['是否高血压'].round(3) * 100
print(state)
# 3. 计算空腹血糖与胆固醇的相关系数。
corr = df['空腹血糖 (mmol/L)'].corr(df['胆固醇 (mmol/L)'])
print(corr)
# 4. 按性别分组,统计收缩压、舒张压、空腹血糖的均值和方差(使用 agg 函数)。
df_mean = df.groupby('性别').agg({
'收缩压 (mmHg)':'mean',
'舒张压 (mmHg)':'mean',
'空腹血糖 (mmol/L)':'mean'
})
print(df_mean)
df_var = df.groupby('性别').agg({
'收缩压 (mmHg)':'var',
'舒张压 (mmHg)':'var',
'空腹血糖 (mmol/L)':'var'
})
print(df_var)
# 5. 绘制男性和女性的平均收缩压对比柱状图。
plt.bar(df_mean.index, df_mean['收缩压 (mmHg)'])
plt.show()代码结果
代码分析
- 条件判断列 :使用
np.where实现条件判断,生成分类列。 - 区间分组 :
pd.cut可将连续年龄离散化为年龄段,right=False表示左闭右开。 - 比例计算 :在
groupby后使用apply结合 lambda 函数计算高血压比例。 - 多函数聚合 :
agg可同时指定多个统计函数,也可分别计算均值和方差。 - 简单可视化:直接使用分组聚合结果绘制柱状图,直观对比性别差异。
四、健身房运动数据分析
代码
python
import pandas as pd
import matplotlib.pyplot as plt
# 1. 读取 CSV 文件数据,将 "运动日期" 转换为 datetime 格式。
data = pd.read_csv(
"健身房数据.csv",
index_col="用户ID"
)
data['运动日期'] = pd.to_datetime(data['运动日期'])
print(data)
# 2. 按 "运动类型" 分组,统计平均运动时长、平均消耗热量和用户数。
data['用户个数'] = [1 for i in range(data.shape[0])]
state = data.groupby('运动类型 (有氧/力量/综合)').agg({
'运动时长 (分钟)':'mean',
'消耗热量 (大卡)':'mean',
'用户个数':'sum'
})
print(state)
# 3. 提取 "运动日期" 中的月份,统计每月的总运动时长,绘制折线图。
data['月份'] = data['运动日期'].dt.month
month_day = data.groupby('月份')['运动时长 (分钟)'].sum()
plt.plot(month_day.index, month_day)
plt.show()
# 4. 计算运动时长与消耗热量的相关系数。
corr = data['运动时长 (分钟)'].corr(data['消耗热量 (大卡)'])
print(corr)
# 5. 筛选出消耗热量 ≥500 大卡的记录,保存为 "高强度运动记录.csv"(不含索引)。
new_Data = data[data['消耗热量 (大卡)'] >= 500]
print(new_Data)
new_Data.to_csv('高强度运动记录.csv')代码结果

代码分析
- 日期处理 :
pd.to_datetime将字符串转为时间格式,便于提取月份。 - 用户计数 :通过添加值为1的列实现计数,也可直接用
size()统计。 - 折线图适用场景:月度趋势数据适合用折线图展示变化趋势。
- 相关性分析:直接计算两数值列的相关系数,评估线性关系强度。
- 数据筛选与导出:筛选高强度记录并导出为 CSV,便于后续分析。
总结
通过这四个完整的数据分析案例,我们实践了以下核心技能:
- 数据读取与预处理:使用 pandas 读取 CSV、处理日期、添加衍生列。
- 数据分组与聚合 :灵活运用
groupby进行单维度、多维度和条件分组统计。 - 统计计算:掌握均值、总和、方差、相关系数等常用统计量的计算。
- 数据可视化:使用 matplotlib 绘制柱状图、折线图,直观展示数据分布与趋势。
- 数据导出:将处理结果保存为新文件,便于后续使用或分享。
提示:实际运行时请确保 CSV 文件与代码在同一目录,或使用完整文件路径。若中文显示异常,可调整 matplotlib 字体设置或使用英文标签。