I/O模型
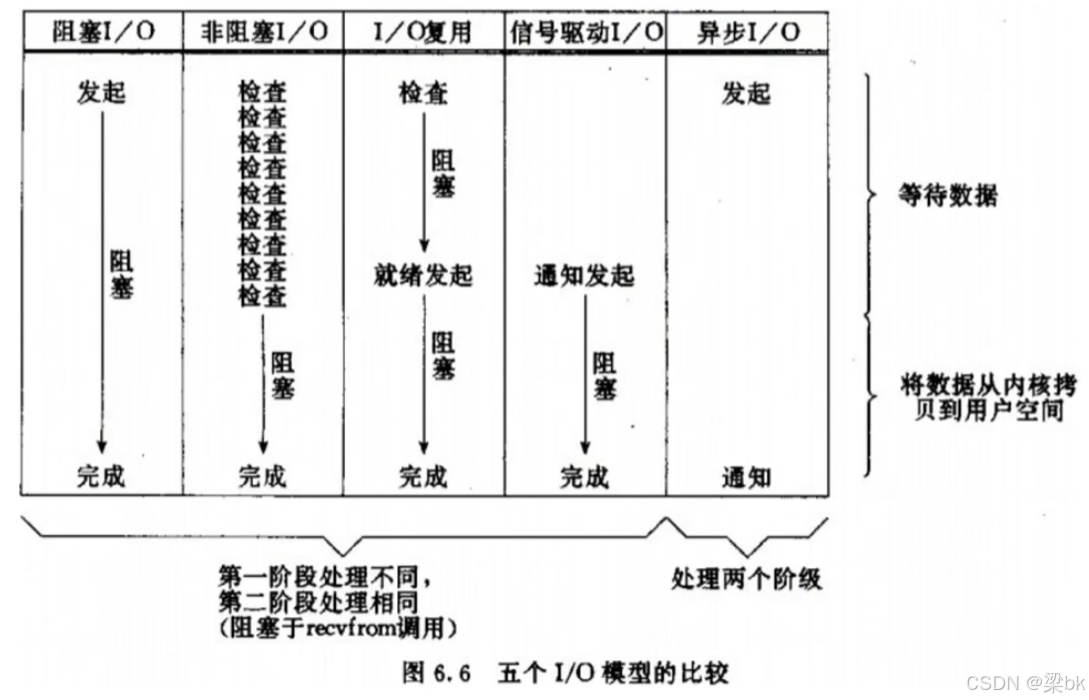
IO模型主要分为5类,在这里我将讲解前三类I/O模型
一、阻塞式 IO(Blocking IO)
定义(非常好理解)
阻塞 IO = 调用 IO 时,会一直等,等数据到达后才继续执行。
类似生活中的场景:
你去排队买奶茶,轮到你后,你对店员说:
"我要一杯奶茶。"
然后你不走,站在原地等奶茶做好。
在等待的时候,你 不能干别的事,只能等。
在代码层面的体现
伪代码:
c
int n = read(fd, buf, size); // 如果没有数据,就一直卡住如果 fd 没有数据:
- 程序就 卡在 read 那一行
- CPU 不执行其他任务
- 整个线程被"阻塞"
阻塞 IO 的缺点:
-
线程浪费
一个连接没数据,线程就一直被卡住。
-
扩展性差
要支持 10000 个连接,就需要 10000 个线程(或多进程)。
这对于 Redis 的高性能需求来说肯定不行。
二、非阻塞式 IO(Non-blocking IO)
定义
非阻塞 IO = IO 立即返回,不等数据。
还是用奶茶店的例子:
你对店员说:
"我要奶茶。"店员说:
"还没好,你回去等会再来问吧。"于是你每隔几秒来问:
"好了没?好了没?好了没?"
这就是非阻塞 IO:
- 不等数据
- 马上返回
- 自己不断轮询(polling)
代码表现
c
fcntl(fd, F_SETFL, O_NONBLOCK); // 设置 fd 非阻塞
int n = read(fd, buf, size);
if (n == -1 && errno == EWOULDBLOCK) {
// 没数据,立即返回
}非阻塞 IO 是"主动不断问",所以会:
- CPU 忙等(不停调用 read)
- 效率低
- 浪费 CPU
这叫做 轮询(busy polling) → 性能很差。
三、IO 多路复用(IO Multiplexing)
定义
IO 多路复用 = 一个线程同时"监听"多个 socket,当哪个有数据,就告诉你处理它。
核心思想:
不要一个线程负责一个连接,而是一个线程负责很多连接。
还是奶茶店例子:
类比理解(最经典)
多个顾客(多个 socket)要取奶茶,
但你不用一个一个地问:
- 顾客 1:奶茶好了吗?
- 顾客 2:奶茶好了吗?
而是:
店员拿个扩音器喊:
"xxx 的奶茶好了!"
你听到后再去取。
你不再轮询所有顾客,而是由"扩音器"(内核)告诉你谁准备好了。
技术概念
Linux 提供几个事件通知机制:
| IO 多路复用方式 | 描述 |
|---|---|
| select | 最古老,性能差 |
| poll | 比 select 稍好 |
| epoll | Linux 高性能 IO,多用于 Redis、Nginx |
Redis 使用的是:
➡ epoll(IO 多路复用) + 单线程事件循环
epoll 模型的核心流程
1. 注册:告诉内核需要监听哪些 fd
2. 阻塞等待:直到某个 fd 有事件(读/写)
3. 内核返回"就绪列表"
4. 程序逐个处理伪代码(Redis 类似):
c
epoll_fd = epoll_create();
epoll_ctl(epoll_fd, ADD, fd1);
epoll_ctl(epoll_fd, ADD, fd2);
epoll_ctl(epoll_fd, ADD, fd3);
while (true) {
ready = epoll_wait(epoll_fd); // 阻塞直到至少一个 fd 有事件
for fd in ready:
handle(fd); // 处理就绪事件
}这就是 Redis 单线程能支撑十万连接的根本原因。
四、三者差异总结(非常关键)
下面是最容易理解的区别:
| 模型 | 行为 | 突出特点 |
|---|---|---|
| 阻塞 IO | read 时会卡住 | 线程浪费 |
| 非阻塞 IO | read 不等,立即返回,需要循环 | CPU 浪费 |
| IO 多路复用 | epoll 统一监听所有 fd,有事件再通知 | 高性能、单线程可处理大量连接 |
总结一句话:
阻塞 IO:等
非阻塞 IO:问
IO 多路复用:内核告诉你哪个准备好了,你再去处理
五、配合图示的最终理解(超级关键)
阻塞 IO:
read(fd)
没有数据 → 线程卡死非阻塞 IO:
read(fd)
没有数据 → 马上返回
程序循环不断 read → CPU 高占用IO 多路复用:
epoll_wait()
只是监听,不占 CPU
有数据时返回一个"就绪列表"
程序处理这些就绪的连接redis网络模型基本概念
一、什么是 fd(文件描述符)?
fd = 文件描述符(File Descriptor)
在 Linux 里:
一切资源都被抽象成文件,包括 socket。
当 Redis 和客户端建立 TCP 连接时:
fd = socket()这个 fd 是一个整数,例如:
3
12
18表示这个连接在 Redis 进程中的"编号",用于定位内核中的 socket 资源。
换句话说:
fd 就是 Linux 给每个网络连接分配的身份证号码。
Redis 只需要记住这个数字,就能读写这条连接上的数据。
生活类比
你去医院看病会拿到一个号码:
取号:37 号医院不关心你是谁,只根据"编号"决定服务顺序。
fd 就是 socket 的编号。
二、什么是 epoll_wait?
epoll_wait 属于 Linux 的 IO 多路复用 API。
Redis 在启动时会创建一个 epoll 句柄:
c
epfd = epoll_create()然后把所有客户端连接 fd 加进去,让 epoll 监控它们:
c
epoll_ctl(epfd, ADD, client_fd)之后 Redis 会调用:
c
epoll_wait(epfd, ...)作用就是:
阻塞等待,看哪些 fd 上有事件(读/写)发生。
如果没有 fd 准备好,Redis 会睡眠,不占 CPU。
生活类比:排队取餐
你告诉店员:
"我点了 3 份餐,当我哪个餐做好时,叫我。"
店员(内核)会:
- 盯着你的 3 份餐(对应多个 fd)
- 哪份先做完,就直接通知你(epoll_wait 返回)
你无需每秒自己跑去问:
"好了没?好了没?好了没?"
这就是 epoll 的意义。
三、为什么客户端发送命令后,阻塞在 epoll_wait 的 Redis 会立刻醒来?
现在我们讲最关键的部分:
为什么客户端一发送命令,epoll_wait 就返回 fd 可读事件?
因为 epoll_wait 监控的是 socket 的 数据缓冲区状态。
当客户端通过 TCP 发送数据(命令)时:
数据进入内核 socket 的接收缓冲区
↓
内核将此 socket 标记为"可读"
↓
内核把这个事件加入 epoll 的就绪队列
↓
epoll_wait 被唤醒并返回这个 fd所以 epoll_wait 并不神奇:
- 它不主动轮询
- 它只是内核的"通知机制"
- 当 socket 数据到了 → 内核叫醒 epoll_wait
再用生活例子解释一次
你坐在候餐区(Redis 在执行 epoll_wait)。
厨房(内核)在监控你的订单状态(socket)。
当你的餐做好了(客户端发送命令 → 数据到达内核):
- 不需要你盯着
- 厨房自动通过叫号器(epoll)通知你
- 你从等待状态醒来(epoll_wait 返回)
这就是为什么 Redis 不需要轮询,却能高性能处理成千上万连接。
四、整个流程图
客户端发送命令
↓
数据到达服务器内核的 socket 缓冲区
↓
内核把 fd 标记为 READABLE
↓
epoll 内部的就绪链表加入这个 fd
↓
正在阻塞的 epoll_wait 立即返回
↓
Redis 主线程被唤醒
↓
调用 readQueryFromClient 读取命令
↓
执行命令 → 写结果 → 写事件再加一个图示:
client ---> kernel socket buffer ---> epoll ---> Redis每一步都有内核参与处理。
Redis 网络模型核心
一、Redis 主线程的整体结构(单线程 Reactor 模型)
Redis 的网络处理模型可以归纳为一句话:
Redis 使用单线程 + IO 多路复用(epoll),主线程统一处理所有客户端的读写事件与命令执行。
Redis 的主线程中有一个事件循环:
aeEventLoop它负责:
- 监听客户端 fd(socket)
- 处理读事件(读客户端命令)
- 执行命令(SET/GET/ZADD/...)
- 处理写事件(将结果返回客户端)
- 执行定时任务(如过期键清理)
主循环伪代码(简化):
c
while (!stop) {
int num = epoll_wait(监听所有FD);
for each ready_fd:
调用相应的事件处理器(读 or 写)
执行时间事件(定时清理、过期处理等)
}二、Redis 如何处理"读事件"(客户端发来命令)
1)客户端发送命令 → fd 变为"可读"
例如客户端发送:
SET name jackLinux 内核会把事件写入 epoll 的就绪列表:
fd 可读 → epoll_wait 返回2)Redis 调用 readQueryFromClient() 读取数据
处理器代码:
c
readQueryFromClient()Redis 从 socket 读取数据:
- 读入 querybuf(命令缓冲区)
- 支持管道(pipeline)
- 一次读多个命令
伪代码:
c
nread = read(fd, client->querybuf)如果读到数据 → 进入下一阶段
如果读到 0(连接关闭) → 关闭客户端
如果出错 → 删除客户端
3)Redis 将命令解析(协议解析)
Redis 使用 RESP 协议,比如:
*3
$3
SET
$4
name
$4
jackRedis 使用:
processInputBuffer()把 querybuf 中的命令解析成:
argv[] = ["SET", "name", "jack"]
argc = 34)命令分发(查命令表)
Redis 有一个命令表 commandTable:
SET → setCommand()
GET → getCommand()
ZADD → zaddCommand()解析后调用对应的函数。
伪代码:
c
cmd = lookupCommand(argv[0])
cmd->proc(client) // 执行命令5)执行命令(真正的业务逻辑)
例如:
SET key valRedis 会:
- 计算 key 的哈希
- 修改 dict 中的内容
- 更新过期时间
- propagate 到 AOF / Replication
- 标记脏数据 dirty++
执行完成后,将结果写入 client->buf(写缓冲区)
例如:
+OK6)为客户端注册写事件
当写缓冲区不为空时:
aeCreateFileEvent(loop, fd, AE_WRITABLE, sendReplyToClient)➡ 意味着:等这个 fd 能写时,我就写回结果
读事件流程结束。
三、Redis 如何处理"写事件"(返回命令结果)
1)fd 可写时,触发写事件处理器
处理器:
sendReplyToClient()Redis 会像流水线一样从写缓冲区取数据:
c
write(fd, client->buf)如果一次写不完:
- 缓冲区未清空
- 下次继续触发写事件
2)写完后取消写事件监听(非常关键)
当缓冲区全部写完:
aeDeleteFileEvent(loop, fd, AE_WRITABLE)为什么要删除?
因为:
- 可写事件几乎 ALWAYS 触发
- 不删除会导致 CPU 100% 空转
Redis 非常聪明:
写事件只在有数据要写时才监听。
四、整体流转图(最重要)
客户端
|
发送命令(SET)
|
fd 可读
↓
epoll_wait 返回
↓
readQueryFromClient
↓
processInputBuffer
↓
命令执行(SET)
↓
结果写入 client->buf
↓
注册写事件 AE_WRITABLE
↓
epoll_wait 等待 fd 可写
↓
sendReplyToClient
↓
清理缓冲区,删除写事件
↓
返回结果给客户端Redis 把每一步做到极致,所以性能极高。
五、配合"单线程"理解 Redis 高性能
即便 Redis 单线程,也能处理大量请求,因为:
- epoll_wait 过滤掉无意义 IO
- 所有命令都是内存操作(快)
- 写事件只在需要时监听
- Redis 避免锁竞争(单线程无锁)
所以 Redis 每秒可以处理十万级请求。
大白话理解
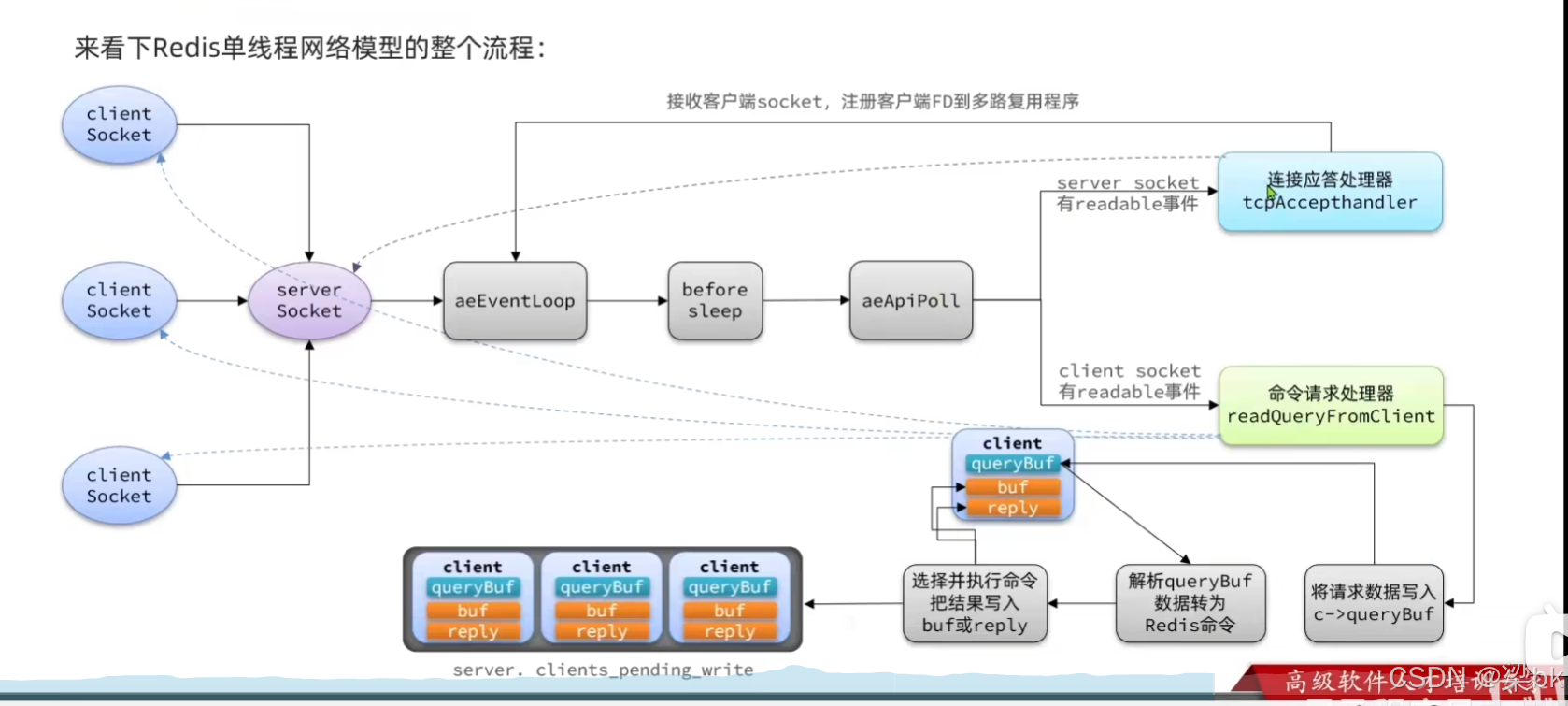
首先客户端和redis服务器建立socket链接,redis使用fd来描述该socket链接;同时在redis服务器有一个不断循环的事件aeEventLoop监听该socket是否发送命令,epoll_wait就在aeEventLoop不断循环;当客户端发送了一个命令之后,fd 变为可读,表示客户端发来命令,epoll_wait监听到fd可读后,就使用readQueryFromClient()来读取socket中发来的命令,使用processInputBuffer()来解析命令,lookupCommand()和call()来执行命令,执行完之后,将fd注册为可写,epoll_wait监听到fd可读后,返回结果给客户端。
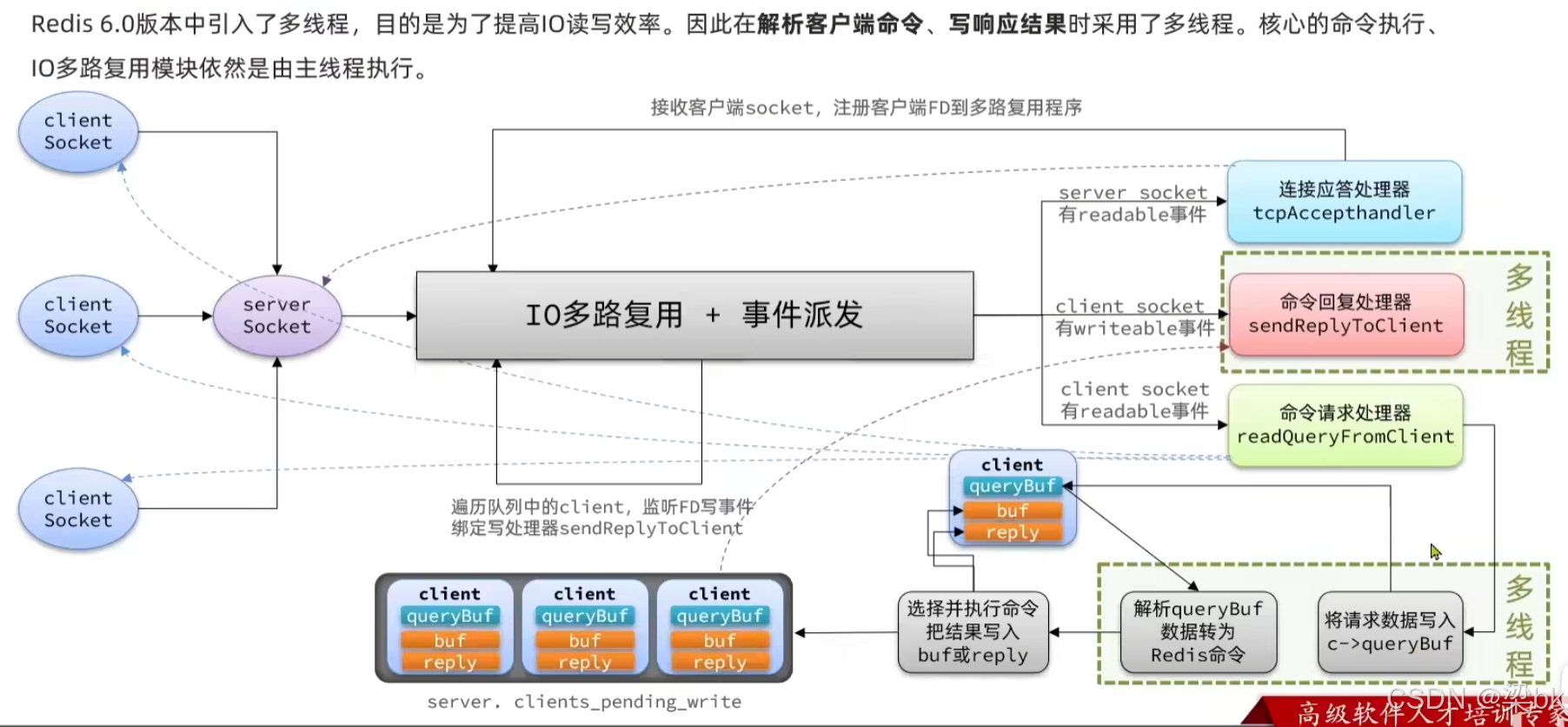
多线程I/O
- Redis 6.0 的 IO 多线程是怎么加入主线程模型的?
Redis 一直以 单线程 著称,但从 Redis 6.0 开始,加入了 多线程 IO(仅用于网络读写),以解决高并发场景下网络瓶颈问题。
但注意:
核心结论(记住)
Redis 6.0 的多线程只用于 IO(网络读 & 网络写),不用于命令执行。
主线程依然负责命令执行(逻辑处理)。
即:
多线程 = 提升"收数据 / 发数据"的吞吐
单线程 = 保持"命令执行"的原子性与简单性
一、为什么 Redis 要引入 IO 多线程?
Redis 单线程瓶颈不是 CPU(CPU 处理内存操作很快)
真正的瓶颈是:
大量客户端接入时的网络读写(read/write 系统调用)
read/write 会消耗大量时间,尤其是:
- pipeline 批量命令
- 大量客户端同时读写
- 高 QPS 网络流量
因此 Redis 6.0 把网络层(读取请求、发送响应)改成多线程加速。
二、Redis 6.0 网络模型:单线程 + 多线程(混合模型)
完整结构如下:
┌───────────────┐
│ 主线程 │
│ epoll_wait │
└───────┬────────┘
│
▼
fd 可读事件到来
│
┌───────┴────────┐
│ 多线程读取请求 │ ← 6.0 新增(并发 read)
└───────┬────────┘
│
▼
主线程执行命令(单线程)
│
┌───────┴────────┐
│ 多线程发送响应 │ ← 6.0 新增(并发 write)
└───────┬────────┘
│
▼
epoll_wait 下一轮循环主线程永远做:
- epoll_wait(事件监听)
- 解析命令调用执行函数
- 操作内存数据结构(SET/GET/ZADD...)
- 复制/持久化等内部逻辑
多线程只做两件事:
- read 请求:把 socket 的数据读到 querybuf
- write 响应:把 reply 写回 socket
三、Redis 6.0 IO 多线程的工作流程(详细图解)
假设有客户端发送 10 万条命令,流程如下:
① epoll_wait 监听到几个 fd 可读(主线程)
主线程做:
collect clients with readable data把这些"准备好读数据的客户端"记录下来:
server.clients_pending_read然后把这些 client 分配给 IO 线程。
② 多线程开始读数据(读取 querybuf)
线程池中的每个线程负责一部分 client:
线程 1 → 处理 client1、client2、client3
线程 2 → 处理 client4、client5
线程 3 → 处理 client6、client7 ...线程执行函数:
c
readQueryFromClientMultiThreaded()任务:
- read() 从 socket 读取数据
- 填充 client->querybuf
但注意:
命令解析 NOT 在这里做
因为命令解析会修改 client 状态,不适合多线程。
③ 多线程读完 → 主线程开始解析命令 & 执行命令
主线程开始处理所有"读完数据的 client":
processInputBuffer()
lookupCommand()
call()这一部分仍是:
单线程
不加锁
保证命令原子性
保证 Lua、事务、键空间操作一致性
保持 Redis 传统优势。
④ 命令执行结束 → 主线程把准备写的 client 发给 IO 线程池
Redis 主线程在执行完命令后,把写缓冲区中有数据的客户端放入:
server.clients_pending_write并交给 IO 线程。
⑤ 多线程并发 write 回客户端
IO 线程执行:
c
sendReplyToClientMultiThreaded()任务:
- write() 写 socket
- 清空出站缓冲区
减少主线程在 write 上的等待时间。
⑥ 主线程继续下一轮事件循环
epoll_wait等待下一批命令。
四、多线程的数量如何配置?
在 redis.conf 中:
io-threads 4默认是 1(即不开启多线程)。
一般推荐:
CPU 核心数 - 2例如 8 核:
io-threads 6五、Redis 6.0 IO 多线程的实现原则(非常重要)
Redis 做到:
不改变原有"命令执行单线程"
保持数据结构的无锁访问、超高性能。
多线程只处理"耗时且可并行"的 read/write
网络 IO 占用 CPU 多 → 可多线程并行。
不引入锁竞争
中间环节 carefully 设计,尽量避免锁。
六、为什么 Redis 不把命令执行也多线程化?
因为 Redis 的命令执行涉及:
- dict(哈希表)操作
- skiplist
- quicklist
- 过期策略
- 主从复制
- AOF/RDB
- 键空间修改事件
这些结构都是无锁设计的,一旦多线程执行:
- 需要给每个数据结构加锁
- 性能会大幅下降
- 代码复杂度增加 10 倍
- 兼容性会变差(Lua、事务、脚本等)
Redis 采取的路线是:
用多线程扩展 IO 吞吐,而不是破坏核心的"单线程内存操作"优势。
七、Redis 6.0 IO 多线程完整流程图(建议收藏)
┌─────────────────────────┐
│ 主线程 aeLoop │
│ epoll_wait监听事件 │
└───────────┬──────────────┘
│ fd可读
▼
┌──────────────────┐
│ IO线程读取socket │ ← 多线程读(read)
└───────────┬────────┘
│
▼
┌──────────────────┐
│ 主线程解析+执行命令 │ ← 单线程执行命令
└───────────┬────────┘
│
▼
┌──────────────────┐
│ IO线程写回客户端 │ ← 多线程写(write)
└───────────┬────────┘
│
▼
回到 aeEventLoop八、总结
Redis 6 的 IO 多线程流程:
- 主线程 epoll_wait 得到可读 fd
- 多个 IO 线程并发 read(读取客户端命令)
- 主线程解析命令 + 执行命令(单线程)
- 多个 IO 线程并发 write(返回结果)
- 主线程继续进入 epoll_wait
核心思想:
多线程加速网络 IO;单线程保障逻辑执行的一致性与高性能。