一、背景
知识库一般通过本场景的人工外呼获得专有知识,以及从其他场景的知识库迁移通用知识来人工构建的。 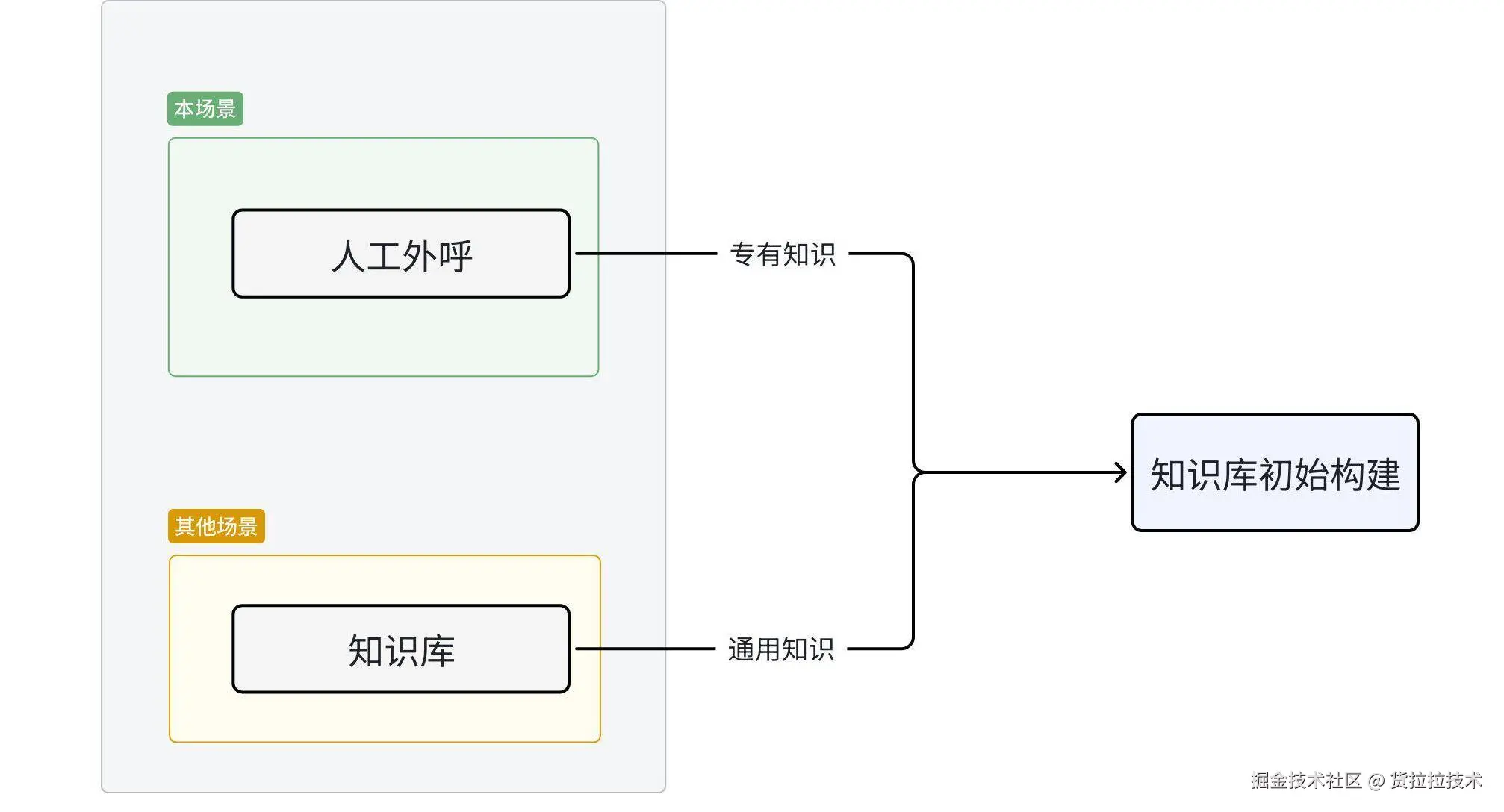
图1 知识库初始构建
初始构建的知识库一般包含三部分:相似问法、意图、标准话术(如图2所示);知识库在线上使用时,是将RAG召回的意图、相似问法、标准话术拼接到prompt中,由LLM生成相应的话术,所以知识库意图、相似问法、标准话术的映射关系是否准确尤为重要。
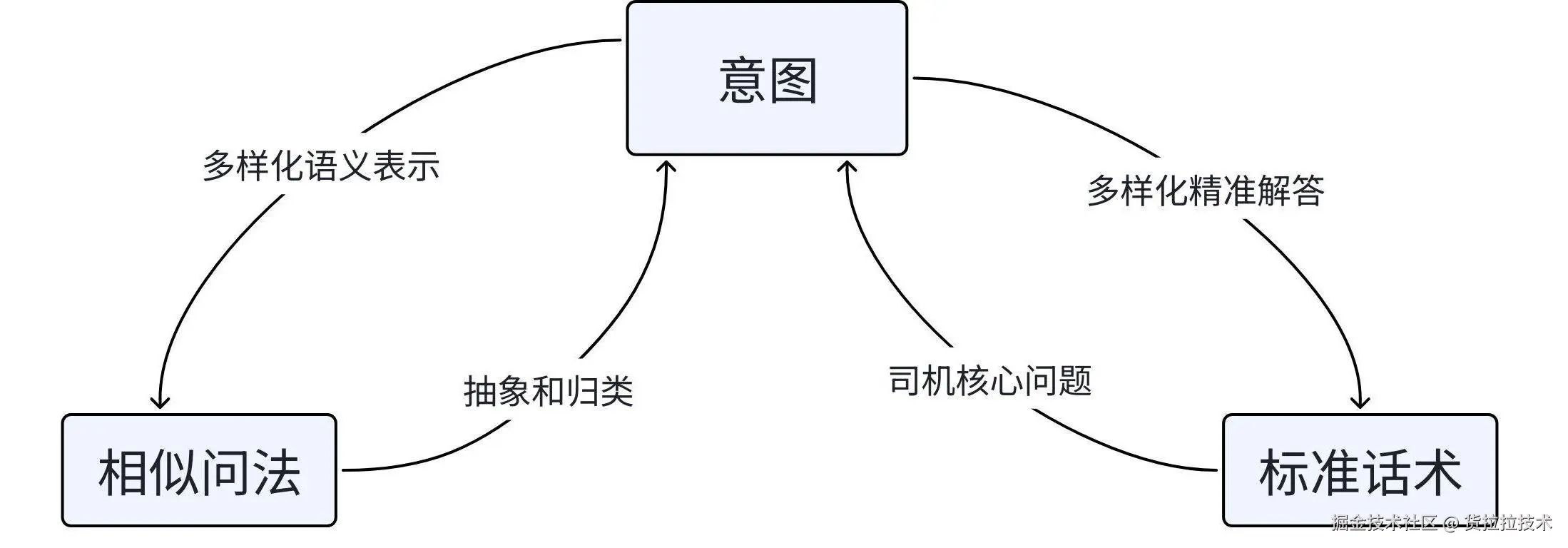
图2 相似问法、意图、标准话术的映射关系
示例:
相似问法:
你们帮我订阅这个路线需不需要收费,你说?
你先说订阅这个收不收费。
意图:询问订阅路线是否收费
标准话术:
自动订阅是不收费的。
不收费的。
自动订阅是完全免费的,不收您钱。
由于知识库的初始构建依赖于人工,由于人力资源的不足,知识库一般存在以下三类问题:
- 意图名定义不清晰 ==> 导致LLM生成话术可能不合理 ==> 需重新定义意图名
图中相似问法实际语义是【质疑来电的真实性】,使用【来电目的】作为意图名,不能准确概括司机语义,进而导致回复话术不合理。
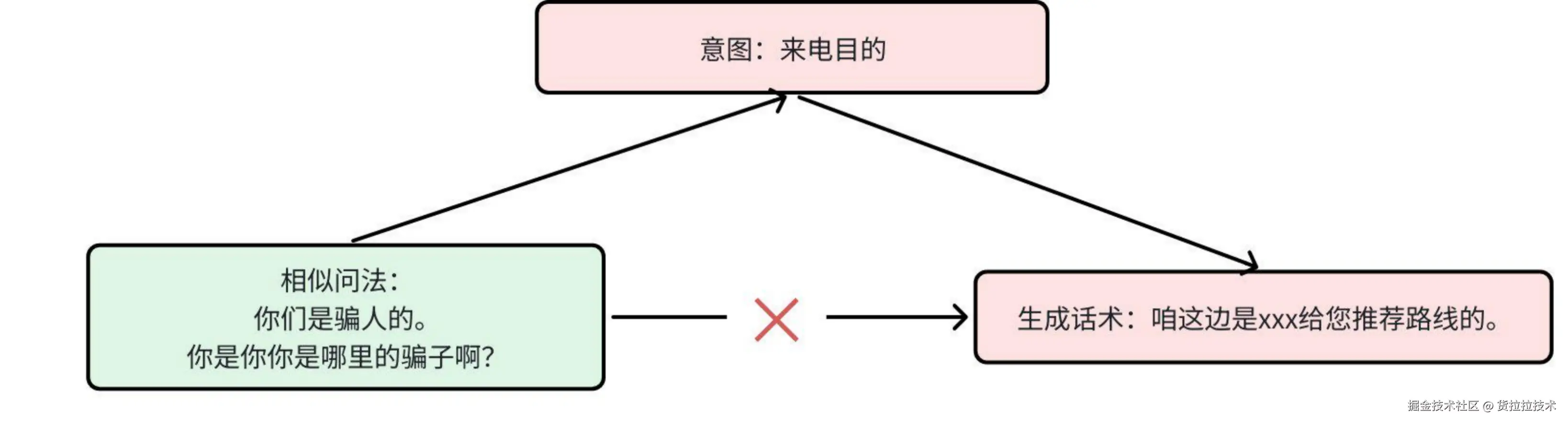
图3 意图名定义不清晰示例
- 相似问法与意图话术不匹配 ==> 导致LLM答非所问 ==> 需对相似问法重新归类
图中相似问法被错分为【车子有货了】,LLM将参考该意图的话术,进而导致答非所问。
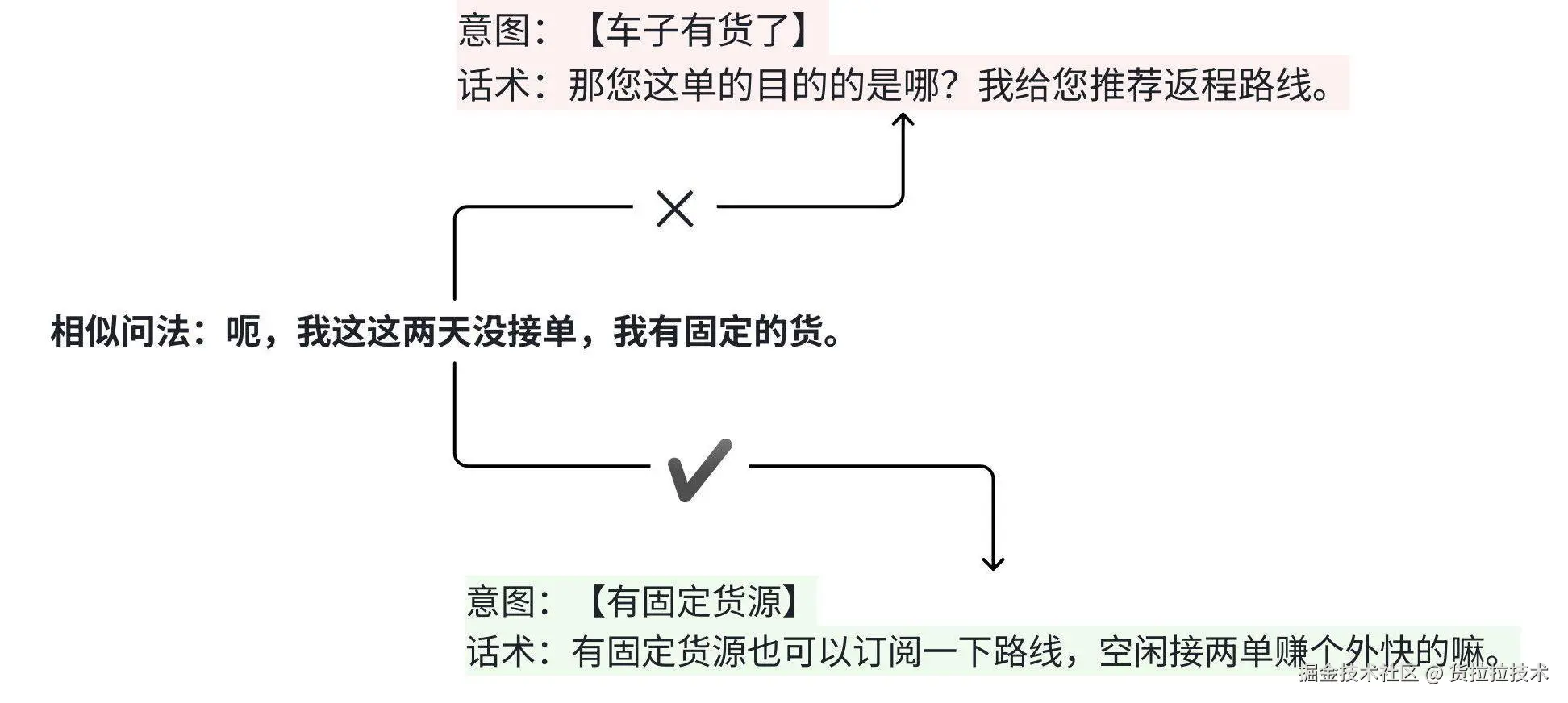
图4 相似问法与意图话术不匹配示例
- 意图过于概括 ==> 标准话术回复不够精准 ==> 需意图细拆
图中相似问法中包含若干种司机没出车的语义如:在住院、在老家、在修车等。
使用统一的话术无法精准的回复司机,需要对意图进行细拆。
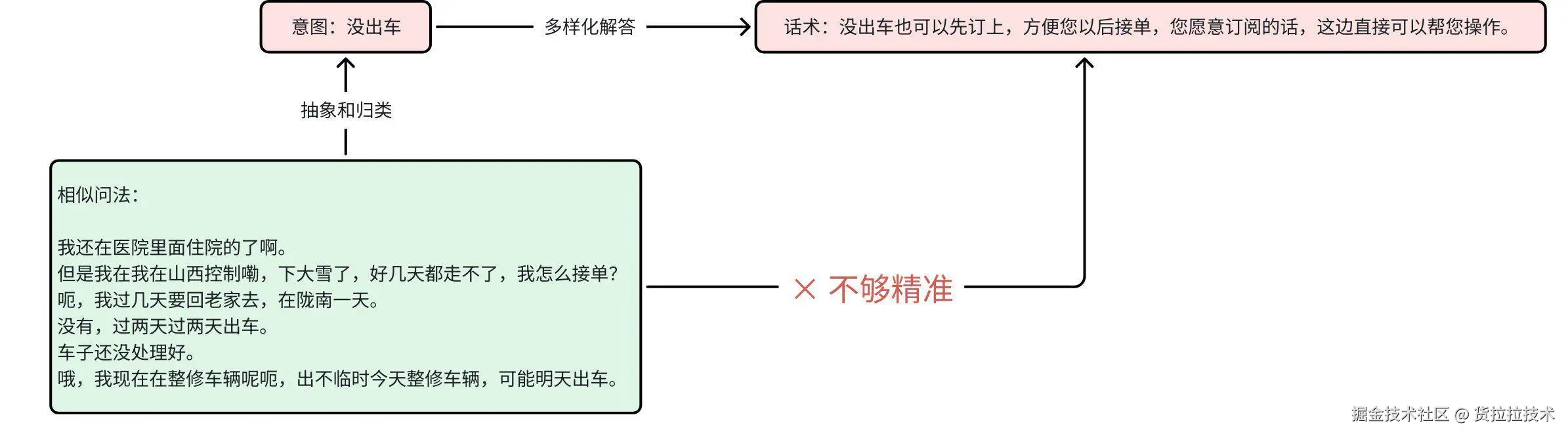
图5 意图过于概括示例
二、解决方案
知识库清洗业界一般有两种方案:
-
方案一:嵌入模型+聚类
-
方案二:大模型语义理解
2.1 方案一:嵌入模型+聚类
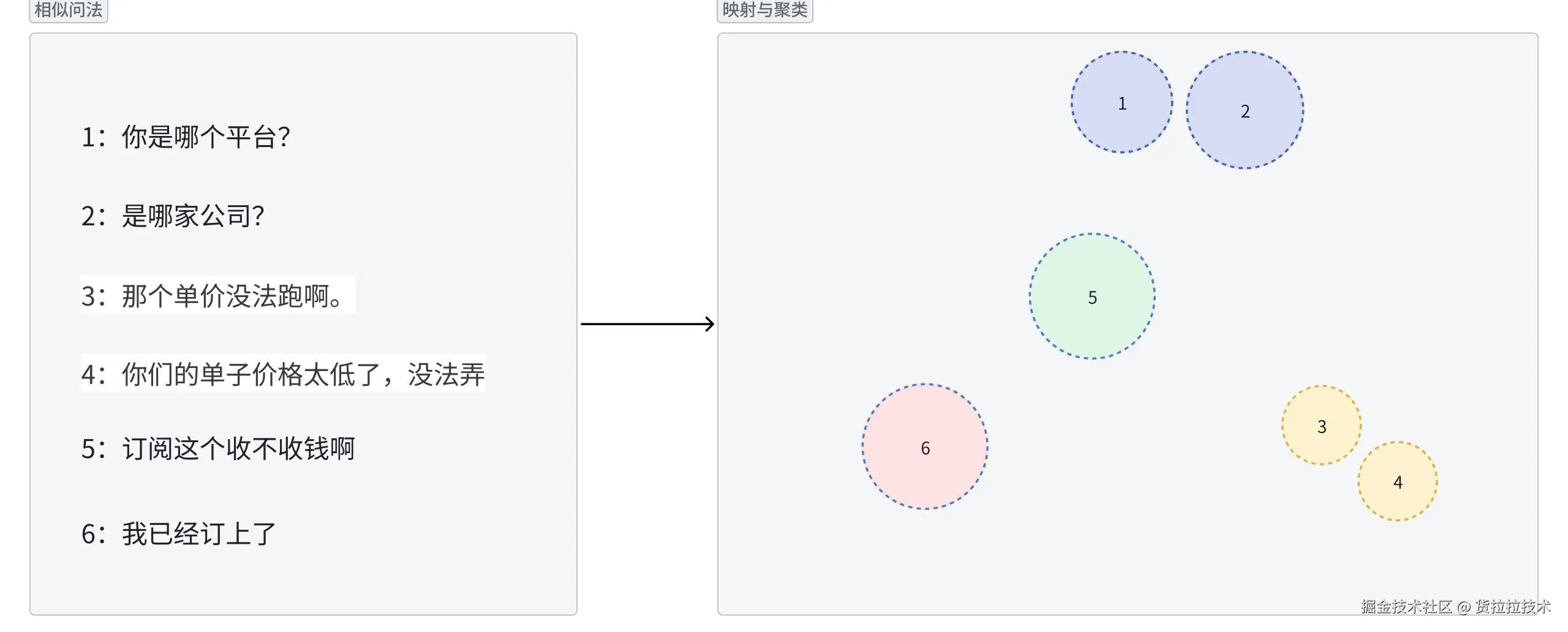
使用嵌入模型将相似问法映射到高维向量空间,使用聚类算法清洗知识库
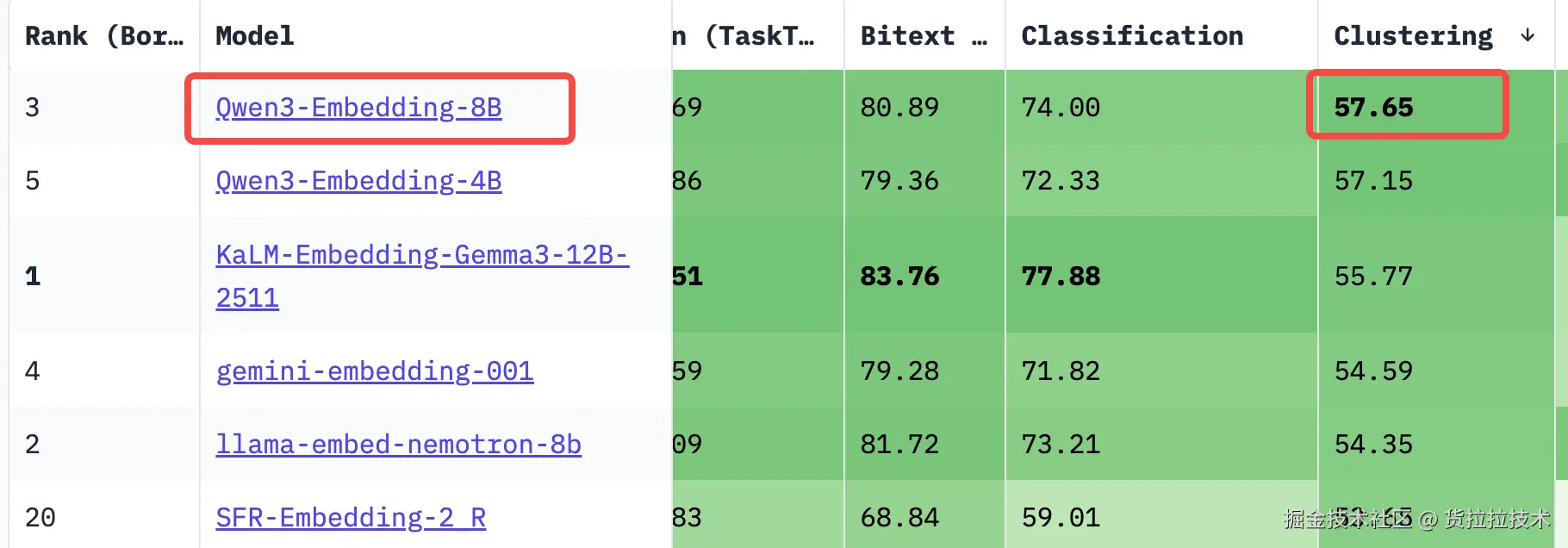
 经调研,Qwen3-Embedding-8B在聚类任务中评分最高,因此模型选择Qwen3-Embedding-8B。
经调研,Qwen3-Embedding-8B在聚类任务中评分最高,因此模型选择Qwen3-Embedding-8B。
实践过程中,因Qwen3-Embedding-8B 语义理解程度有限,聚类算法存在类别不可控/类别语义未知的问题,导致相似问法重新归类准确率极低、意图细分过细,最终采用方案二清洗。
2.2 方案二:大模型语义理解
利用大模型的语言理解能力,辅助人工进行知识库清洗,提高清洗效率

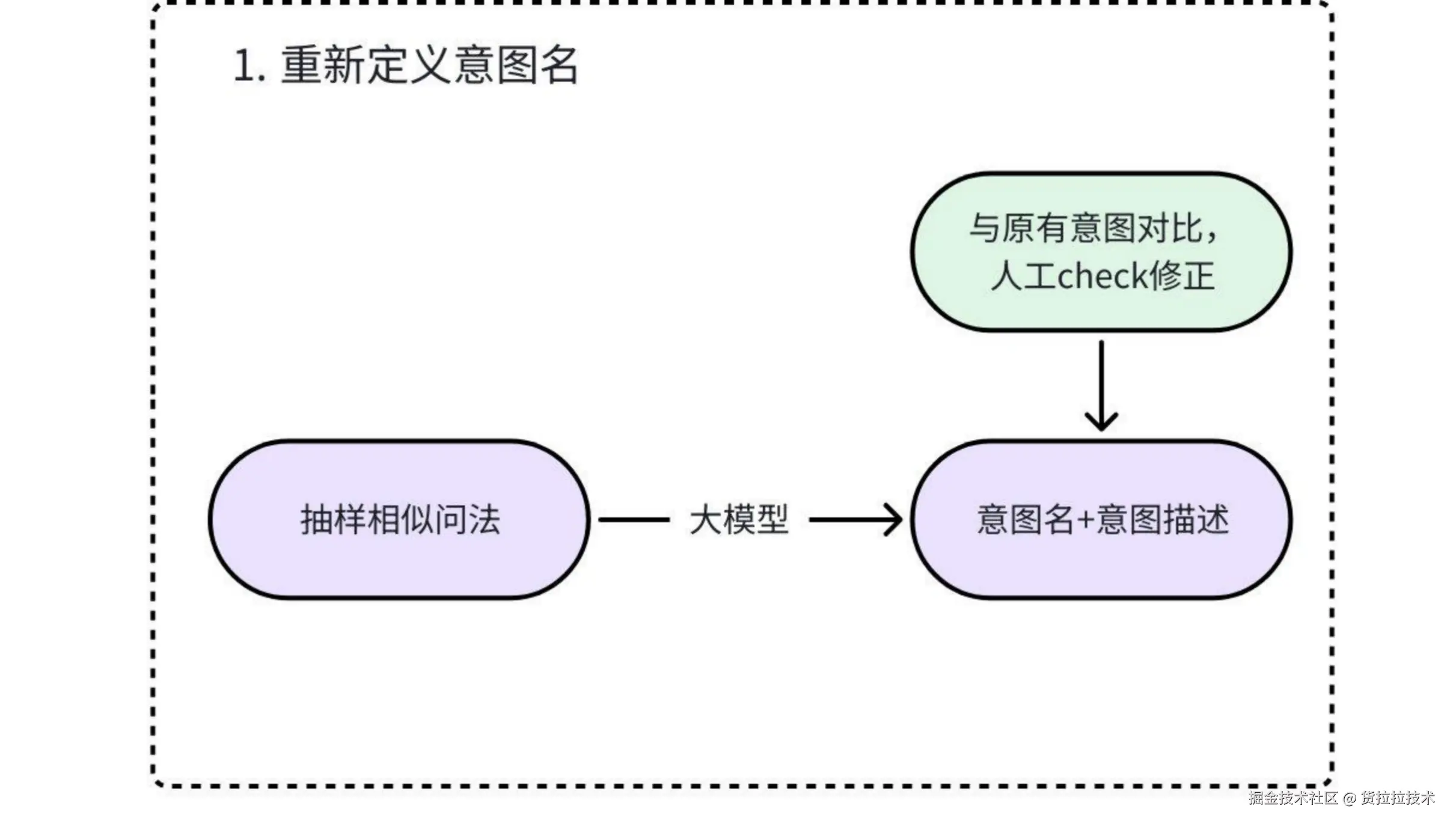
1. 重新定义意图名
结合大模型和业务知识对意图名进行优化
css
a. 少量样本初始化意图名:
抽取少量样本并使用大模型初始化意图名称和意图描述。
b. 人工check:
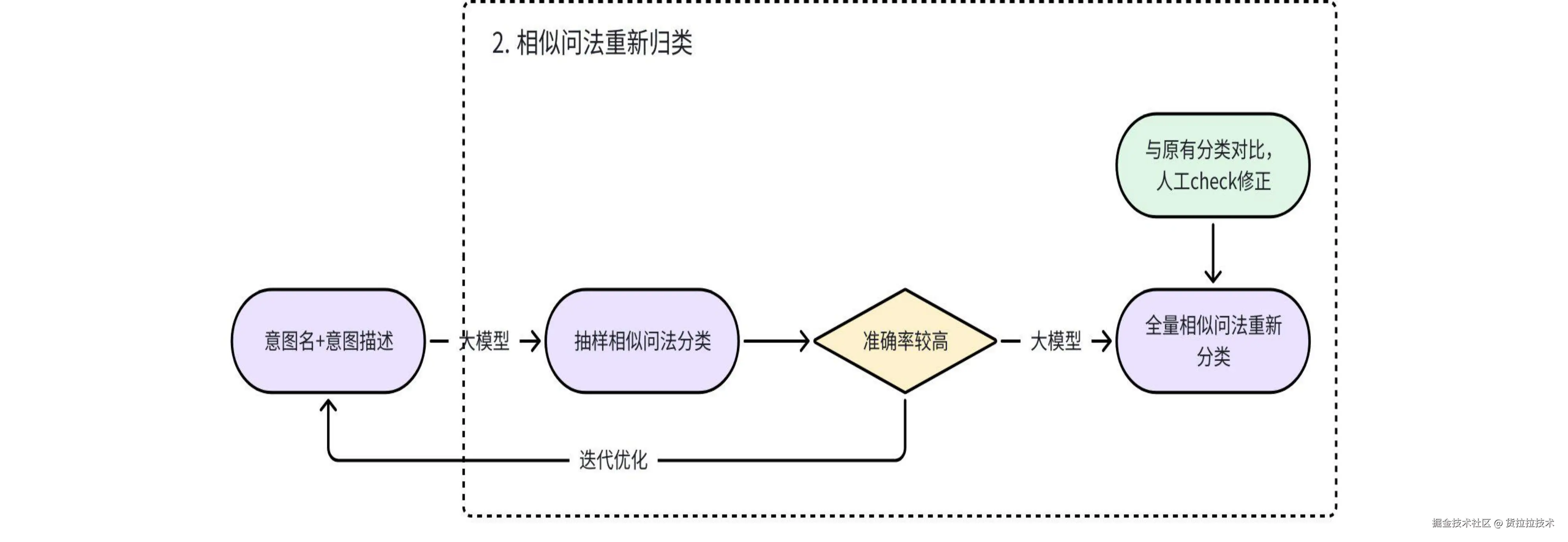
根据业务知识对大模型生成的初始化意图名称进行二次校验,以得到能够精准概括相似问法语义的意图名称。2. 相似问法重新归类
使用大模型+prompt的方式对相似问法重新归类,因此prompt中意图的描述就极为重要;
css
a. 少量样本迭代优化意图描述:
抽样部分相似问法,不断优化迭代prompt中意图的描述,以提高大模型分类准确性。
b. 全量分类:
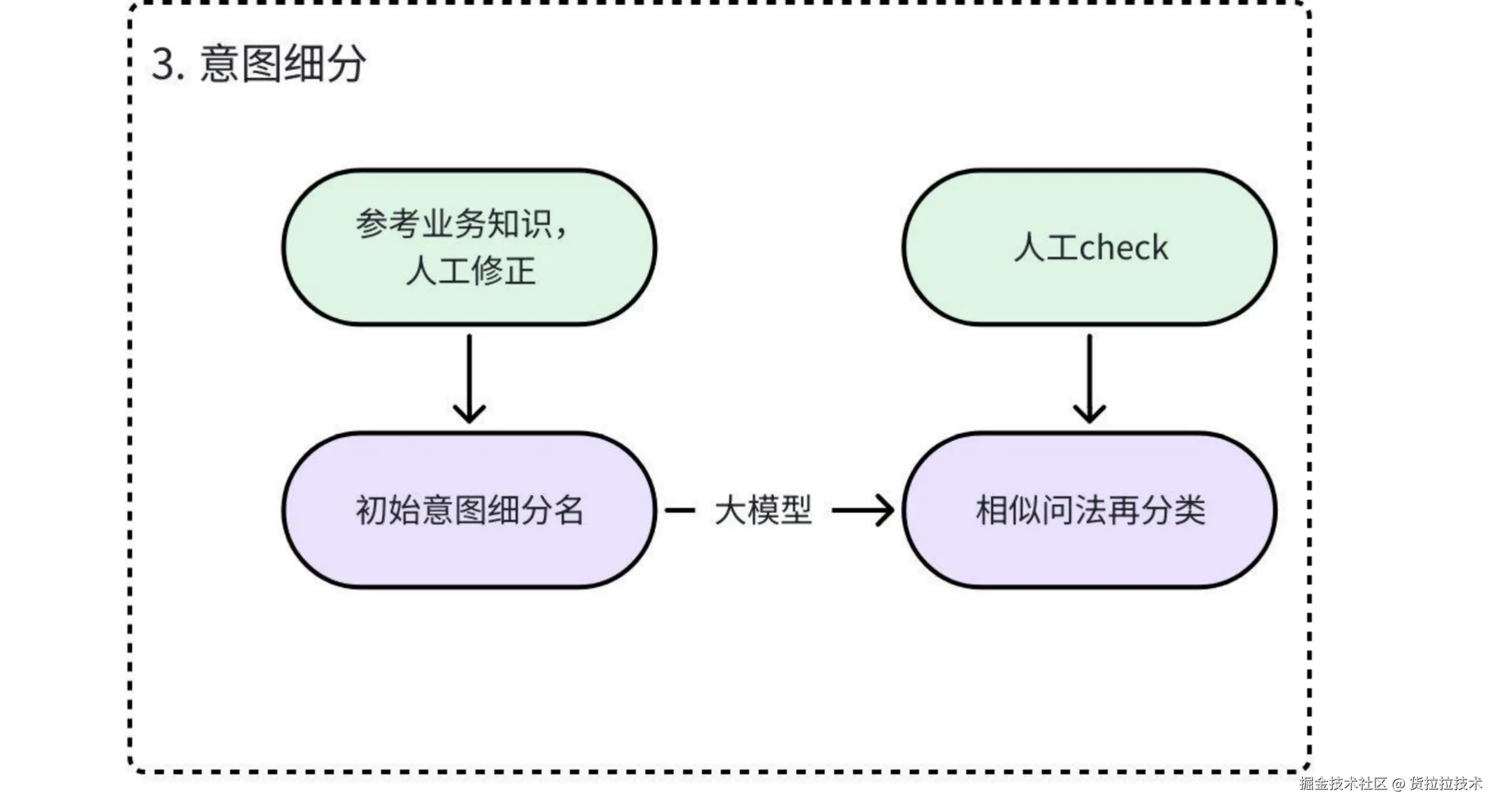
通过大模型+prompt 对全量相似问法进行重新分类,由于准确率很难达到100%,因此仍然需要人工对类别发生变更的相似问法进行二次校验,以保证相似问法分类准确。3. 意图细分
使用大模型初始化细分意图类别,人工二次确认最终的细分意图
css
a. 初始化意图细分:
使用大模型的语言理解能力和业务知识为意图的细分提供初始方案,方便人工二次check;
b. 人工优化:
由于大模型的细分方案并不完全符合业务要求,因此需要人工进行二次确认,以确保意图的细分是符合业务逻辑的。4. 话术生成
结合邀约话术知识,使用大模型生成话术
由于意图的数量繁多,很难使用人工去为每个意图生成多种话术。因此,利用大模型结合场景知识为每个意图生成初始多样化话术,人工做二次校验。
三、结果
1. 意图名定义不清晰
利用业务知识合并相似的意图类别,并为每一个意图提供优化后的意图名

2. 相似问法与意图不匹配
利用意图摘要明晰意图命中范围,并对每一个意图中的相似问法进行优化
对10% 的相似问法进行重新分类,准确率=65%

3. 意图过于概括
根据司机的情绪、具体原因、产品维度进行细分
对63% 的意图进行细分,原有意图44个类细分后为89个类

四、未来展望
1. 自动提示优化
在对相似问法重新归类的过程中,使用人工调整的方式来得到语言表述精准的意图描述。未来可使用自动提示优化的方法对prompt进行自动调优。
2. 相似问法涵盖多个意图
针对相似问法涵盖多个意图的情况,未来可以将相似问法进行拆分并写入对应意图的相似问法中。