文章目录
-
- 一、数据分类:理解数据的三种形态
-
- [1.4 三种数据类型的区别](#1.4 三种数据类型的区别)
- 二、数据的基本统计描述:把握数据的全貌
-
- [2.1 中心趋势度量:数据分布的中心在哪里](#2.1 中心趋势度量:数据分布的中心在哪里)
- [2.2 数据散布度量:数据分散程度如何](#2.2 数据散布度量:数据分散程度如何)
- [2.3 数据基本统计描述的图形显示](#2.3 数据基本统计描述的图形显示)
- 三、数据预处理的原因:为什么需要预处理
-
- [3.1 真实世界中的数据是"脏"的](#3.1 真实世界中的数据是"脏"的)
- [3.2 学习算法和参数选择](#3.2 学习算法和参数选择)
- 第一部分总结
在第一部分中,我们将学习数据预处理的基础知识,包括如何理解不同类型的数据、如何描述数据的特征,以及为什么需要数据预处理。
一、数据分类:理解数据的三种形态
关键词:数据约束程度不同、数据存储方式
结构化数据 :想象一下,你打开Excel表格,看到整齐的行和列,每一列都有明确的含义,比如姓名、年龄、工资。这就是结构化数据------数据被严格地组织在二维表中,每个字段的含义都是确定的、清晰的。特点包括:(1)强约束 :数据的格式、位置、含义都是固定的;(2)易于处理 :可以直接用数据库的SQL语句查询和分析;(3)存储方式:存储在关系型数据库中,用二维表结构表达。实际应用示例:银行账户信息表、学生成绩表、商品库存表都是典型的结构化数据。
半结构化数据 :半结构化数据就像一个有固定框架但内容可以灵活变化的表格。比如XML文档或HTML网页,它们有一定的结构(标签、属性),但具体内容可以变化,字段也可以根据需要扩充。特点包括:(1)弱约束 :有一定结构,但语义不够确定,字段可以扩充;(2)自描述 :数据本身包含结构信息(如XML标签);(3)存储方式:用XML文档、JSON格式存储。实际应用示例:网页HTML、配置文件XML、API返回的JSON数据都是半结构化数据。
非结构化数据 :非结构化数据就像一本没有目录、没有章节的书,内容杂乱无章,很难按照统一的概念去提取信息。比如图片、视频、音频、办公文档等。特点包括:(1)无约束 :数据杂乱无章,没有固定的结构;(2)难以提取 :不方便用数据库的二维表来表现;(3)存储方式:存储成普通的文本文件或二进制文件。实际应用示例:照片、视频、音频文件、Word文档、PDF文档都是非结构化数据。
1.4 三种数据类型的区别
三种数据类型的核心区别在于模式(schema)对数据的约束程度 :(1)结构化数据 :强约束,数据必须严格按照模式存储;(2)半结构化数据 :弱约束,数据有一定结构但可以灵活变化;(3)非结构化数据:无约束,数据没有固定结构。数据处理的演进路径:从非结构化到半结构化,从半结构化到结构化,从结构化到关联数据体系,从关联数据体系到机器学习,从机器学习到故事化呈现,从故事化呈现到决策导向。
二、数据的基本统计描述:把握数据的全貌
关键词:中心趋势度量、数据散布度量、图形显示、均值、中位数、众数、分位数、可视化
把握数据的全貌是成功的数据预处理的关键。基本统计描述可以帮助我们识别数据性质,发现哪些数据值应该视为噪声或离群点。
2.1 中心趋势度量:数据分布的中心在哪里
中心趋势度量告诉我们数据分布的中心位置在哪里,就像找到一群人的平均身高一样。
均值(Mean) :均值是最常用的中心趋势度量,就是算术平均。把所有数值加起来,然后除以个数。对于数据集 { x 1 , x 2 , ... , x n } \{x_1, x_2, \ldots, x_n\} {x1,x2,...,xn},均值计算公式为: x ˉ = 1 n ∑ i = 1 n x i = x 1 + x 2 + ⋯ + x n n \bar{x} = \frac{1}{n}\sum_{i=1}^{n}x_i = \frac{x_1 + x_2 + \cdots + x_n}{n} xˉ=n1∑i=1nxi=nx1+x2+⋯+xn。均值的类型包括:(1)算术平均 :所有数值的简单平均;(2)加权平均 :不同数值有不同的权重;(3)截尾平均:去掉极端值后的平均。重要特点:均值对极端值(离群点)很敏感,如果数据中有一个特别大的值,均值会被拉高。实际应用示例:计算班级平均成绩时,如果有一个学生考了满分,平均分会被拉高,这可能不能代表大多数学生的水平。
中位数(Median):中位数是把数据从小到大排列后,位于中间的那个数。如果数据个数是偶数,就取中间两个数的平均值。对于倾斜(非对称)的数据,中位数是更好的数据中心度量。比如收入数据,少数高收入者会拉高均值,但中位数不受影响。实际应用示例:在统计城市居民收入时,中位数比均值更能反映普通居民的收入水平,因为少数富豪会大幅拉高均值。缺点:当观测数量很大时,中位数的计算开销很大,因为需要先排序。
众数(Mode) :众数是数据集中出现最频繁(最高频率)的值。众数的类型包括:(1)单峰(unimodal) :只有一个众数;(2)双峰(bimodal) :有两个众数;(3)三峰(trimodal):有三个众数。实际应用示例:在调查"最喜欢的颜色"时,如果"蓝色"出现次数最多,那么蓝色就是众数。经验规律:对于适度倾斜(非对称)的单峰数值数据,存在经验近似等式:均值 - 众数 ≈ 3 × (均值 - 中位数)。
中位数(Midrange) :中位数是最大值和最小值的平均值: 中位数 = max + min 2 \text{中位数} = \frac{\max + \min}{2} 中位数=2max+min。中位数很少使用,因为它对极端值非常敏感。
2.2 数据散布度量:数据分散程度如何
数据散布度量告诉我们数据的分散程度,就像看一群人的身高差异有多大。
极差(Range) :极差是最大值和最小值的差: 极差 = max − min \text{极差} = \max - \min 极差=max−min。极差简单直观,但只考虑了最大值和最小值,忽略了中间数据的分布情况。
分位数(Quantile) :分位数是按照分布 (有一个字段)每隔一定间隔把数据划分成基本上相同的连贯集合。**四分位数(Quartile)**把数据分布划分为4个相等的部分,每部分表示数据分布的四分之一:(1)Q1(第1四分位数) :第25个百分位数,25%的数据小于它;(2)Q2(第2四分位数) :中位数,第50个百分位数,50%的数据小于它;(3)Q3(第3四分位数) :第75个百分位数,75%的数据小于它。**四分位数极差(IQR)**是Q3和Q1的差,表示中间50%数据的散布范围: I Q R = Q 3 − Q 1 IQR = Q3 - Q1 IQR=Q3−Q1。
五数概括(Five-Number Summary) :对于倾斜分布,单个分布数值度量(如IQR)不是非常有用,因为倾斜分布两边的分布是不等的。五数概括用五个数来概括数据:(1)Minimum(最小值) ;(2)Q1(第1四分位数) ;(3)Median(中位数) ;(4)Q3(第3四分位数) ;(5)Maximum(最大值)。在五数中相邻的每两个数之间大约有1/4或25%的数据项。实际应用示例:对12个月薪数据的样本,按照递增顺序排列如下:2210, 2255, 2350, 2380, 2380, 2390, 2420, 2440, 2450, 2550, 2630, 2825。五数概括为:Min = 2210,Q1 = 2365,Median = 2405,Q3 = 2500,Max = 2825。
盒图(Boxplot) :盒图以可视化的方式展现五数概括,由统计学家John W. Tukey发明。盒图的构成包括:(1)盒的端点 :在四分位数上,盒的长度是四分位数极差IQR;(2)中位数 :用盒内的线标记;(3)胡须(whiskers) :盒外的两条线延伸到最小和最大观测值;(4)离群点:当数据值超过四分位数达到1.5×IQR时,胡须出现在四分位数的1.5×IQR之内的最极端观测值处终止,剩下的情况个别地绘出。实际应用示例:盒图可以直观地比较不同组数据的分布情况,比如比较不同班级的成绩分布。局限性:针对大数据绘制盒图依然是个挑战。
方差和标准差(Variance and Standard Deviation) :方差衡量数据相对于均值的分散程度: σ 2 = 1 n ∑ i = 1 n ( x i − x ˉ ) 2 \sigma^2 = \frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^2 σ2=n1∑i=1n(xi−xˉ)2。标准差是方差的平方根: σ = σ 2 \sigma = \sqrt{\sigma^2} σ=σ2 。标准差和原始数据有相同的单位,更容易理解。实际应用示例:在质量控制中,标准差越小,说明产品质量越稳定。
2.3 数据基本统计描述的图形显示
图形显示可以帮助我们直观地理解数据分布。
分位数图(Quantile Plot) :分位数图中,每个观测值 x i x_i xi(序列或数值属性)与一个百分数 f i f_i fi 配对,指出大约 f i × 100 % f_i \times 100\% fi×100% 的数据小于值 x i x_i xi。分位数图可以直观地看到数据的分位数位置。
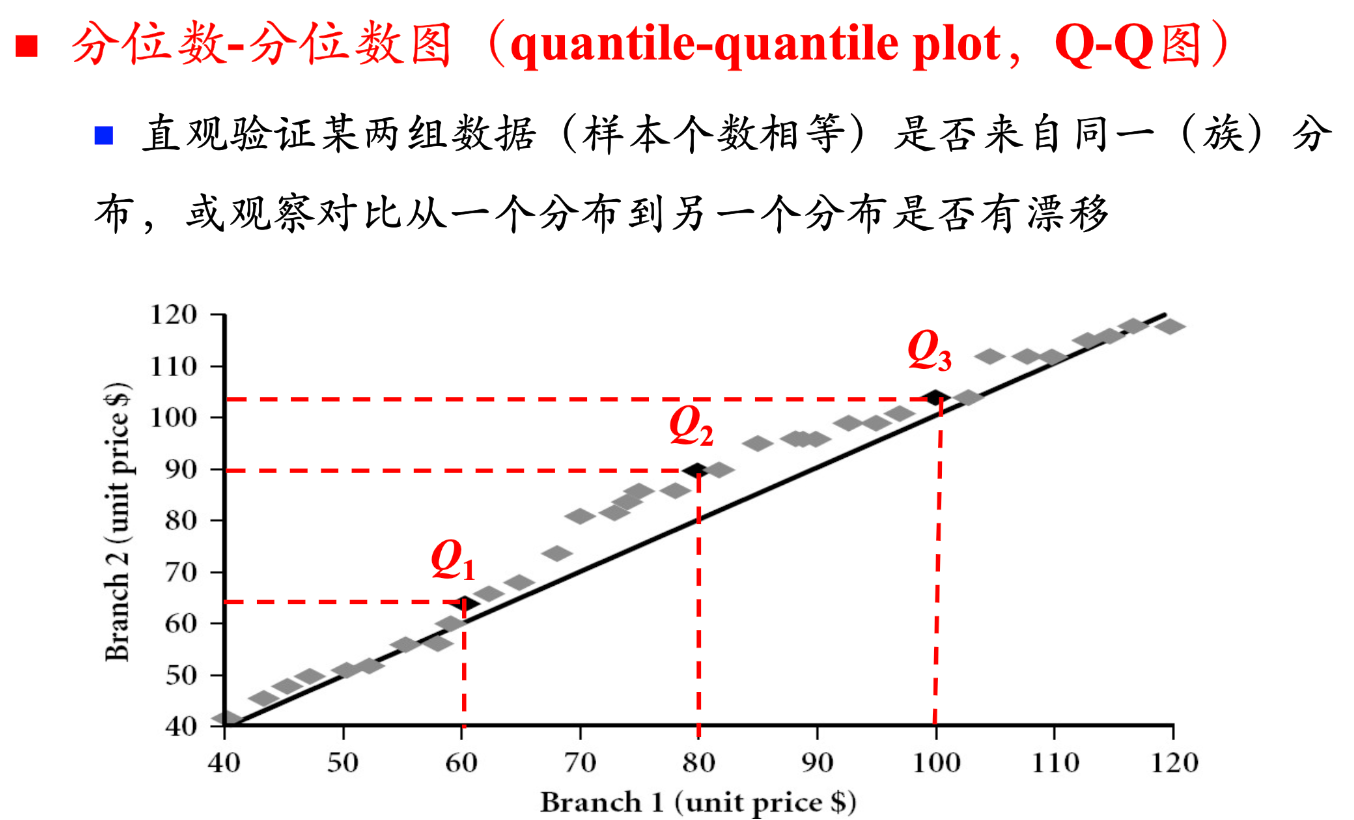
分位数-分位数图(Q-Q图):Q-Q图用于直观验证某两组数据(样本个数相等)是否来自同一(族)分布,或观察对比从一个分布到另一个分布是否有漂移。如果两组数据来自同一分布,Q-Q图上的点应该大致在一条直线上。
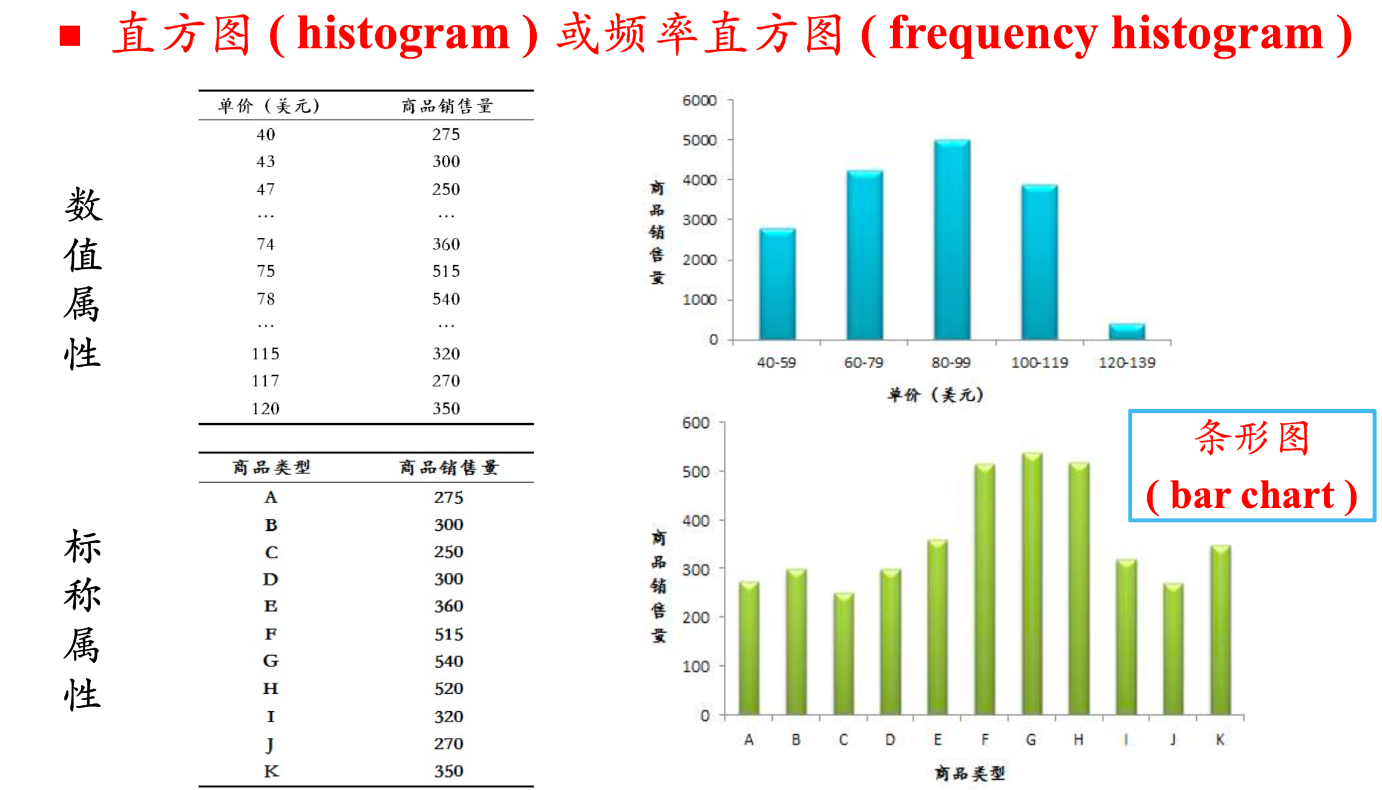
直方图(Histogram) :直方图(或频率直方图)用矩形条的高度表示每个区间的频率或频数。数值属性使用直方图,标称属性使用条形图(bar chart)。直方图可以直观地看到数据的分布形状:是对称的、左偏的还是右偏的。
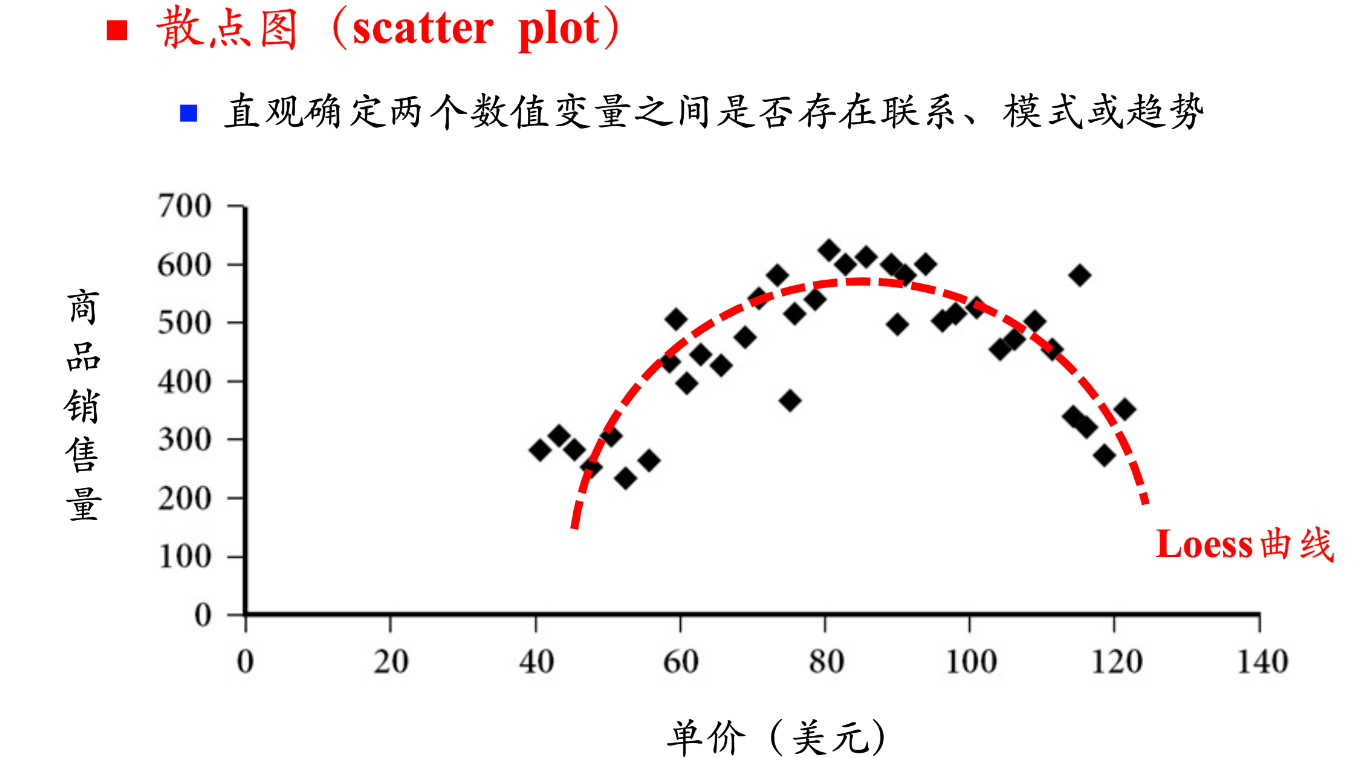
散点图(Scatter Plot):散点图用于直观确定两个数值变量之间是否存在联系、模式或趋势。实际应用示例:绘制商品销售量和单价的关系图,可以看是否存在相关性。如果存在趋势,可以添加Loess曲线来显示趋势。
三、数据预处理的原因:为什么需要预处理
关键词:脏数据、不完整数据、噪声数据、不一致数据、过拟合、欠拟合、交叉验证
3.1 真实世界中的数据是"脏"的
真实世界中的数据往往存在各种问题,不能直接用于机器学习。
不完整(Incomplete) :数据缺少某些属性值,或缺少我们感兴趣的某些属性,或只包含聚合数据。示例包括:occupation = ""(职业字段为空)、缺少某些关键属性。
噪声(Noisy) :数据包含错误或离群点。示例包括:Salary = "-10"(工资为负数,明显错误)、数据录入错误。
不一致(Inconsistent) :数据包含代码或名称的不一致。示例包括:(1)age = "42" 但 birthday = "03/07/1997"(年龄和生日不一致);(2)之前评分用"1, 2, 3",现在用"A, B, C";(3)重复记录之间存在差异,如 name="haha" income="42$" 和 name="haha" income="24$"。
3.2 学习算法和参数选择
没有免费的午餐:合适的选择是由数据决定的。不同的数据需要不同的算法和参数。
要避免的问题 包括:(1)过拟合(Overfitting) :模型在训练数据上表现很好,但在新数据上表现很差;(2)欠拟合(Underfitting):模型太简单,无法捕捉数据中的模式。
测试数据的选择 :(1)数据源充足 :使用与训练数据集分离的大数据集;(2)数据源不足:使用交叉验证(Cross Validation)。
重要观点:机器学习从来就不是提取一个数据集,将学习算法应用于数据上那么简单的事情。每个问题都不相同。必须对数据进行思考,琢磨它的意义,然后从不同的角度来检验,具有创造性地找到一个合适的观点。
第一部分总结
通过第一部分的学习,我们掌握了数据预处理的基础知识:
- 数据分类:理解了结构化、半结构化和非结构化数据的区别,知道不同数据类型的约束程度和存储方式
- 统计描述:学会了用均值、中位数、方差等统计量描述数据,用直方图、散点图等图形可视化数据
- 预处理原因:认识到真实数据存在不完整、噪声、不一致等问题,理解了过拟合和欠拟合的概念
这些基础知识为我们后续学习具体的预处理方法打下了坚实的基础。在第二部分中,我们将学习如何处理缺失值、如何进行数据清理和集成,以及如何进行属性选择和转换。