目录
摘要
今天系统学习了异常检测算法的构建和评估方法。通过高斯分布对每个特征进行建模,将各特征概率相乘得到联合概率p(x),当p(x)小于阈值ε时判定为异常。在算法评估方面,虽然训练使用无标签数据,但可以通过少量带标签的异常样本构建验证集和测试集,使用精确率、召回率和F1分数来评估性能并调整参数ε。
Abstract
Today's lesson systematically covered the construction and evaluation of anomaly detection algorithms. By modeling each feature with Gaussian distribution and multiplying individual probabilities to obtain joint probability p(x), samples are flagged as anomalies when p(x) falls below threshold ε. For algorithm evaluation, although training uses unlabeled data, performance can be assessed using small labeled anomaly datasets for validation and testing, employing precision, recall and F1-score to tune parameter ε.
一、异常检测算法
现在我们已经了解了高斯正态分布或正态分布是如何作用于单个数值的,我们准备构建我们的异常检测算法,我们有一个训练集x1到xm,所以每个样本x是一个包含n个数值向量,在飞机引擎的例子中,我们有两个对应于热量和振动的特征,所以每个xi都是一个二维向量,但在许多实际应用中,我们可能会用几十甚至几百个特征来做这件事,我们想做的是进行密度估计,这意味着我们将构建一个模型或估计p(x)的概率,我们对p(x)的模型将如下所示,x是一个具有x1值的特征向量,我们将把p(x)模型化为x1的概率乘以x2的概率乘以x3的概率最后到特征向量n个特征的xn的概率
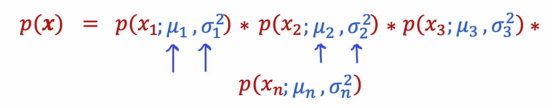
μ即为均值,σ即为方差,x1为热量特征,x2为振动特征,以此类推,到xn都是判断飞机发动机好坏的特征
假设对于飞机引擎,有十分之一的几率它真的很热,也许有二十分之一的几率它会振动得非常剧烈,那么它运行得非常热并且振动得非常剧烈的几率则为十分之一乘以二十分之一,也就是二百分之一,所以我们知道,同时运行得非常热并且振动得非常剧烈得引擎是非常不可能的
上面p(x)的公式我们也可以写成一种更简洁的写法是下面这样
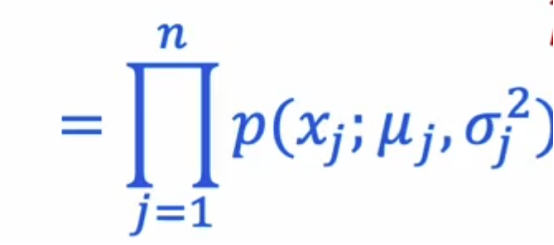
那么让我们把这一切结合起来,看看我们如何构建一个异常检测系统
1、构建异常检测系统
第一步是我们必须自己选择认为可能出现异常的特征,然后我们会为n个特征拟合参数μ1到μn和σ1到σn,其中μj是所有例子中特征j的x_j的平均值
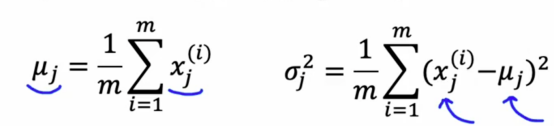
通过在未标记的训练集上估计这些参数,我们现在已经计算出了模型的所有参数,最后我们得到一个新的样本,我们需要做的就是计算p(x)并查看它是大是小,如果我们在刚刚看到的
P(x)为:
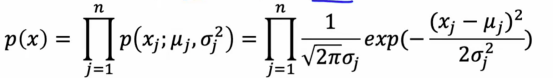
算出来后,我们需要查看p(x)是否小于ε,如果是,则标记异常,该算法背后的一个直觉是如果一个或多个特征标记为异常,那么它会将样本标记为异常,这些特征相对于训练集中看到的要么非常大,要么非常小,所以对每一个特征x_j,如果新样本的一个特征在这里异常的话,也就是说,p(x_j)会非常小,如果这个乘积中的一个因子非常小,那么整个整体乘积往往会非常小,因此p(x)会非常小,而在这个算法中,异常检测所做的系统地量化这个新样本是否,x是否有任何特征异常大或异常小,现在让我们通过一个例子来看看实际上意味着什么
现在,这里有一个包含特征x1和x2的数据集
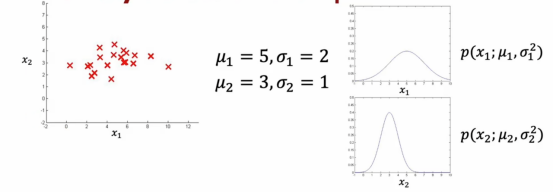
我们会注意到特征x1取值范围远大于特征x2,如果我们要计算特征x1的均值,我们就会得到μ1 = 5,σ1 = 2,然后我们通过x1和x2的高斯分布构建出3D表面图
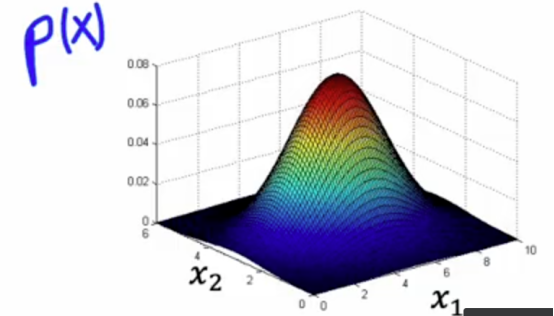
在任何点上,这个高度是p(x1)乘以p(x2)对应x1和x2值的乘积,这表明p(x)较高的值更有可能,所以中间附近的值是高概率的,是正常的
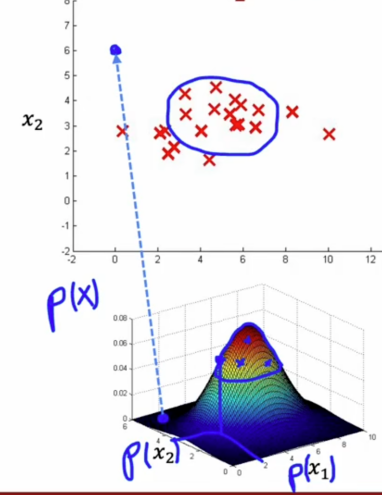
但比如像这个边界上的小点,落到的概率很小,说明它是有问题的
现在,让我们选择两个测试样本,第一个,我们将这里写为Xtest1,第二个在这里写为Xtest2,如下图所示
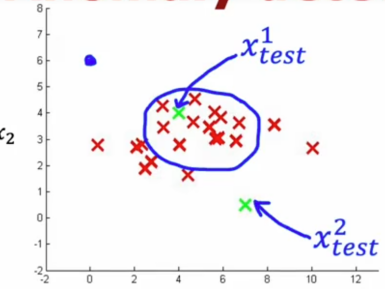
我们选择参数ε= 0.02,如果我们计算p(Xtest1)
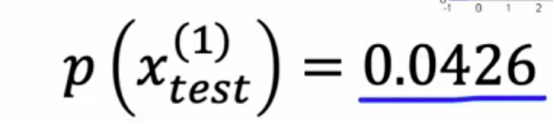
这远远大于ε,所以算法会说,这看起来没问题不像是异常,相比之下,如果我们计算这个点的p(Xtest2)

我们会发现这远远小于ε,所以算法会将其标记为异常
正如我们一开始希望的一样,算法认为Xtest1看起来正常,而Xtest2远离训练集中看到的任何值,现在我们看到了构建异常检测系统的过程,但这里抛出来一个问题,我们如何选择参数ε呢?我们怎么知道我们的异常检测系统是否运行良好,在下一个小节中,我们会更加深入地讨论开发和评估
二、开发和评估异常检测系统
现在我们学习一些开发异常检测系统的实用技巧,其中一个关键想法是,如果我们能在系统开发中进行评估,我们将更快速地做出决策并改进系统
当我们开发一个学习算法的时候,比如选择不同的特征或者尝试不同的参数值如ε,决定是否以某种方式改变特征或增加或减少ε或其他参数,如果我们有一种评估学习算法的方法,这些决策会更加容易,这有时被称为实数评价,意思是如果我们可以快速地以某种方式改变算法,并且有一种方法计算一个数字,该数字告诉我们算法是变好了还是变差了,这样决定是否坚持这种算法变化会更容易,在异常检测中通常是这样做的,即便我们主要讨论的是未标记的数据
现在我们会稍微改变这一假设,假设我们有一些标记数据,通常包括少量之前观察到的异常,所以也许在制造飞机引擎几年后,我们只看到了几个异常的飞机引擎,我们会将标签y = 1与异常关联起来,对于我们认为正常的示例,我们会将标签y = 0与之关联,因此,异常检测算法将从中学习的训练集仍然是这个未标记的训练集x1到xm,我们会认为这些示例都是我们假设的正常的而非异常的,所以y = 0,实际上,如果有少量异常示例混入这个训练集中,我们的算法通常仍然会表现良好,为了评估我们的算法,提出一种方法来进行实际数值评估,如果我们有少量异常示例,这会非常有用,这样我们就可以创建一个,我们将其表示为xcv1
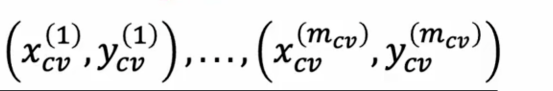
这与我们之前学到的符号是相似的,同样,有一个包含一定数量示例的测试集,其中交叉验证集和测试集希望包含一些异常示例,换句话说,交叉验证集和测试集中会有一些y = 1的示例,但也有很多y = 0的示例,在实际操作中,如果有一些示例确实是异常的,但却被异常标记为y = 0,异常检测算法仍然可以正常工作,让我们用飞机引擎的例子来说明这一点,假设我们多年来一直制造飞机引擎,但多年间我们还收集了20个有缺陷或异常的引擎的数据,即y = 1的,会少得多,因此使用这一类型算法应用于大约2到50个已知异常情况并不算不典型,我们要把这个数据集分成训练集和测试集
这是一个例子,我们会把6000个正常引擎放入训练集,同样,如果有几个异常引擎被混入其中,我们不用太担心这个问题,然后我们放入2000个正常引擎和10个已知异常到交叉验证集中,再放入另外2000个正常引擎和10个异常引擎到测试集中,然后我们可以在训练集上训练算法,将高斯分布拟合到这6000个样本上,然后在交叉验证集中,我们可以看到它正确标记了多少异常引擎,例如,我们可以使用交叉验证集来调整参数ε并将其设置得更高或更低,这取决于算法是否能够可靠地检测到10个异常而不会将太多的正常引擎标记为异常,在我们调整了参数ε并可能添加或删除或调整特征xj之后,我们可以将算法应用到测试集中,以查看它能找到多少这个10个异常引擎,以及它将多少正常引擎错误地标记为异常引擎,但需要注意的是,这仍然是一个无监督学习算法,因为训练集实际上并没有标签,因此我们通过拟合高斯分布从训练集中学习,就像我们在前面的视频中看到的那样,但事实证明,如果我们在构建一个实际的异常检测系统,在交叉验证集和测试集上使用少量异常来评估算法是非常有助于调整算法的
现在让我们看看,如何在交叉验证集或测试集上实际评估算法,我们首先在训练集上拟合模型,然后在任何交叉验证或测试示例x上
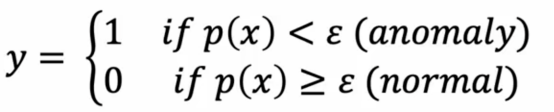
然后我们计算预测y,之后查看这个算法在交叉验证集或测试集上的预测于y标签的匹配度,这与我们之前学到的正向预测和负向预测有异曲同工之妙,然后我们计算精确度和找回度,进一步计算F1-分数,这些评估指标会更好地帮助我们判断这个算法是否是一个好算法,进而确定ε。
总结
今天的学习让我掌握了完整的异常检测系统构建流程。算法的核心思想很巧妙------通过高斯分布量化每个特征的正常范围,任何特征异常都会导致联合概率p(x)降低。最实用的是学会了如何评估这个无监督学习算法:虽然训练时不需要标签,但可以用少量已知异常样本构建验证集来调参,用测试集来最终评估。这种半监督的评估方式既保持了无监督学习的优势,又提供了客观的性能衡量标准。F1分数的使用让我能够平衡误报和漏报,这对实际应用非常重要。这些知识让我对如何在实际项目中部署异常检测系统有了清晰的认识。