【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【Ubuntu】【Gitlab】拉出内网 Web 服务:http.server 分析(三)
分析了 Python 中 http.server 模块的 cgi 功能,下面继续
Nginx 事件驱动分析
OK,经过之前 blog
【Ubuntu】【Gitlab】拉出内网 Web 服务:http.server 分析(一)
【Ubuntu】【Gitlab】拉出内网 Web 服务:http.server 分析(二)
【Ubuntu】【Gitlab】拉出内网 Web 服务:http.server 分析(三)
的分析,现在知道了 Python 的 http.server 模块主要是用于静态网站展示的,其虽然有 CGI,但其动态功能很简单,无法支撑高效的动态网站,而接下来要分析的 Gitlab 是一个完整的 Web 应用程序 ,其功能包含:用户系统 (负责处理注册,登录,权限等),Git 仓库托管 (负责处理 git clone,git push 等协议),数据库存储 ,后台任务队列 ,实时通信 ,CI/CD 流水线 ,动态页面渲染 (不是静态 HTML)等,Python 的 http.server 没有这么强的能力,完全带不动
之前最开始的 blog
【Ubuntu】【GitLab】局域网用 Ubuntu 搭建 GitLab
介绍过如何在局域网中用 Ubuntu 搭建 Gitlab 服务,下面将重新审视之前的配置
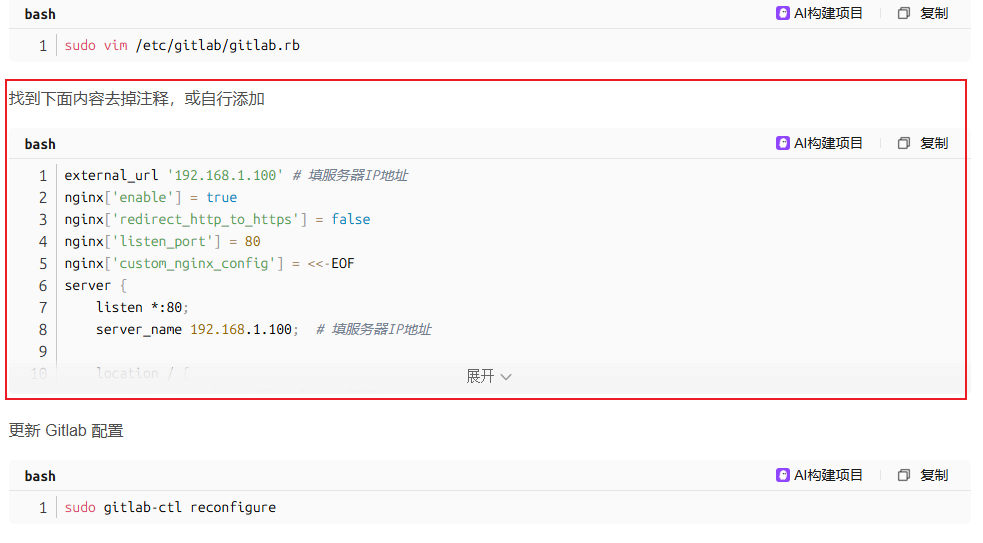
里面提到,需要修改 /etc/gitlab/gitlab.rb 文件,然后在里面添加一个自定义的 Nginx 配置项,这里面的配置项其实有点冗余(虽然不影响正常使用),后面会详细分析
在分析之前,先回顾下 Nginx 的相关概念,之前 blog 【Ubuntu】【GitLab】局域网用 Ubuntu 搭建 GitLab 提到 Nginx 被广泛认为是高性能 HTTP 服务器 (相对于 Python 的 http.server 而言,http.server 主要用来开发,测试或教学目的,在设计目标上就不一样),下面详细分析下两者在架构,性能和使用场景上的一些本质区别
首先是架构,Nginx 用的是事件驱动,配合异步非阻塞 I/O,基于 epoll (Linux 系统调用)高效的 I/O 多路复用机制,实现一个线程(或进程)能同时监听成千上万个 TCP socket 网络连接,并且只在某个连接有数据可读可写时才去处理它,避免无意义的等待和轮询
这里有很多点,首先说这个事件驱动 ,指的是 Nginx 使用一种基于事件的编程模型来处理网络请求,而不是传统的一个线程/进程处理一个请求这种方式
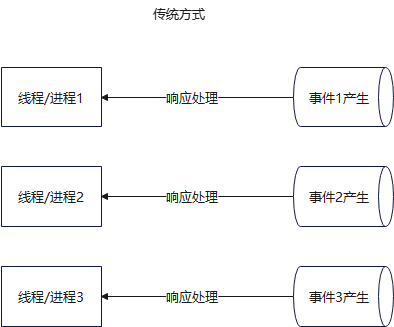
可以看到,传统方式的处理,是一个线程/进程,只能响应处理一个事件
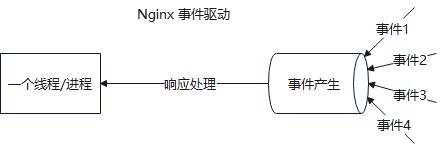
而在这里,Nginx 只需要开一个线程/进程,就能处理 N 个事件产生 ,也就是上面说的成千上万个 TCP socket 连接,这种模型让它能用极少的资源 (比如几个 CPU 核心,几十 MB 内存)同时处理成千上万的并发连接,当然,这样依赖 Linux 的 epoll 事件通知机制
从实现上来说,Nginx 在启动时,创建几个 worker 进程(一般为 CPU 核数),每个 worker 是单线程,然后这些 worker 会调用 epoll_create 创建事件池,并用 epoll_ctl 注册监听 socket,然后进行事件循环,其大概逻辑如下
c
while (1) {
// 阻塞等待,直到有事件发生(如新连接、数据可读)
events = epoll_wait(epoll_fd, ...);
// 遍历所有就绪事件
for (event in events) {
if (event is new connection) {
accept(); // 接受连接
epoll_ctl(ADD, new_socket); // 加入监听
} else if (event is data ready) {
read(socket); // 读请求
process(); // 处理(如读文件)
write(socket); // 发响应
}
}
}这里面有几个关键点:没有线程切换,不轮询所有连接,只处理活跃的连接,所有 I/O 操作都是非阻塞的(recv 立刻返回,没数据就跳过,这个很重要,后面分析)
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog
【Ubuntu】【Gitlab】拉出内网 Web 服务:Nginx 事件驱动分析(二)