🍊作者:计算机毕设匠心工作室
🍊简介:毕业后就一直专业从事计算机软件程序开发,至今也有8年工作经验。擅长Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等。
擅长:按照需求定制化开发项目、 源码、对代码进行完整讲解、文档撰写、ppt制作。
🍊心愿:点赞 👍 收藏 ⭐评论 📝
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
🍅 ↓↓文末获取源码联系↓↓🍅
基于大数据的强迫症特征与影响因素数据分析系统-功能介绍
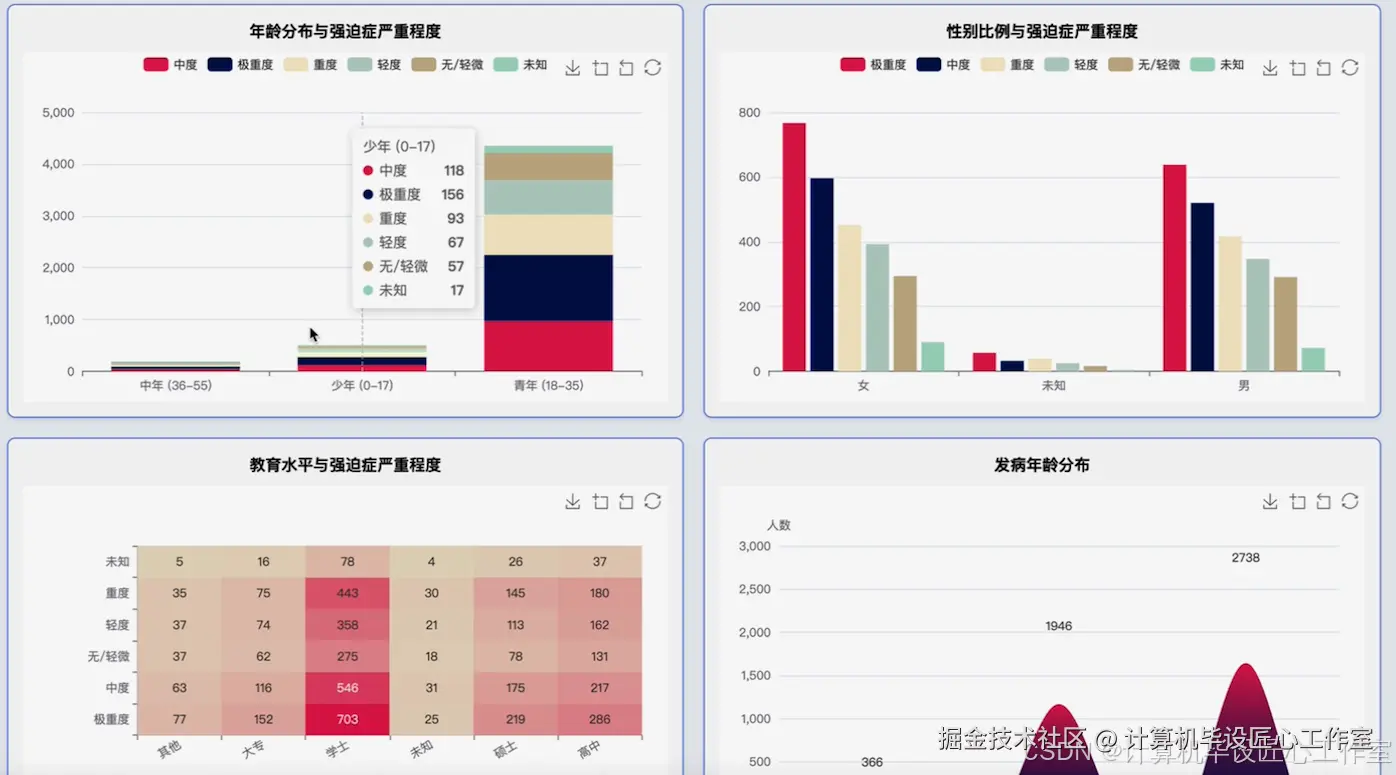
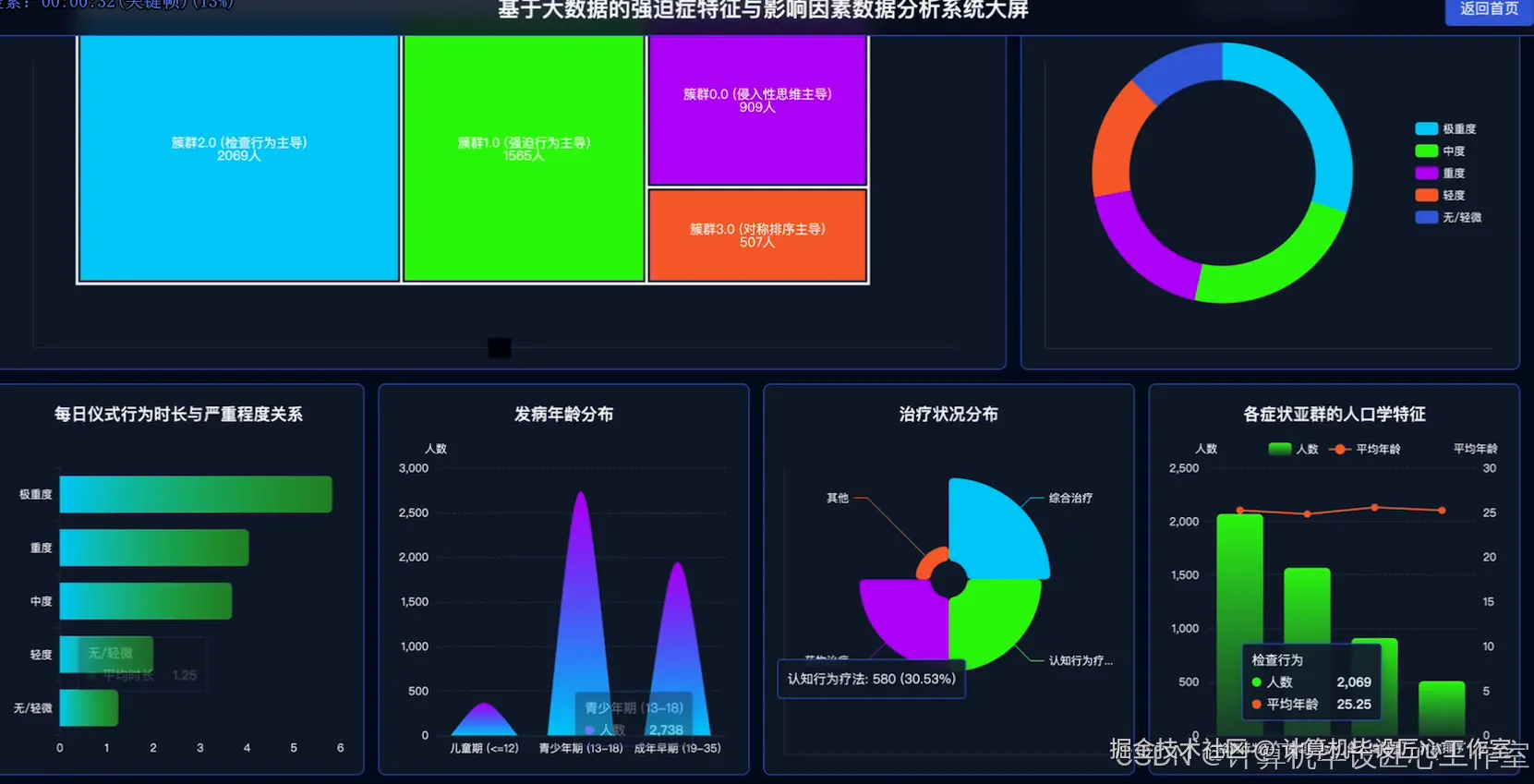
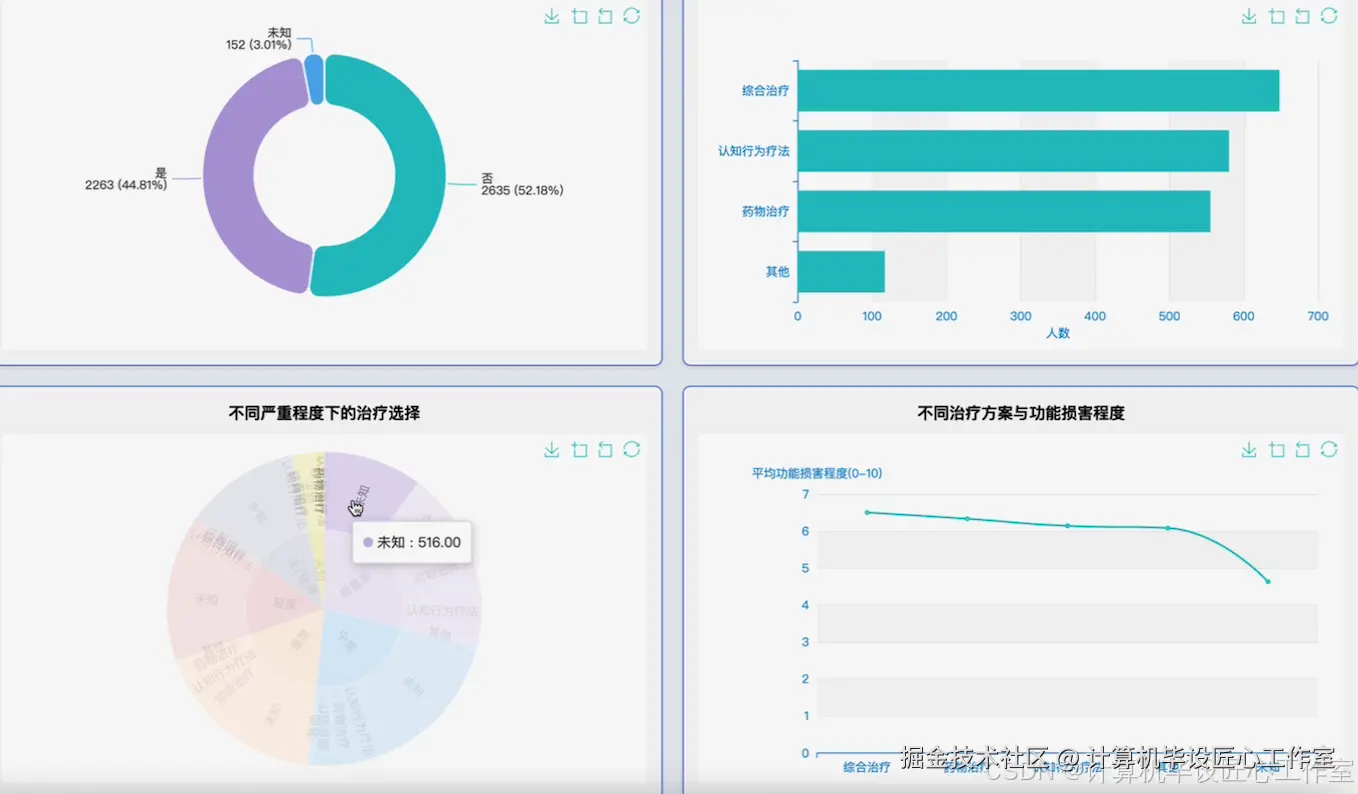
本系统是一个基于大数据技术的强迫症特征与影响因素数据分析系统,旨在为心理健康领域的研究提供一个高效、可扩展的数据处理与分析平台。系统整体采用Hadoop生态进行构建,利用HDFS作为底层分布式文件系统,实现对大规模问卷数据的可靠存储。核心计算引擎采用Apache Spark,通过其内存计算能力,对海量数据进行快速清洗、转换和多维度分析,远超传统单机处理工具的性能瓶颈。系统后端采用Python语言开发,利用PySpark无缝对接Spark集群,实现了从数据预处理、特征工程到高级分析的完整流程。具体功能涵盖了四大核心模块:首先,对强迫症患者的人口学特征进行深入剖析,包括年龄、性别、教育水平与病情严重度的交叉分析;其次,对临床特征进行量化研究,探究每日仪式时长、痛苦程度等功能损害指标与病情的关联性;再者,系统对诊断与治疗现状进行统计,揭示不同严重程度下的治疗模式;最后,也是本系统的亮点,系统利用K-Means等机器学习聚类算法,基于患者的核心症状得分进行智能分群,识别出具有不同症状主导模式的强迫症亚型,并为每个亚群绘制详细的人口学与临床画像,从而为精细化诊断和个性化治疗方案的探索提供数据支持与新的视角。
基于大数据的强迫症特征与影响因素数据分析系统-选题背景意义
选题背景 强迫症(OCD)是一种常见且致残性高的精神障碍,患者常被反复出现的强迫思维和/或强迫行为所困扰,严重影响其日常生活、工作和社交功能。长期以来,对强迫症的理解与研究多依赖于临床访谈和小样本的问卷调查,虽然这些方法为疾病的基础认知奠定了基础,但它们在捕捉疾病的异质性、识别潜在的亚型以及探索复杂影响因素方面存在局限性。随着信息技术的飞速发展,通过在线平台等方式收集大规模心理健康数据已成为可能,这些数据集蕴含了比传统研究更为丰富和复杂的信息。然而,数据量的激增也带来了新的挑战,比如数据中普遍存在的缺失值、异常值以及数据不一致等问题,传统的数据处理工具和分析方法难以高效、准确地应对。因此,如何利用现代大数据技术,对这些宝贵的心理健康数据进行有效管理和深度挖掘,以揭示隐藏在数据背后的模式和规律,成为当前精神卫生研究领域一个亟待探索的新方向。 选题意义 本课题的意义在于探索并实践了一套完整的大数据分析流程,将其应用于具体的心理健康问题,具有一定的方法论参考价值和实际应用潜力。从方法论层面看,本项目详细展示了如何运用Hadoop和Spark等主流大数据框架,处理真实世界中"脏"数据的全过程,包括数据清洗、缺失值填充、特征转换等关键步骤。这对于其他需要处理类似复杂数据集的学生或研究人员来说,提供了一个可供参考的实践范例,降低了他们学习和应用大数据技术的门槛。从实际应用角度看,虽然本系统作为一个毕业设计,其结论不能直接用于临床诊断,但它所实现的聚类分析功能,能够帮助研究人员从宏观上识别出强迫症患者群体中可能存在的不同症状组合模式。这些通过数据驱动的分群结果,或许能为后续的病因学研究、或者开发更具针对性的心理干预或治疗方案提供一些初步的线索和启发。换个角度看,本系统将复杂的分析结果通过可视化图表进行直观展示,也降低了非专业人士理解复杂数据的难度,有助于心理健康知识的科普和传播。
基于大数据的强迫症特征与影响因素数据分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制) 开发语言:Python+Java(两个版本都支持) 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持) 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy 数据库:MySQL
基于大数据的强迫症特征与影响因素数据分析系统-视频展示
基于大数据的强迫症特征与影响因素数据分析系统-图片展示

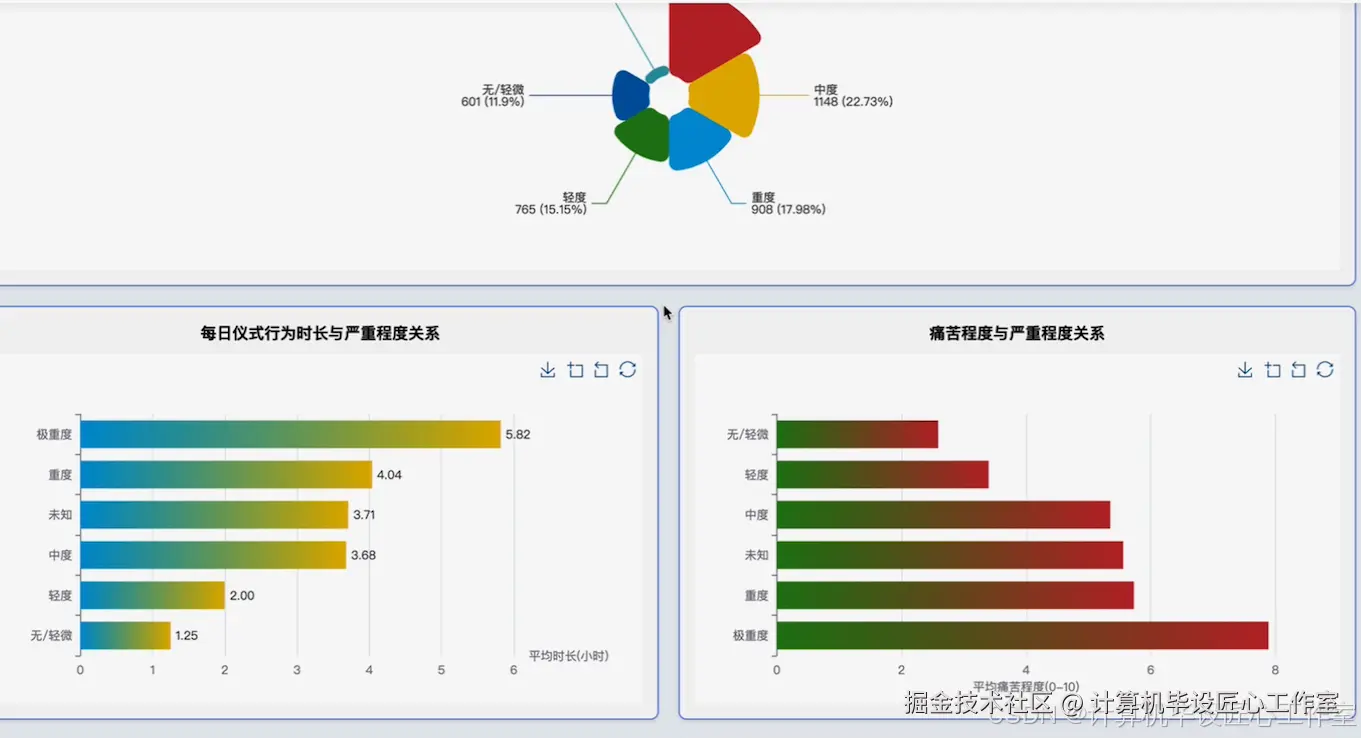
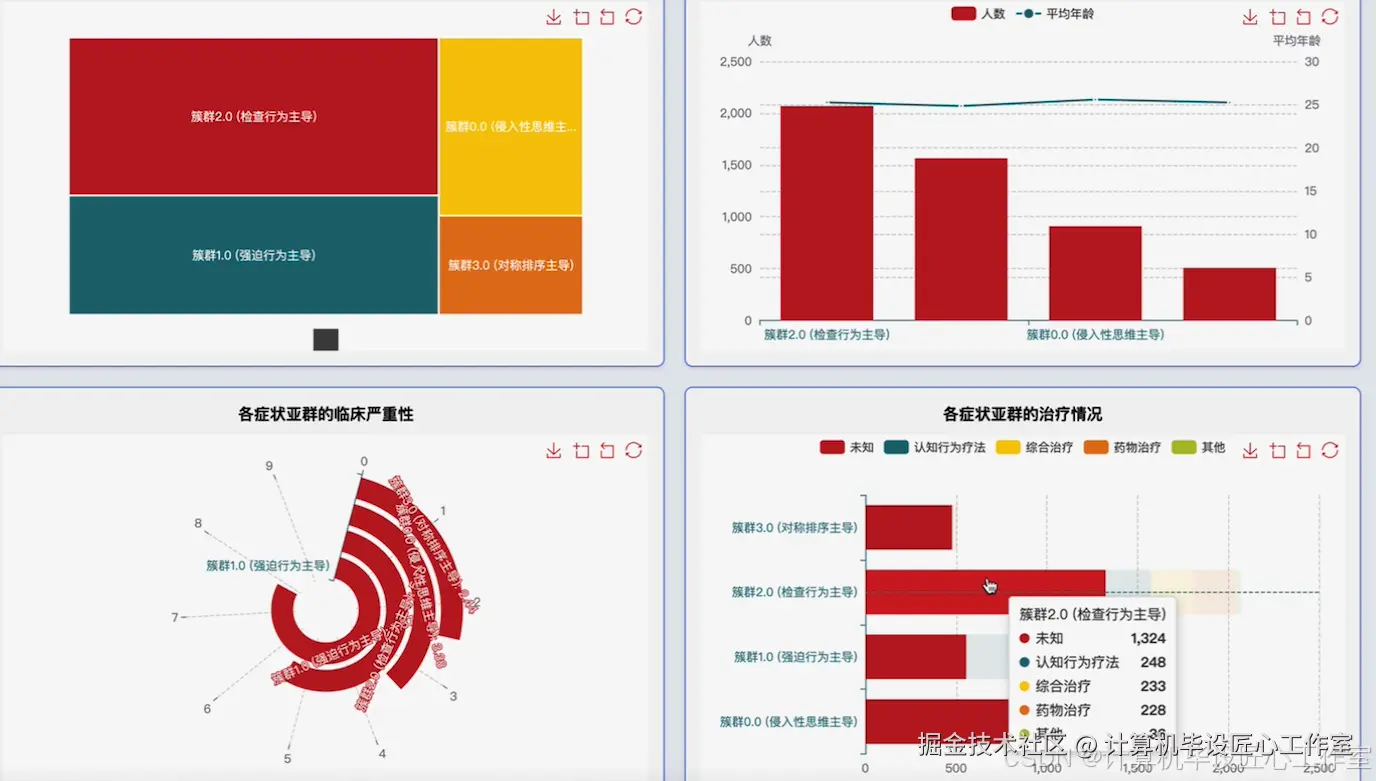
基于大数据的强迫症特征与影响因素数据分析系统-代码展示
python
from pyspark.sql import SparkSession, functions as F
from pyspark.ml.feature import VectorAssembler, KMeans
from pyspark.sql.types import FloatType
spark = SparkSession.builder \
.appName("OCD_Analysis") \
.getOrCreate()
def preprocess_ocd_data(df):
df = df.filter(df.respondent_id.isNotNull())
df = df.withColumn('age', F.when(F.col('age') == 99, None).otherwise(F.col('age')))
symptom_cols = [f'C{i}' for i in range(1, 6)] + [f'CH{i}' for i in range(1, 6)] + [f'S{i}' for i in range(1, 6)] + [f'IT{i}' for i in range(1, 6)]
for col in symptom_cols:
df = df.withColumn(col, F.col(col).cast(FloatType()))
avg_age = df.select(F.mean('age')).collect()[0][0]
avg_onset_age = df.select(F.mean('ocd_onset_age')).collect()[0][0]
df = df.fillna({'age': avg_age, 'ocd_onset_age': avg_onset_age})
for col in symptom_cols:
avg_score = df.select(F.mean(col)).collect()[0][0]
df = df.fillna({col: avg_score})
df = df.withColumn('ocd_total_score_recalculated', sum(df[col] for col in symptom_cols))
df = df.fillna({'ocd_total_score': F.col('ocd_total_score_recalculated')})
df = df.drop('ocd_total_score_recalculated')
df = df.fillna({'gender': '未知', 'education': '未知', 'prior_diagnosis': '未知', 'treatment_status': '未知'})
df = df.na.drop(subset=['ocd_severity'])
return df
def perform_kmeans_clustering(df):
symptom_cols = [f'C{i}' for i in range(1, 6)] + [f'CH{i}' for i in range(1, 6)] + [f'S{i}' for i in range(1, 6)] + [f'IT{i}' for i in range(1, 6)]
assembler = VectorAssembler(inputCols=symptom_cols, outputCol="features")
df_features = assembler.transform(df)
kmeans = KMeans(featuresCol='features', predictionCol='cluster', k=4, seed=42)
model = kmeans.fit(df_features)
clustered_df = model.transform(df_features)
cluster_centers = model.clusterCenters()
cluster_description = {0: "症状群1:混合型", 1: "症状群2:强迫思维主导型", 2: "症状群3:检查行为主导型", 3: "症状群4:对称/排序主导型"}
udf_cluster_description = F.udf(lambda cluster_id: cluster_description.get(cluster_id, "未知"))
final_df = clustered_df.withColumn('cluster_description', udf_description(F.col('cluster')))
return final_df
def analyze_age_severity_distribution(df):
df = df.filter((F.col('age').isNotNull()) & (F.col('ocd_severity').isNotNull()))
df_with_age_group = df.withColumn("age_group",
F.when((F.col('age') >= 18) & (F.col('age') <= 25), "18-25岁")
.when((F.col('age') >= 26) & (F.col('age') <= 35), "26-35岁")
.when((F.col('age') >= 36) & (F.col('age') <= 50), "36-50岁")
.otherwise("50岁以上"))
severity_order = F.when(F.col('ocd_severity') == 'None/Minimal', 1)\
.when(F.col('ocd_severity') == 'Mild', 2)\
.when(F.col('ocd_severity') == 'Moderate', 3)\
.when(F.col('ocd_severity') == 'Severe', 4)\
.otherwise(5)
df_with_severity_order = df_with_age_group.withColumn("severity_order", severity_order)
result_df = df_with_severity_order.groupBy("age_group", "ocd_severity")\
.count()\
.withColumn("total_count", F.sum("count").over(Window.partitionBy("age_group")))\
.withColumn("percentage", F.round((F.col("count") / F.col("total_count")) * 100, 2))
return result_df.select("age_group", "ocd_severity", "count", "percentage")基于大数据的强迫症特征与影响因素数据分析系统-结语
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
🍅 主页获取源码联系🍅