🍊作者:计算机毕设匠心工作室
🍊简介:毕业后就一直专业从事计算机软件程序开发,至今也有8年工作经验。擅长Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等。
擅长:按照需求定制化开发项目、 源码、对代码进行完整讲解、文档撰写、ppt制作。
🍊心愿:点赞 👍 收藏 ⭐评论 📝
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
🍅 ↓↓文末获取源码联系↓↓🍅
基于大数据的青少年抑郁症风险数据分析可视化系统-功能介绍
本项目是一个基于大数据技术的青少年抑郁症风险数据分析与可视化系统,旨在通过现代数据科学技术深入探究青少年抑郁风险与多种潜在因素之间的复杂关系。系统整体采用先进的大数据架构,后端以Python为核心,并整合了Hadoop与Spark两大主流大数据框架,用于处理和分析大规模的健康调查数据集。具体而言,系统利用Hadoop的HDFS作为数据存储的基石,确保海量数据集的可靠存储;通过Apache Spark进行高效的分布式计算,执行包括数据清洗、转换、聚合分析在内的复杂任务,能够快速从原始数据中提取有价值的统计信息。在Web应用层面,我们采用轻量且功能强大的Django框架来构建后端服务,负责处理前端请求、调度Spark分析任务并将分析结果以API形式提供给前端。前端界面则基于Vue.js和ElementUI构建,为用户提供了直观、友好的交互体验。系统的核心亮点在于其强大的数据可视化能力,它利用Echarts图表库,将Spark分析出的复杂数据关系,如不同年龄、性别、生活习惯下的抑郁风险分布,以动态的柱状图、饼图、折线图等多种形式清晰地呈现出来,将枯燥的数据转化为易于理解的视觉洞察,为相关研究和干预措施提供数据支持。
基于大数据的青少年抑郁症风险数据分析可视化系统-选题背景意义
选题背景 近年来,青少年心理健康问题,特别是抑郁症的发病率,已成为全球范围内日益突出的公共卫生挑战,引起了社会各界的广泛关注。青少年阶段是个体生理、心理和社会适应能力发展的关键时期,面临着来自学业、社交、家庭等多方面的压力,使得他们成为抑郁症的高风险群体。传统的心理健康研究多依赖于小样本的问卷调查和临床访谈,虽然具有一定的深度,但在广度和客观性上存在局限,难以全面揭示影响青少年抑郁风险的多元化因素及其潜在的复杂关联。随着信息技术的飞速发展,我们进入了一个数据爆炸的时代,海量、多维度的数据为理解复杂社会现象提供了新的可能性。如何利用大数据技术,从大规模的健康数据中挖掘出有价值的模式和规律,从而更科学、更宏观地审视青少年抑郁症的成因,已成为一个亟待探索的重要课题。本项目正是在这样的背景下提出的,尝试将大数据分析方法应用于青少年心理健康领域,希望能为这一复杂问题的理解提供一个新的数据驱动视角。 选题意义 本课题的意义主要体现在技术和实际应用两个层面。从技术角度来看,它是一个完整的大数据技术栈实战项目。它不仅仅是简单地使用一个数据库或Web框架,而是系统地整合了Hadoop的分布式存储、Spark的快速内存计算、Python的数据处理能力以及Django的Web服务开发,构成了一套端到端的数据处理与展示流程。对于即将毕业的计算机专业学生而言,完成这样一个项目能够全面锻炼和展示对大数据核心技术的理解和应用能力,从数据采集、清洗、分析到最终的可视化呈现,每一个环节都是宝贵的实践经验,这远比单纯学习理论或做一个简单的CRUD系统更有深度和挑战性。在更实际的意义上,虽然这只是一个毕业设计,但它所构建的分析模型和可视化结果,可以为关注青少年心理健康的人群提供一种直观的参考。比如,通过分析结果,家长和教育工作者或许能更清晰地看到睡眠时长、体育锻炼、社交媒体使用习惯等因素与抑郁风险的潜在关联,从而在日常教育和家庭引导中更有针对性地进行调整和干预。当然,我们必须谦虚地认识到,本系统的分析结果仅能揭示相关性而非因果性,绝不能作为医学诊断的依据,但它作为一种数据探索和科普的工具,其价值在于能够引发更多人对青少年心理健康问题的思考和重视。
基于大数据的青少年抑郁症风险数据分析可视化系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制) 开发语言:Python+Java(两个版本都支持) 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持) 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy 数据库:MySQL
基于大数据的青少年抑郁症风险数据分析可视化系统-视频展示
基于大数据的青少年抑郁症风险数据分析可视化系统-图片展示
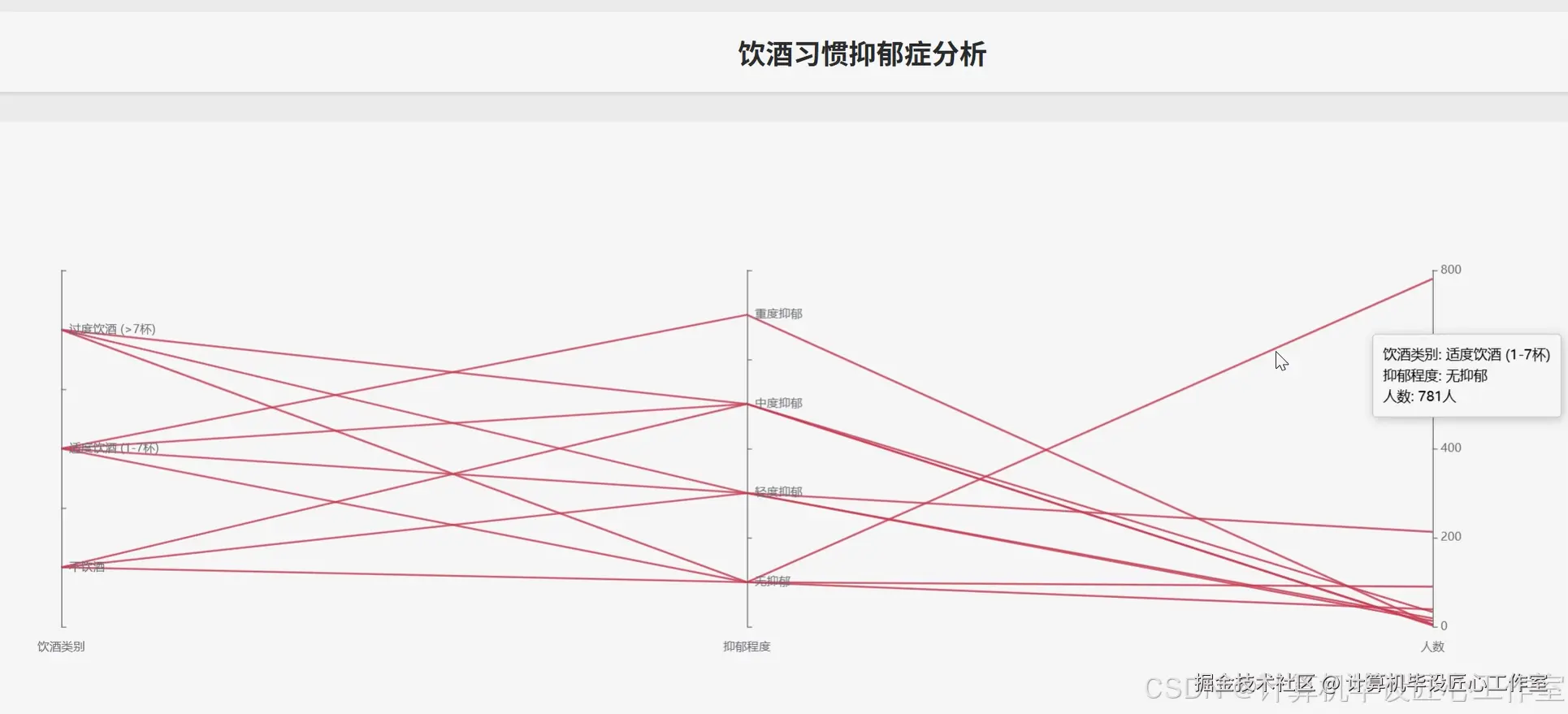
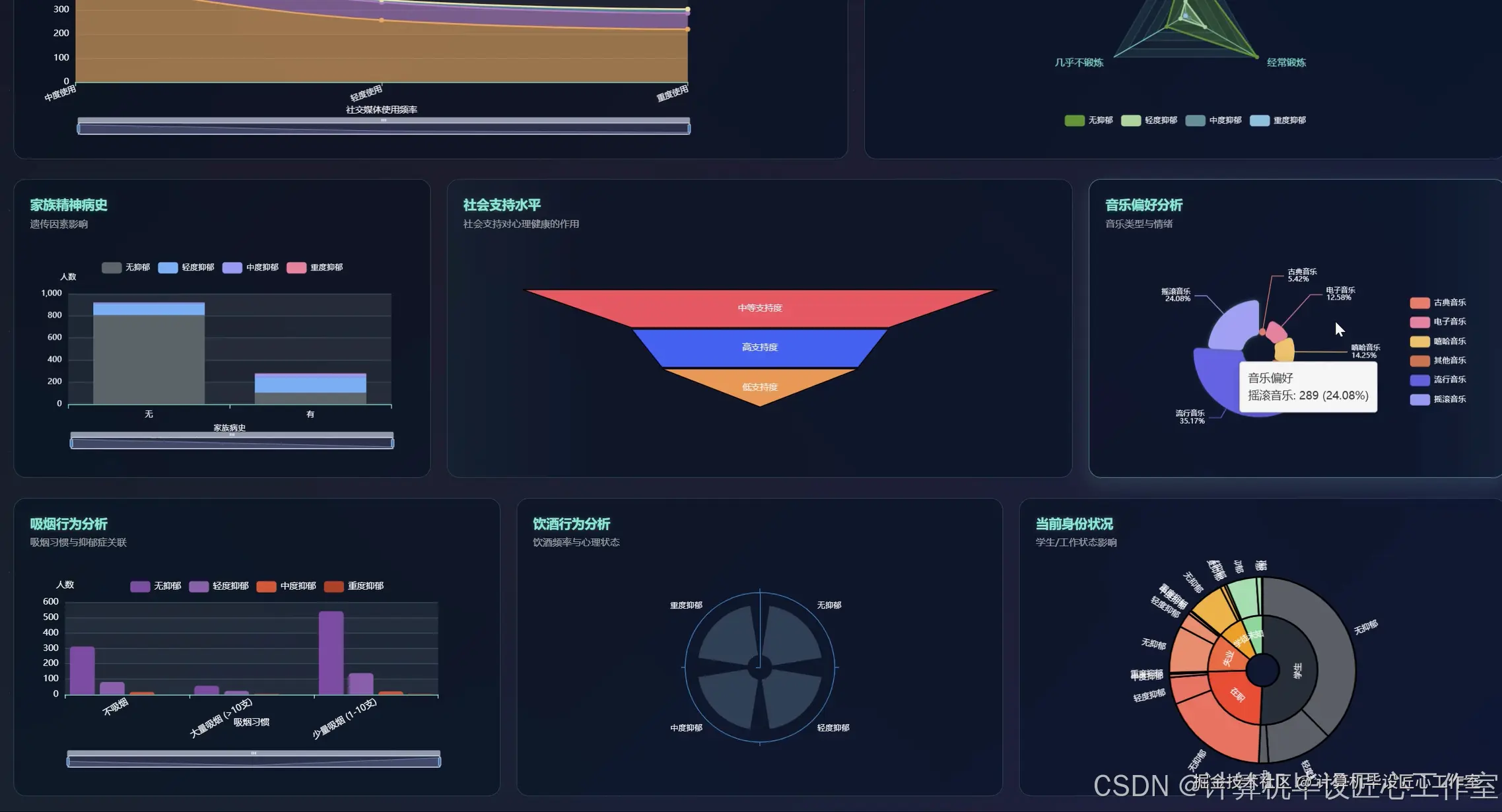

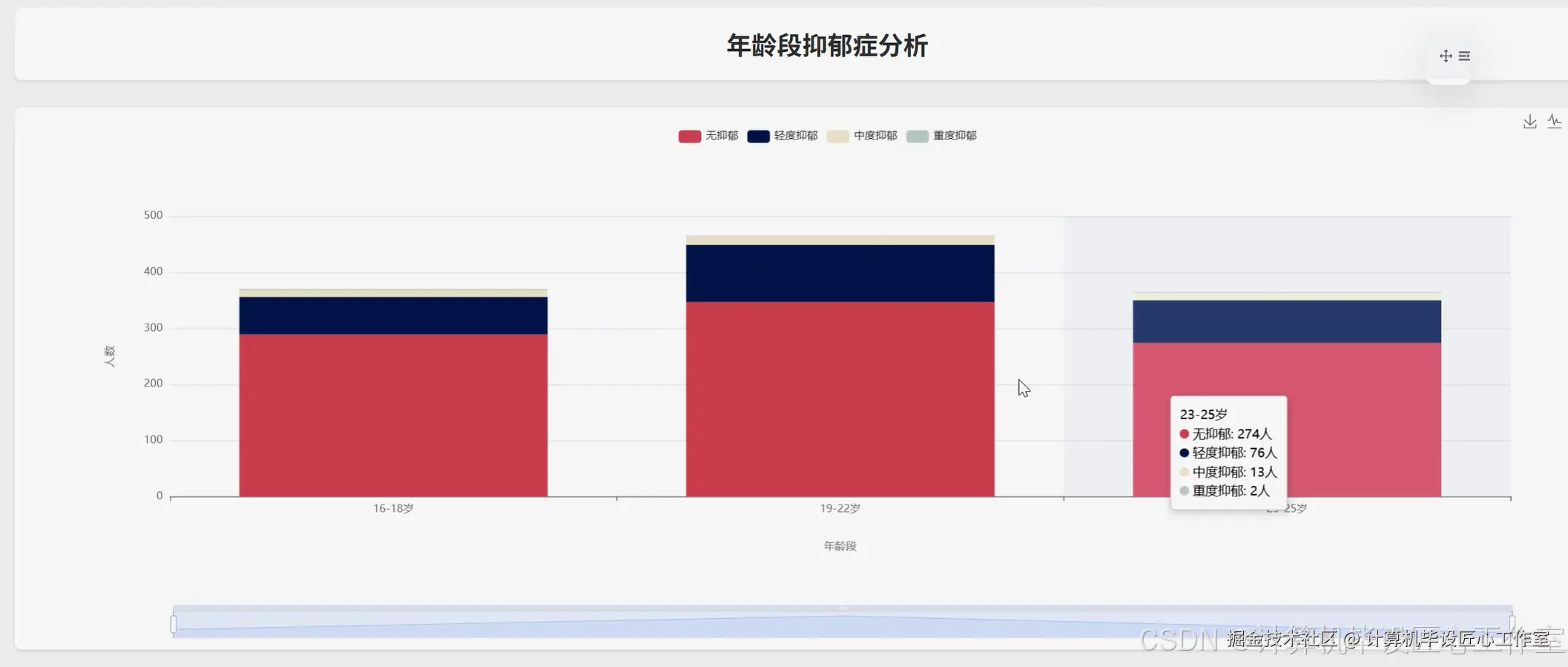
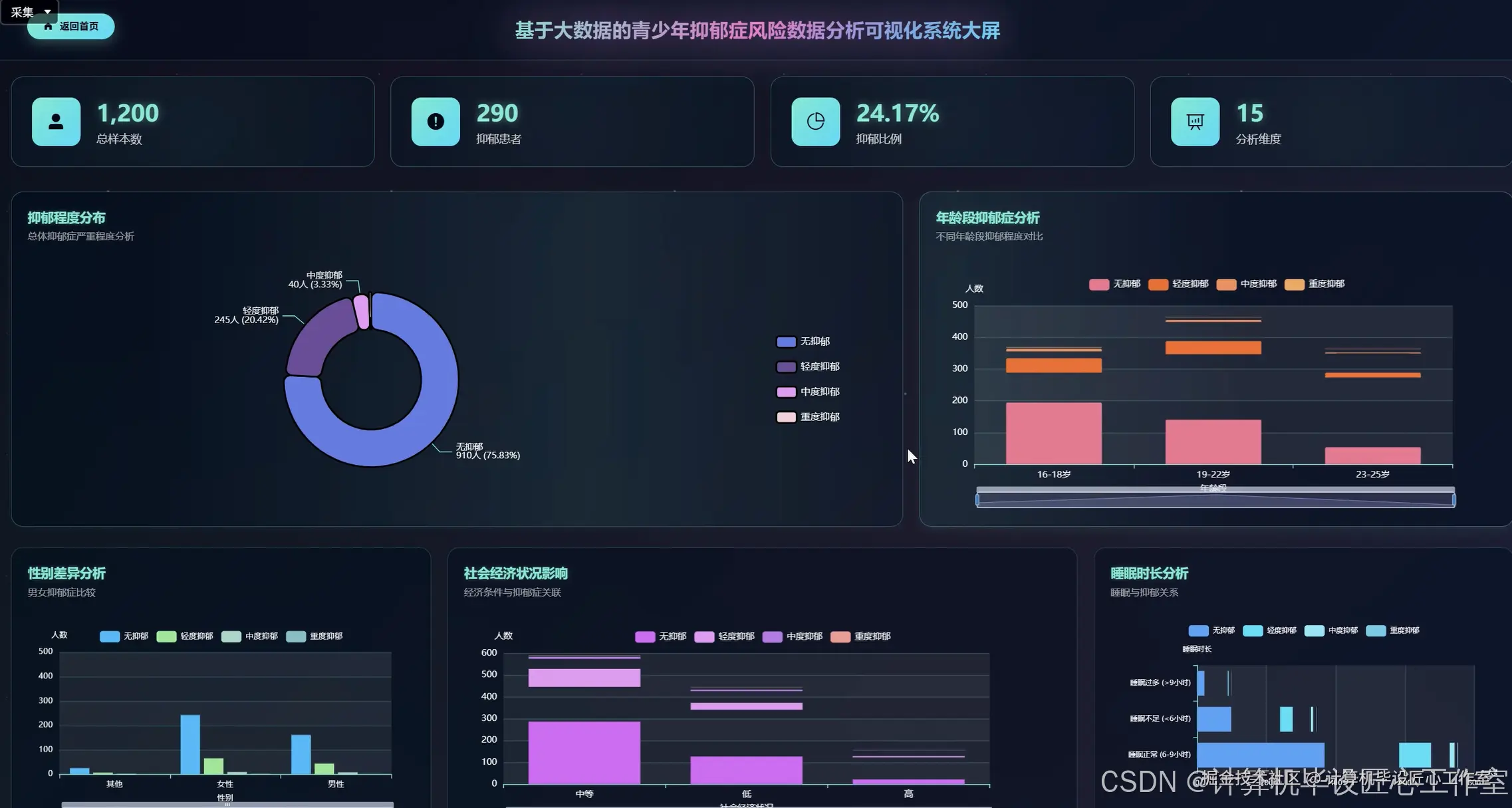
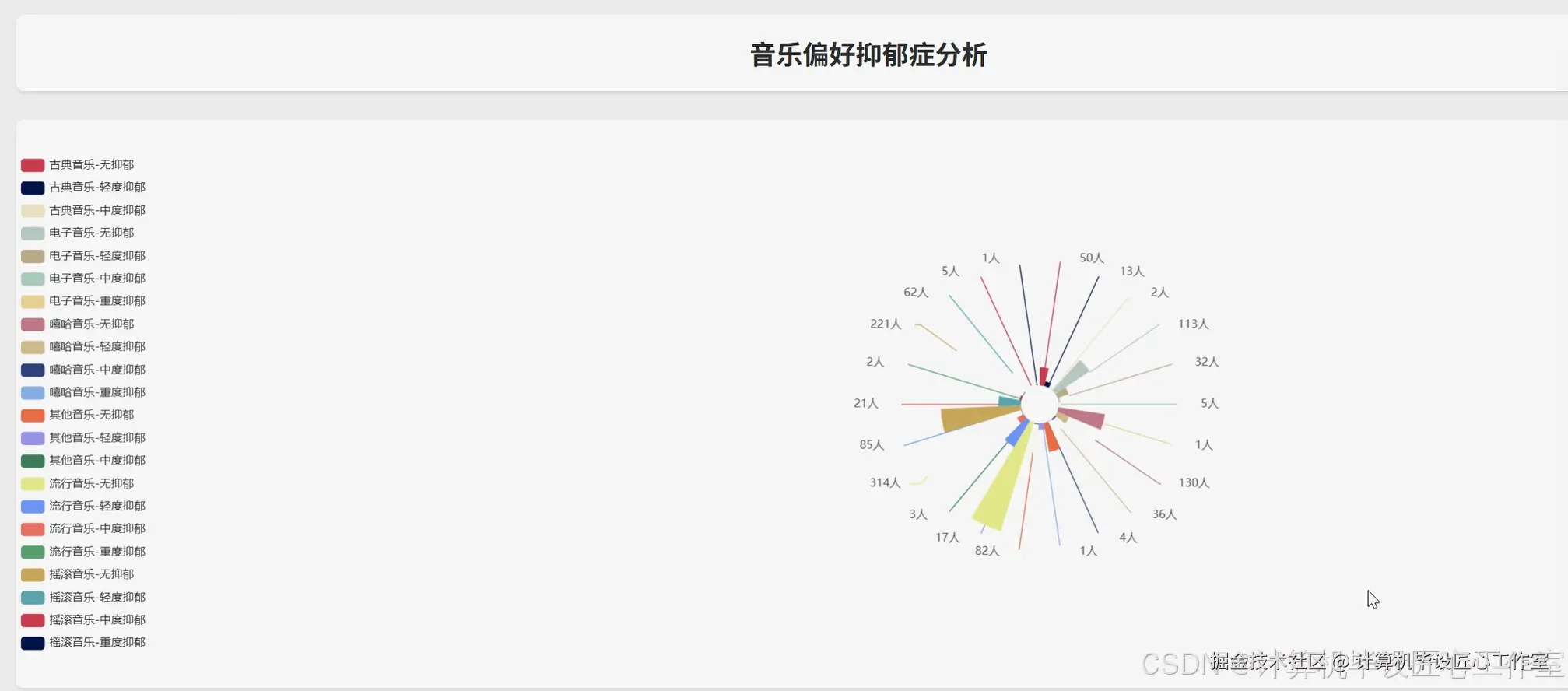
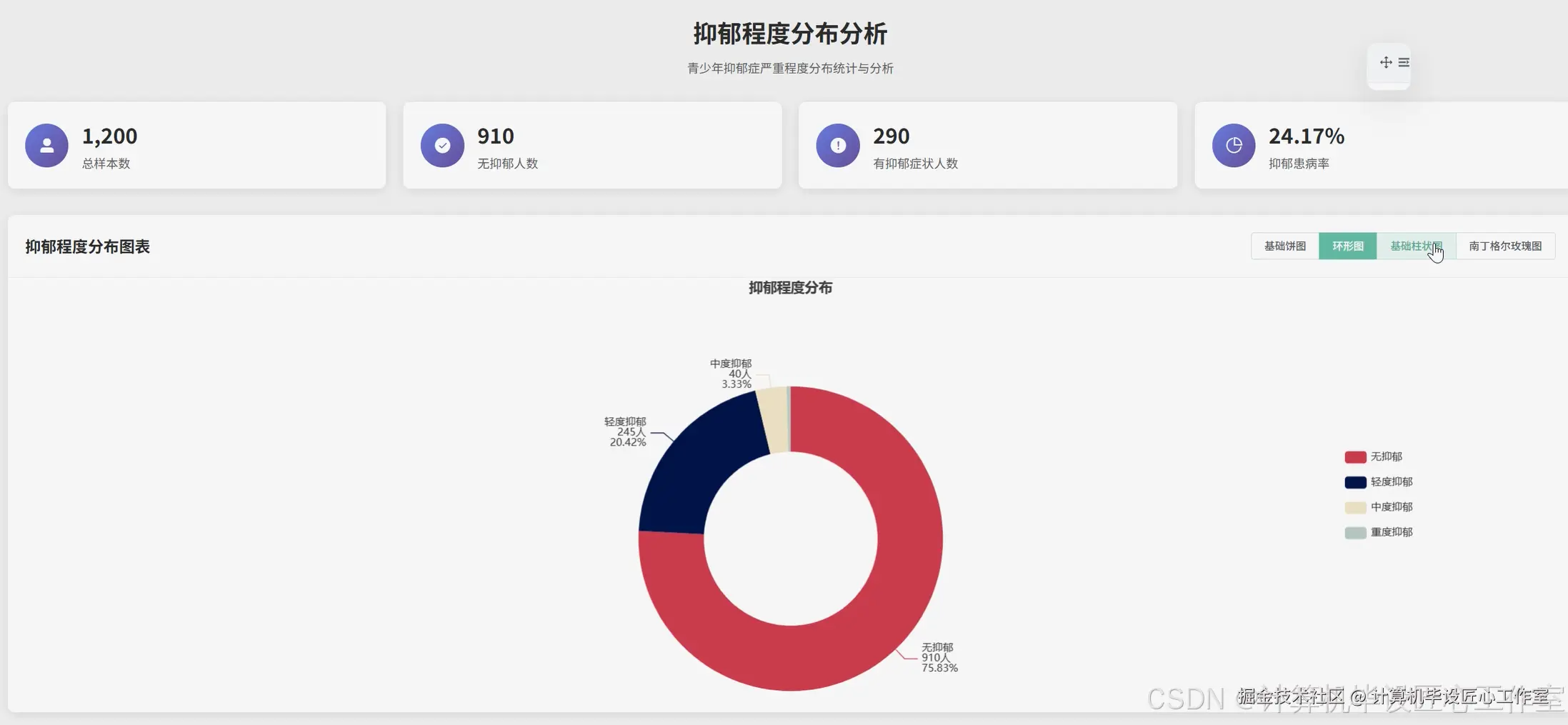



基于大数据的青少年抑郁症风险数据分析可视化系统-代码展示
python
# 初始化SparkSession,这是所有Spark功能的入口点
spark = SparkSession.builder.appName("YouthDepressionAnalysis").getOrCreate()
# 功能一:抑郁程度总体分布分析
def analyze_overall_depression_distribution():
# 读取CSV文件,Spark可以自动推断schema
df = spark.read.csv("path/to/youth_risk_depression_dataset.csv", header=True, inferSchema=True)
# 按抑郁严重程度分组并计算每组的数量
distribution_df = df.groupBy("depression_severity").count()
# 为了方便计算占比,我们获取总人数
total_count = df.count()
# 添加一个新列"percentage",计算每个抑郁等级的人数占比
distribution_with_percentage = distribution_df.withColumn("percentage", (col("count") / total_count) * 100)
# 将结果转换为Pandas DataFrame以便前端或进一步处理
result_pd = distribution_with_percentage.toPandas()
# 返回处理后的结果
return result_pd
# 功能二:不同年龄段的抑郁程度对比分析
def analyze_depression_by_age_group():
df = spark.read.csv("path/to/youth_risk_depression_dataset.csv", header=True, inferSchema=True)
# 使用when函数创建一个新的"age_group"列,将年龄划分为几个区间
df_with_age_group = df.withColumn("age_group",
when(col("age") < 19, "16-18岁")
.when((col("age") >= 19) & (col("age") < 23), "19-22岁")
.otherwise("23-25岁"))
# 按年龄组和抑郁严重程度进行分组,计算每个组合的人数
age_depression_df = df_with_age_group.groupBy("age_group", "depression_severity").count()
# 按年龄组进行分区,并在每个组内按抑郁严重程度排序,以便前端构建堆叠柱状图
# 这里使用窗口函数来实现
window_spec = Window.partitionBy("age_group").orderBy(col("depression_severity"))
result_df = age_depression_df.withColumn("rank", rank().over(window_spec))
result_pd = result_df.toPandas()
return result_pd
# 功能三:社交媒体使用时长与抑郁程度的关联分析
def analyze_social_media_vs_depression():
df = spark.read.csv("path/to/youth_risk_depression_dataset.csv", header=True, inferSchema=True)
# 对社交媒体使用时长进行分箱处理,创建一个新的"usage_category"列
df_with_usage_category = df.withColumn("usage_category",
when(col("social_media_hours_per_day") < 2, "低使用(<2小时)")
.when((col("social_media_hours_per_day") >= 2) & (col("social_media_hours_per_day") < 5), "中使(2-5小时)")
.otherwise("高使用(>5小时)"))
# 过滤掉抑郁程度为"无"的数据,以便更清晰地分析风险因素
filtered_df = df_with_usage_category.filter(col("depression_severity") != "None")
# 按使用类别和抑郁严重程度分组,计算人数
usage_depression_df = filtered_df.groupBy("usage_category", "depression_severity").count()
# 计算每个使用类别下的总人数,用于计算比例
total_per_usage = usage_depression_df.groupBy("usage_category").agg(sum("count").alias("total_in_category"))
# 将两个DataFrame连接起来,以便计算每个抑郁等级在对应使用类别中的占比
joined_df = usage_depression_df.join(total_per_usage, on="usage_category")
# 计算比例
result_df = joined_df.withColumn("proportion", col("count") / col("total_in_category"))
result_pd = result_df.toPandas()
return result_pd基于大数据的青少年抑郁症风险数据分析可视化系统-结语
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
🍅 主页获取源码联系🍅