在深度学习领域,过拟合是一个普遍存在的问题,它指的是模型在训练数据上表现良好,但在未见过的测试数据上性能显著下降的现象。正则化是解决过拟合问题的核心技术之一,它通过限制模型复杂度、引入额外约束或增加训练数据多样性等方式,提高模型的泛化能力。正则化方法的选择直接影响模型的性能、可解释性和计算效率。
随着深度学习模型规模不断增大和应用场景日益复杂,正则化技术也在不断发展和创新。从早期的 L1 和 L2 正则化,到近年来流行的 Dropout、数据增强、半监督学习等方法,每种技术都有其独特的原理和适用场景。在实际应用中,根据不同的任务需求和数据特点选择合适的正则化方法,成为深度学习工程师和研究人员的必备技能。
参数约束型正则化方法
L1 正则化:稀疏特征选择的利器
L1 正则化(L1 Regularization),也称为 Lasso(Least Absolute Shrinkage and Selection Operator)回归,是一种通过在损失函数中添加权重参数的绝对值之和作为惩罚项来防止过拟合的方法。
数学原理: 在损失函数中增加权重参数的绝对值之和:
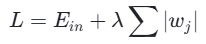
其中,λ 控制正则化强度,值越大,对模型复杂度的惩罚越重。
核心作用: L1 正则化通过鼓励模型参数的稀疏性,使部分权重变为零,从而实现特征选择的效果,减少模型复杂度,有效防止过拟合。
适用场景:
- 特征维度远大于样本量的场景(如自然语言处理中的词向量)
- 需要明确特征贡献度的领域(如医疗诊断中的关键指标分析)
- 数据具有高维稀疏特性的问题(如图像处理、文本分类)
优点:
- 天然的特征选择能力,适用于高维稀疏数据
- 生成可解释性强的模型,便于业务理解
- 计算相对简单,支持分布式处理
缺点:
- 可能丢失弱相关但重要的特征
- 需要手动调整正则化参数λ
- 以平衡稀疏度与精度
- 对异常值较为敏感
数学特性:
- L1 正则化基于 L1 范数,主要用于特征选择
- 其惩罚函数在零点不可导,需要使用次梯度优化方法
- 能产生稀疏解,特别适合于特征选择任务
L2 正则化:模型平滑与参数收缩
L2 正则化(L2 Regularization),也称为岭回归(Ridge Regression),是另一种常用的正则化方法,它通过在损失函数中添加权重参数的平方和作为惩罚项。
数学原理: 在损失函数中增加权重参数的平方和:
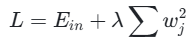
同样由λ调节惩罚力度。
核心作用: L2 正则化通过约束权重幅值,使模型参数的绝对值减小,降低模型的复杂度,防止过拟合,同时保持模型的稳定性。
适用场景:
- 特征间存在多重共线性的场景(如经济指标预测)
- 需要模型输出平滑连续值的任务(如图像超分辨率重建)
- 特征相关性高的领域(如基因数据分析)
优点:
- 防止模型对单一特征过度敏感,适合特征相关性高的场景
- 数学性质优良,优化过程稳定
- 矩阵运算优化友好,适合大规模数据
缺点:
- 无法自动筛选特征,依赖人工特征工程
- 对高度稀疏数据效果有限
- 计算复杂度相对较高
数学特性:
- L2 正则化基于 L2 范数,主要用于防止过拟合
- 惩罚函数处处可导,便于使用梯度下降等优化算法
- 不会将参数权重推向零,而是均匀缩小参数权重的大小
L1 与 L2 正则化的对比分析
L1 和 L2 正则化是最基础的两种正则化方法,它们既有相似之处,也有明显区别。下面从多个维度对它们进行对比分析:
稀疏性与特征选择:
L1 正则化能够产生稀疏解,使部分参数权重变为零,实现特征选择
L2 正则化不会产生
零权重,只会缩小权重值,无法进行特征选择
数学性质:
L1 正则化在零点不可导,需要使用次梯度优化方法
L2 正则化处处可导,支持标准梯度下降算法
L2 正则化的解通常是唯一的,而 L1 正则化可能有多个最优解
计算效率:
L1 正则化在高维数据下计算成本较高
L2 正则化矩阵运算优化友好,适合大规模数据处理
L2 正则化的计算复杂度低于 L1 正则化
抗噪声能力:
L1 正则化对异常值相对敏感
L2 正则化对异常值更鲁棒
L2 正则化具有稳定模型预测效果的作用
典型应用场景对比:
| 场景特点 | 推荐方法 | 原因 |
|---|---|---|
| 高维数据(特征 >> 样本) | L1(Lasso) | 自动特征选择,降低复杂度 |
| 多重共线性 | L2(Ridge) | 稳定系数,减少方差 |
| 需解释性强的模型 | L1 或弹性网络 | 稀疏特征更易业务解读 |
| 特征间相关性高 | L2 | 平衡特征权重,提高稳定性 |
弹性网络:L1 与 L2 的结合
弹性网络(Elastic Net)结合了 L1 和 L2 正则化的优点,其数学表达式为:
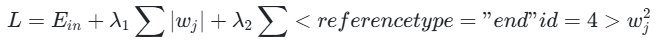
弹性网络能够同时实现特征选择和模型稳定,特别适用于高维且特征相关的场景(如基因组学、金融风控)。
数据增强型正则化方法
Dropout:神经网络中的随机失活
Dropout 是一种由 Hinton 等人在 2012年提出的神经网络正则化方法,它通过在训练过程中随机 "丢弃" 一部分神经元来提高模型的泛化能力。
工作原理: 在每次训练迭代时,Dropout 随机选择一部分神经元,使其暂时 "休眠",即这些神经元在当前迭代中不参与前向传播和反向传播。这种随机性使得网络在
每次迭代时都呈现出不同的结构,从而迫使网络中的其他神经元学习更加鲁棒的特征表示。
数学实现:
在训练阶段,对于每个神经元,以概率 p(丢弃率)将其输出置为 0,以概率 1-p 保留其输出:
python
$\hat{h}_i = \begin{cases} 0, & \text{概率为 } p \\ \frac{h_i}{1-p}, & \text{概率为 } 1-p \end{cases}$
python
其中,$\hat{h}_i$是经过Dropout处理后的神经元输出,$h_i$是原始输出。适用场景:
- 深度神经网络的全连接层
- 循环神经网络(RNN)和LSTM
- 卷积神经网络(CNN)的全连接层
优点:
- 简单有效,易于实现
- 减少神经元间的共适应
- 计算效率高,可并行处理
- 可与其他正则化方法结合
自适应Dropout实现
python
class DynamicDropout(nn.Module):
def __init__(self, base_p=0.5):
super(DynamicDropout, self).__init__()
self.base_p = base_p
def forward(self, x):
mean = x.mean()
std = x.std()
# 根据输入数据动态调整丢弃率
p = self.base_p * (std / (mean + 1e-9))
mask = torch.rand(x.shape) > p
return x * mask.float() / (1 - p) # 归一化输出数据增强:扩充训练样本的多样性
数据增强是一种通过对现有训练数据进行各种变换来生成新样本的正则化方法,它可以增加训练数据的多样性,提高模型的泛化能力。
图像数据增强
- 几何变换:旋转、翻转、平移
- 颜色调整:亮度、对比度
- 噪声添加:高斯噪声
- 裁剪与遮挡:Cutout
- 混合增强:Mixup、CutMix
文本数据增强
- 同义词替换
- 句子重组
- 插入或删除词语
- 回译(翻译再译回)
- 生成式增强(LLM)
音频数据增强
- 时间偏移
- 音高调整
- 音量调整
- 噪声添加
- 时间拉伸
PyTorch图像数据增强实现:
python
import torchvision.transforms as transforms
# 定义数据增强流程
transform = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转
transforms.RandomRotation(degrees=30), # 随机旋转30度
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.RandomResizedCrop(size=(224, 224), scale=(0.8, 1.0)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 应用数据增强
augmented_image = transform(original_image)噪声注入型正则化方法
样本标注引入噪声:提高模型鲁棒性
样本标注引入噪声是一种通过在训练数据的标签中添加随机噪声来防止过拟合的正则化方法。这种方法通过使模型对标签的轻微变化具有鲁棒性,从而提高模型的泛化能力。
噪声类型:
- 高斯噪声:添加服从高斯分布的连续噪声
- 类别翻转:随机翻转样本的类别标签
- 随机置换:随机置换多分类任务中的标签
- 椒盐噪声:将标签设置为最大值或最小值
PyTorch实现:
python
import torch
def add_label_noise(labels, noise_type='gaussian', sigma=0.1, flip_prob=0.1):
if noise_type == 'gaussian':
noisy_labels = labels + torch.randn_like(labels) * sigma
elif noise_type == 'flip':
flip_mask = torch.rand(labels.shape) < flip_prob
num_classes = labels.max().item() + 1
random_labels = torch.randint(0, num_classes, labels.shape)
noisy_labels = torch.where(flip_mask, random_labels, labels)
return noisy_labels
# 使用示例
clean_labels = torch.tensor([1, 2, 3, 4, 5])
noisy_labels = add_label_noise(clean_labels, noise_type='flip', flip_prob=0.1)适用场景:
- 标签存在固有不确定性的任务
- 训练数据量有限的场景
- 模型对标签过度敏感的情况
优点:
- 简单有效,易于实现
- 不需要额外的训练数据
- 可与其他正则化方法结合
- 提高模型对标签噪声的鲁棒性
半监督学习:利用未标注数据增强模型
半监督学习是一种利用少量标注数据和大量未标注数据进行模型训练的方法,它可以视为一种数据增强型的正则化技术。
主要方法:
- 生成式方法:使用GAN等生成模型
- 基于一致性的方法:Mean Teacher等
- 基于图的方法:利用图结构传播标签
- 自训练:使用伪标签扩展训练集
- 对比学习:学习数据的表征
- 一致性正则化:对扰动的不变性
半监督学习框架实现:
python
import torch
import torch.nn as nn
class SemiSupervisedModel(nn.Module):
def __init__(self, backbone):
super().__init__()
self.backbone = backbone
self.classifier = nn.Linear(backbone.out_features, num_classes)
def forward(self, x):
features = self.backbone(x)
logits = self.classifier(features)
return logits
def semi_supervised_train(model, labeled_loader, unlabeled_loader, optimizer, epochs):
criterion_supervised = nn.CrossEntropyLoss()
criterion_unsupervised = nn.MSELoss()
for epoch in range(epochs):
# 监督训练
for (x_l, y_l) in labeled_loader:
logits_l = model(x_l)
loss_supervised = criterion_supervised(logits_l, y_l)
optimizer.zero_grad()
loss_supervised.backward()
optimizer.step()
# 无监督训练(一致性损失)
for (x_u, _) in unlabeled_loader:
x_u_aug1 = augment(x_u)
x_u_aug2 = augment(x_u)
logits_u1 = model(x_u_aug1)
logits_u2 = model(x_u_aug2)
loss_unsupervised = criterion_unsupervised(logits_u1, logits_u2)
optimizer.zero_grad()
loss_unsupervised.backward()
optimizer.step()模型结构型正则化方法
多任务学习:共享表示与知识迁移
多任务学习是一种通过同时学习多个相关任务来提高模型泛化能力的方法,它可以视为一种模型结构型的正则化技术。
模型架构:
多任务学习模型通常采用共享-特定架构,其中:
共享层:所有任务共享的底层特征提取器
特定层:每个任务独有的顶层分类器或回归器
数学形式:
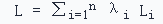
其中,Li是第i个任务的损失函数,λi是第i个任务的权重。
适用场景:
- 多个相关任务需要同时解决的场景
- 主任务数据量有限,但有辅助任务数据
- 自动驾驶中的多传感器融合
优点:
- 提高主任务的泛化能力
- 减少过拟合,学习更通用的特征
- 提高计算效率,共享底层计算
- 利用多个任务的监督信号
提前终止:控制训练过程的正则化
提前终止(Early Stopping)是一种通过在验证损失不再改善时停止训练来防止过拟合的正则化方法。
实现方式:
- 将数据集划分为训练集、验证集和测试集
- 在训练过程中,定期在验证集上评估模型性能
- 记录当前最佳验证性能和对应的模型参数
- 如果验证性能在指定迭代次数内没有改善,则停止训练
- 恢复最佳模型参数作为最终模型
PyTorch实现:
python
import torch
class EarlyStopping:
def __init__(self, patience=5, verbose=False):
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.best_model = None
def __call__(self, val_loss, model):
if self.best_score is None:
self.best_score = val_loss
self.save_checkpoint(val_loss, model)
elif val_loss >= self.best_score:
self.counter += 1
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = val_loss
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
if self.verbose:
print(f'Validation loss decreased ({self.best_score:.6f} --> {val_loss:.6f}). Saving model ...')
self.best_model = model.state_dict().copy()
# 使用示例
early_stopping = EarlyStopping(patience=3, verbose=True)
for epoch in range(num_epochs):
train_loss = train_model(model, train_loader, optimizer)
val_loss = evaluate_model(model, val_loader)
early_stopping(val_loss, model)
if early_stopping.early_stop:
print("Early stopping")
break
# 恢复最佳模型参数
model.load_state_dict(early_stopping.best_model)正则化方法的对比分析与选择指南
正则化方法的多维度对比
| 正则化方法 | 核心原理 | 主要优点 | 计算复杂度 | 适用场景 |
|---|---|---|---|---|
| L1正则化 | 权重绝对值惩罚 | 特征选择,稀疏解 | 高 | 高维稀疏数据 |
| L2正则化 | 权重平方惩罚 | 优化稳定,适合相关特征 | 中高 | 特征相关场景 |
| Dropout | 随机丢弃神经元 | 简单有效,减少共适应 | 中 | 深度神经网络 |
| 数据增强 | 数据变换生成新样本 | 增加数据多样性 | 高 | 图像、文本、音频 |
| 样本标注噪声 | 标签添加随机噪声 | 简单有效,增强鲁棒性 | 低 | 标签不确定任务 |
| 半监督学习 | 利用未标注数据 | 减少标注需求 | 高 | 标注数据稀缺 |
| 多任务学习 | 共享特征表示 | 促进知识迁移 | 高 | 多个相关任务 |
| 提前终止 | 验证损失停止时终止 | 简单有效,减少计算 | 低 | 各种深度学习任务 |