1. 简介
ViT是2020年Google团队提出的将Transformer应用在图像分类的模型。
ViT原论文中最核心的结论是,当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。
但是当训练数据集不够大的时候,ViT的表现通常比同等大小的ResNets要差一些,因为Transformer和CNN相比缺少归纳偏置(inductive bias),即一种先验知识,提前做好的假设。
CNN具有两种归纳偏置,一种是局部性 (locality/two-dimensional neighborhood structure),即图片上相邻的区域具有相似的特征;一种是平移不变形 (translation equivariance), f(g(x))=g(f(x)),其中g代表卷积操作,f代表平移操作。
当CNN具有以上两种归纳偏置,就有了很多先验信息,需要相对少的数据就可以学习一个比较好的模型。
2. ViT模型架构
ViT的工作流程,如下:
- 将一张图片分成patches
- 将patches铺平
- 将铺平后的patches的线性映射到更低维的空间
- 添加位置embedding编码信息
- 将图像序列数据送入标准Transformer encoder中去
- 在较大的数据集上预训练
- 在下游数据集上微调用于图像分类
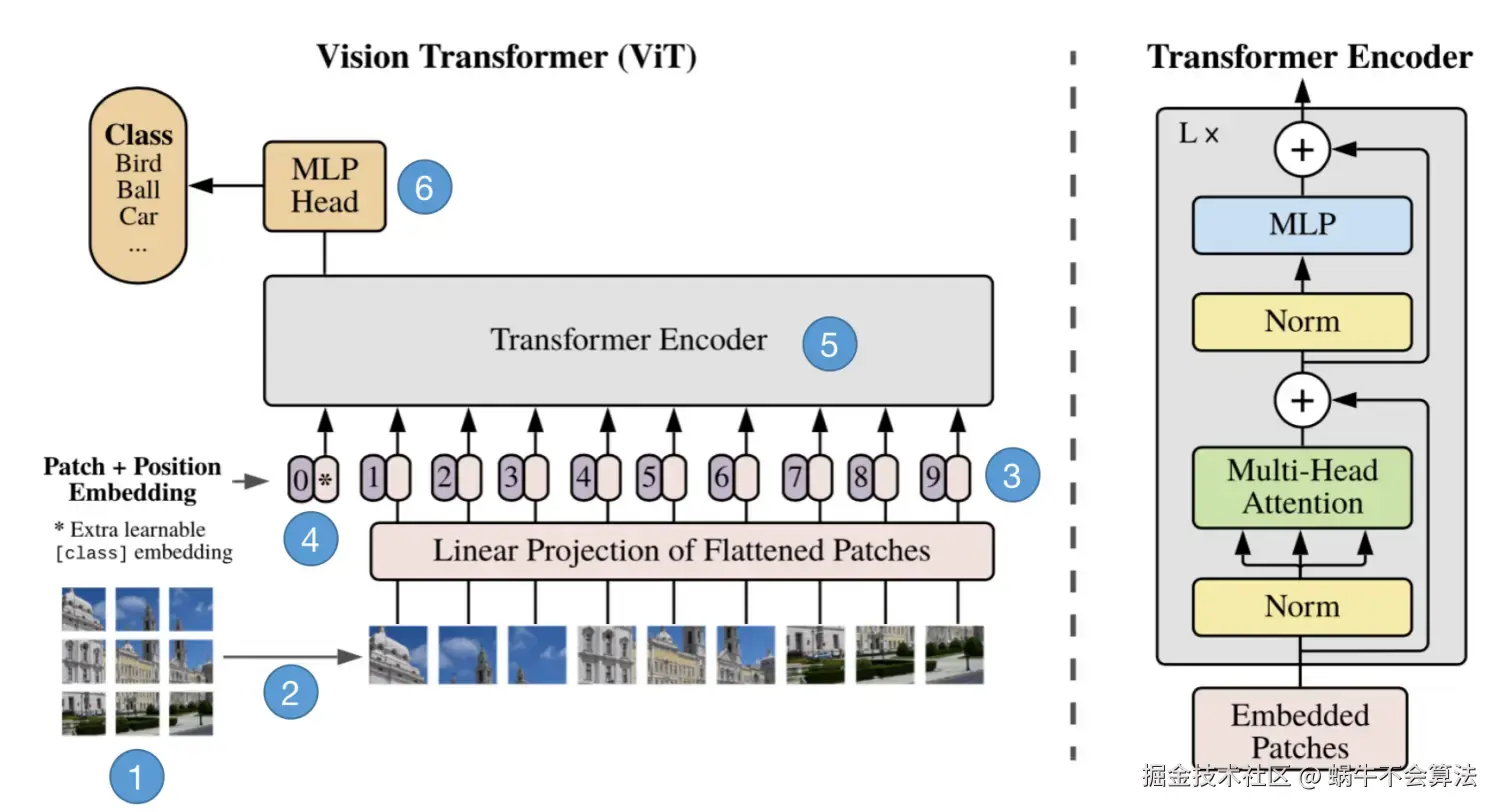
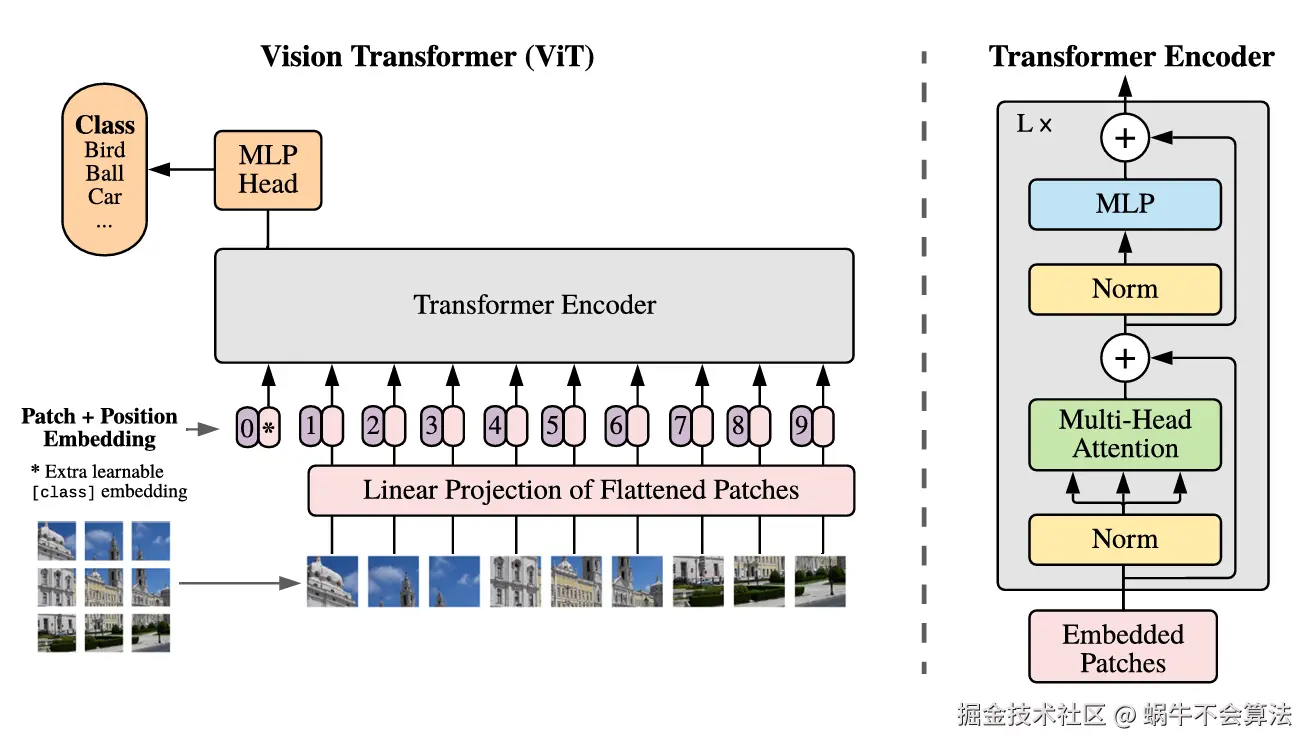 模型由三个模块组成:
模型由三个模块组成:
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder
- MLP Head(最终用于分类的层结构)
Embedding层
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵 num_token, token_dim,如下图,token0-9对应的都是向量,以ViT-B/16为例,每个token向量长度为768。
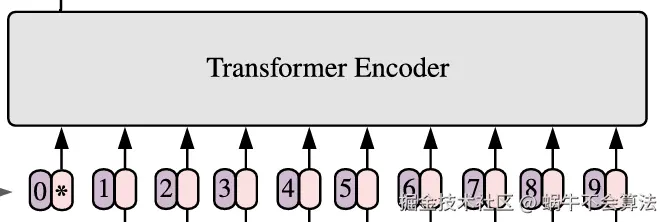
对于图像数据而言,其数据格式为H, W, C是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。如下图所示,首先将一张图片按给定大小分成一堆Patches。以ViT-B /16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到196个Patches。接着通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为16, 16, 3通过映射得到一个长度为768的向量(后面都直接称为token)。16, 16, 3 -> 768
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积224, 224, 3 -> 14, 14, 768,然后把H以及W两个维度展平即可14, 14, 768 -> 196, 768,此时正好变成了一个二维矩阵,正是Transformer想要的。
Transformer Encoder
Transformer Encoder其实就是重复堆叠Encoder Block L次,主要由Layer Norm、Multi-Head Attention 、Dropout和MLP Block几部分组成。
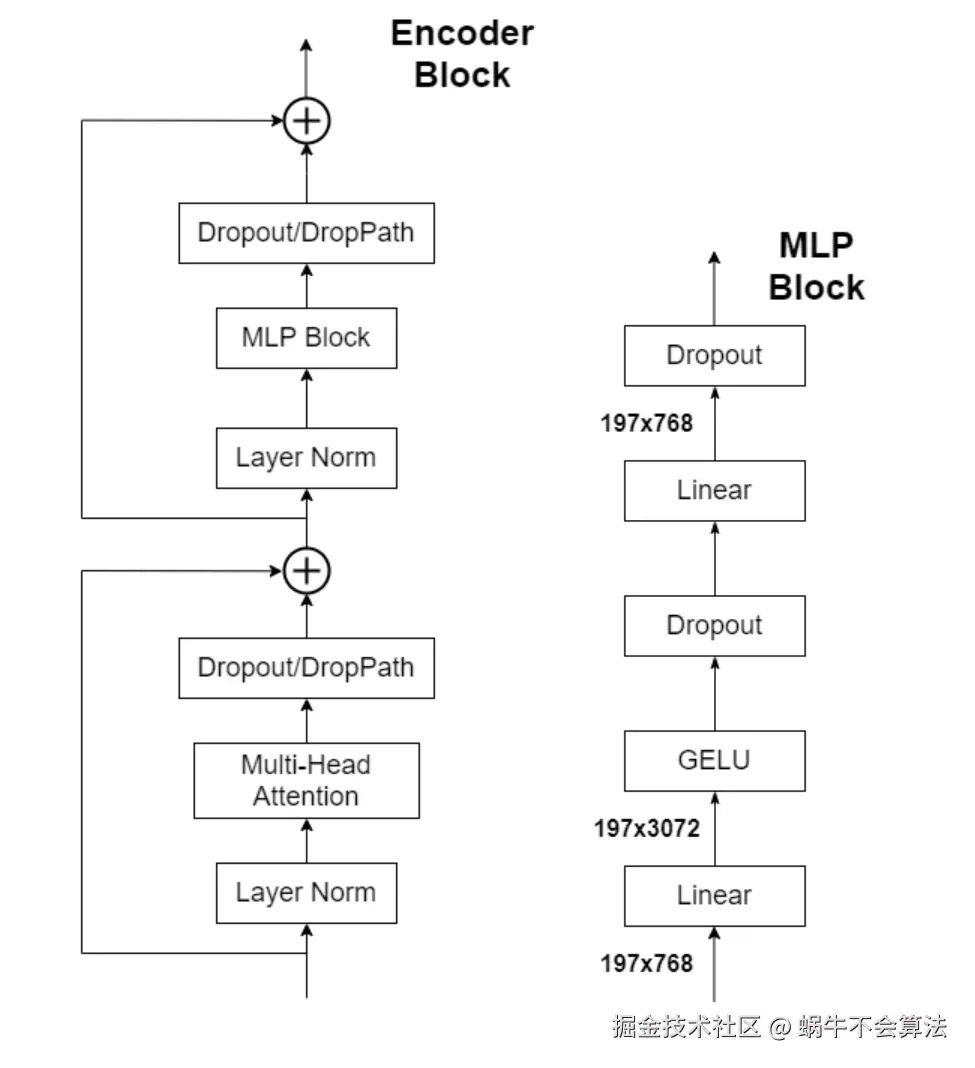
MLP Head
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是197, 768输出的还是197, 768。这里我们只是需要分类的信息,所以我们只需要提取出classtoken生成的对应结果就行,即197, 768中抽取出classtoken对应的1, 768。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
3. ViT工作原理

4. 模型搭建参数
论文的Table1中有给出三个模型(Base/ Large/ Huge)的参数
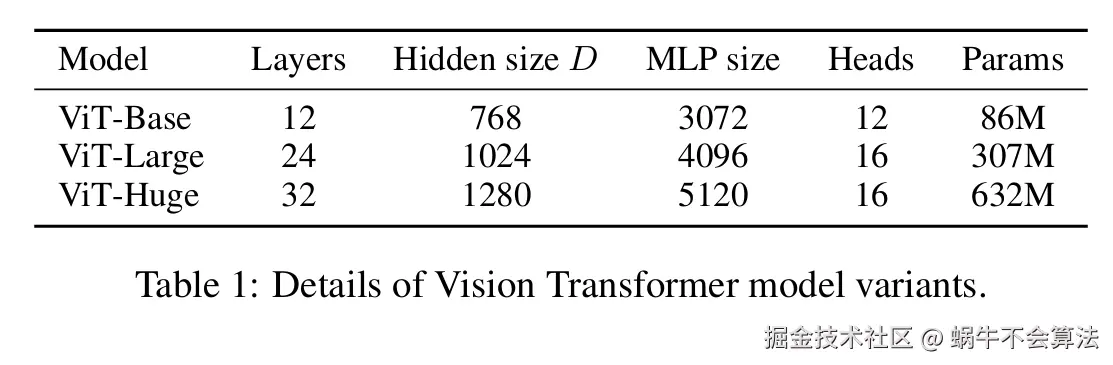
- Layers就是Transformer Encoder中重复堆叠Encoder Block的次数 L。
- Hidden Size就是对应通过Embedding层(Patch Embedding + Class Embedding + Position Embedding)后每个token的dim(序列向量的长度)
- MLP Size是Transformer Encoder中MLP Block第一个全连接的节点个数(是token长度的4倍)
- Heads代表Transformer中Multi-Head Attention的heads数。
5. ViT进行迁移学习
一、下载源码和预训练模型
- 官方源码
- Google Research的官方实现 :github.com/google-rese...
- Hugging Face Transformers (最常用):github.com/huggingface...
- timm库 (PyTorch图像模型库):github.com/rwightman/p...
- 预训练模型下载
python
# 通过timm下载(最简单)
import timm
model = timm.create_model('vit_base_patch16_224', pretrained=True)
# 通过HuggingFace下载
from transformers import ViTModel
model = ViTModel.from_pretrained('google/vit-base-patch16-224')二、训练前的修改步骤
1. 修改分类头
python
import torch.nn as nn
import timm
# 加载预训练模型
model = timm.create_model('vit_base_patch16_224', pretrained=True)
# 获取原始分类头特征维度
num_features = model.head.in_features
# 替换为自己的分类头(假设你的数据集有10类)
model.head = nn.Linear(num_features, 10)
# 或者更复杂的分类头
model.head = nn.Sequential(
nn.Linear(num_features, 512),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(512, 10)
)2. 调整输入尺寸
python
# 如果图像尺寸不是224x224,可以选择:
# 方案1:resize图像到224x224
from torchvision import transforms
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
# 方案2:使用支持其他尺寸的ViT变体
model = timm.create_model('vit_base_patch16_384', pretrained=True) # 384x3843. 配置训练策略
python
# 冻结部分层(可选)
# 冻结所有层
for param in model.parameters():
param.requires_grad = False
# 只解冻分类头
for param in model.head.parameters():
param.requires_grad = True
# 或者解冻最后几层
for name, param in model.named_parameters():
if 'blocks.11' in name or 'head' in name: # 解冻最后一个block和分类头
param.requires_grad = True三、完整的迁移学习示例
python
import torch
import torch.nn as nn
import timm
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 1. 数据准备
transform_train = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载你的数据集
train_dataset = datasets.ImageFolder('path/to/train', transform=transform_train)
test_dataset = datasets.ImageFolder('path/to/test', transform=transform_test)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 2. 加载预训练模型并修改
model = timm.create_model('vit_base_patch16_224', pretrained=True)
# 获取类别数
num_classes = len(train_dataset.classes)
# 替换分类头
model.head = nn.Linear(model.head.in_features, num_classes)
# 3. 训练配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 不同层使用不同学习率
optimizer = torch.optim.Adam([
{'params': model.patch_embed.parameters(), 'lr': 1e-5},
{'params': model.blocks.parameters(), 'lr': 1e-5},
{'params': model.head.parameters(), 'lr': 1e-4}
], weight_decay=1e-4)
criterion = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=50)
# 4. 训练循环
for epoch in range(50):
model.train()
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
scheduler.step()
# 验证
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Epoch {epoch}: Accuracy: {100 * correct / total:.2f}%')- 学习率:通常比从头训练小10-100倍(1e-4到1e-5)
- Batch Size:根据GPU内存调整,ViT通常需要较小的batch size(16-64)
- Epochs:迁移学习通常20-50个epochs就够了
- 数据增强:对特定场景很重要,可以提高泛化能力
详解VIT(Vision Transformer)模型原理, 代码级讲解