1. 论文摘要介绍表格
| 项目 | 内容 |
|---|---|
| 研究背景 | 意图分类和槽位填充是 NLU 的核心任务,但面临人工标注数据少、泛化难(尤其是罕见词)的问题。 |
| 现有问题 | 传统的 RNN/LSTM 模型依赖大量标注数据;现有的联合学习方法虽然有效,但仍受限于数据稀疏性。 |
| 核心创新点 | 1. 引入 BERT :首次深入探索利用 BERT 预训练模型解决 NLU 的泛化问题。 2. 联合建模 :提出了一个基于 BERT 的端到端联合模型,同时输出意图和槽位标签。 3. 架构简单有效:仅使用 BERT 编码器加简单的 Softmax 层(或可选 CRF),即超越了复杂的特定设计模型。 |
| 主要成果 | 在 Snips 和 ATIS 数据集上刷新了 SOTA(State-of-the-Art)。 尤其在 Snips 数据集上,句子级准确率从 75.5% 提升至 92.8%。 |
| 关键技术 | BERT Encoder + CLS 用于意图分类 + 序列输出用于槽位填充 + 联合损失函数。 |
2. 论文具体实现流程
该论文的模型实现逻辑清晰,属于典型的"预训练+微调"范式。
2.1 输入 (Input)
- 原始数据:用户的一句自然语言指令(Query),例如 "Play the song little robin redbreast"。
- 预处理 :
- 分词:使用 WordPiece tokenizer 将句子切分为子词(Sub-tokens)。
- 特殊标记 :
- 句首插入
[CLS](用于分类的标记)。 - 句尾插入
[SEP](用于分隔的标记)。
- 句首插入
- Embedding:将 Token 转换为向量,包含 WordPiece Embedding、Position Embedding(位置嵌入)和 Segment Embedding(段嵌入,此处全为0)。
2.2 核心流转逻辑 (Process)
-
BERT 编码器:
- 输入序列 x=(x1,...,xT)x = (x_1, \dots, x_T)x=(x1,...,xT) 进入多层双向 Transformer。
- 输出 :得到每个 Token 对应的上下文隐藏状态向量 H=(h1,...,hT)\mathbf{H} = (\boldsymbol{h}_1, \dots, \boldsymbol{h}_T)H=(h1,...,hT)。
-
任务分支 1:意图分类 (Intent Classification)
- 提取特征 :取第一个 Token
[CLS]的隐藏状态 h1\boldsymbol{h}_1h1。 - 计算 :通过一个全连接层和 Softmax 函数:yi=softmax(Wih1+bi)y^i = \text{softmax}(\mathbf{W}^i \boldsymbol{h}_1 + \boldsymbol{b}^i)yi=softmax(Wih1+bi)。
- 输出 :预测该句子的整体意图(如
PlayMusic)。
- 提取特征 :取第一个 Token
-
任务分支 2:槽位填充 (Slot Filling)
- 提取特征 :取除
[CLS]外的每个单词第一个子 Token 的隐藏状态 h2,...,hT\boldsymbol{h}_2, \dots, \boldsymbol{h}_Th2,...,hT。 - 计算 :
- 基础版 :每个位置独立通过 Softmax 层分类:yns=softmax(Wshn+bs)y^s_n = \text{softmax}(\mathbf{W}^s \boldsymbol{h}_n + \boldsymbol{b}^s)yns=softmax(Wshn+bs)。
- 进阶版 (+CRF) :将隐藏状态序列输入条件随机场(CRF)层,以建模标签之间的前后依赖关系(如
B-movie后通常接I-movie)。
- 输出 :预测每个单词的槽位标签(如
O,B-song,I-song等)。
- 提取特征 :取除
-
联合训练 (Joint Training)
- 损失函数:将意图分类的损失和槽位填充的损失相加(公式 3),进行端到端的梯度下降优化。
2.3 输出 (Output)
- 一个完整的语义框架(Semantic Frame),包含:
- 意图 :如
SearchScreeningEvent。 - 槽位 :提取出的实体及其类型,如
movie_name = mother joan of the angels。
- 意图 :如
3. 有趣的白话版详细解说
想象一下,你雇了一个超级学霸助理(我们叫他 BERT),他的任务是听懂用户的命令(比如"帮我放首周杰伦的歌")。为了听懂这句话,他需要做两件事:
- 猜意图(Intent):你要干嘛?(哦,是要"播放音乐")。
- 填槽位(Slot):关键词是啥?("周杰伦"是歌手)。
以前的笨办法(RNN/LSTM)
在 BERT 出现之前,以前的模型像是一个死记硬背的小学生。你给它一堆标注好的数据训练它,它就逐字逐字地读:"帮...我...放..."。它能学会简单的规律,但如果遇到它没见过的生僻词,或者句子结构稍微变态一点,它就懵圈了。比如你说"Mother Joan of the Angels",它可能以为这是个人名或者餐厅名字,因为它没见过这电影。
BERT 为什么牛?
BERT 就像是一个博览群书的博士。在来干这个活之前,他已经把维基百科和海量的书都读了一遍(预训练)。
- 当遇到"Mother Joan of the Angels"时,以前的模型在抓瞎,BERT 却会想:"嘿,我在维基百科上读过这个,这是一部 1961 年的波兰电影!"
- 所以,BERT 不仅依靠你给它的那点训练数据,它还带着它原本的"常识"。这就是论文里一直强调的泛化能力。
联合模型(Joint Model)是啥意思?
以前有些方法是把"猜意图"和"找关键词"分成两个人干。
- A 说:我觉得他在点歌。
- B 说:我觉得"周杰伦"是个菜名。
这俩人没商量,结果就搞笑了。
这篇论文的作者让 BERT 一个人同时干两件事 (联合模型)。
BERT 读完句子后,左手写意图(播放音乐),右手写槽位(歌手=周杰伦)。因为是一个大脑在控制,如果意图是"播放音乐",通过关联,他就不太可能把"周杰伦"标记成菜名。这就叫联合建模,互相辅助。
结果怎么样?
作者把 BERT 拉去跟以前的冠军模型(BiLSTM, Slot-Gated 等)比试了一下。
结果 BERT 完爆全场。特别是在那种很难的数据集(Snips)上,准确率提升了一大截。而且作者发现,只训练 BERT 一两个回合(Epoch),它的表现就已经超过了以前训练了很久的老模型。这就是知识储备的力量!
个人观点与理解
这篇论文是 NLU 领域的一个经典转折点。虽然它的架构看起来非常简单(基本上就是拿原生 BERT 加了两个输出头),但它证明了"大力出奇迹" 在 NLP 领域的适用性。
- 预训练的胜利:它再次证明了,与其绞尽脑汁设计复杂的网络结构(什么门控、注意力机制堆叠),不如直接用一个在大规模数据上预训练好的强力底座(Base)。
- 降维打击:之前的研究还在纠结如何通过复杂的机制解决"生僻词"问题,BERT 直接通过预训练把这些生僻词"背"下来了,这是一种高维度的降维打击。
- 极简主义:Joint BERT + CRF 的结构非常优雅,成为了后来工业界落地 NLU 任务的标准范式之一。因为它既快(推理时),效果又好,还省去了复杂的特征工程。
4.论文翻译
摘要
意图分类(Intent Classification)和槽位填充(Slot Filling)是自然语言理解(NLU)的两个基本任务。它们通常受限于小规模的人工标注训练数据,导致泛化能力较差,特别是对于罕见词汇。最近,一种新的语言表示模型 BERT(Bidirectional Encoder Representations from Transformers,来自 Transformer 的双向编码器表示)通过在从大规模未标注语料库上进行预训练,促进了深度双向表示的学习,并在简单的微调之后,在各种自然语言处理任务中创建了最先进(SOTA)的模型。然而,目前尚未有太多工作探索将 BERT 用于自然语言理解。在这项工作中,我们提出了一种基于 BERT 的联合意图分类和槽位填充模型。实验结果表明,与基于注意力的循环神经网络模型和槽位门控(slot-gated)模型相比,我们提出的模型在几个公共基准数据集上的意图分类准确率、槽位填充 F1 值和句子级语义框架准确率方面均取得了显著提升。
1 介绍
近年来,各种智能音箱已被广泛部署并取得了巨大成功,如 Google Home、Amazon Echo、天猫精灵等,它们促进了目标导向的对话,并帮助用户通过语音交互完成任务。自然语言理解(NLU)对于目标导向的口语对话系统的性能至关重要。NLU 通常包括意图分类和槽位填充任务,旨在为用户的话语形成语义解析。意图分类侧重于预测查询的意图,而槽位填充则提取语义概念。表 1 展示了用户查询"Find me a movie by Steven Spielberg"(帮我找一部斯蒂芬·斯皮尔伯格的电影)的意图分类和槽位填充示例。
注: Ongoing work(正在进行的工作)。
| Query (查询) | Find me a movie by Steven Spielberg |
|---|---|
| Frame (框架) | Intent (意图) : find_movie (寻找电影) Slot (槽位) : genre (类型) = movie directed_by (导演) = Steven Spielberg |
表 1:从用户查询到语义框架的示例。
意图分类是一个预测意图标签 yiy^iyi 的分类问题,而槽位填充是一个序列标注任务,将输入词序列 x=(x1,x2,⋯ ,xT)x = (x_1, x_2, \cdots, x_T)x=(x1,x2,⋯,xT) 标记为槽位标签序列 ys=(y1s,y2s,⋯ ,yTs)y^s = (y^s_1, y^s_2, \cdots, y^s_T)ys=(y1s,y2s,⋯,yTs)。基于循环神经网络(RNN)的方法,特别是门控循环单元(GRU)和长短期记忆(LSTM)模型,在意图分类和槽位填充方面已经取得了最先进的性能。最近,提出了几种用于意图分类和槽位填充的联合学习方法,以利用和建模两个任务之间的依赖关系,并提高优于独立模型的性能(Guo et al., 2014; Hakkani-Tur et al., 2016; Liu and Lane, 2016; Goo et al., 2018)。先前的工作表明,注意力机制(Bahdanau et al., 2014)有助于 RNN 处理长距离依赖。因此,提出了基于注意力的联合学习方法,并在联合意图分类和槽位填充方面取得了最先进的性能(Liu and Lane, 2016; Goo et al., 2018)。
NLU 和其他自然语言处理(NLP)任务缺乏人工标注数据,导致泛化能力较差。为了解决数据稀疏的挑战,提出了各种技术,利用大量的未标注文本训练通用语言表示模型,如 ELMo(Peters et al., 2018)和生成式预训练 Transformer(GPT)(Radford et al., 2018)。预训练模型可以在 NLP 任务上进行微调,并比在特定任务标注数据上训练取得了显著的改进。最近,提出了一种预训练技术------来自 Transformer 的双向编码器表示(BERT)(Devlin et al., 2018),它为包括问答(SQuAD v1.1)、自然语言推理等在内的各种 NLP 任务创建了最先进的模型。
然而,目前尚未有太多工作探索将 BERT 用于 NLU。本文的技术贡献主要体现在两方面:1)我们探索了 BERT 预训练模型以解决 NLU 泛化能力差的问题;2)我们提出了一种基于 BERT 的联合意图分类和槽位填充模型,并证明与基于注意力的 RNN 模型和槽位门控模型相比,所提出的模型在几个公共基准数据集上的意图分类准确率、槽位填充 F1 值和句子级语义框架准确率方面取得了显著提升。
2 相关工作
深度学习模型在 NLU 中得到了广泛探索。根据意图分类和槽位填充是单独建模还是联合建模,我们将 NLU 模型分为独立建模方法和联合建模方法。
意图分类的方法包括 CNN(Kim, 2014; Zhang et al., 2015)、LSTM(Ravuri and Stolcke, 2015)、基于注意力的 CNN(Zhao and Wu, 2016)、分层注意力网络(Yang et al., 2016)、对抗性多任务学习(Liu et al., 2017)等。槽位填充的方法包括 CNN(Vu, 2016)、深度 LSTM(Yao et al., 2014)、RNN-EM(Peng et al., 2015)、编码器-标注器深度 LSTM(Kurata et al., 2016)以及联合指针和注意力机制(Zhao and Feng, 2018)等。
联合建模方法包括 CNN-CRF(Xu and Sarikaya, 2013)、RecNN(Guo et al., 2014)、联合 RNN-LSTM(Hakkani-Tur et al., 2016)、基于注意力的 BiRNN(Liu and Lane, 2016)和槽位门控注意力模型(Goo et al., 2018)。
3 提出的方法
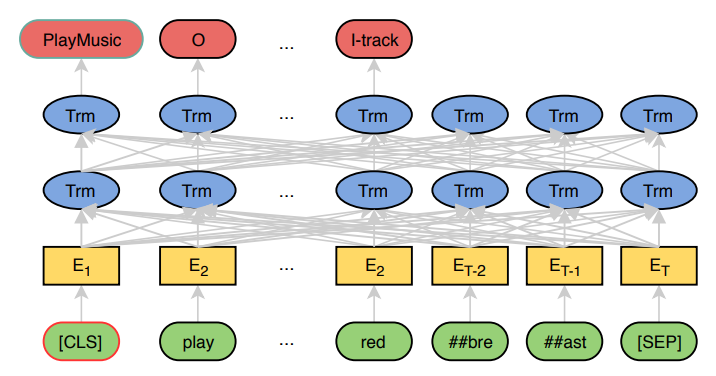
我们首先简要描述 BERT 模型(Devlin et al., 2018),然后介绍基于 BERT 的联合模型。图 1 展示了所提出模型的高层视图。
图1 描述:模型架构图。底部是输入层,显示输入查询为"\[CLS\] play ##bre ##ast \[SEP\]"。中间是 BERT 编码器层,包含多层 Transformer(Trm)。顶部是输出层,对于 \[CLS\] 位置输出意图分类结果(如 PlayMusic),对于序列中的每个 token 输出槽位标签(如 O, O, I-track)。
图 1:所提出模型的高层视图。输入查询是"play the song little robin redbreast"。
3.1 BERT
BERT 的模型架构是基于原始 Transformer 模型(Vaswani et al., 2017)的多层双向 Transformer 编码器。输入表示是 WordPiece 嵌入(Wu et al., 2016)、位置嵌入和段嵌入的拼接。特别地,对于单句分类和标注任务,段嵌入没有区别。特殊的分类嵌入(CLS)作为第一个 token 插入,特殊的 token(SEP)作为最后一个 token 添加。给定一个输入 token 序列 x=(x1,...,xT)x = (x_1, \dots, x_T)x=(x1,...,xT),BERT 的输出是 H=(h1,...,hT)\mathbf{H} = (\boldsymbol{h}_1, \dots, \boldsymbol{h}_T)H=(h1,...,hT)。
BERT 模型使用两种策略在大规模未标注文本上进行预训练,即掩码语言模型(Masked Language Model)和下一句预测(Next Sentence Prediction)。预训练的 BERT 模型提供了强大的上下文相关句子表示,并可以通过微调过程用于各种目标任务,即意图分类和槽位填充,类似于它用于其他 NLP 任务的方式。
3.2 联合意图分类和槽位填充
BERT 可以很容易地扩展为联合意图分类和槽位填充模型。基于第一个特殊 token(CLS)的隐藏状态(记为 h1\boldsymbol{h}_1h1),意图预测如下:
yi=softmax(Wih1+bi),(1)y^i = \text{softmax}(\mathbf{W}^i \boldsymbol{h}_1 + \boldsymbol{b}^i), \quad (1)yi=softmax(Wih1+bi),(1)
对于槽位填充,我们将其他 token 的最终隐藏状态 h2,...,hT\boldsymbol{h}_2, \dots, \boldsymbol{h}_Th2,...,hT 输入到 softmax 层,以对槽位填充标签进行分类。为了使此过程与 WordPiece 分词兼容,我们将每个分词后的输入词输入到 WordPiece 分词器中,并使用对应于第一个子 token 的隐藏状态作为 softmax 分类器的输入。
yns=softmax(Wshn+bs),n∈1...N(2)y^s_n = \text{softmax}(\mathbf{W}^s \boldsymbol{h}_n + \boldsymbol{b}^s), \quad n \in 1 \dots N \quad (2)yns=softmax(Wshn+bs),n∈1...N(2)
其中 hn\boldsymbol{h}_nhn 是对应于词 xnx_nxn 的第一个子 token 的隐藏状态。
为了联合建模意图分类和槽位填充,目标函数公式化为:
p(yi,ys∣x)=p(yi∣x)∏n=1Np(yns∣x),(3)p(y^i, y^s | x) = p(y^i | x) \prod_{n=1}^{N} p(y^s_n | x), \quad (3)p(yi,ys∣x)=p(yi∣x)n=1∏Np(yns∣x),(3)
学习目标是最大化条件概率 p(yi,ys∣x)p(y^i, y^s | x)p(yi,ys∣x)。通过最小化交叉熵损失,对模型进行端到端的微调。
3.3 条件随机场 (Conditional Random Field)
槽位标签的预测依赖于周围单词的预测。已有研究表明,结构化预测模型(如条件随机场 CRF)可以提高槽位填充性能。Zhou 和 Xu (2015) 通过在 BiLSTM 编码器后添加 CRF 层改进了语义角色标注。在这里,我们研究在联合 BERT 模型之上添加 CRF 以建模槽位标签依赖关系的有效性。
4 实验与分析
我们在两个公共基准数据集 ATIS 和 Snips 上评估了所提出的模型。
4.1 数据
ATIS 数据集(Tur et al., 2010)广泛用于 NLU 研究,包括人们预订航班的录音。我们使用与 Goo et al. (2018) 相同的数据划分用于这两个数据集。训练集、开发集和测试集分别包含 4,478、500 和 893 条语句。训练集有 120 个槽位标签和 21 种意图类型。我们还使用了 Snips(Coucke et al., 2018),它是从 Snips 个人语音助手收集的。训练集、开发集和测试集分别包含 13,084、700 和 700 条语句。训练集有 72 个槽位标签和 7 种意图类型。
4.2 训练细节
我们使用英文不区分大小写的 BERT-Base 模型(见脚注1),它有 12 层,768 个隐藏状态和 12 个头。BERT 在 BooksCorpus(8 亿词)(Zhu et al., 2015)和英语维基百科(25 亿词)上进行预训练。对于微调,所有超参数都在开发集上进行调整。最大长度为 50。批量大小为 128。使用 Adam(Kingma and Ba, 2014)进行优化,初始学习率为 5e-5。Dropout 概率为 0.1。最大 epoch 数选自 1, 5, 10, 20, 30, 40。
4.3 结果
表 2:Snips 和 ATIS 数据集上的 NLU 性能。指标包括意图分类准确率、槽位填充 F1 值和句子级语义框架准确率(%)。第一组模型的结果引用自 Goo et al. (2018)。
| Models (模型) | Snips Intent | Snips Slot | Snips Sent | ATIS Intent | ATIS Slot | ATIS Sent |
|---|---|---|---|---|---|---|
| RNN-LSTM (Hakkani-Tur et al., 2016) | 96.9 | 87.3 | 73.2 | 92.6 | 94.3 | 80.7 |
| Atten.-BiRNN (Liu and Lane, 2016) | 96.7 | 87.8 | 74.1 | 91.1 | 94.2 | 78.9 |
| Slot-Gated (Goo et al., 2018) | 97.0 | 88.8 | 75.5 | 94.1 | 95.2 | 82.6 |
| Joint BERT | 98.6 | 97.0 | 92.8 | 97.5 | 96.1 | 88.2 |
| Joint BERT + CRF | 98.4 | 96.7 | 92.6 | 97.9 | 96.0 | 88.6 |
表 3:Snips 数据集的消融分析。
| Model | Epochs | Intent | Slot |
|---|---|---|---|
| Joint BERT | 30 | 98.6 | 97.0 |
| No joint | 30 | 98.0 | 95.8 |
| Joint BERT | 40 | 98.3 | 96.4 |
| Joint BERT | 20 | 99.0 | 96.0 |
| Joint BERT | 10 | 98.6 | 96.5 |
| Joint BERT | 5 | 98.0 | 95.1 |
| Joint BERT | 1 | 98.0 | 93.3 |
表 2 展示了模型在 Snips 和 ATIS 数据集上的槽位填充 F1、意图分类准确率和句子级语义框架准确率的表现。
第一组模型是基线,由最先进的联合意图分类和槽位填充模型组成:使用 BiLSTM 的基于序列的联合模型(Hakkani-Tur et al., 2016),基于注意力的模型(Liu and Lane, 2016)和槽位门控模型(Goo et al., 2018)。
第二组模型包括提出的联合 BERT 模型。从 表 2 可以看出,联合 BERT 模型在两个数据集上均显著优于基线模型。在 Snips 上,联合 BERT 实现了 98.6% 的意图分类准确率(原 97.0%),97.0% 的槽位填充 F1(原 88.8%),以及 92.8% 的句子级语义框架准确率(原 75.5%)。在 ATIS 上,联合 BERT 实现了 97.5% 的意图分类准确率(原 94.1%),96.1% 的槽位填充 F1(原 95.2%),以及 88.2% 的句子级语义框架准确率(原 82.6%)。Joint BERT+CRF 用 CRF 替换了 softmax 分类器,其表现与 BERT 相当,这可能是因为 Transformer 中的自注意力机制已经充分建模了标签结构。
与 ATIS 相比,Snips 包含多个领域并且词汇量更大。对于更复杂的 Snips 数据集,联合 BERT 在句子级语义框架准确率上取得了巨大的增益,从 75.5% 提高到 92.8%(相对提升 22.9%)。这展示了联合 BERT 模型强大的泛化能力,考虑到它是在来自不匹配领域和体裁(书籍和维基百科)的大规模文本上预训练的。在 ATIS 上,联合 BERT 在句子级语义框架准确率上也取得了显著改进,从 82.6% 提高到 88.2%(相对提升 6.8%)。
4.4 消融分析与案例研究
我们在 Snips 上进行了消融分析,如 表 3 所示。如果不进行联合学习,意图分类的准确率下降到 98.0%(从 98.6%),槽位填充 F1 下降到 95.8%(从 97.0%)。我们还比较了不同微调 epoch 下的联合 BERT 模型。仅微调 1 个 epoch 的联合 BERT 模型已经优于 表 2 中的第一组模型。
我们进一步从 Snips 中选择了一个案例,如 表 4 所示,展示了联合 BERT 如何通过利用 BERT 的语言表示能力来优于槽位门控模型(Goo et al., 2018)从而提高泛化能力。在这个案例中,"mother joan of the angels"(《修女乔安娜》)被槽位门控模型错误地预测为对象名称,意图也是错误的。然而,联合 BERT 正确预测了槽位标签和意图,因为"mother joan of the angels"是维基百科中的一个电影条目。BERT 模型部分是在维基百科上预训练的,并且可能学到了关于这个罕见短语的信息。
表 4:Snips 数据集中的一个案例。
| Query (查询) | need to see mother joan of the angels in one second |
|---|---|
| Gold, predicted by joint BERT correctly (标准答案,联合 BERT 预测正确) | Intent : SearchScreeningEvent (搜索放映事件) Slots: O O O B-movie-name I-movie-name I-movie-name I-movie-name I-movie-name B-timeRange I-timeRange I-timeRange |
| Predicted by Slot-Gated Model (槽位门控模型预测) | Intent : BookRestaurant (预订餐厅) Slots: O O O B-object-name I-object-name I-object-name I-object-name I-object-name B-timeRange I-timeRange I-timeRange |
5 结论
我们提出了一种基于 BERT 的联合意图分类和槽位填充模型,旨在解决传统 NLU 模型泛化能力差的问题。实验结果表明,我们提出的联合 BERT 模型优于分别建模意图分类和槽位填充的 BERT 模型,证明了利用两个任务之间关系的有效性。我们提出的联合 BERT 模型在 ATIS 和 Snips 数据集上的意图分类准确率、槽位填充 F1 和句子级语义框架准确率方面,相比之前的 SOTA 模型取得了显著提升。未来的工作包括在更大规模和更复杂的 NLU 数据集上评估所提出的方法,并探索将外部知识与 BERT 结合的有效性。