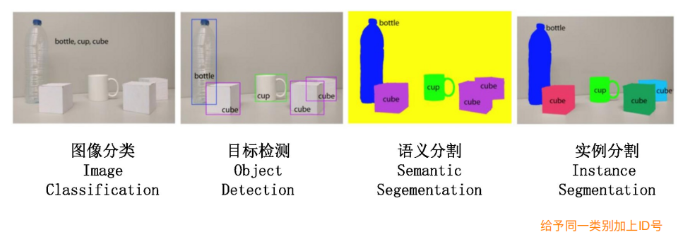
语义分割与实例分割定义 :
语义分割定义:语义分割是将图像中的每个像素分配到一个类别(如道路、建筑物、行人等)。所有同一类别的像素被分配到相同的标签上,但不会区分它们在图像中的具体位置或实例。
实例分割定义:实例分割不仅为每个像素分配一个类别标签,还要区分不同实例。也就是说,它可以区分属于同一类别的不同对象(例如,两个行人或两辆车),并为每个实例提供一个独立的标签。

应用领域 :
(1) 自动驾驶:自动驾驶需要准确地分辨道路、车辆、行人等对象,并对它们进行分割和分析,确保安全行驶;
(2) 医学影像:在医学影像分析中,语义分割和实例分割被用于提取肿瘤、器官等重要结构,帮助医生做出精准诊断;
(3) 遥感影像:遥感图像分割可应用于土地覆盖分类、城市规划、灾后评估等领域;
(4) 机器人视觉:机器人需要实时识别和分割不同的物体,以进行抓取、操控等任务。
语义分割与实例分割的挑战
- 语义分割的挑战:尽管语义分割任务已经取得了很大的进展,但依然存在一些挑战:
- 边界模糊:在一些复杂的图像中,物体的边界不清晰,导致分割精度降低。
- 小物体分割困难:尤其在低分辨率的图像中,较小的物体可能难以分割清晰。
- 实例分割的挑战:实例分割不仅要识别物体,还要解决如何区分同类物体的挑战:
- 重叠与遮挡:在物体遮挡或重叠的情况下,如何正确地分割每个实例,避免物体的混合或重叠。
- 高计算成本:实例分割通常需要比语义分割更多的计算资源和时间,尤其是在实时应用中。
语义分割与实例分割的技术演进
-
传统方法:
在深度学习之前,图像分割主要依靠传统的图像处理技术,如阈值分割、区域生长法和边缘检测等方法。尽管这些方法在某些简单场景中有效,但它们无法应对复杂背景、光照变化等问题,且处理精度较低。
-
深度学习的兴起:
近年来,深度学习,特别是卷积神经网络(CNN)的发展,极大推动了图像分割技术的进步。CNN可以自动学习到数据中的特征,从而大幅提高了分割任务的精度和效率。基于深度学习的分割方法如今成为主流。
常见网络架构:
- FCN(Fully Convolutional Network): FCN是最早的深度学习分割网络之一,它通过全卷积结构进行像素级分类,能够有效地进行图像分割,并为后来的分割网络提供了基础。
- U-Net: U-Net是一种专门用于医学影像分割的网络,具有编码器-解码器结构和跳跃连接设计,使得网络能够在不同层次之间有效地传递信息,尤其适用于处理复杂、精细的医学影像。
- Mask R-CNN: Mask R-CNN是基于Faster R-CNN的实例分割方法,它加入了一个用于实例分割的Mask分支,不仅能够进行物体检测,还能精准地分割出每个实例。它在目标检测和实例分割任务中都表现出了出色的性能。
- Segment Anything Model (SAM):SAM是由 Meta AI(原 Facebook AI Research)开发的一个突破性的图像分割模型。SAM 的推出标志着图像分割领域的一大进步,特别是在用户交互和零样本学习的能力上。该模型的目标是简化和扩展图像分割任务,使其能够在没有先验训练的情况下,处理各种各样的分割场景。SAM 的推出为图像分割任务提供了一个通用、灵活且强大的解决方案。
- YOLOv8-seg (2024):YOLOv8-seg 是 Ultralytics 推出的最新版本的 YOLO(You Only Look Once)系列网络,专注于高效的实例分割。YOLO 系列以其快速检测能力著称,YOLOv8-seg 在此基础上进一步支持了实例分割功能,适用于实时分割任务。
- Segformer (2021):Segformer 是一种基于 Transformer 架构的语义分割网络,由香港中文大学与南京大学的研究团队提出。它结合了 Transformer 的全局建模能力和卷积神经网络(CNN)的局部特征捕捉能力,能够在低计算开销下实现高效的分割。
源自:https://zhuanlan.zhihu.com/p/1963926738900877855
常用数据集
-
Pascal VOC Dataset
VOC数据集是计算机视觉主流数据集之一,由牛津大学、比利时鲁汶大学等高校的视觉研究组联合发布,可以用作分类,分割,目标检测,动作检测和人物定位五类任务,包含21个类别标签,训练1464,验证1449,测试1456。
-
MS COCO Dataset
MS COCO(Microsoft Common Objects in Context Dataset)是微软发布的一个大规模物体检测,分割及文字定位数据集,支持目标检测、实例分割、全景分割、Stuff Segmentation、关键点检测、看图说话等任务类型,包含80个对象类别。
-
ADE20K Dataset
ADE20K数据集由 MIT CSAIL 研究组发布,涵盖广泛的场景和对象类别,可用于场景感知、解析、分割、多物体识别和语义理解。该数据集构建了一个场景解析基准,包含150个对象和素材类。
-
CityScapes Dataset
CityScapes是由奔驰自动驾驶实验室、马克思·普朗克研究所、达姆施塔特工业大学联合发布的图像数据集,专注于对城市街景的语义理解。 该数据集包含50个城市不同场景、不同背景、不同街景,以及30类涵盖地面、建筑、交通标志、自然、天空、人和车辆等的物体标注,共有5000张精细标注的图像和2万张粗略标注的图像。
参考链接:https://blog.csdn.net/weixin_65688914/article/details/135179779
语义分割与目标检测的区别
-
基本概念
-
语义分割(Semantic Segmentation)
语义分割是计算机视觉中的一项重要任务,它是对图像中的每个像素进行分类,以确定其所属的物体或区域。换言之,语义分割将图像中的每个像素分配给特定的类别,从而实现对图像的精细分割。这个过程可以提供对图像的深入理解,对于许多应用场景如自动驾驶、医疗图像分析、遥感图像解析等具有重要意义。
-
目标检测(Object Detection)
目标检测则是计算机视觉中的另一项重要任务,它的主要目标是识别图像或视频中存在的物体,并给出这些物体的位置和边界。目标检测关注的是识别出图像中的物体,并确定这些物体的位置和形状,而不注重对每个像素的分类。这个技术在许多应用场景如安全监控、智能交通、广告推荐等具有广泛的应用。
-
-
工作原理
- 语义分割主要关注的是图像的像素级别的分类,以及不同区域或对象之间的边界。它通常采用深度神经网络来学习图像中的特征,并根据这些特征对每个像素进行分类。这是一种端到端的任务,需要将每个像素正确地分配到一个特定的类别。
- 目标检测则更关注物体的位置和形状。它通常采用滑动窗口或预设的锚点来在图像或视频中搜索物体。目标检测算法通常需要同时检测物体的位置和类别,并根据这些信息来识别出物体。虽然目标检测也涉及到对图像特征的学习,但它并不需要对每个像素进行分类。
-
输出结果
- 语义分割的输出是一个与输入图像相同大小的分割结果图,每个像素都被分配到正确的类别。它更注重对图像的精细分割,即使面对复杂场景也能提供准确的分割结果。
- 目标检测的输出则是一组包围检测到的物体的矩形框以及这些物体的类别。它不提供像素级别的分类,因此无法像语义分割那样提供详细的分割结果。但它的输出对于某些应用场景(如安全监控、智能交通等)来说已经足够。
-
优缺点
- 语义分割能够提供像素级别的分类和边界信息,这使得它能够提供更精细的图像理解和分析结果。然而,面对复杂场景(如光照变化、遮挡等)时,语义分割可能会遇到困难。此外,由于需要对每个像素进行分类,语义分割通常需要大量的计算资源和时间开销。同时,由于需要精细的标注数据来进行训练,语义分割也具有较高的成本。
- 目标检测则可以快速地检测到物体并对其进行跟踪和处理。它的输出对于许多应用场景来说已经足够,因此并不需要像素级别的分类和边界信息。然而,目标检测无法提供详细的分割结果和物体的精细特征描述。此外,由于目标检测算法通常采用滑动窗口或预设的锚点来进行物体检测,因此它的计算效率相对较低。
语义分割和目标检测是计算机视觉领域中的两个重要任务,它们各具特点和应用场景。语义分割能够提供像素级别的分类和边界信息,适用于对图像进行精细分割和分类;而目标检测则可以快速地检测到物体并对其进行跟踪和处理,适用于需要物体位置和形状信息的场景。在实际应用中,可以根据具体需求来选择合适的算法和技术。
参考链接:https://blog.csdn.net/m0_56729804/article/details/133745490