在向量数据库中,我们经常需要在庞大的高维向量 Collections(如图像特征、文本嵌入或音频表示)中快速找到最相似的结果。如果没有索引,唯一的选择就是将查询向量与数据集中的每一个向量进行比较。在只有几千个向量的情况下,这种粗暴的搜索 方式可能会奏效,但一旦要处理几千万或上亿个向量时,搜索速度就会变得非常缓慢,计算成本也会变得非常高昂。
这就是近似近邻(ANN) 搜索的用武之地。把它想象成在一个庞大的图书馆中寻找一本特定的书。与其逐一检查每本书,不如先浏览最有可能包含这本书的部分。你可能不会得到与全面搜索 完全相同 的结果,但你会得到非常接近的结果,而且只需花很少的时间。简而言之,ANN 在准确性上的轻微损失换来了速度和可扩展性的显著提升。
在实现 ANN 搜索的众多方法中,IVF(反转文件) 和HNSW(分层导航小世界) 是使用最广泛的两种。但在大规模向量搜索中,IVF 以其高效性和适应性脱颖而出。在本文中,我们将向您介绍 IVF 的工作原理以及它与 HNSW 的比较,以便您了解它们之间的权衡,并选择最适合您工作负载的一种。
什么是 IVF 向量索引?
IVF(反转文件) 是应用最广泛的 ANN 算法之一。它的核心思想借鉴了文本检索系统中使用的 "倒排索引"--只不过这次我们处理的不是单词和文件,而是高维空间中的向量。
把它想象成整理一个庞大的图书馆。如果你把每本书(向量)都扔到一个巨大的书堆里,要找到你需要的东西就得花很长时间。IVF 解决这个问题的方法是,首先将 所有向量聚类 成组 或桶 。每个 "桶 "代表一个类似向量的 "类别",由一个中心点 定义**--** 这是该聚类中所有东西的一种摘要或 "标签"。
当收到查询时,搜索分两步进行:
1.查找最近的聚类。 系统会寻找其中心点与查询向量最接近的几个簇--就像直接前往最有可能藏有你的书的两三个图书馆分区一样。
2.在这些聚类中搜索。 一旦你进入了正确的区域,你只需要翻阅一小部分图书,而不是整个图书馆。
这种方法将计算量减少了几个数量级。你仍然可以获得高度准确的结果,但速度要快得多。
如何建立 IVF 向量索引
建立 IVF 向量索引的过程包括三个主要步骤:K-means 聚类、向量分配和压缩编码(可选)。整个过程如下
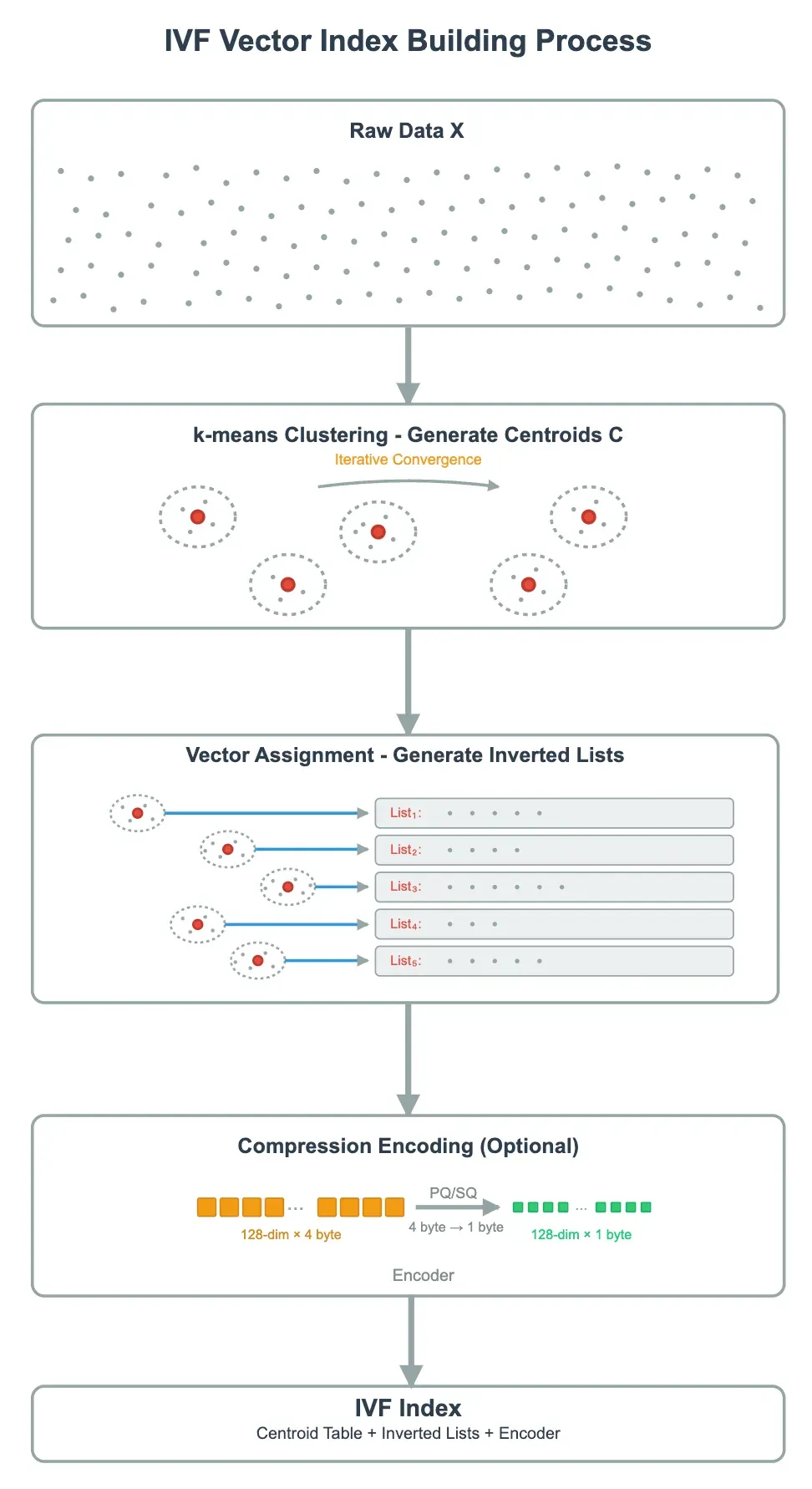
步骤 1:均值聚类
首先,在数据集 X 上运行 K-means 聚类,将高维向量空间划分为 nlist 簇。每个聚类都有一个中心点,存储在中心点表 C 中。中心点的数量 nlist 是一个关键的超参数,决定了聚类的精细程度。
以下是 k-means 的工作原理:
-
初始化: 随机选择 nlist 向量作为初始中心点。
-
分配: 对于每个向量,计算其与所有中心点的距离,并将其分配给最近的一个中心点。
-
更新: 对于每个聚类,计算其向量的平均值,并将其设为新的中心点。
-
迭代和收敛: 重复分配和更新,直到中心点不再发生显著变化或达到最大迭代次数。
k-means 收敛后,得到的 nlist 中心点构成 IVF 的 "索引目录"。它们定义了数据集的粗略划分方式,允许查询者在以后快速缩小搜索空间。
回想一下图书馆的比喻:训练中心点就像是决定如何按主题对书籍进行分组:
-
一个较大的 nlist 意味着更多的分区,每个分区有更少、更具体的书籍。
-
较小的 nlist 意味着较少的分区,每个分区涵盖的主题范围更广、更杂。
第二步:向量分配
接下来,每个向量被分配到其中心点最接近的聚类,形成倒列表(List_i)。每个倒列表都存储了属于该聚类的所有向量的 ID 和存储信息。
你可以把这一步想象成把书架分成各自的区域。当你以后要查找某个书目时,只需查看最有可能有该书的几个分区,而不用逛遍整个图书馆。
步骤 3:压缩编码(可选)
为了节省内存和加快计算速度,每个簇内的向量都可以进行压缩编码。常见的方法有两种:
-
SQ8(标量量化): 这种方法将向量的每个维度量化为 8 位。对于一个标准的
float32向量,每个维度通常占用 4 个字节。使用 SQ8,则可将其减少到 1 个字节--实现 4:1 的压缩比,同时保持向量的几何形状基本不变。 -
PQ(乘积量化): 它将高维向量分割成多个子空间。例如,一个 128 维的向量可以分成 8 个子向量,每个子向量 16 维。在每个子空间中,都预先训练了一个小的编码本(通常有 256 个条目),每个子向量都由一个指向与其最近的编码本条目的 8 位索引来表示。这意味着原始的 128-D
float32向量(需要 512 个字节)只需使用 8 个字节(8 个子空间 × 每个子空间 1 个字节)即可表示,实现了 64:1 的压缩比。
如何使用 IVF 向量索引进行搜索
一旦建立了中心点表、反转列表、压缩编码器和编码本(可选),IVF 索引就可用于加速相似性搜索。这一过程通常有三个主要步骤,如下所示:
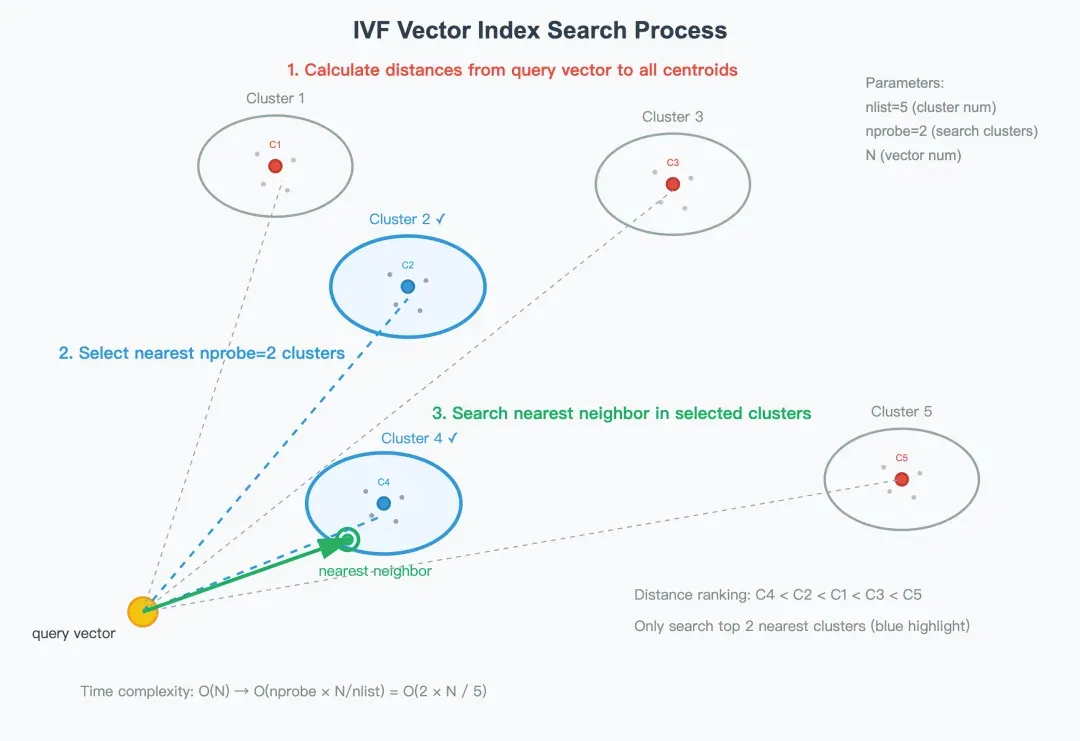
步骤 1:计算查询向量到所有中心点的距离
当一个查询向量 q 到达时,系统首先会确定它最有可能属于哪些聚类。然后,计算 q 与中心点表 C 中每个中心点之间的距离--通常使用欧氏距离或内积作为相似度量。然后根据中心点与查询向量的距离进行排序,生成一个从最近到最远的有序列表。
例如,如图所示,排序为C4 < C2 < C1 < C3 < C5。
步骤 2:选择最近的 nprobe 群集
为了避免扫描整个数据集,IVF 只在最靠近查询向量的前 nprobe 簇内进行搜索。
参数 nprobe 定义了搜索范围,并直接影响搜索速度和召回率之间的平衡:
-
nprobe 越小,查询速度越快,但可能会降低召回率。
-
较大的 nprobe 会提高召回率,但会增加延迟。
在实际系统中,nprobe 可以根据延迟预算或准确性要求进行动态调整。 在上面的例子中,如果 nprobe = 2,系统将只在第 2 和第 4 个群组(两个最近的群组)内搜索。
第 3 步:在选定的群集中搜索最近的邻居
选定候选簇后,系统会将查询向量 q 与存储在其中的向量进行比较。 比较主要有两种模式:
-
精确比较(IVF_FLAT) :系统从选定的簇中检索原始向量,直接计算它们与 q 的距离,返回最准确的结果。
-
近似比较(IVF_PQ / IVF_SQ8) :当使用 PQ 或 SQ8 压缩时,系统会采用查找表方法 来加速距离计算。在搜索开始前,它会预先计算查询向量与每个编码本条目之间的距离。然后,对于每个向量,它可以简单地 "查找并求和 "这些预先计算的距离,以估计相似性。
最后,合并所有搜索簇的候选结果并重新排序,产生最相似的前 k 个向量作为最终输出。
IVF 在实践中的应用
了解了 IVF 向量索引的构建 和搜索 方式后,下一步就是将其应用于实际工作负载。在实践中,你往往需要在性能 、准确性 和内存使用 之间取得平衡。下面是根据工程经验总结出的一些实用指南。
如何选择正确的 nlist
如前所述,参数 nlist 决定了在构建 IVF 索引时将数据集划分为多少个簇。
-
较大的 nlist :创建更细粒度的簇,这意味着每个簇包含的向量更少。这样可以减少搜索时扫描的向量数量,通常会加快查询速度。但建立索引需要更长的时间,而且中心点表会消耗更多内存。
-
更小的 nlist :加快索引构建速度,减少内存使用量,但每个簇会变得更加 "拥挤"。每次查询都必须扫描簇内更多的向量,这会导致性能瓶颈。
基于上述权衡,这里有一个实用的经验法则:
对于百万级别 的数据集,一个好的起点是nlist ≈ √n (n 是被索引的数据碎片中向量的数量)。
例如,如果你有 100 万个向量,可以尝试 nlist = 1,000。对于数千万或数亿的大型数据集,大多数向量数据库都会将数据分片,使每个分片包含约 100 万个向量,从而使这一规则保持实用性。
由于 nlist 在创建索引时是固定的,因此稍后更改它就意味着要重建整个索引。因此,最好尽早进行试验。测试几个值--最好是 2 的幂次(如 1024、2048)--找到平衡速度、准确性和内存的最佳值,以满足工作负载的需要。
如何调整 nprobe
参数 nprobe 控制着查询期间搜索的集群数量。它直接影响召回率和延迟之间的权衡。
-
nprobe 越大 :覆盖更多的群集,导致更高的召回率,但延迟也更高。一般来说,延迟与搜索的集群数呈线性增长。
-
较小的 nprobe :搜索较少的群集,延迟较低,查询速度较快。不过,它可能会错过一些真正的近邻,从而略微降低召回率和结果准确率。
如果您的应用程序对延迟不是非常敏感,那么最好对 nprobe 进行动态试验,例如测试 1 到 16 的值,观察召回率和延迟的变化情况。这样做的目的是找到一个最佳点,在这个点上,召回率是可以接受的,而延迟则保持在目标范围内。
由于 nprobe 是一个运行时搜索参数,因此可以动态配置调整,而无需重建索引。这样就能在不同的工作负载或查询场景中实现快速、低成本和高度灵活的调整。
IVF 索引的常见变体
在构建 IVF 索引时,需要决定是否对每个簇中的向量使用压缩编码--如果是,使用哪种方法。
这就产生了三种常见的 IVF 索引变体:
| IVF 变体 | 主要特征 | 使用案例 |
|---|---|---|
| IVF_FLAT | 在每个簇内存储原始向量,不进行压缩。精度最高,但内存消耗也最大。 | 适用于需要高召回率(95% 以上)的中等规模数据集(多达数亿向量)。 |
| IVF_PQ | 应用乘积量化(PQ)来压缩簇内的向量。通过调整压缩率,可以大大减少内存使用量。 | 适用于大规模向量搜索(数亿或更多),在这种情况下可以接受一定的精度损失。在压缩比为 64:1 的情况下,召回率通常在 70% 左右,但通过降低压缩比,召回率可以达到 90% 或更高。 |
| IVF_SQ8 | 使用标量量化 (SQ8) 对向量进行量化。内存使用量介于 IVF_FLAT 和 IVF_PQ 之间。 | 非常适合需要在提高效率的同时保持较高召回率(90% 以上)的大规模向量搜索。 |
IVF 与 HNSW:选择合适的方法
除了 IVF,HNSW(层次导航小世界) 是另一种广泛使用的内存向量索引。下表重点介绍了两者的主要区别。
| IVF | HNSW
---|---|---
算法概念 | 聚类和分桶| 多层图导航
内存使用 | 相对较低| 相对较高
索引建立速度 | 快(只需聚类)| 慢(需要构建多层图)
查询速度(无过滤) | 快,取决于 nprobe | 极快,但复杂度为对数
查询速度(有过滤) | 稳定 - 在中心点级别执行粗过滤,缩小候选范围| 不稳定--尤其是当过滤率很高(90% 以上)时,图会变得支离破碎,可能会退化到接近全图遍历,甚至比暴力搜索还要慢
召回率 | 取决于是否使用了压缩;如果没有量化,召回率可达95% 以上 | 通常更高,约为98%+
关键参数 | nlist 、 nprobe | m 、 ef_construction 、 ef_search
使用案例| 内存有限,但要求高查询性能和召回率;非常适合有过滤条件的搜索| 内存充足,目标是极高的召回率和查询性能,但不需要过滤或过滤率很低时
在实际应用中,包含过滤条件是非常常见的--例如,"只搜索来自特定用户的向量 "或 "将结果限制在一定的时间范围内"。由于底层算法的不同,IVF 处理过滤搜索的效率通常比 HNSW 高。
IVF 的优势在于其两级过滤过程。它可以首先在中心点(簇)级别执行粗粒度过滤,以快速缩小候选集的范围,然后在选定的簇内执行细粒度距离计算。这样,即使大部分数据被过滤掉,也能保持稳定和可预测的性能。
相比之下,HNSW 基于图遍历。由于其结构原因,它无法在遍历过程中直接利用过滤条件。当过滤比例较低时,这不会造成大问题。但是,当过滤率较高(例如,90% 以上的数据被过滤掉)时,剩余的图往往会变得支离破碎,形成许多 "孤立节点"。在这种情况下,搜索可能会退化为近乎全图遍历--有时甚至比暴力搜索还要糟糕。
在实践中,IVF 索引已经在不同领域的许多高影响力用例中发挥了作用:
-
电子商务搜索: 用户可以上传产品图片,并立即从数百万个列表中找到视觉相似的商品。
-
专利检索: 给定一个简短的描述,系统就能从海量数据库中找到语义最相关的专利--这比传统的关键词搜索要高效得多。
-
RAG 知识库: IVF 可帮助从数百万个租户文档中检索出最相关的上下文,确保人工智能模型生成更准确、更接地气的回复。
结论
要选择正确的索引,关键在于您的具体使用情况。如果您正在处理大规模数据集或需要支持过滤搜索,IVF 可能更适合您。与 HNSW 等基于图形的索引相比,IVF 的索引构建速度更快,内存使用率更低,而且在速度和准确性之间取得了很好的平衡。
Milvus 是最流行的开源向量数据库,它为整个 IVF 系列提供全面支持,包括 IVF_FLAT、IVF_PQ 和 IVF_SQ8。您可以轻松尝试这些索引类型,找到最适合您的性能和内存需求的设置。有关 Milvus 支持的索引的完整列表,请查看Milvus 索引文档页面。
如果您正在构建图像搜索、推荐系统或 RAG 知识库,请尝试一下 Milvus 中的 IVF 索引--看看高效的大规模向量搜索是如何运行的。