01.内存
1.1内存布局

当然可以!以下是对你提供的 C++ 面试知识点内容进行结构化、清晰化、排版优化后的版本,保留所有技术细节,同时提升可读性和逻辑层次:
1.2 栈和队列的区别
| 特性 | 栈(Stack) | 队列(Queue) |
|---|---|---|
| 操作原则 | 后进先出(LIFO) | 先进先出(FIFO) |
| 插入/删除 | 只在一端(栈顶)操作 | 插入在队尾,删除在队头 |
| 典型应用 | 函数调用、表达式求值、括号匹配 | 任务调度、BFS、缓冲区管理 |
"栈是后进先出(LIFO),只在一端操作,常用于函数调用、括号匹配;队列是先进先出(FIFO),一端入、一端出,用于任务调度、BFS 等场景。两者都是线性结构,但操作规则和应用场景完全不同。"
✅1.3 什么是内存泄漏,如何避免
定义
内存泄漏是指程序在堆上通过 new 或 malloc 分配了内存,但使用完毕后未调用 delete 或 free 释放,导致该内存无法被系统回收。长期积累会耗尽可用内存,引发性能下降甚至程序崩溃。
避免方法
- RAII(Resource Acquisition Is Initialization):将资源管理封装在对象生命周期中。
- 使用智能指针 (C++11 起):
std::unique_ptr:独占所有权std::shared_ptr:共享所有权std::weak_ptr:解决循环引用
- 避免裸
new/delete:尽量使用容器(如std::vector)或智能指针管理动态内存。
"内存泄漏是指堆上分配的内存未被释放,长期积累导致内存耗尽。避免方法包括:使用 RAII 原则、优先用智能指针(如
unique_ptr、shared_ptr),避免裸new/delete,并借助工具如 AddressSanitizer 检测。"
✅智能指针, weak_ptr
答:
weak_ptr是一种不控制对象生命周期 的智能指针,它不会增加引用计数。主要用途:打破
shared_ptr的循环引用。不能直接解引用,必须通过
lock()转为shared_ptr
cppstd::weak_ptr<int> w = s; // s 是 shared_ptr if (auto sp = w.lock()) { std::cout << *sp; // 安全使用 } else { // 对象已被释放 }典型场景:观察者模式、缓存(如 LRU 中的 weak 引用)。
✅1.4 如何查看对象的内存布局
sizeof(Type):获取对象或类型的总大小(含填充)。offsetof(struct, member):获取结构体成员相对于起始地址的偏移量(仅适用于 POD 类型)。- 编译器扩展(如 GCC 的
-fdump-class-hierarchy)可输出类的内存布局。 - 工具辅助:
pahole(Linux)、Visual Studio 的调试器内存视图等。
"可以用
sizeof和offsetof获取大小与偏移;对于类,GCC 加-fdump-class-hierarchy能输出内存布局;Linux 下也可用pahole工具分析结构体填充和对齐。"
✅1.5 内存对齐
为什么需要对齐?
CPU 通常以"字"(如 4 字节、8 字节)为单位访问内存。对齐的数据可一次读取;未对齐可能需多次访问,降低性能,某些架构甚至直接报错。
对齐规则(默认)
- 每个成员对齐到
min(自身大小, #pragma pack(n))的整数倍地址。 - 整个结构体大小对齐到最大成员对齐值的整数倍。
控制对齐方式
-
禁用填充(紧凑布局) :
cpp#pragma pack(1) // 1 字节对齐 struct Packet { char a; int b; }; #pragma pack() // 恢复默认 -
C++11 标准对齐控制 :
alignas(N):指定对齐字节数(如alignas(16) int x;)alignof(T):查询类型T的对齐要求std::aligned_alloc(size, alignment):分配对齐内存(C11/C++17)
应用场景:网络协议解析、二进制文件读写需禁用填充以保证数据一致性。
✅全局变量初始化时机 & 类构造函数调用时机
-
全局/静态变量:
- 在
main()函数之前初始化。 - 初始化顺序:
- 零初始化 (如
int x;→x = 0) - 常量初始化 (如
int y = 42;) - 动态初始化 (如调用函数:
int z = getValue();)
- 零初始化 (如
- 注意:不同编译单元间的全局变量初始化顺序未定义。
- 在
-
类对象构造函数:
- 仅在对象创建时调用 (如定义局部对象、
new、作为成员初始化等)。
- 仅在对象创建时调用 (如定义局部对象、
"全局变量在
main()之前初始化,分零初始化、常量初始化和动态初始化三阶段;而类的构造函数只在对象创建时调用,比如定义局部变量、new对象或作为成员初始化时。"
✅崩溃常见原因
| 原因 | 示例 |
|---|---|
| 数组越界 | int a[10]; a[100] = 1; |
| 栈溢出 | 无限递归:void f() { f(); }(默认栈空间几 MB) |
| 野指针/悬空指针 | int* p = new int(42); delete p; *p = 10; |
✅什么是段错误
- 操作系统通过内存保护机制,禁止程序访问非法地址(如空指针、已释放内存、只读区域)。
- 当发生非法访问时,CPU 触发异常,OS 发送
SIGSEGV信号终止进程,防止系统被破坏。
✅排查内存访问越界问题
- AddressSanitizer(ASan) :
- 编译时加
-fsanitize=address - 运行时自动检测越界、Use-After-Free 等问题,精准定位代码行。
- 编译时加
- GDB 调试 :
- 结合 core dump 分析崩溃现场(
bt查看调用栈)。
- 结合 core dump 分析崩溃现场(
- 静态分析工具 :
- Clang Static Analyzer、Cppcheck 等可在编译前发现潜在问题。
✅左值 vs 右值 & 引用类型
基本概念
| 类型 | 特点 | 是否可取地址 | 示例 |
|---|---|---|---|
| 左值(lvalue) | 有名字、持久存在 | ✅ | 变量、数组元素、对象成员 |
| 右值(rvalue) | 临时、无名、将亡 | ❌ | 字面量、函数返回值、表达式结果 |
引用类型
| 引用类型 | 语法 | 可绑定对象 | 用途 |
|---|---|---|---|
| 左值引用 | T& |
仅左值 | 避免拷贝、修改原对象 |
| const 左值引用 | const T& |
左值 + 右值 | 延长临时对象生命周期 |
| 右值引用 | T&& |
仅右值 | 实现移动语义、完美转发 |
示例代码
cpp
int x = 10;
int& lref = x; // OK:左值引用绑定左值
// int& lref2 = 20; // ❌ 错误
const int& cref = 20; // OK:const 左值引用可绑定右值
int&& rref = 30; // OK:右值引用绑定右值
int&& rref2 = std::move(x); // OK:std::move 将左值转为右值引用重载示例
cpp
void process(int&); // 处理左值
void process(int&&); // 处理右值
int a = 5;
process(a); // 调用左值版本
process(10); // 调用右值版本
process(a + 1); // 调用右值版本
process(std::move(a)); // 显式转为右值,调用右值版本
cpp
private:
char* data_; // 指向堆上分配的字符数组
size_t size_;
public:
// 拷贝构造函数(深拷贝)
MyString(const MyString& other) {
size_ = other.size_;
data_ = new char[size_ + 1];
std::strcpy(data_, other.data_);
}
MyString(MyString&& other) noexcept {
// 1. 接管 other 的资源
data_ = other.data_;
size_ = other.size_;
// 2. 将 other 置为空(防止析构时 delete 有效指针)
other.data_ = nullptr;
other.size_ = 0; 移动构造的底层就是指针移交 + 原对象置空 。它不分配内存、不复制数据,只是把资源的所有权从一个对象转移到另一个,从而避免昂贵的深拷贝。关键是要把源对象置为安全状态(如 nullptr),防止双重释放。
拷贝构造是初始化一个新对象,它没有旧资源,所以不需要释放;而拷贝赋值是给已有对象赋新值,必须先清理旧资源,否则会内存泄漏。
"左值是有名字、可取地址的对象;右值是临时值。左值引用(
T&)绑定左值用于修改;右值引用(
T&&)绑定右值,用于移动语义。const T&可绑定右值以延长生命周期。"
✅std::move 的作用与原理
- 将左值"转换"为右值引用,使其能参与移动语义(如调用移动构造函数)。
- 不实际移动数据,仅改变表达式的值类别(value category)。
底层实现
cpp
template<typename T>
typename std::remove_reference<T>::type&& move(T&& t) {
return static_cast<typename std::remove_reference<T>::type&&>(t);
}- 本质是
static_cast<T&&>的封装,无运行时开销,纯编译期类型转换。
"
std::move不移动数据,只是将左值转为右值引用,让编译器选择移动构造函数。底层是static_cast<T&&>,无运行时开销,纯类型转换。"
✅std::forward 的使用场景
在模板函数中保持参数的原始值类别 (左值/右值),实现完美转发(Perfect Forwarding)。
使用条件
- 仅用于转发引用(forwarding reference) :
template<typename T> void f(T&& arg) - 必须显式指定模板参数:
std::forward<T>(arg)
cpp
template<typename T>
void wrapper(T&& arg) {
process(std::forward<T>(arg)); // 保持 arg 的原始类型
}
int x = 10;
wrapper(x); // T = int&, 转发为左值
wrapper(20); // T = int, 转发为右值🎯 面试答法:"用于模板中的完美转发:在转发引用(
T&&)函数里,用std::forward<T>(arg)保持参数原始的左值/右值属性,确保调用正确的重载版本。"
✅虚函数表工作原理
每个包含虚函数的类或派生类都有一个虚函数表。虚函数实际上是一个函数指针数组,里面存放虚函数的地址。每个对象一般情况下有一个指向虚函数表的虚指针。当调用虚函数时,通过对象的虚指针找到虚函数表,再通过索引找到对应函数。
多态
| 类型 | 决策时机 | 实现方式 | 示例 |
|---|---|---|---|
| 静态多态 | 编译期 | 函数重载、模板 | template<typename T> void f(T); |
| 动态多态 | 运行期 | 虚函数 + 基类指针/引用 | virtual void draw(); |
✅动态多态使用频率
- 高频使用:在需要运行时行为扩展的场景(如 GUI 组件、游戏对象、插件系统)。
- 核心机制:通过虚函数表(vtable)实现,有轻微性能开销,但灵活性极高。
"多态是同一接口多种实现。静态多态靠模板(编译期),动态多态靠虚函数(运行期)。动态多态在插件系统、UI 框架、游戏对象中很常用,虽有轻微开销,但灵活性高。"
✅单例模式的场景,实际
STL 常用容器,vector扩容机制,扩容时具体过程?
- 序列式 :
vector(动态数组)、deque(双端队列)、list(双向链表) - 关联式 :
map/set(红黑树)、unordered_map/unordered_set(哈希表)
当 push_back 导致 size() == capacity() 时,vector 会自动扩容。
- 开辟新空间
- 转移数据
- 使用拷贝构造会一个一个字符的复制过去开销大
- 移动构造则为每个元素调用移动构造函数,转移资源所有权
- 释放旧空间
- 更新指针和容量
⚠️ 关键影响:
-
时间复杂度 :单次
push_back平均 O(1)(摊还分析),但扩容那次是 O(n) -
迭代器/指针/引用失效:扩容后所有指向旧内存的指针都变"野指针"
"常用容器:
vector、unordered_map、string。vector扩容时,当容量不足,会分配更大内存(通常 1.5 或 2 倍),用移动或拷贝构造迁移元素,再释放旧内存。扩容后迭代器失效,建议用reserve预分配。"
✅map底层实现,插入复杂度,vector 插入
✅进程线程区别?
-
开销
- 进程:创建/切换慢(需复制页表、TLB 刷新,内核开销大)
- 线程:创建/切换快(共享地址空间,只切寄存器和栈)
-
通信
- 进程:需 IPC(管道、共享内存等),有内核开销
- 线程:直接读写共享内存,高效但需同步(锁、原子操作)
-
健壮性
- 进程崩溃不影响其他进程;
- 任一线程崩溃会导致整个进程退出。
-
资源与调度
- 进程是资源分配单位 (内存、文件句柄等按进程统计);
- 线程是CPU 调度单位(内核调度的是线程)。
- 进程是资源分配单位 (内存、文件句柄等按进程统计);
✅线程怎么用的
✅共享资源并发控制方式
小操作用原子变量,复杂逻辑用互斥锁;读多写少考虑读写锁;极致性能才考虑无锁。
✅原子变量和互斥锁区别,为什么更轻量,底层实现
原子变量靠 CPU 指令实现无锁同步,避免了互斥锁的内核态切换开销,但只适用于简单操作。
原子变量 vs 互斥锁:区别、为什么更轻量、底层实现
| 原子变量 | 互斥锁 | |
|---|---|---|
| 粒度 | 单个变量 | 任意临界区 |
| 阻塞 | 无(通常 busy-wait 或硬件指令) | 可能阻塞线程(进内核) |
| 开销 | 极低(CPU 指令级) | 较高(系统调用 + 上下文切换) |
✅ 为什么更轻量
了解动态库和静态库的区别吗,优缺点
- 静态库:服务端热修复。部署简单、启动快、无依赖;但体积大、更新难、浪费内存。
- 动态库:嵌入式/安全场景使用。节省内存、支持热更新、便于插件化;但有依赖问题、加载稍慢。
"静态库在编译时链接进可执行文件,部署简单但体积大、更新难;动态库运行时加载,节省内存、支持热更新,但有依赖问题。服务端倾向动态库便于维护,嵌入式常用静态库避免依赖。"
✅动态库热更新是怎么做的
热更新=即不重启进程,替换正在使用的动态库
"热更新需避免直接覆盖正在使用的
.so。做法是:先加载新库(dlopen),通过函数指针切换逻辑,等旧任务结束后dlclose旧库。关键要保证 ABI 兼容,并处理好正在执行的函数。实际中更常用滚动重启,C++ 层热更新风险高,多用于插件或脚本层。"
shell命令考查,查找文件字符串,统计某个词出现次数?
✅ 查找包含某字符串的文件:
cpp
grep "keyword" filename # 查看某文件
grep -r "keyword" /path/ # 递归查找目录✅ 统计某个词出现次数(精确单词):
c
grep -o -w "word" file.txt | wc -l-o:只输出匹配部分(每行一个)-w:匹配完整单词(避免 "word" 匹配到 "keyword")wc -l:统计行数 = 出现次数
✅gdb断点有几种方式,显示栈帧,切换栈帧,多线程怎么用
| 设断点 | break main(函数) break file.cpp:20(行号) break *0x400526(地址) |
| 显示栈帧 | bt(backtrace,完整调用栈) info frame(当前帧详情) |
| 切换栈帧 | frame 2(跳到第 2 层) up/down(上下移动) |
| 多线程调试 | info threads(列出线程) thread 2(切换到线程 2) thread apply all bt(所有线程栈) |
"断点可用函数名、行号或地址;用
bt看栈,frame N切帧;多线程用info threads和thread N切换,thread apply all bt查所有线程状态。"
✅gdb?
答 :了解。
gdb是 GNU 调试器,用于调试 C/C++ 程序。常用功能包括:
- 启动/附加进程:
gdb ./a.out或gdb -p <pid>- 设置断点:
break func/b 25- 单步执行:
step(进函数)、next(不进函数)- 查看变量:
print x- 查看调用栈:
bt(backtrace)- 调试 core dump:
gdb ./a.out core- 多线程调试:
info threads,thread 2- 条件断点、watch 变量等高级功能。
是排查段错误、死锁、逻辑错误的利器。
✅崩溃gdb调试
-
生成 core 文件(若未开启):
cppulimit -c unlimited # 允许生成 core ./program # 崩溃后生成 core.pid -
用 GDB 加载:
cppgdb ./program core.pid -
关键操作:
bt:看崩溃时的调用栈frame N:定位到具体函数print var:查看变量值info registers:看寄存器(如 rip 指向非法地址)
"先确保生成 core 文件,用
gdb 程序 core加载,然后bt看栈,frame定位,
✅断言原理,为什么用断言,为什么能结束程序?
原理
assert(expr) 是宏,当expr为假时:
- 打印错误信息(文件、行号、表达式)
- 调用
abort()→ 发送SIGABRT信号 → 终止程序
为什么用?
- 调试期快速暴露逻辑错误(如空指针、非法参数)
- 文档作用:表明"此处条件必须成立"
🎯 面试答法:
"断言用于调试期检查程序不变式,失败时调用
abort()终止进程。它不是错误处理机制,而是'早崩早发现'的防御性编程手段。"
✅简单说tcp和udp区别
| 连接 | 面向连接(三次握手) | 无连接 |
| 可靠性 | 可靠(重传、确认、排序) | 不可靠(可能丢包、乱序) |
| 速度 | 慢(开销大) | 快(头部小,无控制) |
| 适用场景 | HTTP、文件传输 | 视频通话、DNS、游戏 |
🎯 面试答法:
"TCP 可靠但慢,适合传文件;UDP 快但不可靠,适合实时音视频。选型看业务对可靠性和延迟的要求。"
tcp粘包,实际有在应用层解决过吗
✅ 什么是粘包?
- TCP 是字节流协议,无消息边界,发送多个包可能被合并(粘包),或一个包被拆开(拆包)。
-
固定长度:每条消息定长(如 1024 字节),不足补零
-
分隔符 :用
\n或特殊字符分隔(如 Redis 协议) -
长度头:最常用!前 4 字节表示 body 长度
c[4-byte len][data...]- 读取 4 字节 → 得到 len → 再读 len 字节 → 完整消息
🎯 面试答法:
"在 Web 服务器中,我用'长度头 + JSON'协议解决粘包:先读 4 字节长度,再读对应字节数的 JSON,确保消息完整解析。"
TCP三次握手,四次挥手过程?
✅心跳检测
检测链接是否存活,防止中间设备(NAT)长时间无数据断开连接。
应用层:定期发送PING/PONG消息
传输层:启用 TCP Keep-Alive(SO_KEEPALIVE),但默认间隔长(2 小时)
✅操作系统内核态
操作系统内核运行态,权限高,可访问所有资源。但是存在上下文切换+TLB刷新+安全检查,开销较大。
✅死锁条件 怎么避免
- 破坏"持有并等待":一次性申请所有资源
- 破坏"循环等待":资源编号,按序申请
- 银行家算法:动态检测安全状态(理论可行,工程少用)
- 超时机制:加锁失败则回退重试
✅C++如果要设计一个string库,要考虑哪些内容
- 内存管理:实现构造、析构、拷贝构造和赋值运算符,确保正确的内存分配释放
- 基本接口:实现
length(),reserve(),operator[]等常用方法 - 常用功能:提供
append(),find(),substr()等字符串操作 - 异常安全:保证基本的内存分配异常处理"
✅C++ vector特性
- 连续内存、随机访问 O(1)
- 尾插摊还 O(1),中间插入 O(n)
- 扩容时迭代器失效
- 支持移动语义(C++11)
✅面对对象三大特性
- 封装:隐藏内部实现
- 继承:
- 多态:
✅多态,虚函数,函数指针
- 多态:同一接口多种实现(运行时通过虚函数表)
- 虚函数 :用
virtual声明,派生类可重写,调用时动态绑定 - 函数指针 :指向普通函数或静态成员函数,无多态能力
✅C++回调函数
本质是将函数作为参数传递给了另外一个函数,并在特定时期进行调用的机制。
cpp
void callback(int x) {
std::cout << "Callback called with: " << x << std::endl;
}
void doWork(void (*cb)(int)) {
cb(42);
}
// 使用
doWork(callback);
-----------------------------------------------------------------
#include <functional>
typedef std::function<void(int)> Callback;
void doWork(Callback cb) {
cb(42);
}
// 使用 lambda(可捕获上下文)
int val = 100;
doWork([val](int x) {
std::cout << x + val << std::endl;
});
void doWork(std::function<void(int)> cb) {
cb(42);
}
// 使用 lambda(可捕获上下文)
int val = 100;
doWork([val](int x) {
std::cout << x + val << std::endl;
});✅用过哪些容器,为什么不用 map,而用 unordered_map
常用容器:
vector,list,deque,set,map,unordered_map,unordered_setmap vs unordered_map:
底层 红黑树(有序) 哈希表(无序) 查找复杂度 O(log n) 平均 O(1),最坏 O(n) 是否有序 是 否 内存开销 较小 较大(哈希桶 + 负载因子) 选择 unordered_map 的原因:
- 需要高性能查找/插入(如缓存、ID 映射)
- 不需要元素有序
- 键类型支持哈希(或自定义 hash)
✅ 你对上下文的理解
答 :上下文(Context)指程序执行时的环境状态,不同场景含义不同:
- CPU 上下文:寄存器、程序计数器、栈指针等,线程切换时需保存/恢复。
- 函数调用上下文:局部变量、参数、返回地址(即栈帧)。
✅lambda表达式
作为匿名函数,可以作为参数直接传给函数,作用域限定和编译器内联优化。

✅std::move 在 lambda 捕获中的作用
cpp
[变量名 = std::move(外部变量)]背景:std::unique_ptr 的特性
std::unique_ptr是独占所有权的智能指针。- 不能拷贝 (copy),只能移动(move)。
- 一旦被
move,原变量变为nullptr。
cpp
auto b = std::make_unique<int>(5);
auto b2 = b; // 编译错误!不能拷贝 unique_ptr
auto b2 = std::move(b); // 可以移动,b 现在是 nullptr如何把 unique_ptr 传进 lambda?
如果直接按值捕获 [b]:
cpp
auto f = [b](int a) { ... }; // 编译错误!因为 lambda 默认会拷贝 捕获的变量,但 unique_ptr 禁止拷贝 → 编译失败!
解决方案:C++14 的"初始化捕获"(广义 lambda 捕获)
语法:[新变量名 = 表达式]
cpp
[c = std::move(b)]含义:
- 在 lambda 内部创建一个名为
c的成员变量 - 它的值由
std::move(b)初始化 - 结果:
b的所有权被 move 到 lambda 内部的c
三、move 的作用总结
std::move(b) |
将b转为右值引用(unique_ptr<int>&&) |
[c = std::move(b)] |
用这个右值初始化 lambda 内部的成员c,触发move 构造 |
| 捕获后 | b变为nullptr,c拥有原内存的所有权 |
| lambda 销毁时 | c自动析构,释放内存(RAII) |
cpp
#include <iostream>
#include <memory>
#include <typeinfo>
int main() {
auto b = std::make_unique<int>(5);
auto f = [c = std::move(b)](int a) { // 广义捕获 + move
std::cout << a << std::endl;
// 注意:这里其实没用到 c,但 c 已被移动进 lambda
};
f(5);
// 输出 lambda 类型(用于调试,实际无意义)
std::cout << typeid(f).name() << std::endl;
}✅有哪些强制类型转换?dynamic_cast 的用途
答:C++ 有四种类型转换:
static_cast:静态转换(编译期),用于相关类型(如 int↔float,基类↔派生类向上)dynamic_cast:动态转换(运行时) ,用于带多态的类继承体系const_cast:移除/添加const(慎用)reinterpret_cast:底层 reinterpret(如指针↔整数),极不安全
dynamic_cast用途:
- 安全地向下转型(基类指针 → 派生类指针)
- 需要基类有虚函数(RTTI 支持)
- 失败时:指针返回
nullptr,引用抛std::bad_cast
cppBase* b = new Derived(); Derived* d = dynamic_cast<Derived*>(b); // 安全 if (d) { /* 转换成功 */ }
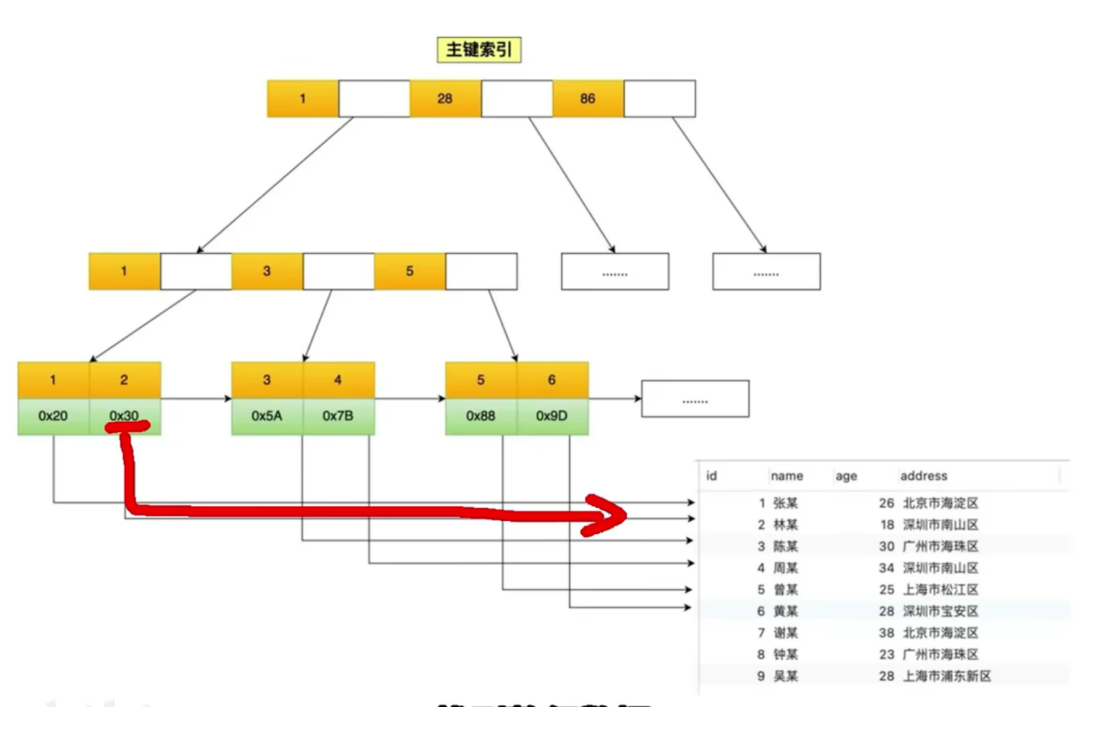
✅MySQL 索引底层实现
-
默认存储引擎 InnoDB 使用 B+ 树作为索引结构。
-
为什么是 B+ 树?
- 相比二叉树/红黑树:减少磁盘 I/O 次数(树高度低,适合磁盘块读取)。
- 相比 B 树:非叶子节点不存数据,只存索引 → 单页可存更多键 → 树更矮 → 查询更快。
- 叶子节点用双向链表连接 → 范围查询高效(如
WHERE id BETWEEN 10 AND 100)。
-
聚簇索引 vs 非聚簇索引:
- InnoDB 中,主键索引 = 聚簇索引,数据行与索引存储在一起。
- 二级索引(非主键)的叶子节点存的是主键值,需回表查询。
下述回表。
makefile更新条件是 a.exe:xx.cpp...;后者比前面时间戳新就更新
- 安全地向下转型(基类指针 → 派生类指针)
- 需要基类有虚函数(RTTI 支持)
- 失败时:指针返回
nullptr,引用抛std::bad_cast
cppBase* b = new Derived(); Derived* d = dynamic_cast<Derived*>(b); // 安全 if (d) { /* 转换成功 */ }