目录
[5、MySQL 读写分离原理](#5、MySQL 读写分离原理)
1、什么是读写分离?
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
2、为什么要读写分离呢?
因为数据库的"写"(写10000条数据可能要3分钟)操作是比较耗时的。
但是数据库的"读"(读10000条数据可能只要5秒钟)。
所以读写分离,解决的是,数据库的写入,影响了查询的效率。
3、什么时候要读写分离?
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用。利用数据库主从同步,再通过读写分离可以分担数据库压力,提高性能。
4、主从复制与读写分离
在实际的生产环境中,对数据库的读和写都在同一个数据库服务器中,是不能满足实际需求的。无论是在安全性、高可用性还是高并发等各个方面都是完全不能满足实际需求的。因此,通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。有点类似于rsync,但是不同的是rsync是对磁盘文件做备份,而mysql主从复制是对数据库中的数据、语句做备份。
5、MySQL 读写分离原理
读写分离就是只在主服务器上写,只在从服务器上读。基本的原理是让主数据库处理事务性操作,而从数据库处理 select 查询。数据库复制被用来把主数据库上事务性操作导致的变更同步到集群中的从数据库。
6.读写分离实验
6.1环境部署
整个实验的环境 以及服务器信息
systemctl stop firewalld
setenforce 0
环境部署 cetos7.6
虚拟机服务环境
Master服务器:192.168.10.132
slave1服务器:192.168.10.142
Slave2服务器:192.168.10.164
Amoeba & 客户端服务器:192.168.10.128 #jdk1.6、Amoeba & mysql 测试
注:做读写分离实验之前必须有一 主 两从 环境
6.2Amoeba服务器配置
① 安装 Java 环境
bash
因为 Amoeba 基于是 jdk1.5 开发的,所以官方推荐使用 jdk1.5 或 1.6 版本,高版本不建议使用。
cd /opt/
下载安装包 jdk-6u14-linux-x64.bin
cp jdk-6u14-linux-x64.bin /usr/local/
cd /usr/local/
chmod +x jdk-6u14-linux-x64.bin
./jdk-6u14-linux-x64.bin
//按yes,按enter
mv jdk1.6.0_14/ /usr/local/jdk1.6
vim /etc/profile
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin
export AMOEBA_HOME=/usr/local/amoeba
export PATH=$PATH:$AMOEBA_HOME/bin
source /etc/profile #刷新
java -version #查看版本② 安装 Amoeba软件
bash
1.mkdir /usr/local/amoeba
2.下载包amoeba-mysql-binary-2.2.0.tar.gz
3.tar zxvf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
4.chmod -R 755 /usr/local/amoeba/
5./usr/local/amoeba/bin/amoeba
//如显示amoeba start|stop说明安装成功③ 配置 Amoeba读写分离,两个 Slave 读负载均衡
bash
#先在Master、Slave1、Slave2 的mysql上开放权限给 Amoeba 访问
grant all on *.* to test@'192.168.10.%' identified by '123456';
#再回到amoeba服务器配置amoeba服务:
cd /usr/local/amoeba/conf/
cp amoeba.xml amoeba.xml.bak
#修改amoeba配置文件
vim amoeba.xml
--30行-- <property name="user">amoeba</property>
--32行-- <property name="password">123456</property>
--115行-- <property name="defaultPool">master</property>
--117-去掉注释- <property name="writePool">master</property>
<property name="readPool">slaves</property>
--------------------------------------------------------
cp dbServers.xml dbServers.xml.bak
#修改数据库配置文件
vim dbServers.xml
--23行--注释掉 作用:默认进入test库 以防mysql中没有test库时,会报错
<!-- <property name="schema">test</property> -->
--26--修改 <property name="user">test</property>
--28-30--去掉注释 <property name="password">123456</property>
--45--修改,设置主服务器的名Master <dbServer name="master" parent="abstractServer">
--48--修改,设置主服务器的地址 <property name="ipAddress">192.168.10.132</property>
--52--修改,设置从服务器的名slave1 <dbServer name="slave1" parent="abstractServer">
--55--修改,设置从服务器1的地址 <property name="ipAddress">192.168.10.142</property>
--58--复制上面6行粘贴,设置从服务器2的名slave2和地址
<dbServer name="slave2" parent="abstractServer">
<property name="ipAddress">192.168.10.164</property>
--65行--修改 <dbServer name="slaves" virtual="true">
--71行--修改 <property name="poolNames">slave1,slave2</property>
---------------------------------------------
/usr/local/amoeba/bin/amoeba start& #启动Amoeba软件,按ctrl+c 返回
netstat -anpt | grep java #查看8066端口是否开启,默认端口为TCP 80666.3测试读写分离
先安装数据库(在客户端上安装)
bash
yum install -y mariadb-server mariadb
systemctl start mariadb.service在客户端服务器上测试
bash
mysql -u amoeba -p123456 -h 192.168.10.128 -P8066
通过amoeba服务器代理访问mysql ,在通过客户端连接mysql后写入的数据只有主服务会记录,然后同步给从--从服务器在主服务器上:
bash
create database db_test;
use db_test;
create table test (id int(10),name varchar(10),address varchar(20));在两台从服务器上:
bash
stop slave; #关闭同步
use db_test;
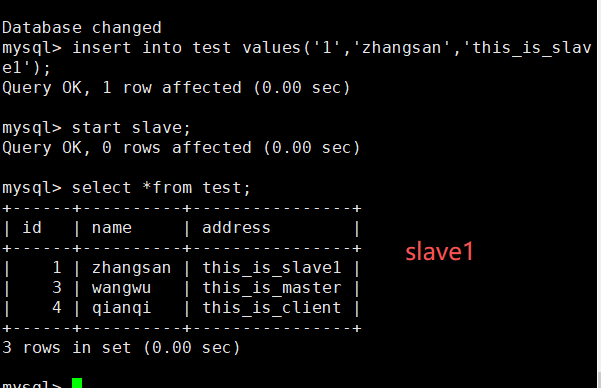
在slave1上:
insert into test values('1','zhangsan','this_is_slave1');
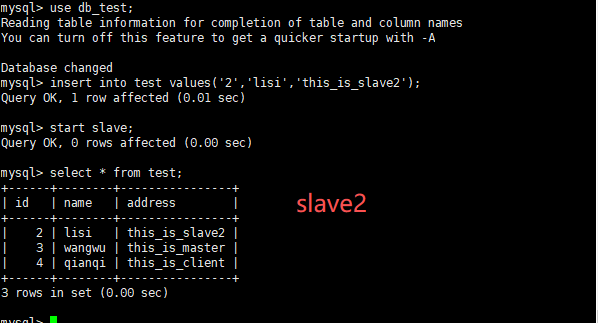
在slave2上:
insert into test values('2','lisi','this_is_slave2');在主服务器上:
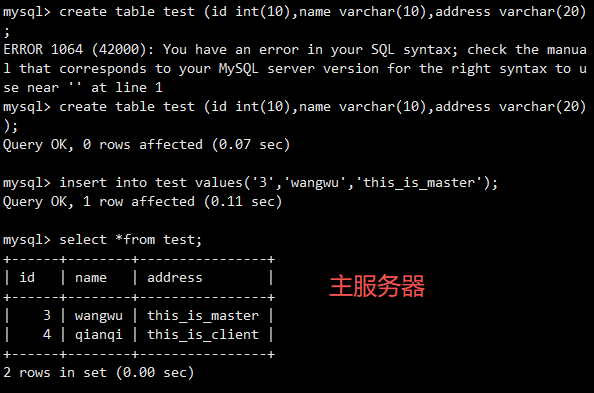
bash
insert into test values('3','wangwu','this_is_master');在客户端服务器上:
bash
use db_test;
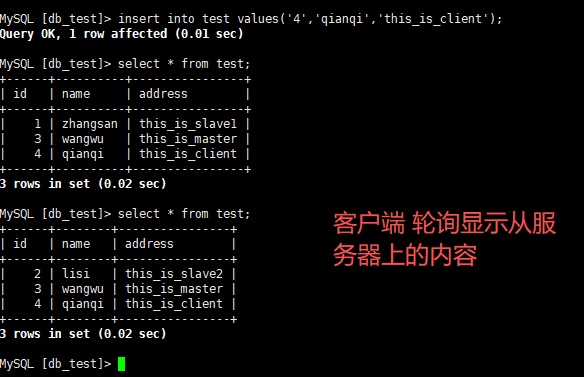
select * from test; //客户端会分别向slave1和slave2读取数据,显示的只有在两个从服务器
上添加的数据,没有在主服务器上添加的数据 (轮询显示,每次只出现一个从服务器的内容)
insert into test values('4','qianqi','this_is_client'); //只有主服务器上有此数据最后,在两个从服务器上执行 start slave; 即可实现同步在主服务器上添加的数据。
展示结果:
总结:
想要进行读写分离一定要想进行主从复制,读写分离的本质意义就是MySQL主只做写,从只做读。