背景:分片集群的核心价值与适用场景
当数据库面临高并发请求或海量数据存储时,单服务器瓶颈凸显:
- 📈 CPU压力:客户端请求激增导致计算资源饱和
- 💾 I/O压力:数据量持续增长引发磁盘吞吐瓶颈
MongoDB 采用横向扩展策略,其解决方案即 数据库分片(Sharding):将完整数据集划分为多个子集(分片),每个分片存储于独立服务器,所有分片共同构成 分片集群(Sharded Cluster),实现分布式存储与计算,所以,其核心目标:解决数据库水平扩展问题
扩展方案对比
| 扩展方式 | 实现方法 | 优势 | 劣势 |
|---|---|---|---|
| 纵向扩展 | 提升单机硬件配置 | 架构简单,运维成本低 | 硬件成本指数增长,存在物理上限 |
| 横向扩展 | 增加服务器构建分片集群 | 无限扩展能力,成本弹性高 | 架构复杂度高,运维难度升级 |
扩展需求 纵向扩展 横向扩展 单机性能上限 分片集群
扩展系统的方式分为两类:
- 纵向扩展(Scale Up):
- 通过提升单服务器硬件(如增加 CPU、内存、存储)增强性能
- 优势:架构简单,运维复杂度低
- 局限:受硬件成本与物理上限制约,无法无限扩展
- 横向扩展(Scale Out):
- 通过增加服务器数量分散负载
- 优势:理论上无限扩展,适应数据量与请求量增长
- 挑战:增加架构复杂度,提升运维难度
分片本质:将完整数据集划分为逻辑子集(Shard),分布式存储于物理服务器群,突破单机性能天花板
MongoDB的横向扩展方案:分片(Sharding)
- 核心思想:将完整数据集划分为逻辑子集(分片),分布式存储于独立服务器
- 集群组成:多个分片协同工作,整体对外提供统一数据库服务
关键术语
- 分片(Shard):存储数据子集的独立节点(物理/逻辑)
- 数据段(Chunk):分片内数据的最小管理单元(默认64MB)
架构解析:分片集群的核心组件
| 组件 | 功能描述 | 高可用方案 |
|---|---|---|
| 分片(Shard) | 存储数据子集,每个分片承载部分数据 | 部署为副本集 |
| 配置服务器(Config Server) | 存储集群元数据: - 分片数据范围映射 - 集群拓扑信息 - 分片策略配置 | 必须部署为副本集 |
| mongos路由 | 请求分发枢纽: 1. 解析客户端请求 2. 查询配置服务器 3. 路由至目标分片 | 多实例负载均衡部署 |
架构1
客户端 mongos路由 分片1 分片2 配置服务器
架构2
元数据同步 元数据同步 客户端 Mongos 配置服务器 分片1 分片2
详细架构版本如下
分片集群 配置服务器 Shard1-1:27018 Shard 1 副本集 Shard1-2:27018 Shard1-3:27018 Shard2-1:27018 Shard 2 副本集 Shard2-2:27018 Config1:27019 Config Server 副本集 Config2:27019 Config3:27019 客户端应用 Mongos 路由 Shard N 副本集
| 组件 | 角色 | 关键职责 | 高可用方案 |
|---|---|---|---|
| 分片(Shard) | 数据存储节点 | 存储集合的子集数据 | 可部署为复制集 |
| 配置服务器(Config Server) | 元数据管理 | 保存集群元数据(分片范围、Chunk分布等) | 必须部署为复制集 |
| 查询路由(Mongos) | 请求代理 | 路由客户端请求至目标分片,聚合结果 | 可多实例部署 |
1 )分片(Shard)
-
存储全量数据的子集
-
部署形态:推荐复制集(3节点)保障高可用
-
扩容逻辑:
总分片数 = 峰值TPS / 单分片支撑TPS × 2 -
每个分片存储数据子集,可部署为单节点或复制集(兼顾可用性与扩展性)
-
示例分片部署配置:
sh# 步骤1 # 在每个分片节点执行(需替换实际端口和复制集名称) mongod --shardsvr --replSet shard1 --port 27018 \ --dbpath /path/to/data \ # 数据存储路径 --logpath /path/to/mongod.log \ # 日志文件路径 --bind_ip_all \ # 允许所有IP连接 --fork # 后台运行 # --replSet shard1:复制集名称需全局唯一(如 shard1/shard2) # --shardsvr:声明此节点为分片角色 # 路径需实际创建(示例:mkdir -p /data/shard1) # 步骤2 # 初始化复制集(在其中一个节点操作) # 连接到任意分片节点(如主节点) mongo --port 27018 # 初始化复制集配置 rs.initiate({ _id: "shard1", // 必须与启动参数 --replSet 一致 members: [ { _id: 0, host: "node1:27018", priority: 3 }, // 主节点(高优先级) { _id: 1, host: "node2:27018", priority: 2 }, // 副本节点 { _id: 2, host: "node3:27018", priority: 1, arbiterOnly: true } // 仲裁节点 ] }); # 验证状态(显示 PRIMARY 即成功) rs.status() # host 字段需用 真实IP/域名,端口与启动命令一致 # 仲裁节点 (arbiterOnly) 不存储数据,仅参与选举 # 步骤3 # 添加分片到集群(通过 mongos 路由) # 连接到 mongos 路由节点 mongo --host mongos_host --port 27017 # 添加分片(复制集名称 + 成员列表) sh.addShard("shard1/node1:27018,node2:27018,node3:27018"); # 格式必须为 复制集名称/节点列表(如 shard1/...),不可直接写 rs0 # 节点列表需包含所有数据节点(仲裁节点无需写入) # node1 和 node2 是 ip/hostname 可访问 # 步骤4 # 验证命令: # 查看集群分片状态 sh.status(); # 输出应包含: # shard1: { "host" : "shard1/node1:27018,...", "state" : 1 }
2 )配置服务器(Config Server)
-
核心元数据存储:
- 分片数据范围分布 (
shard key ranges) - 分片与数据段(Chunk)映射关系
- 数据段范围定义(如
{x: [min, 10)})
- 分片数据范围分布 (
-
高可用要求:必须3节点复制集(生产环境强制配置)
-
灾难影响:元数据丢失将导致集群不可恢复!
-
需部署为复制集确保高可用(3节点推荐):
bashmongod --configsvr --replSet cfgReplSet --port 27019 -
路由节点(mongos)
作为客户端入口,执行请求路由与结果聚合:javascript// NestJS中连接mongos示例 @Module({ imports: [ MongooseModule.forRoot('mongodb://mongos1:27017,mongos2:27017/appDB'), ], }) export class AppModule {}
3 )查询路由(Mongos)
-
请求处理流程:
- 客户端发送请求至 Mongos
- 向Config Server获取分片元数据
- 路由到目标分片,聚合多分片结果后返回客户端
-
路由原理,基于代码模拟示例
javascript// 典型请求处理流程(Node.js环境示例) app.post('/query', async (req, res) => { const { query } = req.body; // 1. Mongos向Config Server获取元数据 const metadata = await configServer.getShardMap(query.key); // 2. 路由到目标分片执行操作 const targetShard = connectToShard(metadata.shardId); const result = await targetShard.executeQuery(query); // 3. 聚合多分片结果(如需) res.send(aggregateResults(result)); });或
ts// NestJS 模拟 mongos 路由逻辑 import { ConfigService } from './config.service'; @Injectable() export class MongosRouter { constructor(private configService: ConfigService) {} async routeRequest(query: Query): Promise<Response> { // 步骤1:解析查询条件 const shardKey = this.extractShardKey(query); // 步骤2:查询配置服务器获取分片映射 const targetShard = await this.configService.locateShard(shardKey); // 步骤3:转发请求到目标分片 const result = await targetShard.executeQuery(query); // 步骤4:聚合多分片结果(如需) return this.aggregateResults(result); } } -
部署建议:贴近应用层部署(减少网络跳数)
4 )部署示例
-
配置服务器部署(3节点副本集)
bash# 节点1 mongod --configsvr --replSet configRepl --dbpath /data/configdb1 --port 27019 # 节点2 mongod --configsvr --replSet configRepl --dbpath /data/configdb2 --port 27019 # 节点3 mongod --configsvr --replSet configRepl --dbpath /data/configdb3 --port 27019 # 初始化副本集 mongo --port 27019 > rs.initiate({ _id: "configRepl", configsvr: true, members: [ {_id: 0, host: "host1:27019"}, {_id: 1, host: "host2:27019"}, {_id: 2, host: "host3:27019"} ] }) -
分片节点部署(每个分片为3节点副本集)
bash# 分片1节点1 mongod --shardsvr --replSet shardRepl1 --dbpath /data/shard1-1 --port 27018 # 分片1节点2 mongod --shardsvr --replSet shardRepl1 --dbpath /data/shard1-2 --port 27018 # 初始化分片副本集 mongo --port 27018 > rs.initiate({ _id: "shardRepl1", members: [ {_id: 0, host: "host1:27018"}, {_id: 1, host: "host2:27018"}, {_id: 2, host: "host3:27018"} ] }) -
启动Mongos路由
bashmongos --configdb configRepl/host1:27019,host2:27019,host3:27019 --port 27017 -
集群配置
bashmongo --port 27017 # 添加分片 > sh.addShard("shardRepl1/host1:27018,host2:27018,host3:27018") # 启用数据库分片 > sh.enableSharding("mydatabase") # 分片集合 > sh.shardCollection("mydatabase.mycollection", {_id: "hashed"}) -
连接方案
typescript// 1. 安装依赖:npm install @nestjs/mongoose mongoose import { Module } from '@nestjs/common'; import { MongooseModule } from '@nestjs/mongoose'; @Module({ imports: [ // 连接 Mongos 路由(非直接连分片) MongooseModule.forRoot('mongodb://mongos-router:27017/mydatabase', { useNewUrlParser: true, useUnifiedTopology: true, retryAttempts: 5, // 网络波动重试 retryDelay: 3000, // 重试间隔 readPreference: 'primary' // 明确读偏好 }), ], }) export class DatabaseModule {} // 2. 定义模型与分片键 import { Schema, Prop, SchemaFactory } from '@nestjs/mongoose'; import { Document } from 'mongoose'; @Schema({ shardKey: { region: 1 } }) // 指定分片键为 "region" export class Order extends Document { @Prop({ required: true }) region: string; @Prop() amount: number; } export const OrderSchema = SchemaFactory.createForClass(Order);- 关键说明:
- NestJS 应用仅连接 Mongos 路由,屏蔽底层分片细节
- 分片键在模型装饰器
@Schema中声明,需与 MongoDB 分片配置一致
连接方式对比
方式 配置示例 优点 缺点 直连分片节点 mongodb://host1:27018,host2:27018/mydatabase❌ 破坏分片逻辑 数据路由错误查询性能低下 连接Mongos mongodb://mongos-host:27017/mydatabase✅ 自动路由查询 需额外维护路由服务 多Mongos负载 mongodb://mongos1:27017,mongos2:27017/mydatabase?replicaSet=rs-mongos✅ 高可用+负载均衡 需要部署多个Mongos实例 - 关键说明:
-
关于 readPreference
-
readPreference 的作用:控制客户端从副本集(Replica Set)中哪个节点读取数据,实现读写分离、负载均衡或就近访问。其行为受副本集状态和数据同步延迟影响。
-
五种模式详解
模式 读取目标 一致性风险 典型场景 primary(默认)✅ 仅主节点 最低 金融交易、需强一致性的写后读操作 primaryPreferred️ 优先主节点 → 主节点故障时降级到从节点 低 高可用场景(如电商订单查询) secondary❌ 仅从节点 高 报表分析、历史数据查询等容忍延迟的读密集型业务 secondaryPreferred️ 优先从节点 → 从节点不可用时降级到主节点 中等 读写分离的通用场景 nearest🌐 选择网络延迟最低的节点(无论主从) 高 全球化部署(如CDN资源就近访问) -
关键补充
- 降级机制:
primaryPreferred/secondaryPreferred在目标节点不可用时自动切换备选节点 - 数据延迟风险:非
primary模式可能读取旧数据(因主从同步延迟) - 超时控制:可通过
maxStalenessSeconds限制从节点数据延迟(需≥90秒)
- 降级机制:
-
使用注意事项
- 主节点故障影响
primary模式在主节点宕机时完全不可读(需等待新主节点选举)- 生产环境建议用
primaryPreferred避免服务中断
- 分片键匹配
- 若查询未包含分片键(如
region),Mongos会广播到所有分片,导致性能下降 - 优化方案:关键查询需显式指定分片键(例:
find({ region: "Asia" }))
- 若查询未包含分片键(如
- 主节点故障影响
-
Tag 精细化路由
-
通过标签定向节点类型(如OLTP或OLAP节点):
javascript// 连接字符串示例 mongodb://nodes/?readPreference=secondary&tagSet=use:analytics -
适用于混合负载集群(如高性能节点处理交易,低配节点处理报表)
-
-
与 writeConcern 的协同
-
读写一致性保障:写操作设置
writeConcern: majority+ 读操作设置readConcern: majority,可确保读取已持久化到多数节点的数据javascriptdb.orders.insert({...}, { writeConcern: { w: "majority" } }) db.orders.find().readConcern("majority")
-
-
场景选择建议
需求 推荐模式 理由 订单支付后实时查询 primary避免因主从延迟导致支付状态显示不一致 用户历史订单浏览 secondaryPreferred分流读请求,减轻主节点压力 跨国服务就近访问 nearest利用本地节点降低延迟(如亚洲用户访问东京节点) 凌晨生成大数据报表 secondary隔离资源消耗,不影响线上交易 -
配置示例(Node.js驱动)
javascriptconst { MongoClient, ReadPreference } = require('mongodb'); const client = new MongoClient(uri, { readPreference: ReadPreference.SECONDARY_PREFERRED, maxStalenessSeconds: 120 // 从节点数据延迟不超过120秒 });
- 关键配置说明
-
单点连接(基础方案)
typescriptmongodb://<mongos_ip>:27017/mydatabase -
多Mongos高可用(生产推荐)
typescriptmongodb://mongos1:27017,mongos2:27017,mongos3:27017/mydatabase?replicaSet=rs-mongos -
重要参数
replicaSet=rs-mongos:当多个Mongos组成副本集时必需readPreference=secondaryPreferred:读分离配置w=majority:写确认机制
8.架构建议
-
Mongos部署原则
- 每个应用服务器部署本地Mongos实例(减少网络延迟)
- 最少部署2个Mongos实现高可用
- 使用负载均衡器暴露统一入口
-
分片策略优化
javascript// 范围分片(适用于连续查询) sh.shardCollection("db.orders", {orderDate: 1}) // 哈希分片(均匀分布) sh.shardCollection("db.users", {_id: "hashed"}) // 组合分片键 sh.shardCollection("db.logs", {app: 1, timestamp: -1}) -
性能监控点
- Mongos连接池使用率(
db.serverStatus().network) - 分片区块分布均衡性(
db.chunks.stats()) - 查询路由效率(
db.currentOp()查看op: "query")
- Mongos连接池使用率(
关键结论:必须通过Mongos路由连接分片集群!直连分片节点会导致:
- 查询仅访问单个分片,返回不完整数据
- 写入可能分配到错误分片
- 完全失去分片的负载均衡能力
- 副本集故障切换失效
- 生产环境应在Mongos层实现:
客户端 负载均衡器 Mongos实例1 Mongos实例2 分片集群
分片集群的数据分布与主分片机制
分片集群支持灵活的数据管理策略,允许混合存储分片与非分片集合:
1 ) 分片与非分片集合共存
- 分片集合:数据按分片键(Shard Key)分布至多个分片。
- 非分片集合:存储于主分片(Primary Shard),每个数据库独立指定一个主分片。
2 ) 主分片的核心作用
- 每个数据库存在主分片(Primary Shard)
- 存储该数据库内所有未分片的集合。
- 选择逻辑:
- 新数据库创建时,自动选择数据量最少的分片作为主分片。
- 同一分片可兼任多个数据库的主分片或普通分片(如分片 A 是 DB1 的主分片,同时是 DB2 的普通分片)
3 ) 主分片迁移
-
手动迁移场景:需调整主分片归属(如从分片 A 迁移至分片 B)
-
风险与限制:
-
迁移耗时与数据量成正比,期间可能影响数据库可用性
-
手动迁移主分片代价高昂(需停机或在线迁移工具)
-
原生 MongoDB 命令示例:
mongodb// 迁移数据库 "mydb" 的主分片至 "shardB" db.adminCommand({ movePrimary: "mydb", to: "shardB" })
-
-
运维建议:避免频繁迁移,优先通过分片键设计优化数据分布
分片键设计:策略与优化方案
1 ) 分片键类型
| 类型 | 生成方式 | 适用场景 |
|---|---|---|
| 范围分片键 | 直接使用字段值 | 范围查询高效(如时间序列) |
| 哈希分片键 | 字段值哈希运算(如MD5) | 数据均匀分布 |
2 )分片键的核心作用
- 数据分布依据:根据文档的分片键值划分Chunk,决定数据存储位置
- 强制要求:分片键必须是集合的索引字段(单字段或复合索引前缀)
3 )分片键作用原理
- 通过字段值将文档划分到不同数据段(Chunk),每个Chunk关联特定分片
4 )分片键核心要求
-
必须为索引字段(单字段或复合索引前缀)
-
创建语法:
javascript// 哈希分片键(解决单向增长问题) sh.shardCollection("appDB.users", { "user_id": "hashed" }) // 等效原生SQL(概念类比) // CREATE TABLE transactions (...) PARTITION BY HASH(id); // 复合分片键(解决取值范围窄问题) sh.shardCollection("logs.events", { "severity": 1, "uuid": 1 }); -
原生 MongoDB 命令示例(启用分片):
mongodb// 对数据库 "mydb" 和集合 "orders" 启用分片(使用哈希分片键 "orderId") sh.enableSharding("mydb") sh.shardCollection("mydb.orders", { orderId: "hashed" })
-
必须关联索引:
- 单字段索引(如
{ customerId: 1 }) - 复合索引(如
{ region: 1, createdAt: -1 })
- 单字段索引(如
-
数据段(Chunk)创建:
- 基于片键值范围划分(如
x ∈ [0,10)) - 或基于哈希值划分(如
hash(x) ∈ [0x0000, 0x3FFF])
- 基于片键值范围划分(如
5 )数据分布逻辑
plaintext
[分片键值范围]
/ | \
Chunk1 (min-10) Chunk2 (10-20) Chunk3 (20-max)
↓ ↓ ↓
Shard A Shard B Shard C 6 )分片键设计禁忌与补救
- 不可更改性:分片键一旦设定无法修改!
- 补救方案:
- 范围窄 → 组合高基数字段形成复合键
- 分布偏斜 → 引入均匀分布字段(如随机数)
- 单向增减 → 替换为哈希分片键
7 )数据段分配示例:
sql
-- 原生SQL类比逻辑
SELECT shard_id
FROM chunk_ranges
WHERE ? BETWEEN min_value AND max_value;三大设计原则与实践案例
| 设计原则 | 劣质案例 | 优化方案 | 技术本质 |
|---|---|---|---|
| 取值范围广 | 布尔类型(true/false) | 添加时间戳字段构成复合键 | 避免数据段(Chunk)过少 |
| 分布均衡性 | 90%数据集中某特定值 | 引入随机后缀/哈希转换 | 防止分片负载倾斜 |
| 避免单向增长 | ObjectId/时间戳 | 使用hashed分片模式 |
规避写入热点 |
-
取值广度
- 避免低基数字段(如布尔值)
- 改进方案:使用复合分片键(
{low_card_field, high_card_field})
-
分布均衡性
- 警惕数据倾斜(如90%文档的
status=10) - 解决方案:添加均衡分布字段(如随机后缀)
- 警惕数据倾斜(如90%文档的
-
避免单向变化
- 禁止直接使用单调递增字段(如
ObjectId) - 替代方案:采用哈希分片键
- 禁止直接使用单调递增字段(如
不可逆操作:分片键一旦设定无法修改!设计需前瞻性评估业务场景
1 ) Chunk生命周期管理
2 ) 动态平衡机制:数据段(Chunk)的分裂与迁移
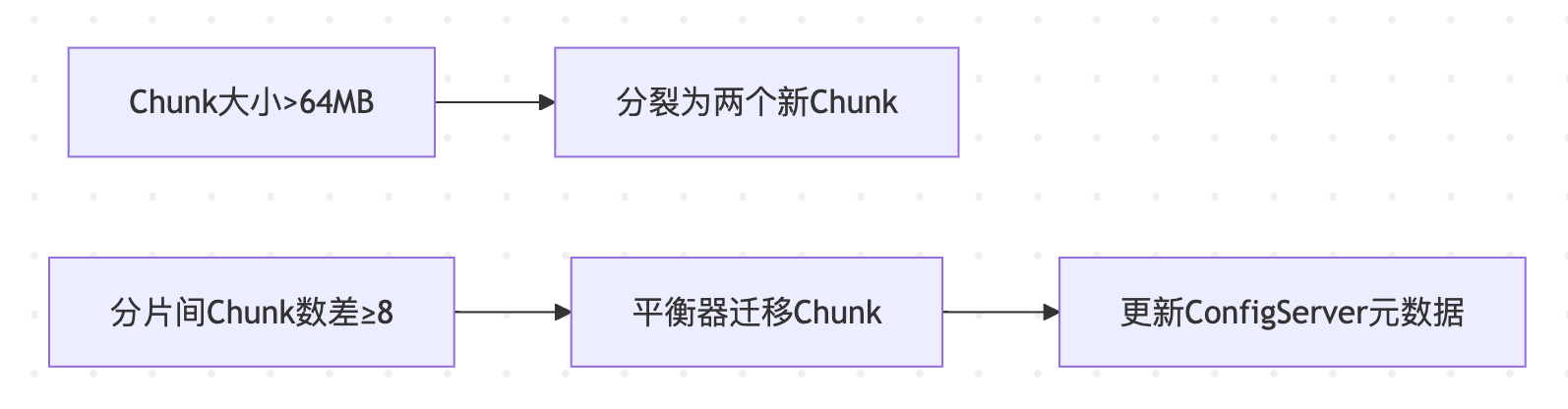
2.1 分裂机制(Splitting)
-
触发条件:
- Chunk文档数(
MAX_CHUNK_DOCS) > 250,000(默认, 250k) - Chunk数据尺寸(
chunksize) > 64MB(默认) - 数据尺寸超过阈值(默认128MB)
- Chunk文档数(
-
核心特点:纯元数据操作(更新Config Server中段范围定义),毫秒级完成,无物理数据移动
-
底层实现:仅更新配置服务器的元数据(无数据物理移动)
-
分裂过程:
python# 伪代码逻辑 if chunk.size > threshold: new_ranges = split_chunk(chunk) # 仅更新元数据 configDB.updateChunkMetadata(new_ranges) -
元数据更新示例
plaintext原Chunk: [10, 30] 分裂为: [10, 20] 和 [20, 30]
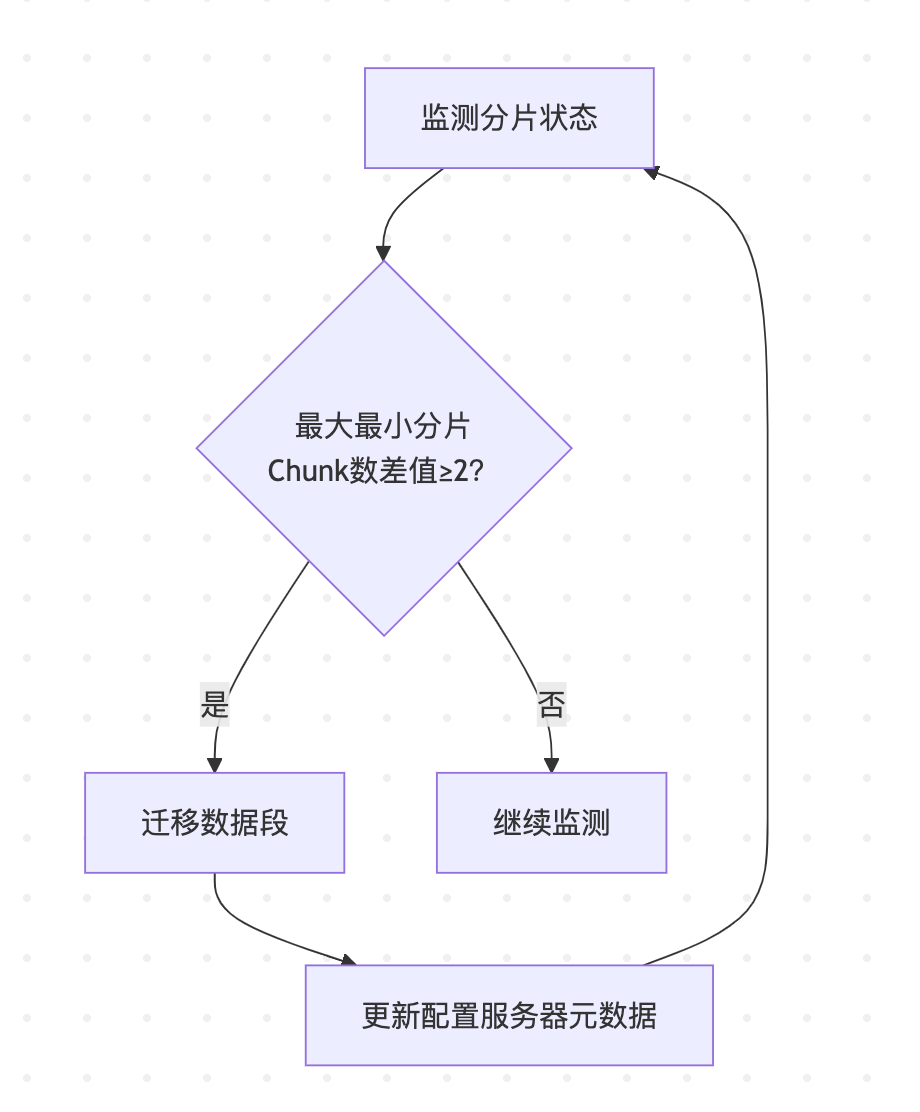
2.2 平衡器(Balancer)工作逻辑
-
运行机制:
- 监控分片间Chunk数量差异
- 当
max_shard_chunks - min_shard_chunks > 迁移阈值时触发迁移
-
触发迁移场景:
- 新增/移除分片(新分片初始Chunk=0)
- 数据分布严重倾斜 (数据写入热点导致不均衡)
- 分片间Chunk数量差值 ≥ 8(默认阈值)
- 手动执行
sh.startBalancer()
-
最佳实践:在预设时间窗口运行(避开业务高峰)
-
平衡过程
plaintext迁移前: ShardA(3 Chunks) | ShardB(1 Chunk) → 差值=2 > 阈值 平衡器迁移1个Chunk至ShardB 迁移后: ShardA(2 Chunks) | ShardB(2 Chunks) -
关键配置:平衡器仅在预设时间窗口运行(避免高峰影响性能)
查询路由机制与性能优化
1 ) 查询路由逻辑
路由请求 路由请求 Client Mongos 配置服务器 ShardA ShardB
2 ) 三类查询性能对比
| 查询类型 | Mongos路由行为 | 性能等级 | 优化方案 |
|---|---|---|---|
| 精准分片键查询 | 直连目标分片 | ⭐⭐⭐⭐⭐ | 强制包含分片键条件 |
| 范围分片键查询 | 并发查询相关分片 | ⭐⭐⭐ | 缩小查询范围 |
| 无分片键查询 | 广播查询所有分片 | ⭐ | 创建覆盖索引或重组查询逻辑 |
NestJS中分片查询示例
typescript
// 精准分片键查询(高效)
async getOrderById(orderId: string) {
return this.orderModel.findOne({ _id: orderId }).exec();
}
// 无分片键查询(低效,慎用!)
async findOrdersByStatus(status: string) {
return this.orderModel.find({ status }).exec(); // 触发广播查询
} 分片查询优化方案
sql
/* 低效查询(全分片广播) */
SELECT * FROM users WHERE age > 30;
/* 优化方案1:添加分片键条件 */
SELECT * FROM users
WHERE region = 'Asia' -- 分片键字段
AND age > 30;
/* 优化方案2:使用覆盖索引 */
CREATE INDEX idx_region_age ON users(region, age);
SELECT _id, name FROM users
WHERE region = 'Asia' AND age > 30; -- 索引覆盖3 ) 路由过程代码模拟
javascript
// mongos路由伪代码
async function routeQuery(query) {
const shardKey = extractShardKey(query);
const chunk = await configDB.getChunk(shardKey); // 查询配置服务器
const targetShard = chunk.assignedShard;
return await targetShard.execute(query);
}完整版实施部署方案
MongoDB分片集群拓扑结构
典型分片集群包含三层组件:
存储元数据 客户端应用 mongos路由 配置服务器副本集 分片1-副本集 分片2-副本集 分片N-副本集 Config Server 1 Config Server 2 Config Server 3 Shard1-Primary Shard1-Secondary Shard1-Arbiter
-
配置服务器(Config Server)
- 存储集群元数据(分片信息、数据分布)
- 需3节点组成副本集(生产环境必选)
-
分片节点(Shard Server)
- 实际存储数据,每个分片建议为3节点副本集(Primary + Secondary + Arbiter)
- 分片数量根据数据量和吞吐需求动态扩展
-
路由节点(mongos)
- 无状态服务,可多实例部署
- 客户端唯一接入点,负责请求路由和结果聚合
分片集群搭建步骤
环境准备(以3台服务器为例)
| 角色 | Server1 | Server2 | Server3 |
|---|---|---|---|
| Config Server | 192.168.0.1:27019 | 192.168.0.2:27019 | 192.168.0.3:27019 |
| Shard1 | 192.168.0.1:27018 | 192.168.0.2:27018 | 192.168.0.3:27018 |
| Shard2 | 192.168.0.1:27028 | 192.168.0.2:27028 | 192.168.0.3:27028 |
| mongos | 192.168.0.1:27017 | 192.168.0.2:27017 | 192.168.0.3:27017 |
1 ) 部署配置服务器副本集
每台服务器创建配置文件 config.conf:
yaml
config.conf
storage:
dbPath: /data/configdb
systemLog:
destination: file
path: /var/log/mongodb/config.log
net:
bindIp: 0.0.0.0
port: 27019
replication:
replSetName: configRepl # 副本集名称
sharding:
clusterRole: configsvr # 声明为配置服务器 启动服务并初始化副本集:
bash
启动服务
mongod -f config.conf
在任意节点初始化(通过mongo shell)
rs.initiate({
_id: "configRepl",
configsvr: true,
members: [
{_id:0, host: "192.168.0.1:27019"},
{_id:1, host: "192.168.0.2:27019"},
{_id:2, host: "192.168.0.3:27019"}
]
})2 ) 部署分片节点
以Shard1为例,创建配置文件 shard1.conf:
yaml
shard1.conf
storage:
dbPath: /data/shard1
systemLog:
destination: file
path: /var/log/mongodb/shard1.log
net:
port: 27018
replication:
replSetName: shard1 # 分片副本集名称
sharding:
clusterRole: shardsvr # 声明为分片节点 启动服务并初始化副本集(重复此步骤部署Shard2):
bash
mongod -f shard1.conf
mongo --port 27018
> rs.initiate({_id:"shard1", members:[
{_id:0, host:"192.168.0.1:27018", priority:2},
{_id:1, host:"192.168.0.2:27018"},
{_id:2, host:"192.168.0.3:27018", arbiterOnly:true}
]})3 ) 部署mongos路由
每台服务器创建 mongos.conf:
yaml
mongos.conf
systemLog:
path: /var/log/mongodb/mongos.log
net:
port: 27017
sharding:
configDB: configRepl/192.168.0.1:27019,192.168.0.2:27019,192.168.0.3:27019 启动服务:
bash
mongos -f mongos.conf4 ) 集群分片配置
连接任意mongos节点:
bash
mongo --port 27017添加分片并启用分片数据库:
javascript
// 添加分片
sh.addShard("shard1/192.168.0.1:27018,192.168.0.2:27018,192.168.0.3:27018")
sh.addShard("shard2/192.168.0.1:27028,192.168.0.2:27028,192.168.0.3:27028")
// 启用数据库分片
sh.enableSharding("mydatabase")
// 对集合分片(以user_id作为分片键)
sh.shardCollection("mydatabase.users", {user_id: "hashed"})Nest.js连接mongos路由
1 ) 安装依赖
bash
npm install @nestjs/mongoose mongoose 2 ) 配置Mongoose模块
typescript
// app.module.ts
import { MongooseModule } from '@nestjs/mongoose';
@Module({
imports: [
MongooseModule.forRoot('mongodb://192.168.0.1:27017,192.168.0.2:27017,192.168.0.3:27017/mydatabase', {
dbName: 'mydatabase',
user: 'admin', // 若启用认证
pass: 'password',
replicaSet: 'configRepl', // 指向配置服务器副本集
directConnection: false // 强制通过mongos路由
})
],
})
export class AppModule {}3 ) 数据模型与操作
typescript
// user.schema.ts
import { Prop, Schema, SchemaFactory } from '@nestjs/mongoose';
import { Document } from 'mongoose';
@Schema()
export class User extends Document {
@Prop({ required: true })
user_id: number;
@Prop()
name: string;
}
export const UserSchema = SchemaFactory.createForClass(User);
// user.service.ts
import { Model } from 'mongoose';
import { Injectable } from '@nestjs/common';
import { InjectModel } from '@nestjs/mongoose';
@Injectable()
export class UserService {
constructor(@InjectModel(User.name) private userModel: Model<User>) {}
async create(user: User): Promise<User> {
return this.userModel.create(user); // 自动路由到正确分片
}
}4 ) 关键注意事项
-
分片键选择
- 优先选择基数大、分布均匀的字段(如
user_id) - 避免单调递增键(如时间戳)导致热点分片
- 优先选择基数大、分布均匀的字段(如
-
安全配置
- 启用访问控制:在配置文件中添加
security.authorization: enabled - 开启TLS加密通信
- 启用访问控制:在配置文件中添加
-
性能优化
- 部署多个mongos实例实现负载均衡
- 监控分片平衡:
sh.status()查看数据分布
分片集群部署拓扑
数据层 控制层 应用层 元数据同步 元数据同步 元数据同步 Shard01 RS Shard02 RS Shard03 RS Config ReplicaSet Mongos1 Mongos2 Client
生产环境部署与运维最佳实践
1 ) 容量规划公式
sh
理论最大数据量 = 分片数量 × 单分片存储容量
建议分片数 = (峰值TPS / 单分片支撑TPS) × 冗余系数(1.5-2)2 ) 部署规范
| 组件 | 配置要求 | 关键参数示例 |
|---|---|---|
| Mongos | 与应用同节点部署 最小2节点 | mongos --configdb cfgReplSet |
| Config Server | 3节点复制集 | mongod --configsvr --replSet |
| Shard节点 | 最小3节点复制集 | mongod --shardsvr --replSet |
3 )分片键设计黄金法则
- 基数原则:选择高基数字段(如用户ID)
- 写分布:避免单调递增键(导致写入热点)
- 查询关联:匹配高频查询模式
4 ) 运维红线
- 🚫 禁止在生产时段修改主分片
- 🚫 禁用
balancer需评估数据分布 - 🚫 避免无分片键的聚合操作(如
$lookup跨分片关联) - 分片键一旦设定不可更改
5 )分片集群性能公式:
吞吐量 = min(mongos处理能力, 分片副本集写入能力) × 分片数量
6 ) 监控命令集
ts
// 查看Chunk分布
db.getSiblingDB("config").chunks.find().pretty();
// 检查平衡器状态
sh.isBalancerRunning();
// 评估分片负载
db.adminCommand({ listShards: 1 });关键知识点补充
1 ) 配置服务器高可用
- 必须部署为3节点复制集(生产环境强制要求)
- 元数据丢失将导致集群不可恢复
2 ) 分片集群限制
- 事务操作仅支持在分片键上的精确查询
$lookup跨分片关联查询性能较差- 最大分片数:官方推荐 ≤ 1000 个分片
- 命名空间限制:
config数据库存储元数据,单个集合最大16MB
3 ) 性能监控命令
javascript
// 查看Chunk分布
db.getSiblingDB("config").chunks.find().pretty();
// 监控平衡器状态
sh.isBalancerRunning(); 4 ) 数据迁移优化
bash
# 设置迁移时间窗口
use config
db.settings.update(
{ _id: "balancer" },
{ $set: { activeWindow: { start: "23:00", stop: "06:00" } } },
{ upsert: true }
)5 ) 冷热数据分层案例
sh
// 基于时间范围的分片策略(热数据存SSD分片)
sh.addShardTag("shard1", "SSD");
sh.addTagRange("logs.events",
{ "timestamp": ISODate("2023-01-01") },
{ "timestamp": ISODate("2023-06-01") },
"SSD"
);6 ) 灾难恢复方案
- Config Server备份:每日
mongodump --configDB - 分片级恢复:使用
--shardsvr参数单独还原分片
7 ) 终极建议:分片键设计应提前模拟真实数据分布,避免后期不可逆调整!
关键总结
- 分片本质:通过数据水平拆分实现无限横向扩展
- 核心组件协作:
mongos:智能路由网关Config Server:集群元数据中心库Shard:数据存储与计算单元
- 设计关键:
- 分片键选择决定集群性能上限
- Chunk分裂与迁移保障数据均衡
- 部署建议:
- 配置服务器必须3节点复制集
- 生产环境分片至少部署为2副本集+1仲裁节点
通过分片集群,MongoDB可在不中断服务的前提下,实现从TB到PB级数据的线性扩展,支撑千万级QPS场景
关键总结与扩展思考
1 ) 架构本质
- 分片集群通过动态数据段管理(分裂/迁移)实现水平扩展,配合Mongos智能路由,在保障扩展性的同时最大化查询效能
2 ) 设计铁律
- 分片键选择需在业务需求(查询模式)与技术约束(分布均衡)间取得平衡
- 遵循 取值范围广 + 分布均匀 + 非单向增长 三位一体原则
终极设计原则:
- 分片集群通过动态数据段管理(分裂/迁移)实现数据均匀分布,配合Mongos智能路由,在保障扩展性的同时最大化查询效能
- 分片键选择需在业务需求(查询模式)与技术约束(分布均衡)间取得平衡,这是架构设计的核心挑战所在
3 ) 进阶挑战
- 事务支持:仅限分片键精准查询范围内的操作
- 索引限制:分片键必须为索引,全局二级索引需特殊处理
- 扩容策略:通过
addShard()动态扩展,需预判业务增长曲线
终极建议:在测试环境使用 mongoreplay 工具模拟真实流量,验证分片键设计合理性,避免生产环境不可逆调整
技术演进方向
-
动态平衡 2.0:
- 实时流量监控自动调整分片边界
- 预测式分片预分配(基于机器学习)
-
智能路由优化:
typescript// 增强型 mongos 路由逻辑(NestJS 实现) @Injectable() class SmartRouter extends MongosRouter { async routeRequest(query: Query) { if (this.cache.has(query.pattern)) { return super.cachedRoute(query); // 缓存命中 } // 实时分析查询模式 const analysis = this.analyzer.predict(query); this.configService.adjustShardRanges(analysis); return super.routeRequest(query); } } -
结语
- MongoDB 分片集群通过三大核心组件的协同工作 ------ 分片实现数据分布式存储,配置服务器维护全局视图,mongos 提供无缝路由 ------ 构建了真正弹性的水平扩展能力
- 其中主分片机制对非分片数据的托管,使系统能兼容传统架构平滑过渡
- 设计时需深度权衡扩展性收益与架构复杂度成本,尤其在分片键设计和主分片规划上需注入前瞻性思考
- 随着流量模式分析技术和自适应平衡算法的发展,分片集群正向着更智能、更透明的方向持续演进