在数据驱动决策的今天,数据的"新鲜度"已成为企业在激烈市场竞争中脱颖而出的核心竞争力。传统的 T+1 数据处理模式,由于其固有的延迟,已无法满足现代商业对实时性的苛刻要求。无论是为了实现毫秒级的业务库与数据仓库同步、动态调整运营策略,还是为了在秒级内修正错误数据以保障决策的准确性,强大的实时数据更新能力都显得至关重要。
Apache Doris作为一个现代化的实时分析型数据库,其设计的核心目标之一便是提供极致的数据新鲜度。它通过强大的数据模型和灵活的更新机制,将数据分析的延迟从天级、小时级成功压缩至秒级,为用户构建实时、敏捷的商业决策闭环提供了坚实的基础。
本文档将作为一份官方指南,系统性地阐述 Apache Doris 的数据更新能力,内容涵盖其核心原理、多样的更新与删除方式、典型的应用场景,以及在不同部署模式下的性能最佳实践,旨在帮助您全面掌握并高效利用 Doris 的数据更新功能。
1. 核心概念:表模型与更新机制
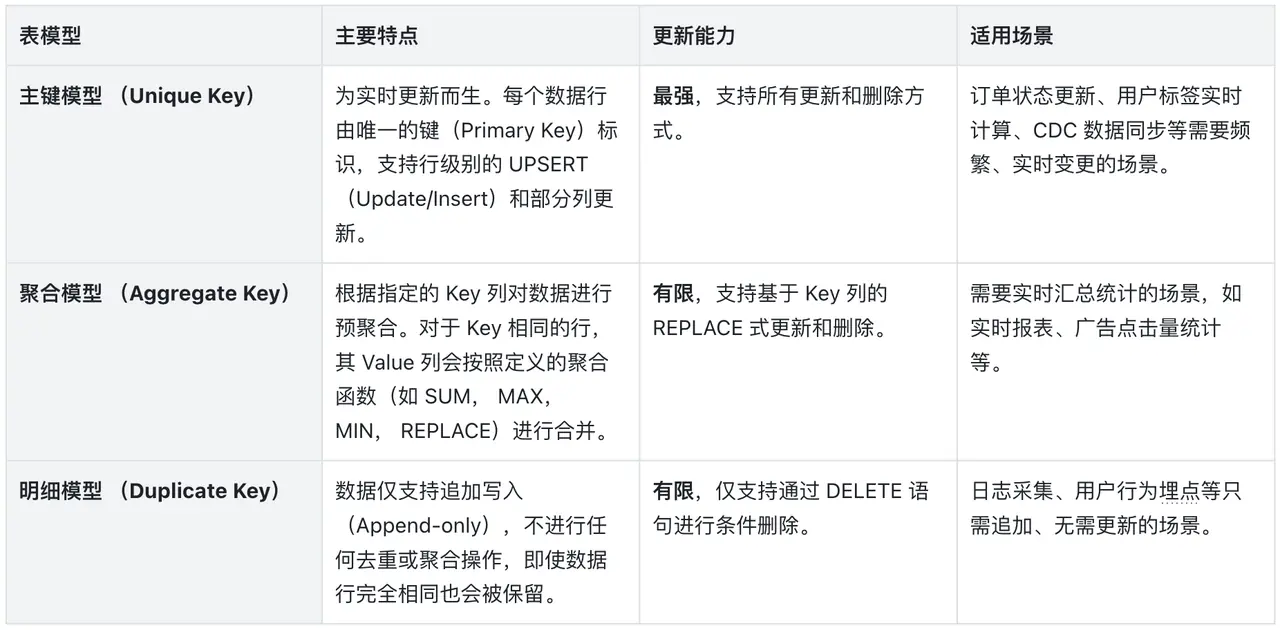
在 Doris 中,数据表的表模型(Data Model)决定了其数据组织方式和更新行为。为了支持不同的业务场景,Doris 提供了三种表模型:主键模型(Unique Key)、聚合模型(Aggregate Key)和明细模型(Duplicate Key)。其中,主键模型是实现复杂、高频数据更新的核心。
1.1. 表模型概览
1.2. 数据更新方式
Doris 提供了两大类数据更新方法:通过数据导入进行更新 和通过 DML 语句进行更新。
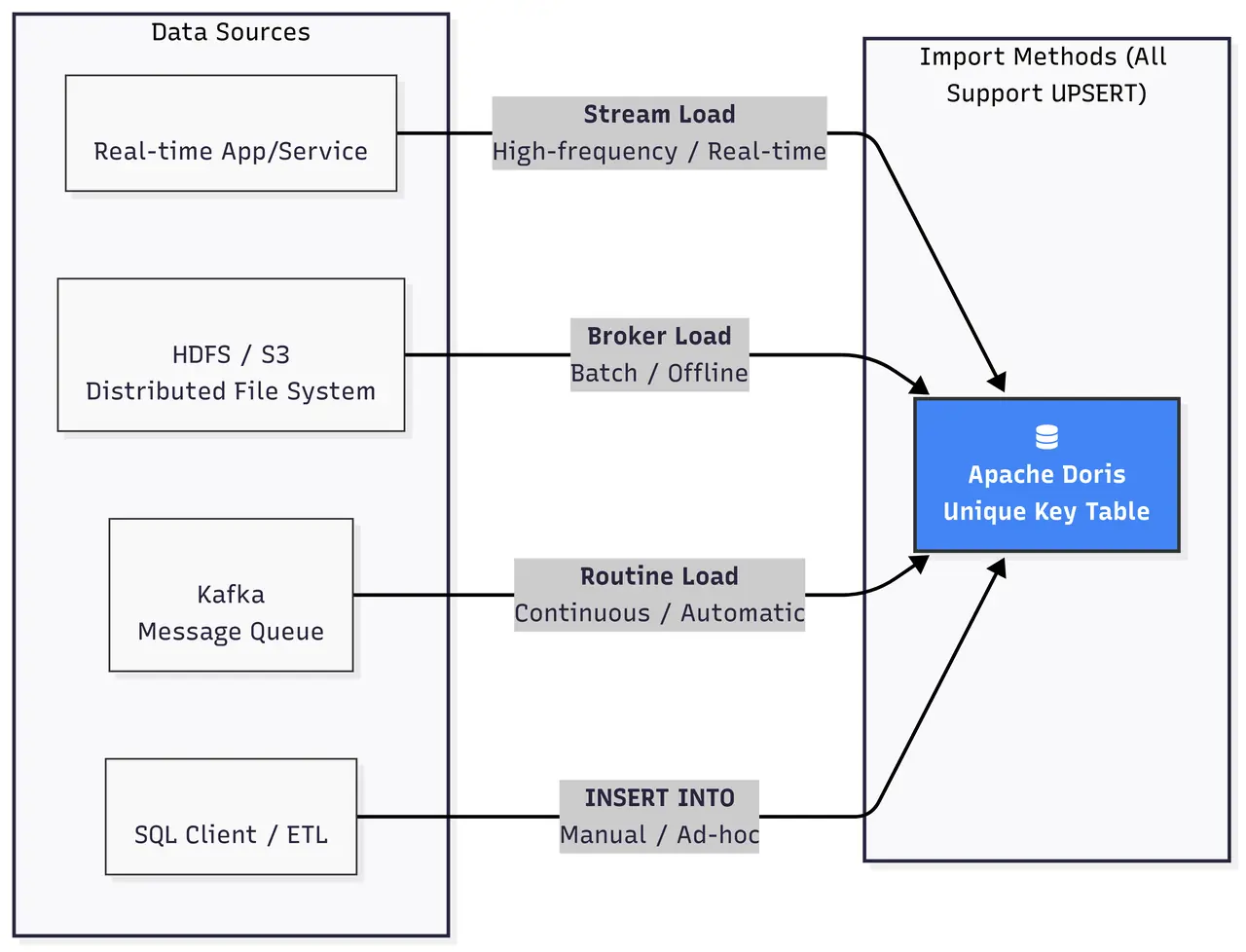
1.2.1. 通过导入进行更新 (UPSERT)
这是 Doris 推荐的高性能、高并发 的更新方式,主要针对主键模型 。所有的导入方式(Stream Load, Broker Load, Routine Load, INSERT INTO)都天然支持 UPSERT 语义。当新数据导入时,如果其主键已存在,Doris 会用新行数据覆盖旧行数据;如果主键不存在,则插入新行。
1.2.2. 通过 UPDATE DML 语句更新
Doris 支持标准的 SQL UPDATE 语句,允许用户根据 WHERE 子句指定的条件对数据进行更新。这种方式非常灵活,支持复杂的更新逻辑,例如跨表关联更新。
Plain
-- 简单更新
UPDATE user_profiles SET age = age + 1 WHERE user_id = 1;
-- 跨表关联更新
UPDATE sales_records t1
SET t1.user_name = t2.name
FROM user_profiles t2
WHERE t1.user_id = t2.user_id;注意 :UPDATE 语句的执行过程是先扫描满足条件的数据,然后将更新后的数据重新写回表中。它适合低频、批量的更新任务。不建议对 UPDATE 语句进行高并发操作 ,因为并发的 UPDATE 在涉及相同主键时,无法保证数据的隔离性。
1.2.3. 通过 INSERT INTO SELECT DML 语句更新
由于 Doris 默认提供了 UPSERT 的语义,因此使用INSERT INTO SELECT也可以实现类似于UPDATE的更新效果。
1.3. 数据删除方式
与更新类似,Doris 也支持通过导入和 DML 语句两种方式删除数据。
1.3.1. 通过导入进行标记删除
这是一种高效的批量删除方法,主要用于主键模型 。用户可以在导入数据时,增加一个特殊的隐藏列 DORIS_DELETE_SIGN。当某行的该列值为 1 或 true 时,Doris 会将该主键对应的数据行标记为删除(关于 delete sign 的原理,后文会有详细的介绍)。
Plain
// Stream Load 导入数据,删除 user_id 为 2 的行
// curl --location-trusted -u user:passwd -H "columns:user_id, __DORIS_DELETE_SIGN__" -T delete.json http://fe_host:8030/api/db_name/table_name/_stream_load
// delete.json 内容
[
{"user_id": 2, "__DORIS_DELETE_SIGN__": "1"}
]1.3.2. 通过 DELETE DML 语句删除
Doris 支持标准的 SQL DELETE 语句,可以根据 WHERE 条件删除数据。
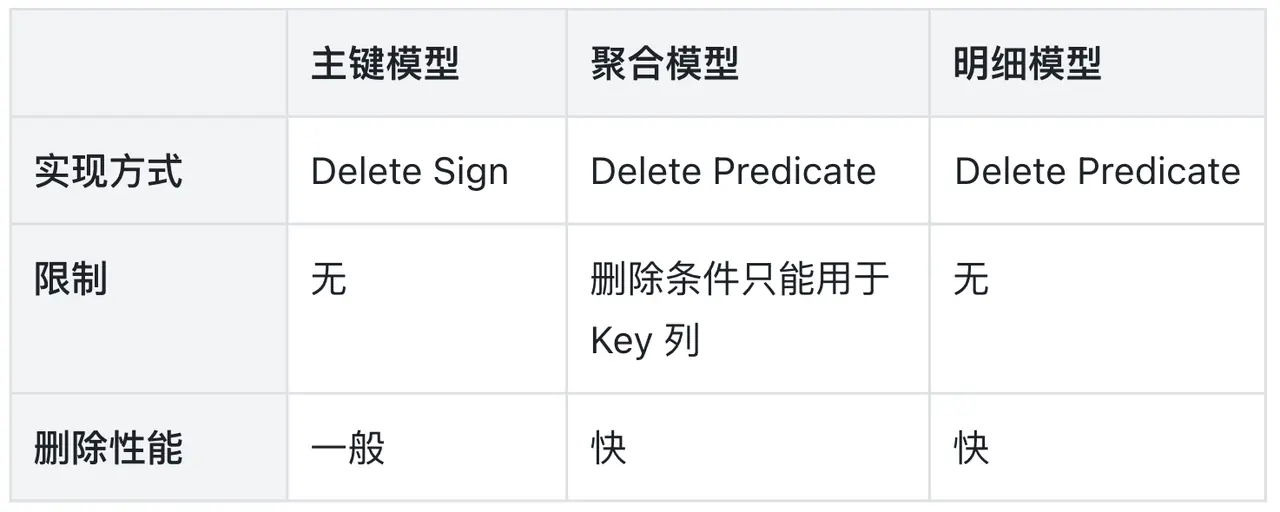
- 主键模型 :
DELETE语句会将满足条件的行的主键重新写入,并附带删除标记。因此,其性能与需要删除的数据量成正比。主键模型上的DELETE语句执行原理与UPDATE语句非常相似,先通过查询把要删除的数据读取出来,然后再附加删除标记进行一次写入。相比UPDATE语句,DELETE语句只需要写入 Key 列和删除标记列,相对轻量一些。 - 明细/聚合模型 :
DELETE语句的实现方式是记录一个删除谓词(Delete Predicate)。在查询时,这个谓词会作为一个运行时过滤器(Runtime Filter)来过滤掉被删除的数据。因此,DELETE操作本身非常快,几乎与删除的数据量无关。但需要注意,在明细/聚合模型上进行高频的DELETE操作会累积大量的运行时过滤器,严重影响后续的查询性能。
Plain
DELETE FROM user_profiles WHERE last_login < '2022-01-01';下表是对使用 DML 语句进行删除的一个简要总结:
2. 深入主键模型:原理与实现
主键模型是 Doris 实现高性能实时更新的基石。理解其内部工作原理,对于充分发挥其性能至关重要。
2.1. Merge-on-Write (MoW) vs. Merge-on-Read (MoR)
主键模型有两种数据合并策略:写时合并(MoW)和读时合并(MoR)。自 Doris 2.1 版本起,MoW 已成为默认且推荐的实现方式。

MoW 机制通过在写入阶段付出少量代价,换取了查询性能的巨大提升,完美契合了 OLAP 系统"重读轻写"的特点。
下图简要的介绍了 MoW 的核心机制:

2.2. 条件更新 (Sequence Column)
在分布式系统中,数据乱序到达是一个常见问题。例如,一个订单状态先后变更为"已支付"和"已发货",但由于网络延迟,代表"已发货"的数据可能先于"已支付"的数据到达 Doris。
为了解决这个问题,Doris 引入了 Sequence 列 机制。用户可以在建表时指定一个列(通常是时间戳或版本号)作为 Sequence 列。当处理具有相同主键的数据时,Doris 会比较它们的 Sequence 列的值,并始终保留 Sequence 值最大的那一行数据,从而保证了数据的最终一致性,即使数据乱序到达。
Plain
CREATE TABLE order_status (
order_id BIGINT,
status_name STRING,
update_time DATETIME
)
UNIQUE KEY(order_id)
DISTRIBUTED BY HASH(order_id)
PROPERTIES (
"function_column.sequence_col" = "update_time" -- 指定 update_time 为 Sequence 列
);
-- 1. 写入 "已发货" 记录 (update_time 较大)
-- {"order_id": 1001, "status_name": "Shipped", "update_time": "2023-10-26 12:00:00"}
-- 2. 写入 "已支付" 记录 (update_time 较小,后到达)
-- {"order_id": 1001, "status_name": "Paid", "update_time": "2023-10-26 11:00:00"}
-- 最终查询结果,保留了 update_time 最大的记录
-- order_id: 1001, status_name: "Shipped", update_time: "2023-10-26 12:00:00"2.3. 删除机制 DORIS_DELETE_SIGN
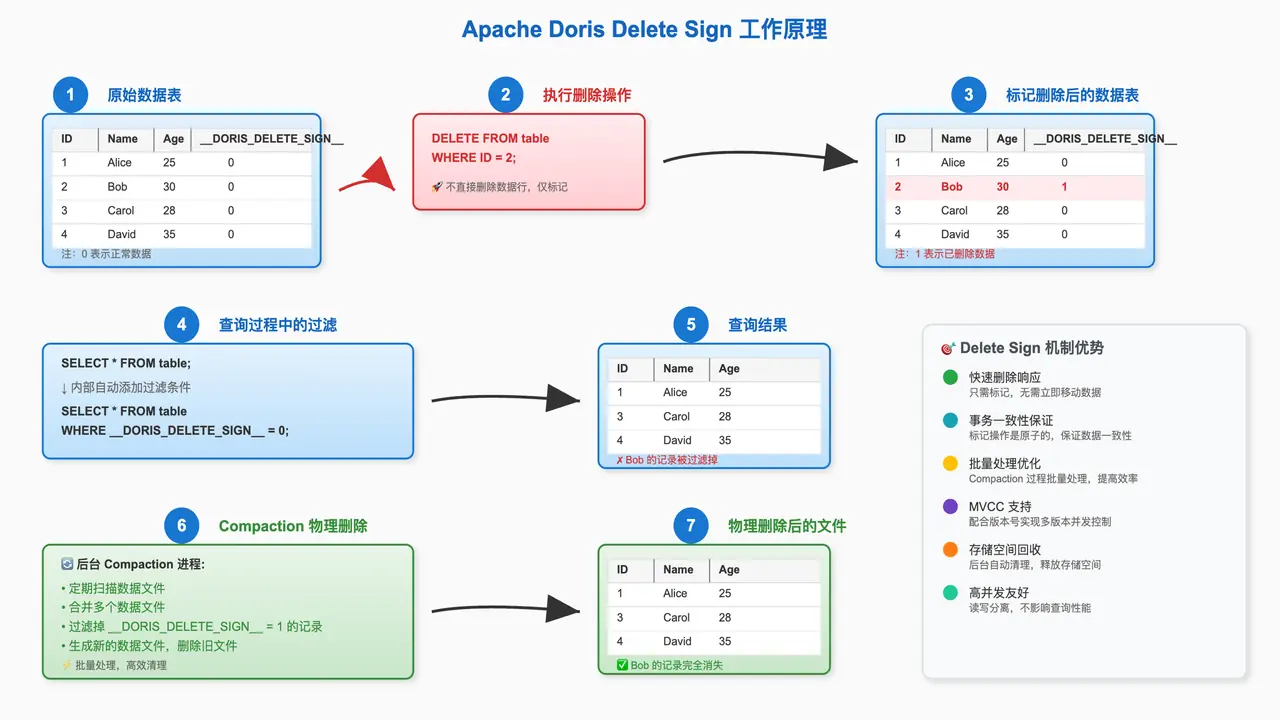
DORIS_DELETE_SIGN 的工作原理可以概括为"逻辑标记,后台清理"。
- 执行删除 :当用户通过导入或
DELETE语句删除数据时,Doris 不会立即从物理文件中移除数据。相反,它会为要删除的主键写入一条新记录,该记录的DORIS_DELETE_SIGN列被标记为1。 - 查询过滤 :当用户查询数据时,Doris 会在查询计划中自动添加一个过滤条件
WHERE DORIS_DELETE_SIGN = 0,从而在查询结果中隐藏所有被标记为删除的数据。 - 后台 Compaction:Doris 的后台 Compaction 进程会定期扫描数据。当它发现一个主键同时存在正常记录和删除标记记录时,它会在合并过程中将这两条记录都物理地移除,最终释放存储空间。
这种机制确保了删除操作的快速响应,同时通过后台任务异步完成物理清理,避免了对在线业务的性能冲击。
下图展示了DORIS_DELETE_SIGN 的工作原理:
2.4 部分列更新(Partial Column Update)
从 2.0 版本开始,Doris 在主键模型(MoW)上支持了强大的部分列更新能力。用户在导入数据时,只需提供主键和待更新的列,未提供的列将保持其原值不变。这极大地简化了宽表拼接、实时标签更新等场景的 ETL 流程。
要启用此功能,需在创建主键模型表时,开启 Merge-on-Write (MoW) 模式,并设置 enable_unique_key_partial_update 属性为 true。或者在数据导入时配置"partial_columns"参数
Plain
CREATE TABLE user_profiles (
user_id BIGINT,
name STRING,
age INT,
last_login DATETIME
)
UNIQUE KEY(user_id)
DISTRIBUTED BY HASH(user_id)
PROPERTIES (
"enable_unique_key_partial_update" = "true"
);
-- 初始数据
-- user_id: 1, name: 'Alice', age: 30, last_login: '2023-10-01 10:00:00'
-- 通过 Stream Load 导入部分更新数据,只更新 age 和 last_login
-- {"user_id": 1, "age": 31, "last_login": "2023-10-26 18:00:00"}
-- 更新后数据
-- user_id: 1, name: 'Alice', age: 31, last_login: '2023-10-26 18:00:00'部分列更新原理概要
不同于传统的 OLTP 数据库,Doris 的部分列更新并非是原地的数据更新,为了让 Doris 有更好的写入吞吐以及查询性能,主键模型的部分列更新采取了"导入时将缺失字段补齐后再整行写入"的实现方案。如下图所示:
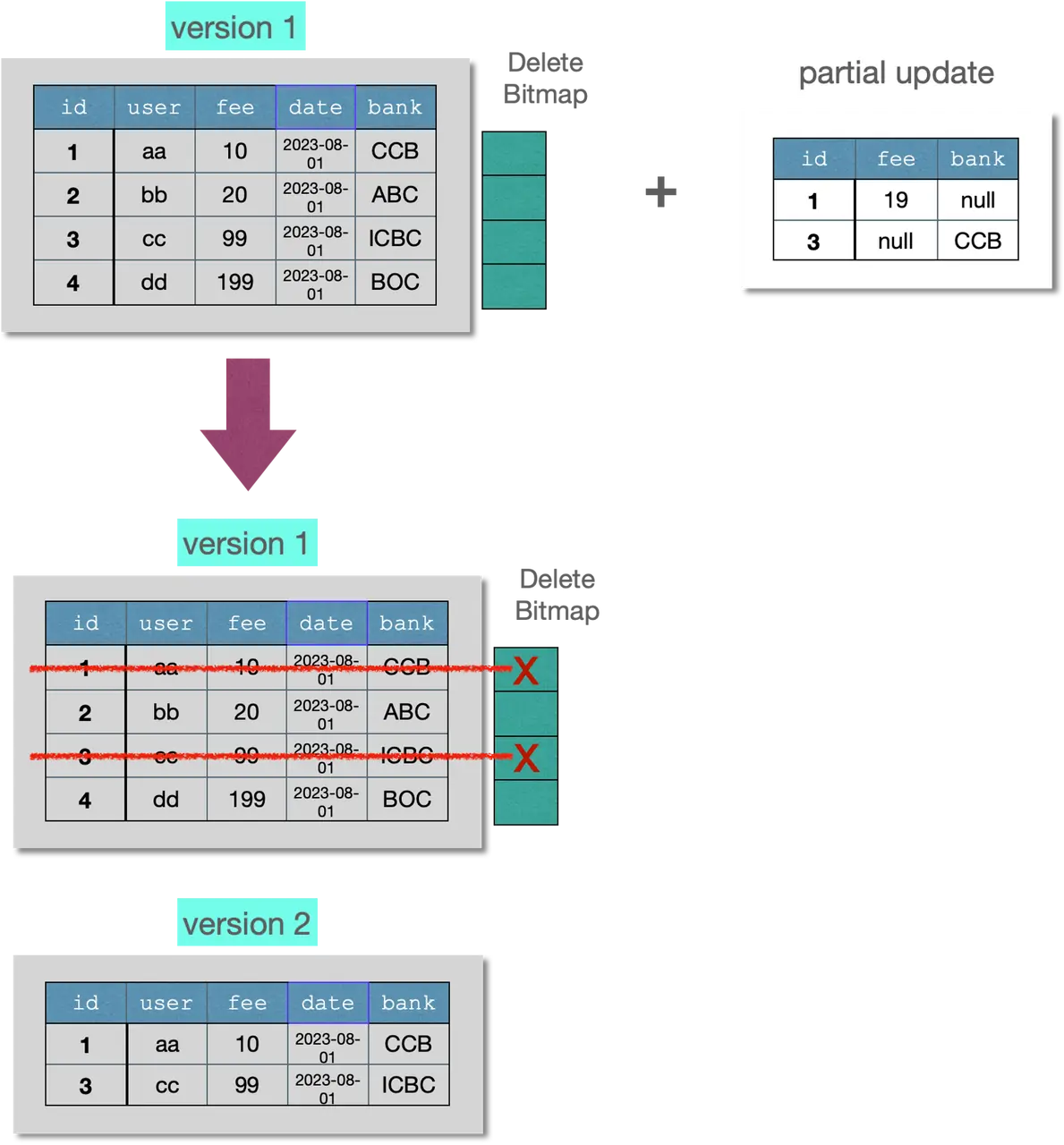
因此使用 Doris 的部分列更新存在"读放大 "和"写放大"的影响。例如给一个 100 列的宽表更新 10 个字段,Doris 在写入过程中需要补齐缺失的 90 个字段,假设每个字段的大小接近,则 1MB 的 10 字段更新,会在 Doris 系统中产生大约 9MB 的数据读取(补齐缺失的字段),以及 10MB 的数据写入(补齐整行后写入到新的文件),也就是有大约 9 倍的读放大和 10 倍的写放大。
部分列更新性能建议
由于部分列更新存在读放大和写放大,同时 Doris 还是列存系统,在数据读取的过程中可能会产生大量随机 IO,因此对硬盘的随机读 IOPS 有较高的要求。由于传统的机械磁盘在随机 IO 上存在显著瓶颈,因此如果要使用部分列更新功能进行高频的写入,建议使用 SSD 硬盘,最好是 nvme 接口,能够提供最好的随机 IO 支撑。
同时,如果表很宽,也建议开启行存来减少随机 IO。开启行存后,Doris 会在列存之外额外的存储一份行存数据,由于行存数据每一行都是连续存储的,因此可以一次 IO 就读取到整行数据(列存则需要 N 次 IO 才能读取到所有缺失的字段,例如前面的 100 列宽表更新 10 列的例子,每一行需要 90 次 IO 才能读取到所有的字段)
3. 典型应用场景
Doris 强大的数据更新能力使其能够胜任多种要求严苛的实时分析场景。
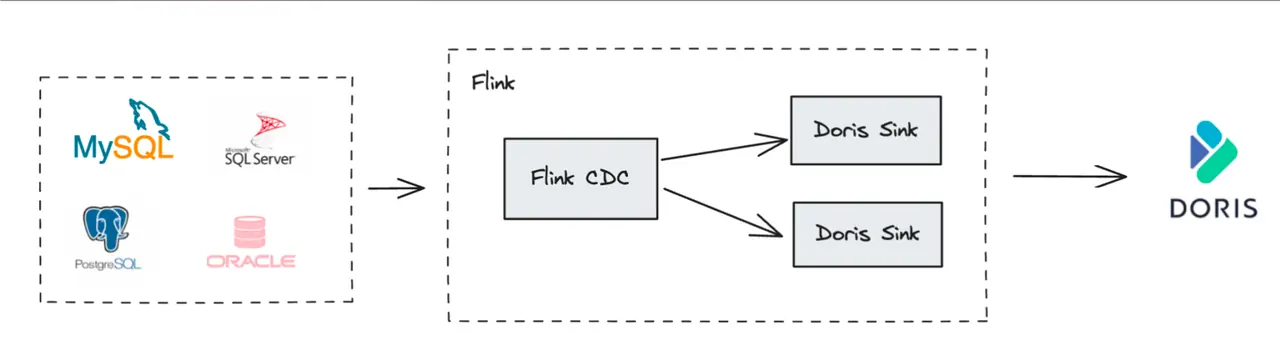
3.1. CDC 数据实时同步
通过 Flink CDC 等工具捕获上游业务数据库(如 MySQL, PostgreSQL, Oracle)的变更数据(Binlog),并实时写入 Doris 的主键模型表,是构建实时数仓最经典的场景。
- 整库同步:Flink Doris Connector 内部集成了 Flink CDC,可以实现从上游数据库到 Doris 的自动化、端到端的整库同步,无需手动建表和配置字段映射。
- 保证一致性 :利用主键模型的
UPSERT能力处理上游的INSERT和UPDATE操作,利用DORIS_DELETE_SIGN处理DELETE操作,并结合 Sequence 列(如 Binlog 中的时间戳)处理乱序数据,完美复刻上游数据库的状态,实现毫秒级延迟的数据同步。
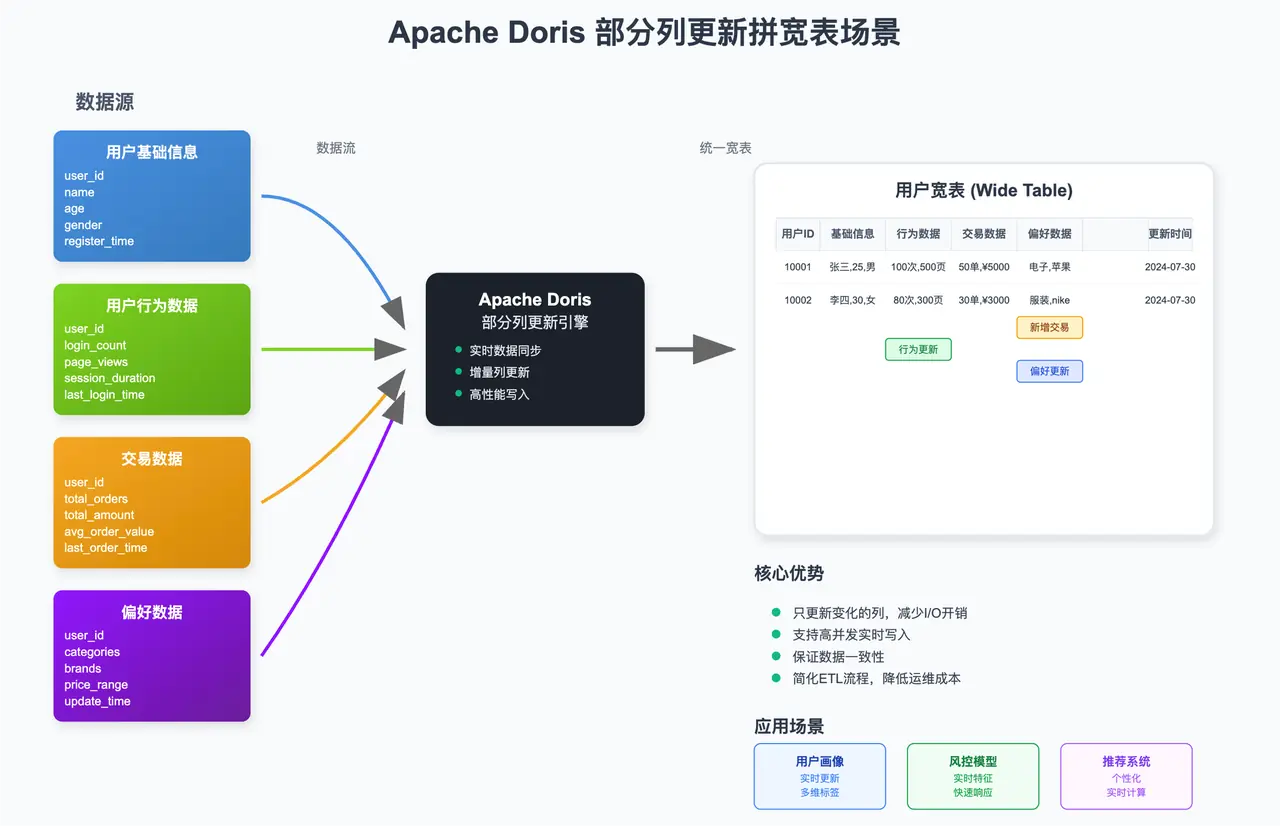
3.2. 实时宽表拼接
在很多分析场景中,需要将来自不同业务系统的数据拼接成一张用户宽表或商品宽表。传统的方式是使用离线的 ETL 任务(如 Spark 或 Hive)定期(T+1)进行拼接,实时性差,且维护成本高。或者使用 Flink 进行实时的宽表 join 计算,将拼接后的数据写入数据库,这通常需要消耗大量的计算资源。
利用 Doris 的部分列更新能力,可以极大地简化这一流程:
- 在 Doris 中创建一张主键模型的宽表。
- 将来自不同数据源(如用户基础信息、用户行为数据、交易数据等)的数据流通过 Stream Load 或 Routine Load 实时写入这张宽表。
- 每个数据流只负责更新自己相关的字段。例如,用户行为数据流只更新
page_view_count,last_login_time等字段;交易数据流只更新total_orders,total_amount等字段。
这种方式不仅将宽表的构建从离线 ETL 转变为实时流式处理,大大提升了数据新鲜度,还因为只写入变化的列而减少了 I/O 开销,提升了写入性能。
4. 最佳实践
遵循以下最佳实践,可以帮助您更稳定、更高效地使用 Doris 的数据更新功能。
4.1. 通用性能实践
- 优先使用导入更新 :对于高频、大量的更新操作,应优先选择 Stream Load, Routine Load 等导入方式,而非
UPDATEDML 语句。 - 攒批写入 :避免使用
INSERT INTO语句进行逐条的高频写入(如 > 100 TPS),因为每条INSERT都会产生一次事务开销。如果必须使用,应考虑开启 Group Commit 功能,将多个小批量提交合并成一个大事务。 - 谨慎使用高频 DELETE :在明细模型和聚合模型上,避免高频的
DELETE操作,以防查询性能下降。 - 删除分区数据时使用 TRUNCATE PARTITION :如果需要删除整个分区的数据,应使用
TRUNCATE PARTITION,其效率远高于DELETE。 - 串行执行 UPDATE :避免并发执行可能作用于相同数据行的
UPDATE任务。
4.2. 存算分离架构下的主键模型实践
Doris 3.0 引入了先进的存算分离架构,带来了极致的弹性和更低的成本。在该架构下,由于 BE 无状态,因此在 Merge-on-Write 过程中,需要通过 MetaService 来维护一个全局状态以解决导入/compaction/schema change 之间的写写冲突。主键模型的 MoW 实现依赖于一个基于 Meta Service 的分布式表锁来保证写操作的一致性,如下图所示:
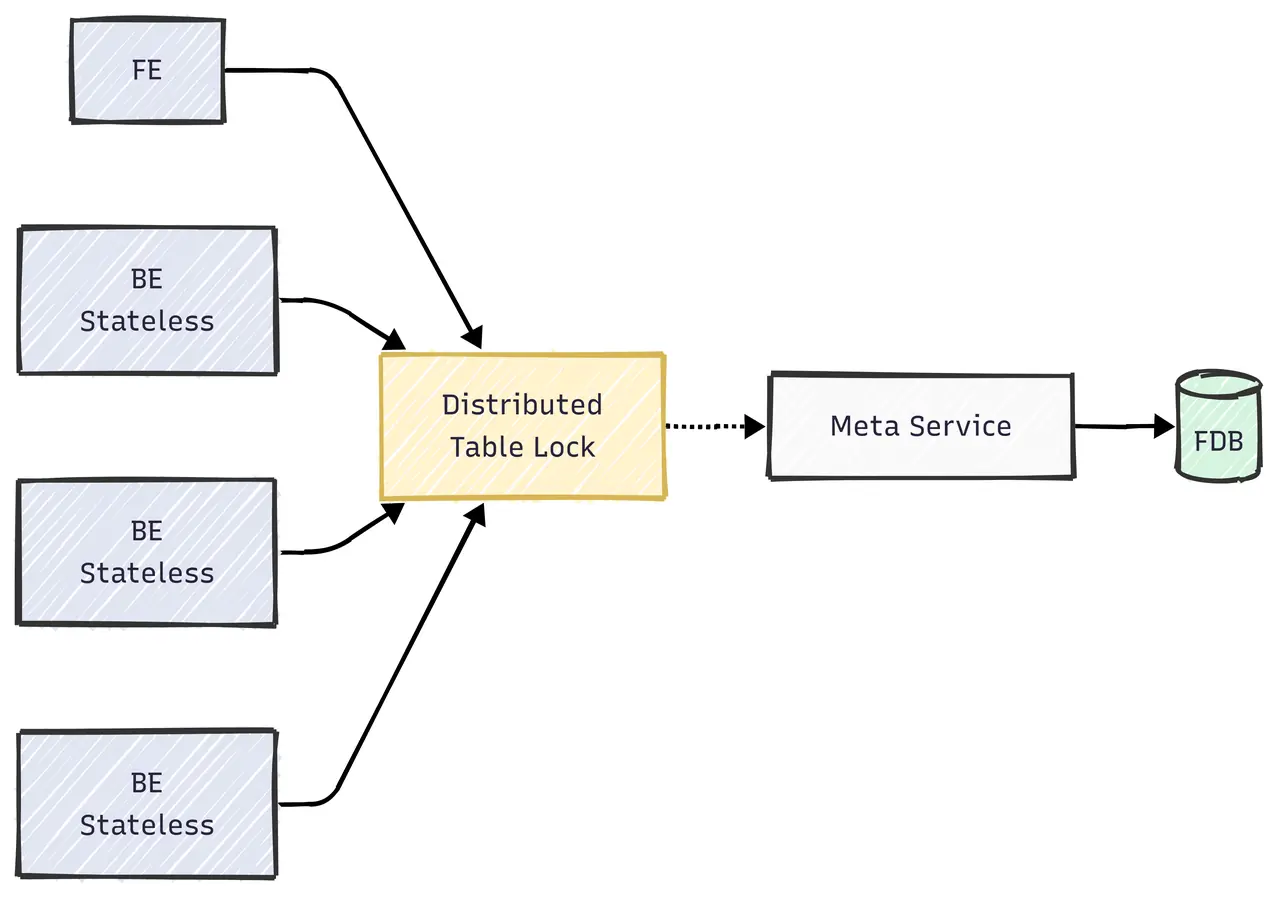
高频的导入和 Compaction 会导致对表锁的频繁竞争,因此需要特别注意以下几点:
- 控制单表导入频率 :建议将单张主键表的导入频率控制在 60 次/秒 以内。可以通过攒批、调整导入并发等方式来降低频率。
- 合理设计分区分桶 :
- 分区:利用时间分区(如按天或按小时)可以确保单次导入只更新少量分区,减少锁竞争的范围。
- 分桶:分桶数(Tablet 数量)应根据数据量合理设置,通常在 8-64 之间。过多的 Tablet 会加剧锁竞争。
- 调整 Compaction 策略:在写入压力非常大的场景下,可以适当调整 Compaction 策略,降低 Compaction 的频率,从而减少其与导入任务之间的锁冲突。
- 升级到最新稳定版本 :Doris 社区正在持续优化存算分离架构下的主键模型性能。例如,即将发布的 3.1 版本对分布式表锁的实现进行了大幅优化。始终建议使用最新的稳定版本以获得最佳性能。
结论
Apache Doris 凭借其以主键模型为核心的强大、灵活且高效的数据更新能力,真正打破了传统 OLAP 系统在数据新鲜度上的瓶颈。无论是通过高性能的导入实现 UPSERT 和部分列更新,还是利用 Sequence 列保证乱序数据的一致性,Doris 都为构建端到端的实时分析应用提供了完整的解决方案。
通过深入理解其核心原理,掌握不同更新方式的适用场景,并遵循本文档提供的最佳实践,您将能够充分释放 Doris 的潜力,让实时数据真正成为驱动业务增长的强大引擎。