本文入选顶会NeurIPS 2025
大型语言模型的能力很大程度上取决于各个领域的训练数据。优化特定领域数据的混合比例可以建模为双层优化问题。本文将该双层优化问题简化为单层惩罚形式,并使用一组孪生模型进行求解:一个使用原始数据训练的代理模型和一个使用额外数据训练的动态更新的参考模型。本文提出的方法,基于孪生模型的双层数据混合比例优化 (TANDEM),通过孪生模型的差异来衡量数据有效性:能从额外数据中获益更多的领域其权重应该被上调。与先前的方法相比,TANDEM 提供了理论保证和更广泛的适用性。此外,本文的双层视角为模型训练数据配比调整提供了新的场景,如数据受限场景和监督微调。在这些场景中,优化数据混合比可以显著提高性能。大量实验验证了 TANDEM 在所有场景下的有效性。论文链接:neurips.cc/virtual/202...** ****背景
-
大模型的能力极大地依赖于不同来源数据/任务的组合配置:
SlimPajama The Pile Natural Instruction 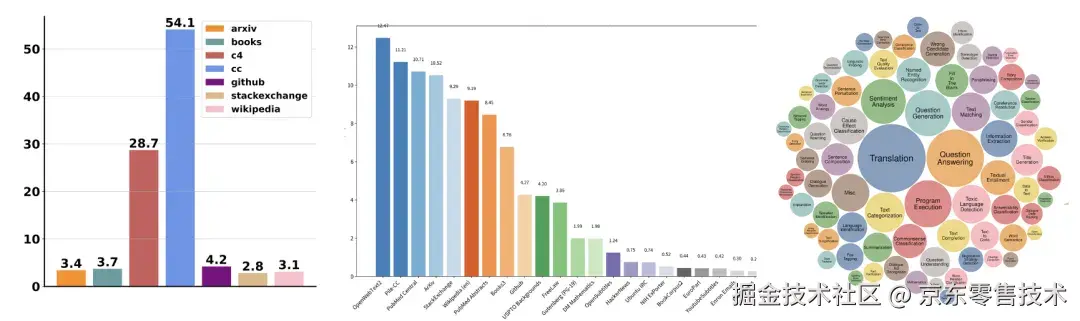
-
- 传统方法依赖人工经验和试错来确定最优的数据混合比例(如Llama),成本高、耗时长且容易陷入次优。自动化确定最优数据配置的方法研究仍非常欠缺。
- 优化不同任务/来源样本分配,根据不同来源数据的学习难度、收敛状态以及对整体泛化能力的贡献,自动化组织训练数据,最大化模型的综合能力。
02 方法
2.1 基于双层优化的数据配比方法
优化目标:找到一组数据配比α,使得使用该配比构造的数据上训练的模型在验证集上表现最好。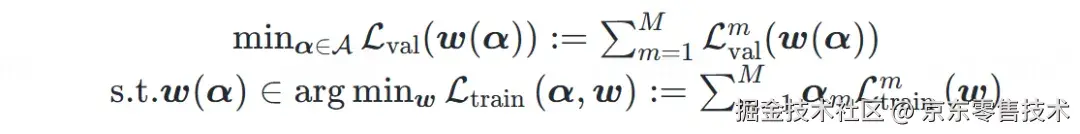
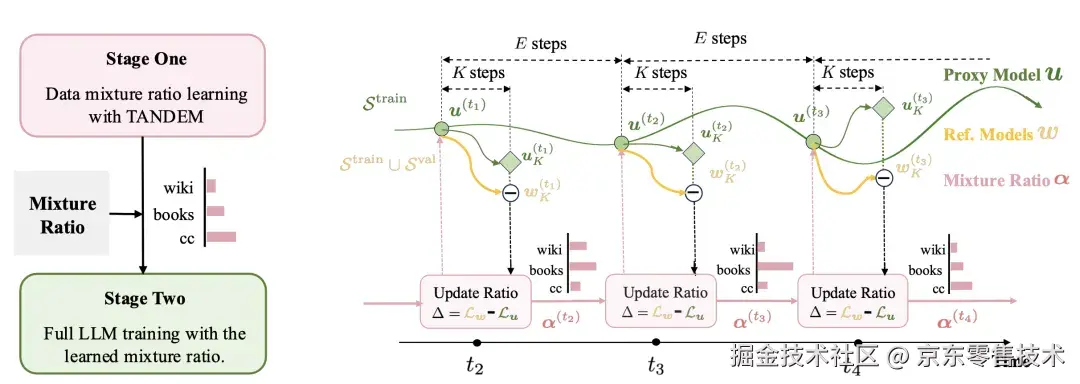
2.2 使用孪生网络求解双层优化
 引入代理模型u,通过拉格朗日乘子法将双层优化问题转化为单层优化:
引入代理模型u,通过拉格朗日乘子法将双层优化问题转化为单层优化: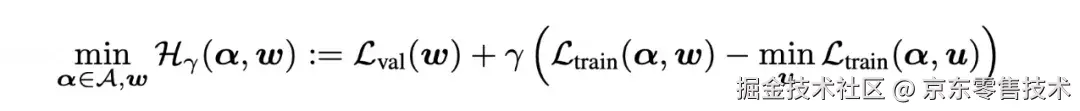 求解该问题对应于以下混合比例更新逻辑:
求解该问题对应于以下混合比例更新逻辑:
- 在当前数据配比α下,在训练集上训练代理模型u K步。
- 在同样的数据配比下,在训练集和验证集上训练参考模型w K步。
- 用二者在每个领域数据上的损失差来更新数据混合比例:该损失差代表了增加额外验证数据能够带来的额外收益。损失差大的领域说明增加额外数据带来的收益大,其配比应该增加,反之则应该减少。
 训练过程包含同源的代理模型u和参考模型w的交互,因此本方法被命名为TANDEM(双人自行车)。数据混合比例学习完成后,根据学到的比例重新构造训练数据,并训练模型。
训练过程包含同源的代理模型u和参考模型w的交互,因此本方法被命名为TANDEM(双人自行车)。数据混合比例学习完成后,根据学到的比例重新构造训练数据,并训练模型。
2.3 理论保障: 收敛性分析

2.4 与已有数据配比方法对比
从α更新角度看,Tandem统一了此前的数据配比方法如DoReMi1和DoGE2。DoReMi对应于静态参考模型的TANDEM,而DoGE对应于K=1步训练的TANDEM。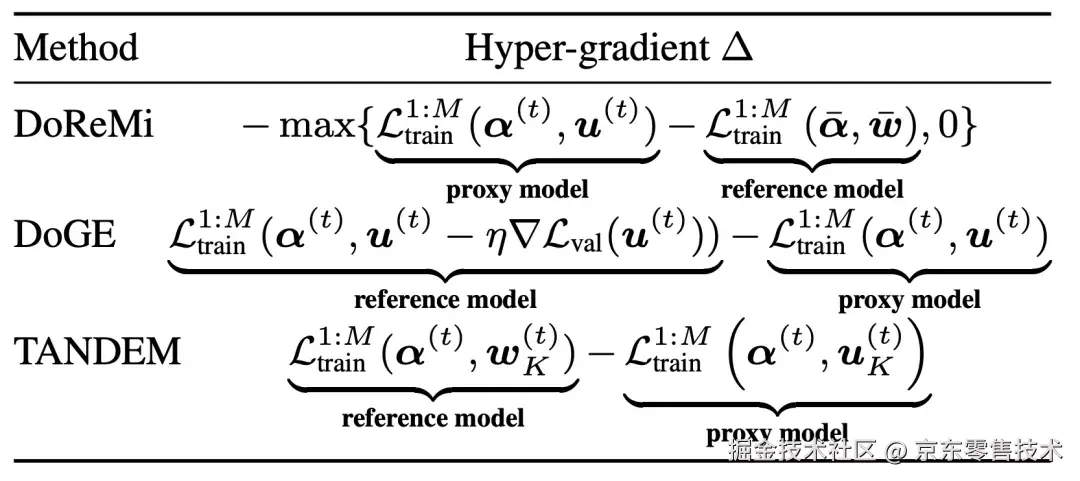 表1:Tandem统一了此前的数据配比方法如DoReMi和DoGE
表1:Tandem统一了此前的数据配比方法如DoReMi和DoGE
2.5 更多讨论--什么情况下数据配比调整更有效果?
可以证明,在(各领域)数据量均衡且充足的情况下,平均采样就是最优数据配比。在本身数据不均衡,以及涉及多轮训练的情况下进行数据配比调整会有更加显著的效果。03 ****效果
3.1 通用任务上的实验效果
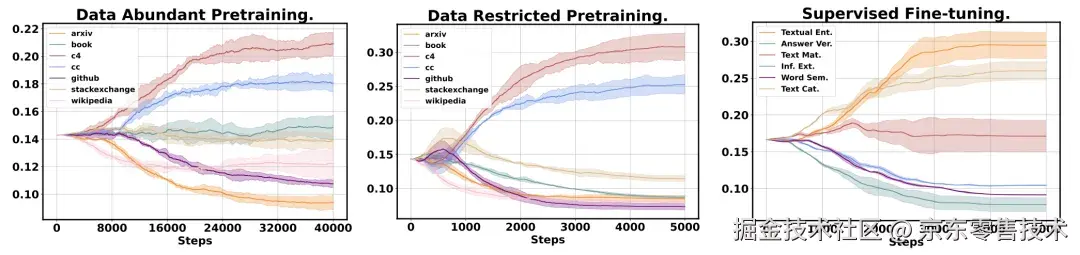
图1:在预训练以及监督微调场景下的数据混合比例优化过程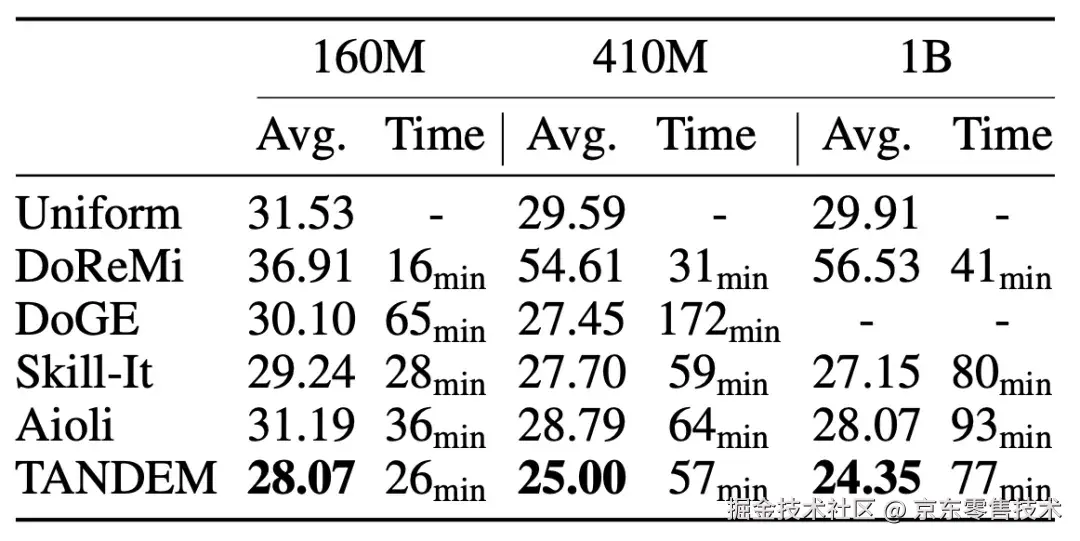 表1:预训练场景下不同模型规模下数据混合比例选择方法效果对比
表1:预训练场景下不同模型规模下数据混合比例选择方法效果对比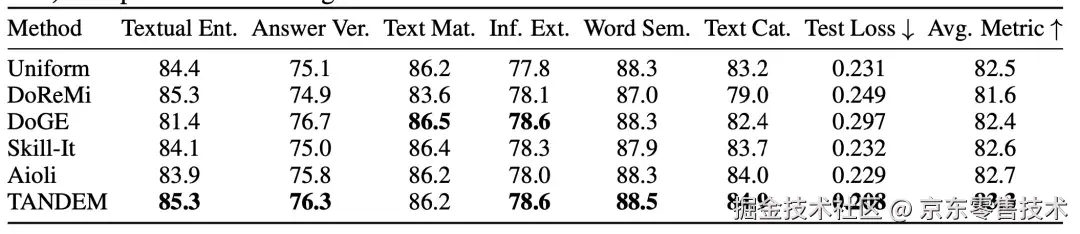 表2:监督微调场景下数据混合比例选择方法效果对比。(6大类99种不同任务)
表2:监督微调场景下数据混合比例选择方法效果对比。(6大类99种不同任务)
3.2 京东商品理解任务的实验效果:
电商平台涵盖海量商品理解任务,如判别(同品识别)、抽取(产品词识别,属性识别,品牌,型号识别)等。构建统一的商品理解模型是降低维护成本强化模型泛化能力的有效方案。TANDEM方法应用于京东商品理解模型训练,取得了超过默认数据配比的效果。
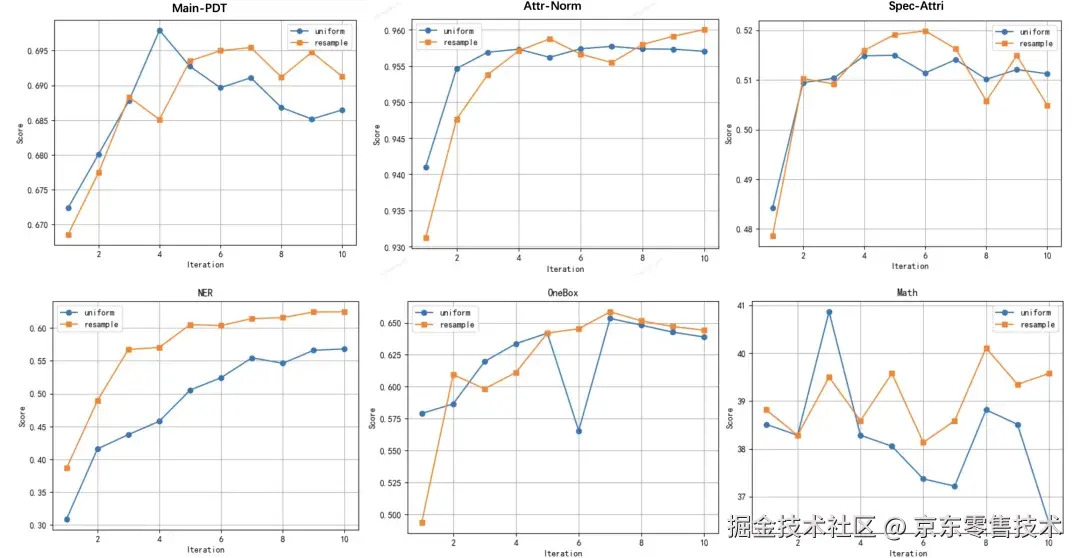
图2:在主产品识别、属性归一化、规格属性抽取、命名实体识别、同品识别和数学六个任务上与默认数据配比的效果对比。
参考文献:
1 SM. Xie et.al. DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining. NeurIPS 2023.
2 S. Fan et.al. DoGE: Domain Reweighting with Generalization Estimation. ICML 2024.
3 J. Wang et.al. TANDEM: Bi-level Data Mixture Optimization with Twin Networks. NeurIPS 2025.