1. LLVM 的定位:现代编译器的"操作系统"
LLVM 不只是一个编译器后端,而是一套 模块化、可组合、可复用的编译基础设施平台。其定位类似"编译器界的操作系统":
-
多语言共享的 IR 目标平台(Clang、Rust、Swift、Zig、Julia 等)
-
统一的优化架构(Pass Pipeline)
-
多架构机器码生成器(x86 / ARM / RISC-V / WebAssembly)
-
JIT、静态编译、LTO、工具链等能力的融合中心
示意图:
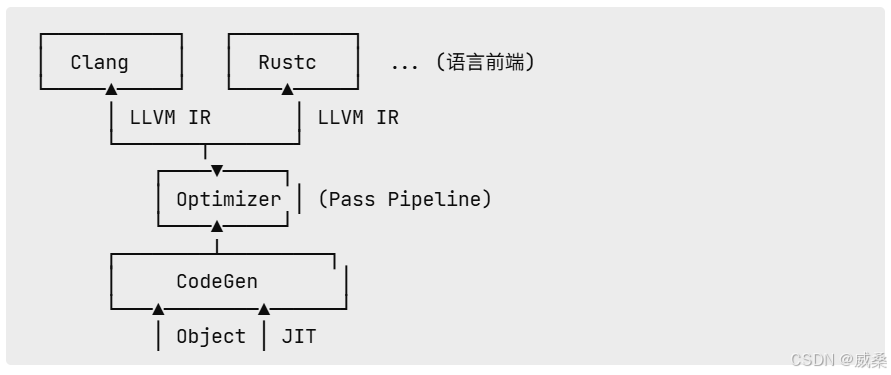
2. LLVM 的核心组件
2.1 LLVM IR(中间表示)
LLVM 的心脏,统一所有语言到优化层的"共同语言"。
2.2 Pass Optimization Framework
一系列可组合的优化 Pass,用于 IR 的 SSA 变换、死代码删除、循环优化等。
2.3 CodeGen(后端)
将 IR 转化为目标架构机器码,包括:
-
指令选择(Instruction Selection)
-
寄存器分配(Register Allocation)
-
指令调度(Scheduling)
2.4 JIT / ORC
用于动态执行 IR 的高性能 JIT 机制。
2.5 相关工具链
-
LLD(高速链接器)
-
clang-tidy / clang-format(工具集)
-
Sanitizers(运行期检测)
示意图:
3. LLVM IR:设计理念与结构细节
3.1 设计目标
-
与语言无关:能表达 C、C++、Rust、Swift 等各种语言特性
-
与架构无关:在 IR 层进行通用优化
-
面向优化:SSA(Static Single Assignment)形式
3.2 三层 IR

3.3 SSA 特性图示

使优化器可以精确追踪数据流。
3.4 IR 的可视化示例

IR 易读、可序列化、可打印,非常方便工具生态构建。
4. Pass Manager 与优化流水线
LLVM 的优化机制由 一系列 Pass(变换/分析组件) 组成。
4.1 Pass 分类
-
分析 Pass:提供信息(如循环结构、别名分析)
-
变换 Pass:修改 IR(如 DCE、GVN、InstCombine)
-
Loop/Function/Module Pass:不同粒度的优化作用范围
4.2 优化流水线示意图
IR → Simplify → InstCombine → GVN → LICM → Loop Unroll → SROA → Optimized IR
4.3 Pass 管线的演化
传统 PassManager → 新 PM(更快、并行度更高)
5. LLVM 后端(CodeGen)的完整流程
5.1 核心阶段
-
SelectionDAG:根据 IR 选择合适的机器指令
-
Register Allocation:将虚拟寄存器映射到真实寄存器
-
Instruction Scheduling:根据 CPU pipeline 重新排序指令
-
Emit Machine Code:生成真正的机器码或汇编
5.2 指令选择示意图

5.3 架构抽象层(Target)
每个架构都提供:
-
指令定义
-
寄存器模型
-
调度模型
6. JIT(MCJIT / ORC JIT)、运行时与工具集
6.1 MCJIT → ORC 的演进
ORC 采用更模块化的图式 JIT Pipeline。
示意图:
IR → ORC Layer → Obj Layer → Execution Session → CPU
6.2 使用场景
-
游戏脚本系统
-
数据库表达式 JIT 优化(SQLite/ClickHouse)
-
AI 编译器(XLA/TVM 的底层)
6.3 Sanitizers / PGO / LTO
LLVM 工具链已成为现代工程最佳实践的基础。
7. LLVM 如何支持多语言生态
LLVM 成为语言基础设施的原因:
-
IR 足够表达丰富语义
-
优化强大且通用
-
后端覆盖架构丰富
-
JIT/静态链接可自由组合
示例:

8. 与 GCC 的结构差异与现代化优势
8.1 架构对比
| 项目 | GCC | LLVM |
|---|---|---|
| 架构 | 单体式 | 模块化/可组合 |
| IR | GIMPLE/RTL | 单一 SSA IR |
| 工具生态 | 弱耦合 | 强生态(IDE/JIT/分析) |
| 可扩展性 | 较弱 | 极强 |
8.2 LLVM 的现代化优势
-
IR 更统一、易组合、利于构建工具链
-
更容易做 JIT、交叉编译、插件化
-
更适合构建新语言
9. LLVM 的未来方向
9.1 MLIR(多层 IR 架构)
未来语言基础设施的扩展层,使 LLVM 从"通用后端"升级为"多级编译平台"。
MLIR 解决:
-
深度学习编译优化
-
多领域 DSL
-
更大规模的中间表示表达能力
示意图:
高层 DSL → MLIR → LLVM IR → CodeGen
9.2 更高效的 Pass Pipeline
并行 Pass、更多缓存机制、统一分析复用。
9.3 更灵活的后端(如可插拔 RISC-V 扩展)
LLVM 正朝着 更加可定制、可扩展、可共享的通用编译基础设施 方向发展。