问题背景:
最近遇到了生产故障,原因是rabbit的主机被修改,重启后导致rabbitmq的数据丢失,为此整理了RabbitMQ 数据恢复指南,专为应对因主机名变更、节点身份丢失、误删数据或配置错误 等导致 RabbitMQ 无法识别原有数据的场景而设计。重点保障队列消息、用户、权限、策略、交换机等核心数据可恢复。
方式1:
通过数据备份文件恢复:
实现方式:
做任何变更前,对rabbitmq集群提前进行备份。然后如果集群发生数据重构,可以及时恢复之前的数据。
备份步骤:
1、打开rabbitmq的overview界面,选择Export definitions 下载此时的数据。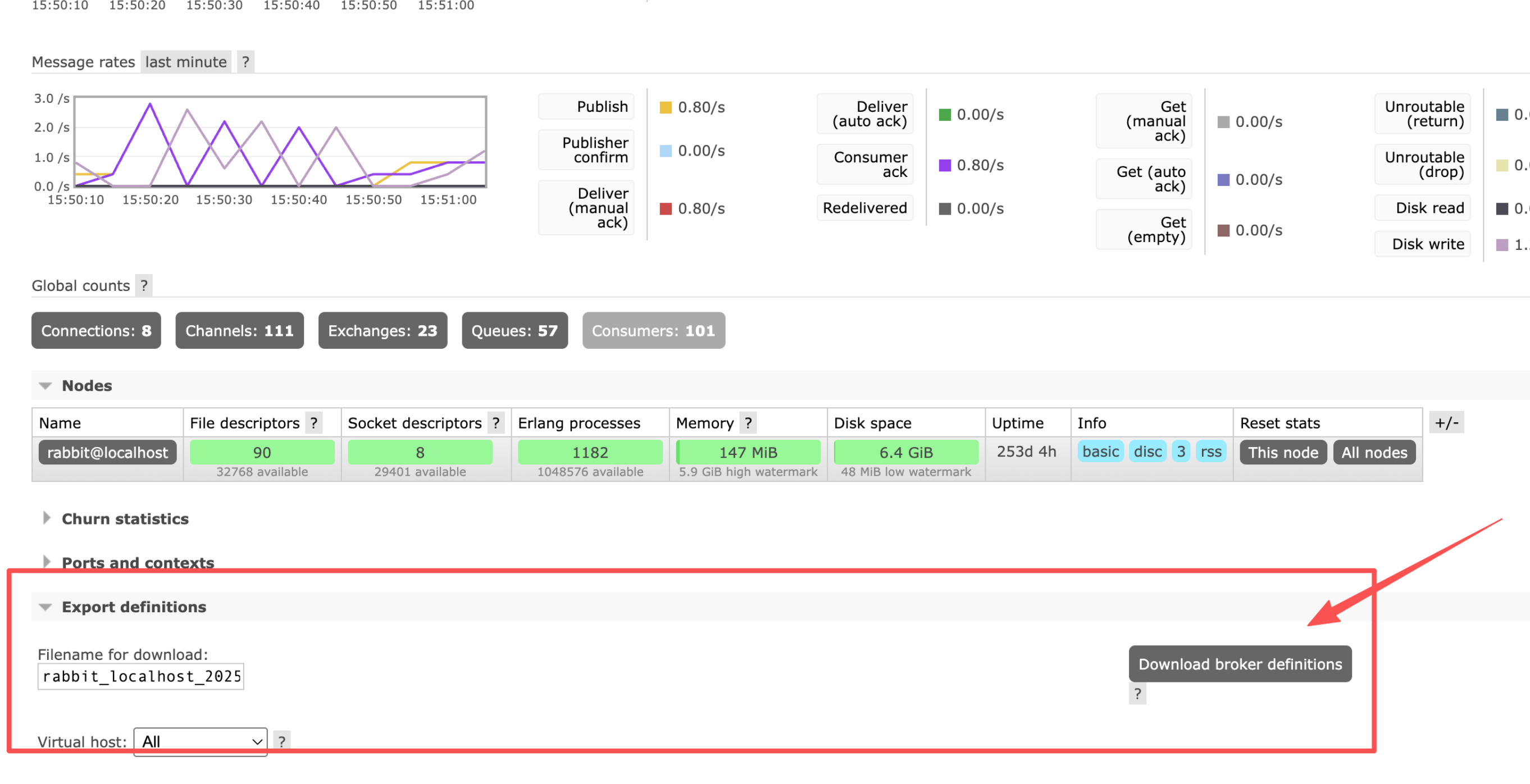
从页面上可以看到集群当前的交换机数量是:23 队列: 57 等数据。
2、rabbit_localhost_2025-12-4.json文件是包含队列交换机、虚拟机、队列的备份数据。
恢复步骤:
1、模拟主机修改故障发生,主机名发生修改。
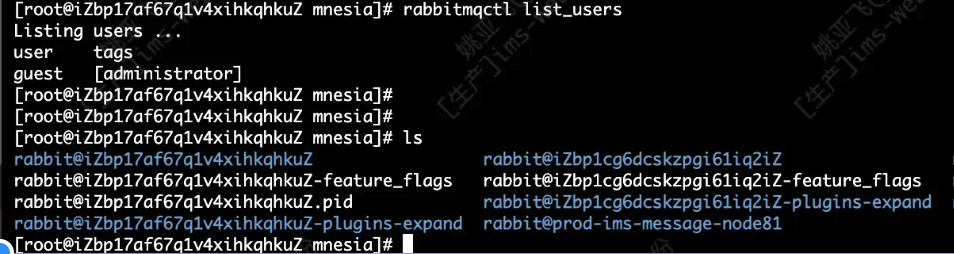
从图片上我们可以看到服务器的主机名发生了修改。存储目录发生了改变,rabbitmq用户不存在。
2、此时我们需要新建用户导入之前已经备份的数据,进行恢复。
bash
#添加用户
rabbitmqctl add_user repairuser QWEs1seSDv35bdl
# 设置为管理员(可选)
rabbitmqctl set_user_tags repairuser administrator
# 授权访问默认 vhost "/"
rabbitmqctl set_permissions -p / repairuser ".*" ".*" ".*"3、登录到web页面,此时无任何队列。无业务的交换机,和虚拟机。
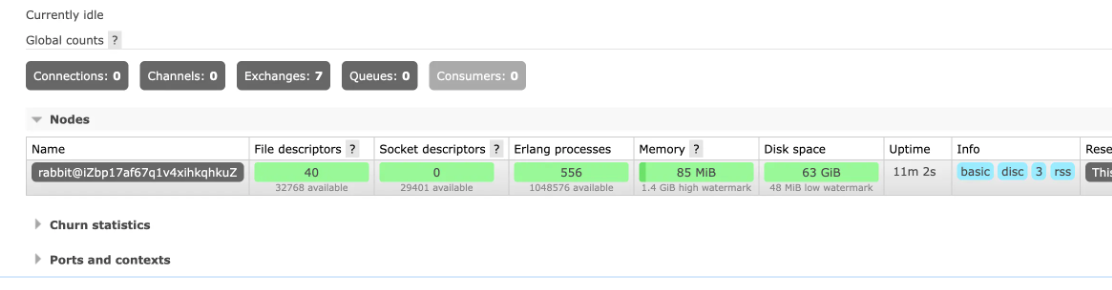
4、手动导入我们之前备份的数据,进行恢复。
Overview - import definitions -选择文件进行导入
出现以下标识代表成功,然后进行数据验证。
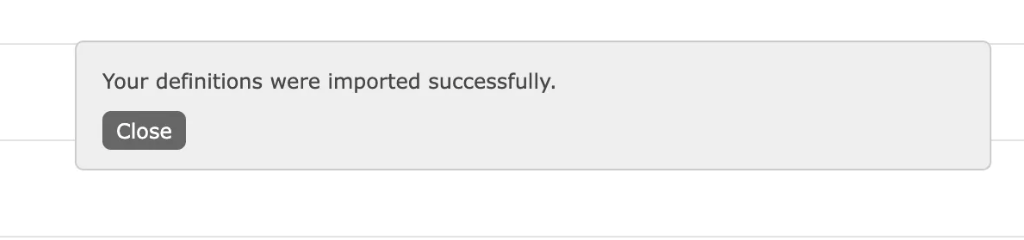
5、数据验证,验证账号密码
#查看用户
rabbitmqctl list_users
#查看交换机
rabbitmqctl list_exchanges
#查看虚拟机
rabbitmqctl list_vhosts
#查看权限
rabbitmqctl list_permissions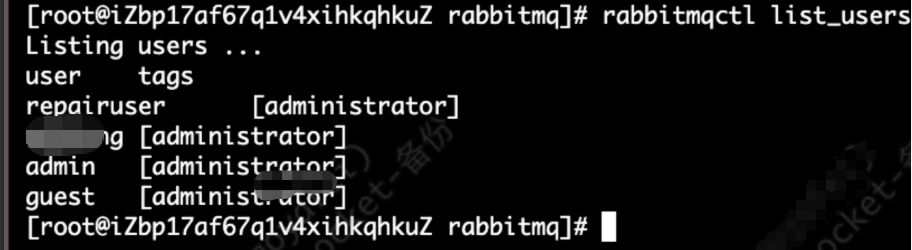
方式2:
通过修改旧的主机名进行数据恢复:
此方式建立在无备份数据的情况进行数据恢复,达到数据数据一致。
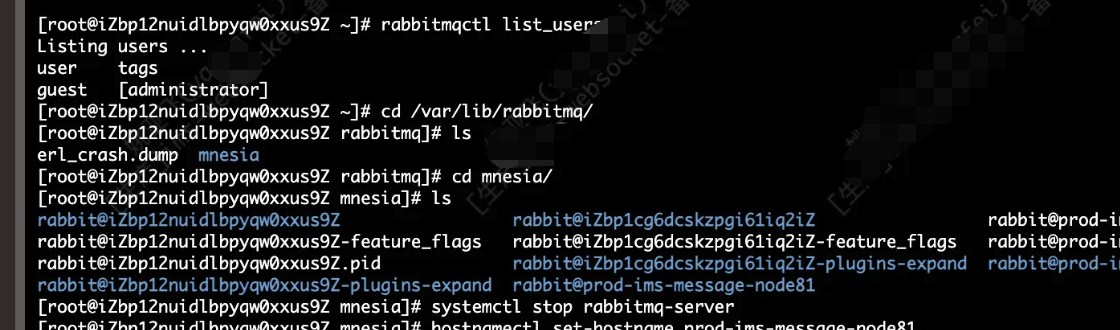
步骤 1:停止 RabbitMQ
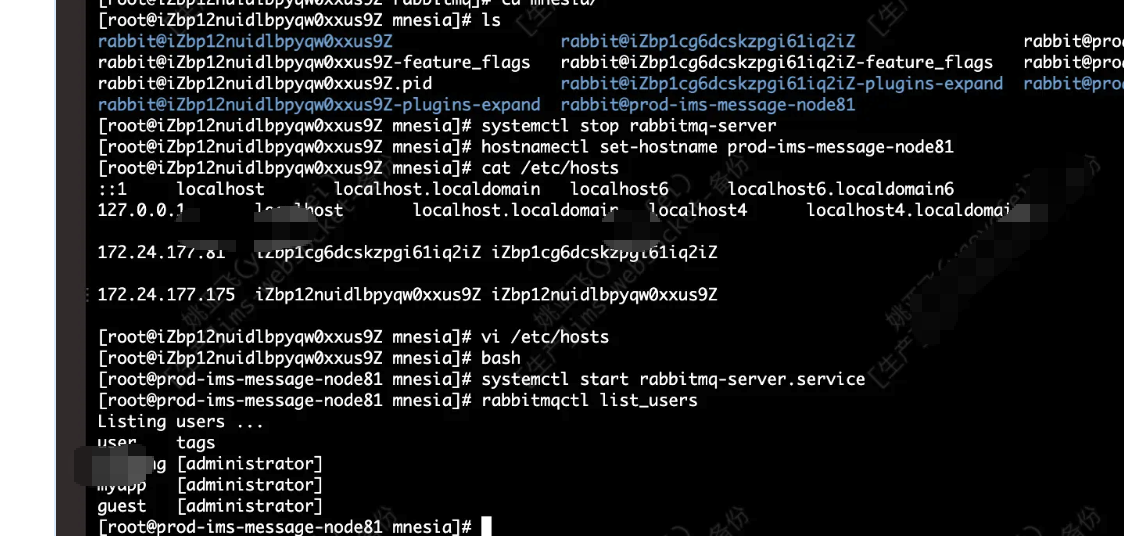
systemctl stop rabbitmq-server步骤 2:恢复原始主机名(最佳方案)
#改回原主机名(原名为 prod-ims-message-node81)
hostnamectl set-hostname prod-ims-message-node81
echo "127.0.0.1 prod-ims-message-node81" >> /etc/hosts✅ 这是最安全的方式,让 RabbitMQ 认出自己。
方式3:
通过增加配置参数进行恢复:
存储目录无需变更,我们只需要在/etc/rabbitmq/目录编辑rabbitmq-env.conf文件,增加我们之前的旧主机名即可
1、编辑rabbitmq-env.conf,如果没有需要新建这个文件,prod-ims-message-node81是旧的主机名
bash
NODENAME=rabbit@prod-ims-message-node812、增加hosts文件的解析,不然启动也会报错主机名无法解析。
bash
echo "127.0.0.1 prod-ims-message-node81" >> /etc/hosts
3、重启rabbitmq
bash
systemctl restart rabbitmq-server.service如果没有其他问题,启动是正常的
4、检查数据并验证账号密码队列等