apt install nvidia-cuda-toolkit一、前文
之前用过qwen3.0 转rkllm,部署rk3588上面,这次就来记录下,如何转换吧。
由于qwen3.0 需要python 3.9以上,所以之前的提供的 rknn-toolkit2-v2.3.0-cp38-docker.tar.gz 不能用,那么我们直接在ubuntu上面进行使用把。要不就自己慢慢搭建环境。
首先可以看看在windows上面搭建ubuntu的教程:方案二:ubuntu安装【docker】
在上面安装conda环境,这个网上一大堆很容易。
# 下载最新版Miniconda(Python 3)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
# 按照提示操作,包括阅读许可协议、确认安装位置等。
# 通常情况下,默认选项即可,但需要同意许可协议并选择是否初始化Miniconda3。
#执行完后生效配置
source ~/.bashrc二、rkllm工具环境
2.1 下载Rkllm-toolkit工具
通过git拉去环境(最好拉去最新的,之前有些模型可能不支持)
git clone https://github.com/airockchip/rknn-llm.git如果访问不了git,询问我直接提供。
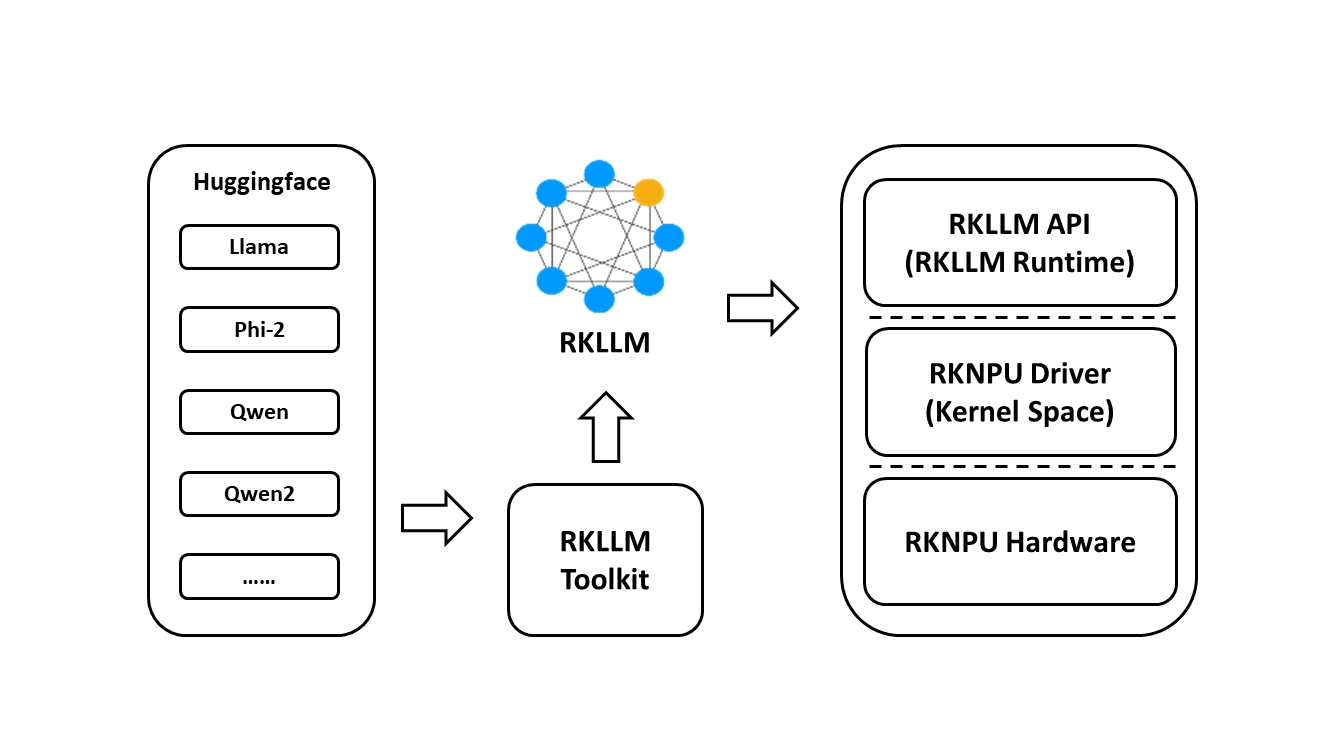
rkllm-toolkit的作用就是把大模型转换为rk板子所识别的模型,转换为rk板子所识别的模型就可以使用rk的npu,这里用的rk3588有6T的算力。
-
Rkllm-toolkit是一个软件开发工具包,供用户在PC上执行模型转换和量化。
-
RKLLM Runtime为Rockchip NPU平台提供C/C ++ 编程接口,以帮助用户部署RKLLM模型并加速LLM应用程序的实现。
-
RKNPU内核驱动程序负责与NPU硬件进行交互。它是开源的,可以在Rockchip内核代码中找到。
2.2 安装rkllm工具
拷贝文件到如下目录,在运行窗口访问这个目录,拷贝的数据就到了ubuntu系统了,具体看之前的文档。
\\wsl$\Ubuntu-20.04\home\ubuntu20解压之后得到目录:
unzip rknn-llm-release-v1.2.3.ziprknn-llm-release-v1.2.3
通过conda创建一个python3.11的环境
conda create -n py311 python=3.11成功之后进入到环境
conda activate py311如果在命令行前面有了py311 那么环境切换成功了
进入到安装环境目录:rknn-llm-release-v1.2.3/rkllm-toolkit/packages
下面包含如下信息:

安装工具
pip install numpy gekko panda
【1】如果需要cuda那么就安装cuda环境
bash
apt install nvidia-cuda-toolkit
apt install nvidia-driver-535执行:
nvcc --version
bash
nvidia-smi执行量化信息
bash
pip install auto_gptq【2】如果不需要cuda
bash
pip install auto_gptq --no-build-isolation *对了如果是python311 可能无法直接安装auto-gptq
执行下面的文件: rkllm_toolkit-1.2.3-cp311-cp311-linux_x86_64.whl
bash
pip install rkllm_toolkit-1.2.3-cp311-cp311-linux_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple等待一段时间。
三、模型转换
3.1 安装modelscope
安装 modelscope,用于下载大模型
bash
pip install modelscope3.2 下载模型
bash
modelscope download --model Qwen/Qwen3-1.7B下载地址:/root/.cache/modelscope/hub/models/Qwen/Qwen3-1.7B
3.3 转换模型
进入到rknn-llm-release-v1.2.3/examples/rkllm_api_demo/export
bash
cp export_rkllm.py export_rkllm_qwen3.py修改模型路径
bash
modelpath = '/root/.cache/modelscope/hub/models/Qwen/Qwen3-1.7B'执行转换
bash
python export_rkllm_qwen3.py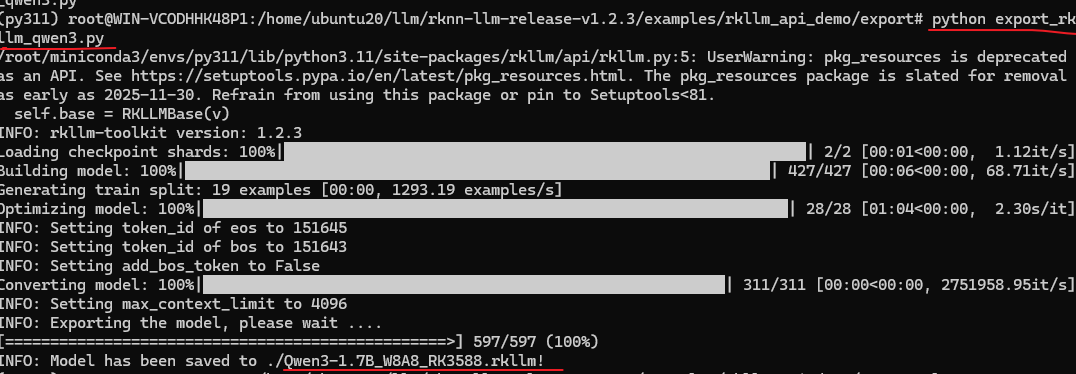
然后再当前目录生成了 Qwen3-1.7B_W8A8_RK3588.rkllm
3.4 编译
有两种方式,一种是交叉编译,另外是直接在办卡rk3588里面编译
这里我没有写在交叉编译环境,直接就在板子上面进行编译把
通过工具连接主板,我是用的 MobaXterm,也可以使用xshell,可以通过串口先查询到ip
把 Qwen3-1.7B_W8A8_RK3588.rkllm 拷贝过去
把下面的文件拷贝过去
rknn-llm-release-v1.2.3/examples/rkllm_api_demo/deploy
rknn-llm-release-v1.2.3\rkllm-runtime\Linux\librkllm_api\aarch64\
rknn-llm-release-v1.2.3\rkllm-runtime\Linux\librkllm_api\include\
把上面两个文件夹内的都拷贝到rk3588具体如下:
把所有的文件拷贝到src:
librkllmrt.so llm_demo.cpp rkllm.h
安装g++
bash
sudo apt install gcc g++ cmake编译
bash
g++ llm_demo.cpp -L. -lrkllmrt -o llm_main编译之后发现如下文件:
llm_main
3.5 验证
添加权限
bash
chmod +x llm_main设置环境变量,可以找到so
bash
export LD_LIBRARY_PATH=/home/hmy/llm/src:$LD_LIBRARY_PATH执行
bash
./llm_main /home/hmy/llm/Qwen3-1.7B_W8A8_RK3588.rkllm 4096 4096如下:
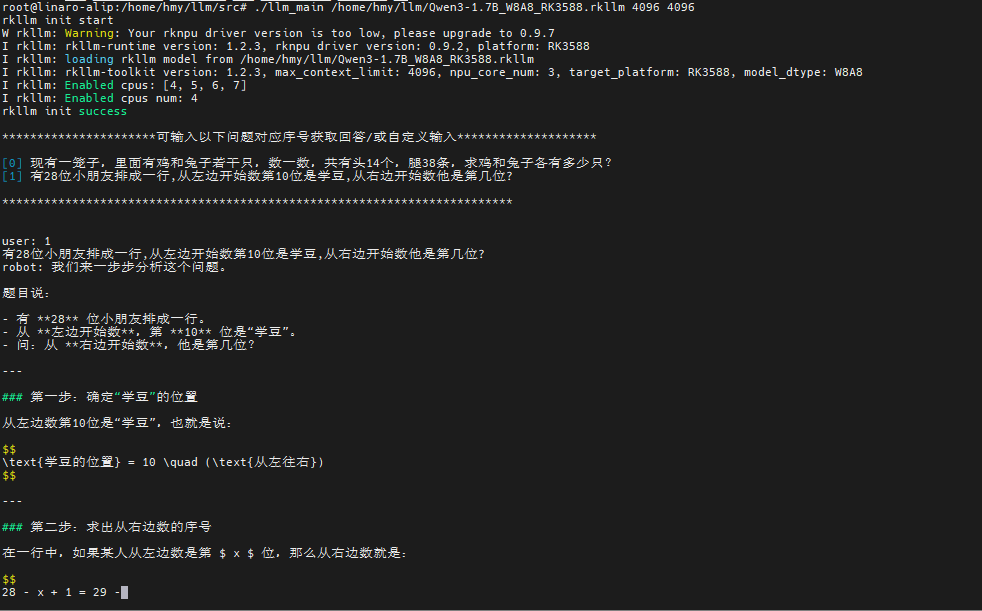
这上述是示例,可以选择另外的python代码,可以接入api
代码路径在:rknn-llm-release-v1.2.3\examples\rkllm_server_demo
执行的时候可以查询npu使用
bash
cat /sys/kernel/debug/rknpu/load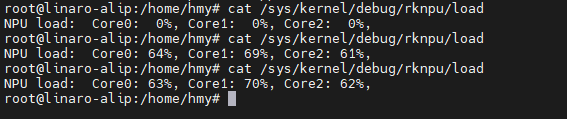
执行cpu和内存
bash
top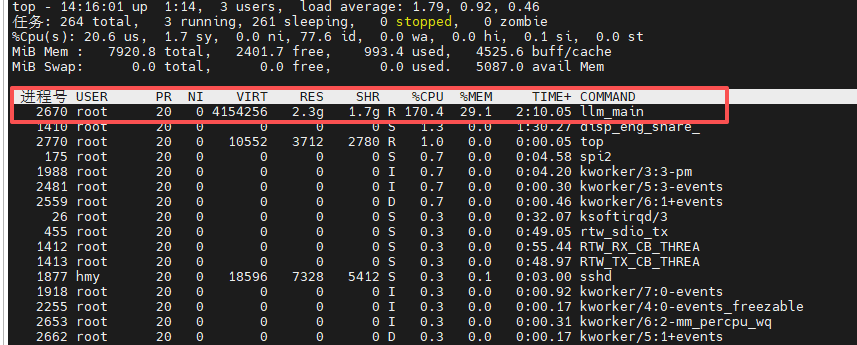
还可以跑其他的模型,其他模型也可以按照这样的思路跑起来。当然多模态的需要转到下面
rknn-llm-release-v1.2.3\examples\multimodal_model_demo\
另外 转换为rknn的模型可以看另外的文档: