个人博客地址
|----------------------------------------|
| 个人博客: 花开富贵 |
文章目录
- 个人博客地址
-
- [1 什么是存储过程](#1 什么是存储过程)
- [2 存储过程的语法](#2 存储过程的语法)
-
- [2.1 环境准备](#2.1 环境准备)
- [2.2 存储过程的创建与调用](#2.2 存储过程的创建与调用)
- [2.3 存储过程的查看](#2.3 存储过程的查看)
- [2.4 删除存储过程](#2.4 删除存储过程)
- [3 变量](#3 变量)
-
- [3.1 系统变量](#3.1 系统变量)
-
- [3.1.1 查看系统变量](#3.1.1 查看系统变量)
- [3.1.2 修改/设置系统变量](#3.1.2 修改/设置系统变量)
- [3.2 用户自定义变量](#3.2 用户自定义变量)
-
- [3.2.1 用户自定义变量的赋值](#3.2.1 用户自定义变量的赋值)
- [3.3 局部变量](#3.3 局部变量)
-
- [3.3.1 局部变量的声明与赋值](#3.3.1 局部变量的声明与赋值)
- [4 SQL编程](#4 SQL编程)
-
- [4.1 条件判断](#4.1 条件判断)
- [4.2 参数](#4.2 参数)
- [4.3 CASE](#4.3 CASE)
- [4.4 循环](#4.4 循环)
-
- [4.4.1 WHILE 循环](#4.4.1 WHILE 循环)
- [4.4.2 REPETA 循环](#4.4.2 REPETA 循环)
- [4.4.3 LOOP 循环](#4.4.3 LOOP 循环)
1 什么是存储过程
-
存储过程
存储过程是一组为了完善特定功能的
SQL语句集, 通常经编译过后存储在数据库当中, 用户通过制定存储过程的名字和参数来进行执行, 并获取相应的结果;
从这个表述来看, 实际上, 存储过程类似于函数;
举个简单的例子:
cpp
int func(int value){
value = value+20;
return valuel;
}这个例子是一个函数, 而存储过程类似于一个函数, 其中以该段代码为例, "用户指定存储过程的名字和参数来执行" 不就是在该函数的调用中为 int res = func(10);的方式吗, 其中func为对应的存储过程名, 参数为10, 返回值为res;
首先我们知道SQL的全称实际上为 Structured Query Language , 这意味着MySQL同样是一种语言, 因此在MySQL或者其他SQL中, 将一条或者多条SQL语句进行封装编译并保存, 当调用时不需要重新进行编译, 直接调用当前库中的函数即可, 这种封装的函数, 我们称之为 存储过程 ;
存储过程主要的特点有以下几种:
-
封装性
将业务逻辑封装在数据库内部, 减少应用程序的复杂性;
-
可维护性
集中管理数据库操作, 便于维护和更新;
当数据库操作需要进行修改时, 上层业务逻辑无需进行大改;
-
可复用性
可以被多次调用, 提高代码复用性;
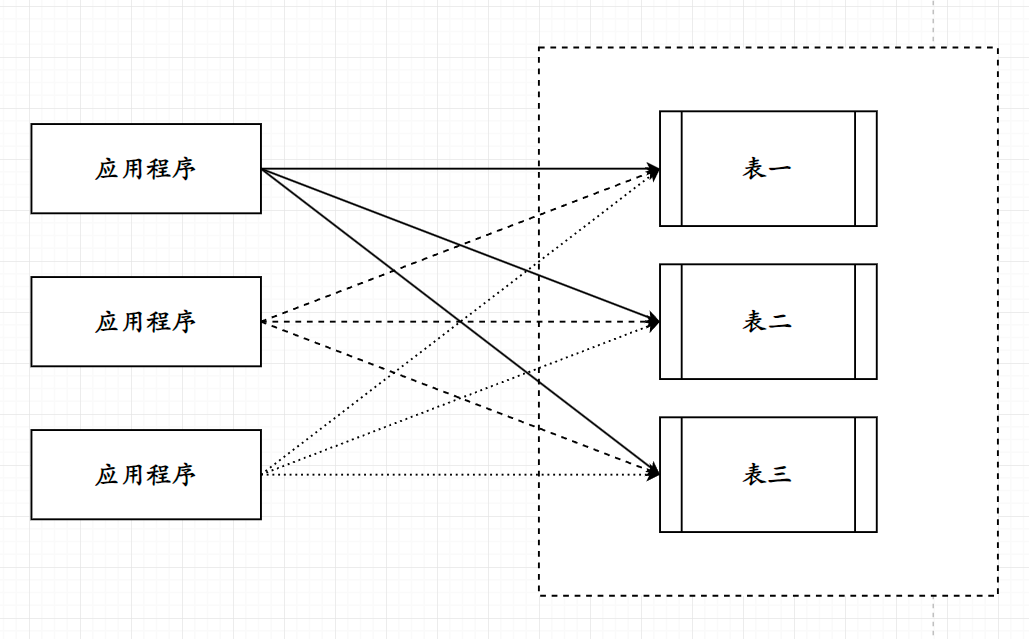
我们可以进行对比, 即应用程序直接操作表, 与应用程序通过存储过程操作表;
-
应用程序直接操作表
-
应用程序通过存储过程操作表
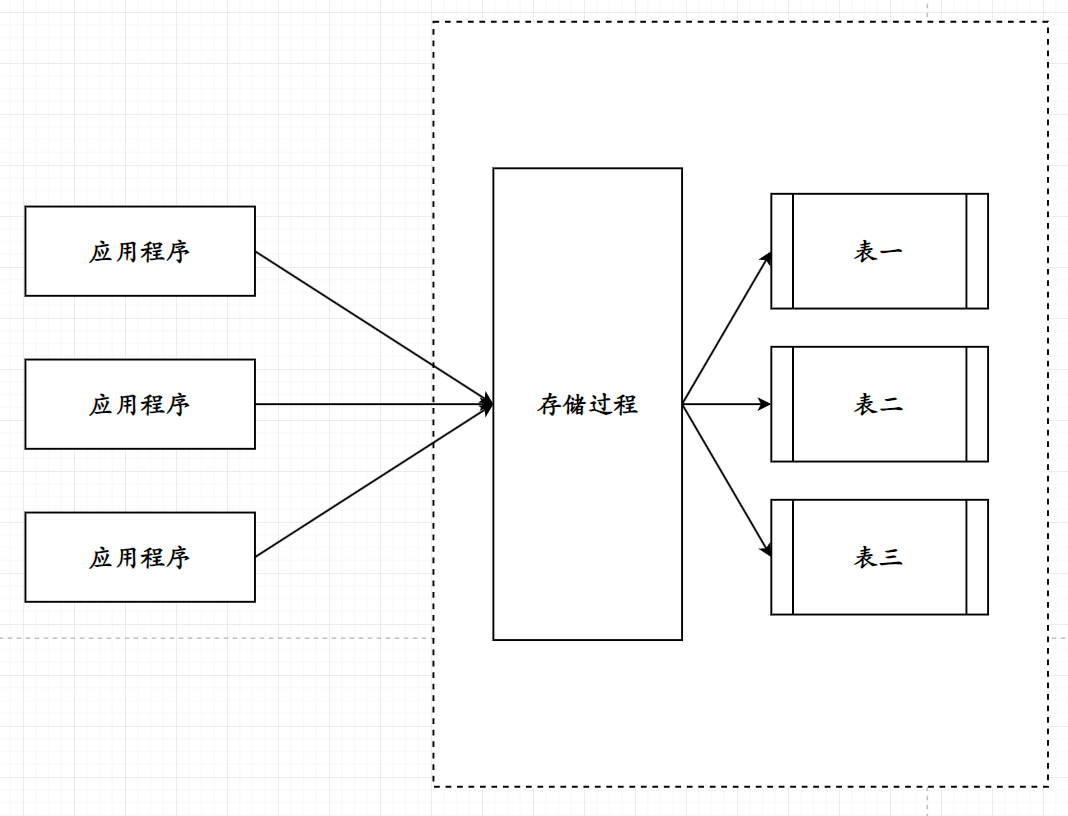
可以从上图看到, 经过封装后, 应用程序只需要调用存储过程即可, 无需再进行复杂的事务编写从而避免了繁杂的事务编写, 多条相同事务的冗余(代码复用低)以及每次语句进入数据库的编译导致的效率低;
这种方式可以使得大部分的业务逻辑直接在数据库层面处理, 应用程序位置只进行对应的调用, 也间接的提高性能(减少语句编译频率, 减少IO;
存储过程也能够提高数据库的安全性, 当编写好存储过程过后, 只向外部暴露提供一个执行接口, 以避免数据库或表直接暴露在外部所产生的安全隐患;
存储过程的优缺点分别如下:
优点
性能优化
存储过程在创建时编译并保存在数据库中, 执行速度比单个
SQL语句快;本质上而言, 当一个
SQL进入数据库后, 需要进行编译, 解释, 再进行执行;而存储过程已进行了编译并保存, 直接调用即可;
代码复用
存储过程类比于函数, 编程语言函数为将一系列操作封装为一个方法, 而存储过程为, 将一系列的数据库操作语句封装为一个方法;
安全性
使用存储过程可以限制用户对数据库的直接访问, 而是通过存储过程间接访问, 从而保证系统安全性;
事务管理
可以在存储过程中实现复杂的事务逻辑;
降低耦合
当表结构发生变化时, 只需要修改对应的存储过程, 对应的应用上层业务代码可以减少改动;
缺点
可移植性差
存储过程无法跨数据库移至, 当数据库发生变更时(如
MySQL转至SQLServer), 需要重新编写;调试困难
只有少数的数据库管理系统支持存储过程的调试, 本身开发和维护困难;
不适合高并发场景
在高并发场景下, 本身数据库需要进行高负载的工作, 再使用存储过程会增加数据库的压力;
2 存储过程的语法
存储过程的语法与一些编程语言如出一辙, 主要为存储过程的定义与存储过程的调用;
2.1 环境准备
本章节所使用的主要工具为Navicat;
所需表为如下:
cpp
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP DATABASE IF EXISTS `test_db`;
CREATE DATABASE `test_db` CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
USE `test_db`;
-- ----------------------------
-- Table structure for classes
-- ----------------------------
DROP TABLE IF EXISTS `classes`;
CREATE TABLE `classes` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`desc` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of classes
-- ----------------------------
-- Translated class names and descriptions
INSERT INTO `classes` VALUES (1, 'CS Class 1, 2019', 'Learned Computer Principles, C, Java, Data Structures, Algorithms');
INSERT INTO `classes` VALUES (2, 'Chinese Dept Class 3, 2019', 'Learned Traditional Chinese Literature');
INSERT INTO `classes` VALUES (3, 'Automation Class 5, 2019', 'Learned Mechanical Automation');
-- ----------------------------
-- Table structure for course
-- ----------------------------
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of course
-- ----------------------------
-- Translated course names
INSERT INTO `course` VALUES (1, 'Java');
INSERT INTO `course` VALUES (2, 'Traditional Chinese Culture');
INSERT INTO `course` VALUES (3, 'Computer Principles');
INSERT INTO `course` VALUES (4, 'Chinese Language');
INSERT INTO `course` VALUES (5, 'Advanced Mathematics');
INSERT INTO `course` VALUES (6, 'English');
-- ----------------------------
-- Table structure for score
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`score` decimal(3, 1) NULL DEFAULT NULL,
`student_id` int(11) NULL DEFAULT NULL,
`course_id` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of score
-- ----------------------------
INSERT INTO `score` VALUES (70.5, 1, 1);
INSERT INTO `score` VALUES (98.5, 1, 3);
INSERT INTO `score` VALUES (33.0, 1, 5);
INSERT INTO `score` VALUES (98.0, 1, 6);
INSERT INTO `score` VALUES (60.0, 2, 1);
INSERT INTO `score` VALUES (59.5, 2, 5);
INSERT INTO `score` VALUES (33.0, 3, 1);
INSERT INTO `score` VALUES (68.0, 3, 3);
INSERT INTO `score` VALUES (99.0, 3, 5);
INSERT INTO `score` VALUES (67.0, 4, 1);
INSERT INTO `score` VALUES (23.0, 4, 3);
INSERT INTO `score` VALUES (56.0, 4, 5);
INSERT INTO `score` VALUES (72.0, 4, 6);
INSERT INTO `score` VALUES (81.0, 5, 1);
INSERT INTO `score` VALUES (37.0, 5, 5);
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) PRIMARY KEY AUTO_INCREMENT,
`sn` int(11) NOT NULL COMMENT 'Student Number',
`name` varchar(20) NOT NULL COMMENT 'Student Name',
`mail` varchar(20) COMMENT 'QQ Email'
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
-- Translated student names to Pinyin/English to match email abbreviations (zs, ls, ww, etc.)
INSERT INTO `student` VALUES (1, 50001, 'Zhang San', 'zs@bit.com');
INSERT INTO `student` VALUES (2, 50002, 'Li Si', 'ls@bit.com');
INSERT INTO `student` VALUES (3, 50003, 'Wang Wu', 'ww@bit.com');
INSERT INTO `student` VALUES (4, 50004, 'Zhao Liu', 'zl@bit.com');
INSERT INTO `student` VALUES (5, 50005, 'Qian Qi', 'qq@bit.com');
SET FOREIGN_KEY_CHECKS = 1;2.2 存储过程的创建与调用
sql
DELIMITER // -- 修改SQL语句的结束标识符为 //
CREATE PROCEDURE 存储过程名 (参数)
BEGIN -- 标志存储过程的开始作用域
-- SQL语句
END // -- 标志存储过程的结束作用域
DELIMITER ; -- 修改SQL语句的结束标识符为 ;
-- -------------------------
CALL 存储过程名 (传参) ; -- 调用存储过程, 如: CALL f1();其中主要的部分为CREATE PROCEDURE ... 至 END部分, 该部分为真正创建一个存储过程;
示例:
SQL
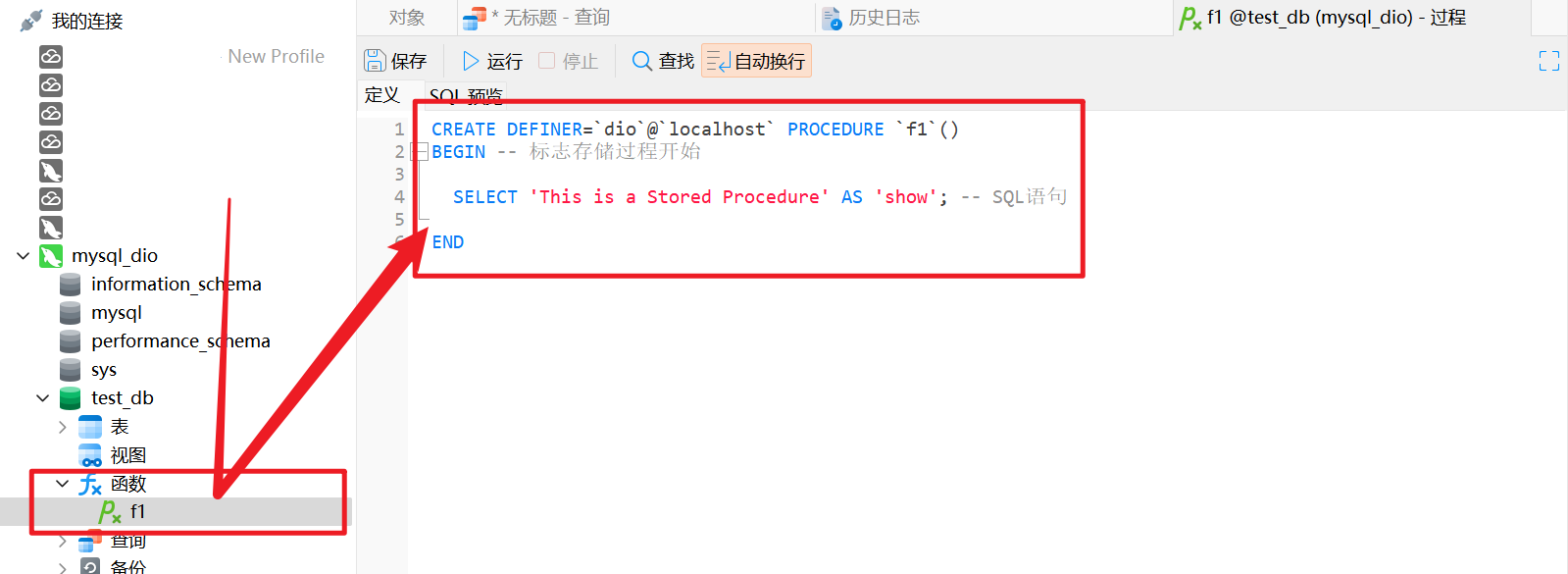
CREATE PROCEDURE f1 () -- 创建存储过程名
BEGIN -- 标志存储过程开始
SELECT 'This is a Stored Procedure' AS 'show'; -- SQL 显示 'This is a Stored Procedure' 并重命名为 'show'
END -- 标志存储过程结束运行结果后对应的Navicat中的 "函数" 部分将出现此次编译保存的存储过程;
双击后可以查看对应的存储过程的创建语句;
通常调用存储过程的方式为:
sql
CALL 存储过程名(参数);如:
sql
CALL f1();对应的调用结果为:
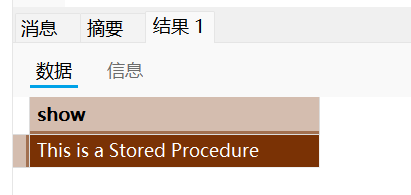
在最开始的例子中, 我们使用了关键字DELIMITER来修改SQL语句的结束标识符, 这是一种预防行为;
当在Shell命令行中使用SQL语句时, 通常会将第一个遇到的 ; 看作是SQL语句的结束符;
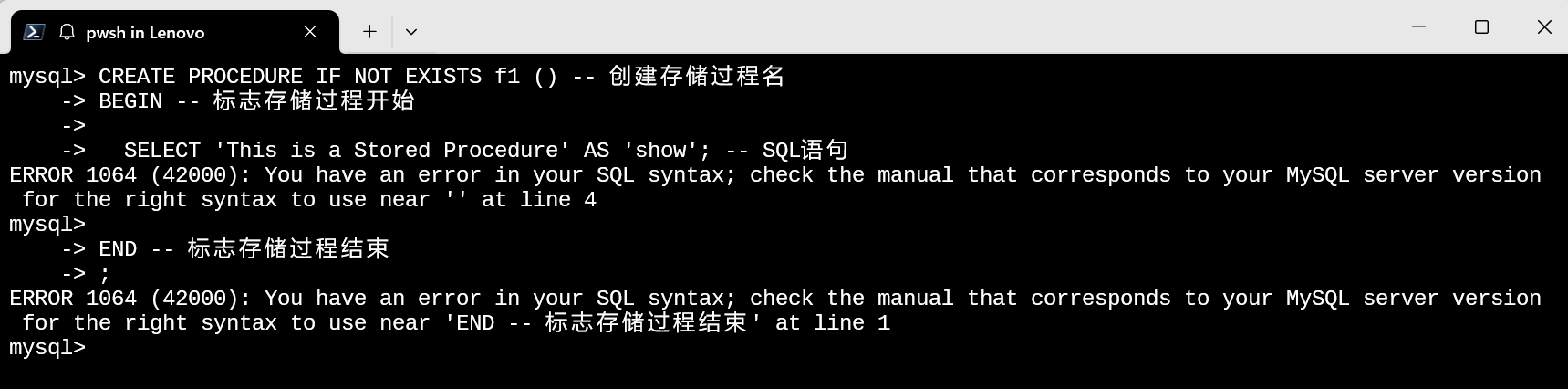
因此无法很好的执行;
而通过DELIMITER可以修改结束标识符, 当修改了结束标识符后, 存储过程中出现的单条SQL语句将不会被解释器中断;
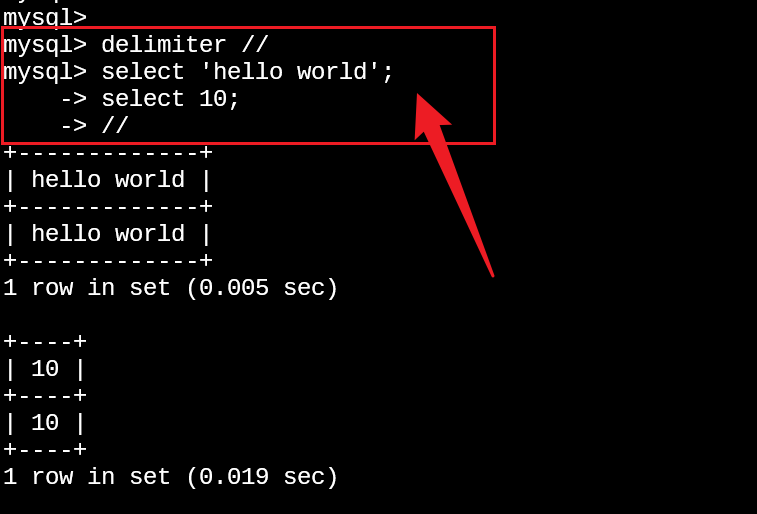
使用DELIMITER修改SQL语句的结束标识为//, 因此 ; 不会结束单条语句, 遇到 // 才算单条SQL语句的结束;
因此使用DELIMITER修改SQL语句的结束标识能更好的在不同的客户端中进行存储过程的创建;
完整的语句为:
sql
DELIMITER // -- 修改SQL语句的结束标识符为 //
CREATE PROCEDURE f1 () -- 创建存储过程名
BEGIN -- 标志存储过程开始
SELECT 'This is a Stored Procedure' AS 'show'; -- SQL语句
END // -- 标志存储过程结束
DELIMITER ;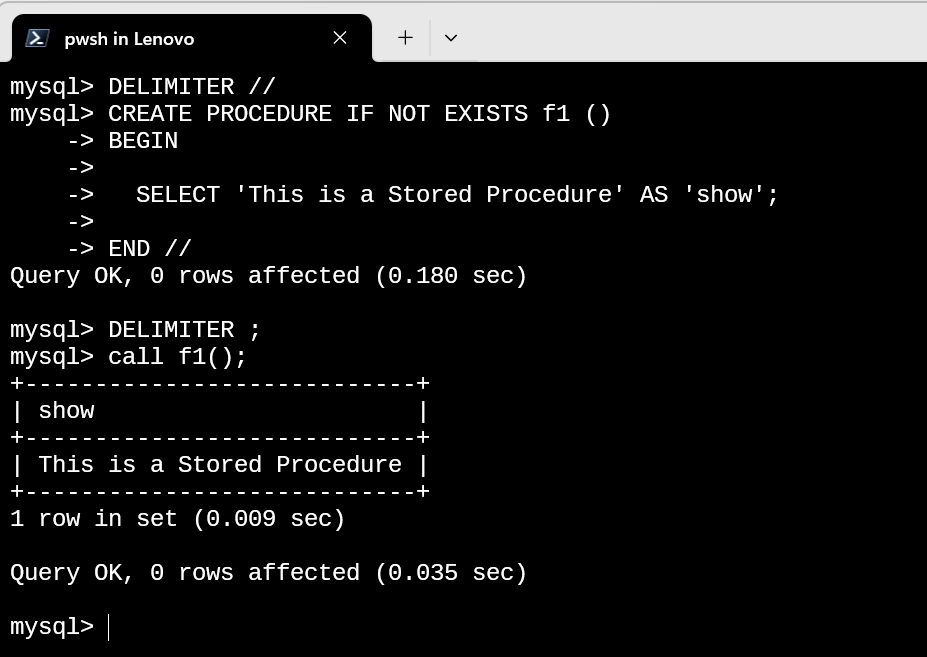
通常情况下, 开发机对应的SQL语句转移至服务端时, 都需要使用DELIMITER修改对应的SQL结束标识符, 以便于整段SQL语句的载入;
2.3 存储过程的查看
存储过程通常存储在数据库 information_schema的ROUTINES表中, 其中该表中的 ROUTINE_NAME字段为对应的存储过程名(不同版本可能有细微差异);
sql
SELECT * FROM information_schema.ROUTINES WHERE ROUTINE_NAME = '存储过程名';
除此之外, 也可以使用 SHOW CREATE 存储过程名 的方式进行查询;
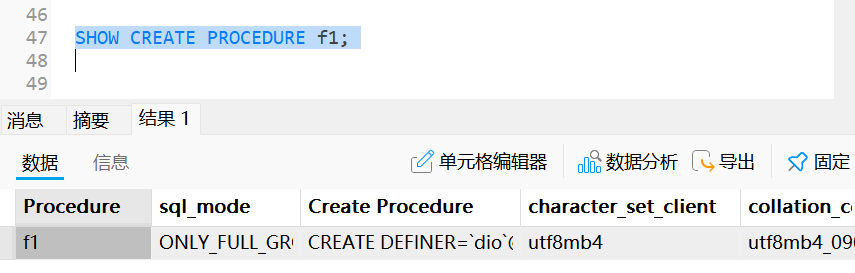
2.4 删除存储过程
删除存储过程的方式与删除表的方式相同:
sql
DROP PROCEDURE IF EXISTS 存储过程名;
3 变量
SQL是一种结构化查询语言, 同样支持变量的定义与使用;
MySQL中的变量大致分为三种:
- 系统变量
- 用户定义变量
- 局部变量
3.1 系统变量
系统变量通常用于对MySQL而言是一种服务器的配置变量, 其控制者服务器的行为和性能;
系统变量通常分为两个级别:
-
全局级(
GLOBAL)全局级的系统变量为级别最高级别的系统变量, 通常来自于一些配置文件;
MySQL读取对应的配置文件后将配置文件中的系统设置读取进服务端中, 并进行设置;当使用命令行或者
SQL语句修改对应的全局系统变量时, 本质是在内存中设置了这个全局变量, 并不会写入对应的配置文件;通过
SET GLOBAL的全局系统变量将会在mysqld服务重启后丢失(恢复成配置文件.ini/.cnf中的旧值);在
MySQL 8.0+的版本中引入了一个新语法, 可以将对应的全局变量设置进mysqld-auto.cnf文件;sqlSET PERSIST max_connections = 1000;若要进行持久化的全局系统变量设置, 需要单独修改对应的配置文件;
-
会话级(
SESSION)每个连接都是一个会话, 会话级的系统变量默认继承自全局系统变量;
通常通过命令行或是
SQL语句来修改对应的会话级系统变量时不会影响全局系统变量, 因此也不会影响其他会话, 只影响当前会话;
3.1.1 查看系统变量
-
查看所有系统变量
sqlSHOW [GLOBAL | SESSION] VARIABLES; -
查看指定的系统变量(可模糊查询)
sqlSHOW [GLOBAL | SESSION] VARIABLES LIKE 'xxx'; SHOW [GLOBAL | SESSION] VARIABLES LIKE '%xxx_'; -- 使用 % 或 _ 进行模糊查询如查看开头为
auto的系统变量名;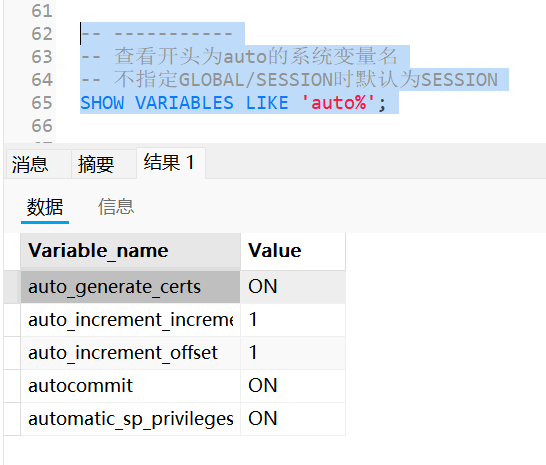
-
使用
SELECT查看指定的系统变量sqlSELECT @@[GLOBAL | SESSION].system_variable_name;如查看
autocommit系统变量;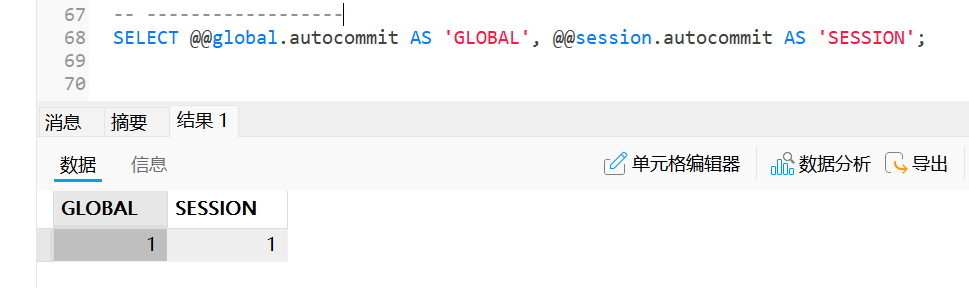
由于SELECT查询的是指定的变量而不是通过字符串的形式模糊查找, 因此需要指定的系统变量名;
通常情况下, 全局变量的变量名前存在 @@前缀, 即 @@xxxx的形式, @前缀的变量为用户自定义变量;
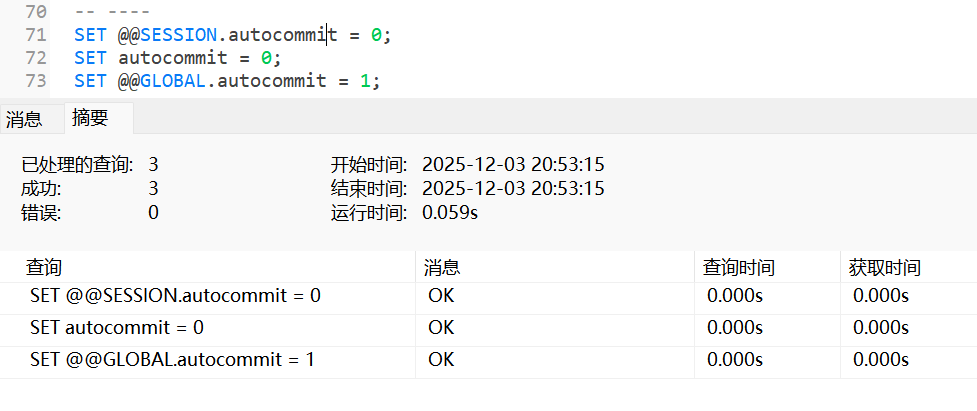
3.1.2 修改/设置系统变量
sql
SET [GLOBAL | SESSION] 系统变量名 = 值;
SET @@[GLOBAL | SESSION].系统变量名 = 值;修改设置系统变量的方式通常需要指定具体的系统变量名, 并采用SET进行设置;
3.2 用户自定义变量
用户自定义变量是在SQL会话中定义的一种变量, 通常不用提前声明, 作用域为当前会话;
其主要的作用为保存查询的中间结果, 以便后续进行使用;
在MySQL中, 前缀为@的为用户自定义变量, 前缀为 @@的为系统变量;
3.2.1 用户自定义变量的赋值
变量的定义(赋值)可以分为三种:
-
采用
SET赋值sql-- 1) SET @var_name = expr [, @var_name] ...; -- 2) SET @var_name := expr [, @var_name] ...; -- 推荐这两种方式实际上是一种方式, 只是使用的赋值符号不同, 一个采用
=, 一个采用:=;通常情况下采用第二种, 也是极为推荐的一种;
不推荐使用第一种的方式本质上是因为, 其产生了一种语法歧义;
在
MySQL中, 我们通常使用=进行相等的比较, 而在这里进行了一种赋值的操作, 因此为了避免在使用过程中将二者混淆又或是为了提高存储过程的代码可读性, 因此采用第二种方式;
-
在
SELECT语句中进行赋值sqlSELECT @var_name := expr [, @var_name] ...; -- 这里必须使用 := , 否则将产生歧义这种使用方式为设置对应的变量并对其进行
SELECT打印;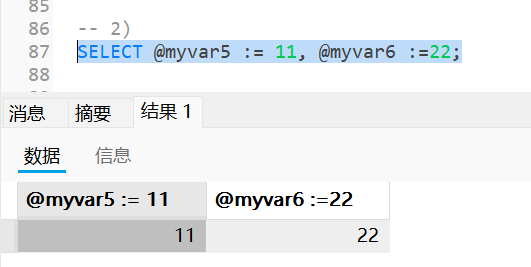
-
查询结果赋值给自定义变量
sqlSELECT column_name INTO @var_name1 [, @var_name2, ...] FROM table_name WHERE ...;这种方式可以将对应的查询结果赋值给某个自定义变量;
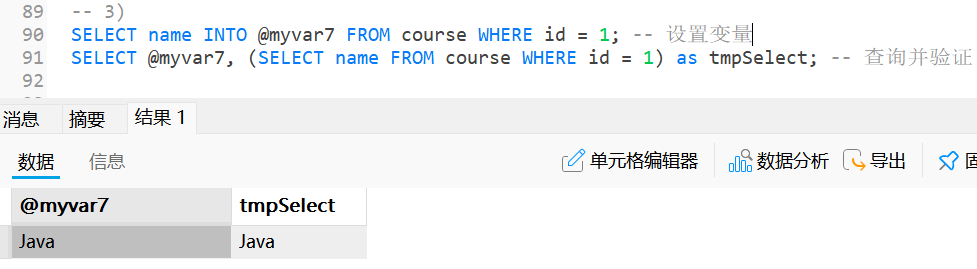
这种查询方式的结果必须精确指定字段数量, 且只能为单行, 即"一个萝卜一个坑";
用户自定义变量通常不需要声明, 其定义与赋值即为声明, 且单个用户自定义变量无需指定对应的数据类型;
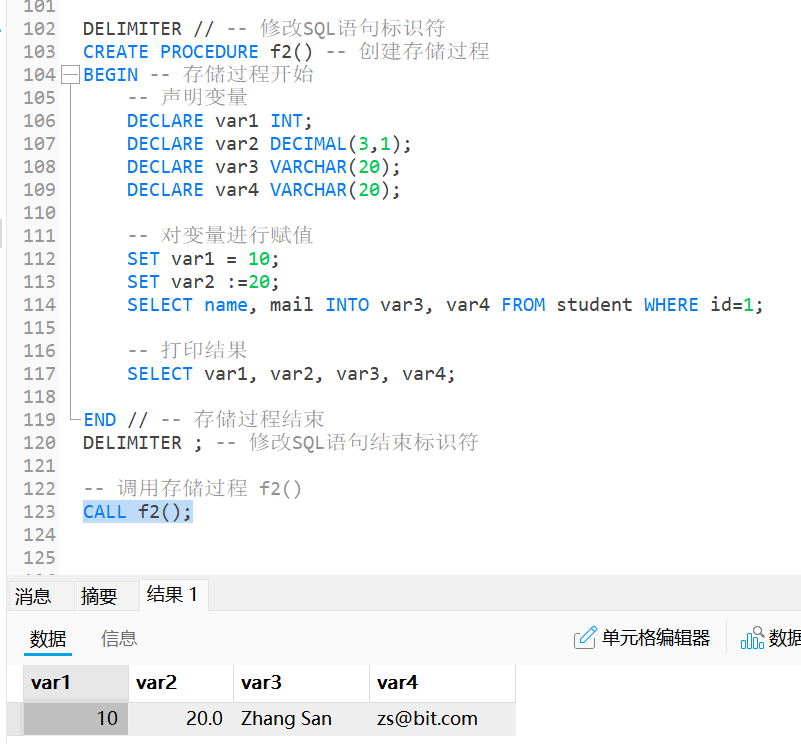
3.3 局部变量
局部变量旨在存储过程, 函数或是触发器的范围内有效, 需要使用DECLARE声明, 其作用域范围在声明的BEGIN ... END块内;
3.3.1 局部变量的声明与赋值
局部变量需要指定数据的类型, 其对应的类型可以是MySQL中任意的有效类型, 包括但不限于INT, VARCHAR, DATATIME等;
声明局部变量的语法为:
sql
DECLARE var_name var_type [DEFAULT default_val] ... ;其赋值方式与用户自定义变量的赋值方式类似:
sql
-- 1)
SET var_name = expr [, var_name = expr ...]; -- 不推荐
SET var_name := expr [, var_name = expr ...]; -- 推荐
-- 2)
SELECT column_name1 [, var_name2, ...] INTO var_name1 [, var_name2, ...] FROM table_name WHERE ...;示例:
4 SQL编程
SQL是结构化查询语言, 本身是一种特殊目的的编程语言, 一种数据库查询和程序设计语言, 通常用于数据的存取, 查询, 更新以及管理;
既然是一种语言, 其必定存在各项编程语言的基础语法, 包括但不限于条件判断, 循环等;
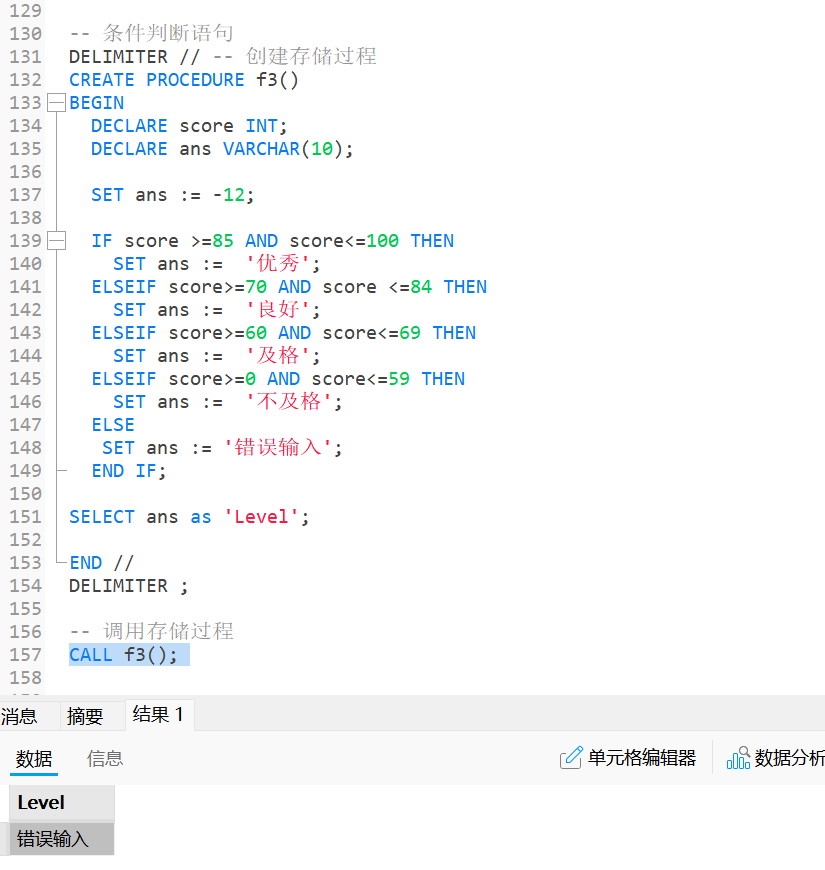
4.1 条件判断
在MySQL中同样存在IF条件语句;
其对应的条件判断语句为:
sql
IF condition1 THEN -- 条件判断开始
...... -- 执行语句
[ELSEIF condition2 THEN
...... -- 执行语句
ELSE
......]
END IF; -- 条件判断结束这种句式可以类比于c/cpp中的条件判断语句:
cpp
if(/* condition1 */){
/* write code here */
} else if(/* condition2 */){
/* write code here */
}else{ /* the other conditions */
/* write code here */
}唯一不同的是, 在SQL存储过程中, 需要标定IF的结束位置, 主要原因是在SQL中不存在{}, 因此只能采用这种方式来标定一个特殊语句的作用域;
4.2 参数
同样的, 在存储过程中同样可以设置参数;
在MySQL的存储过程中, 参数被分为三种:
| 类型 | 描述 |
|---|---|
IN |
输入类型, 调用存储过程时要传入的值, 默认参数类型; |
OUT |
输出类型, 可以作为存储过程的返回值; |
INOUT |
输入输出类型, 既可以作为输入类型, 也可以作为输出类型; |
三种类型的参数不能混用, 通常情况下, IN类型只能进行输入, 无法进行输出, OUT无法进行输入, 只能进行输出, INOUT既能进行输入, 也能进行输出;
我们可以类比cpp中的, 传值传参, 传指针传参, 与传引用传参, 分别对应的IN, OUT, INOUT;
当存储过程传入一个IN类型的参数时, 相当于传值传参, 进入存储过程的参数只是一个临时拷贝, 形参不影响实参;
SQL
-- 1) 输入型参数
DROP PROCEDURE IF EXISTS inf4;
DELIMITER //
CREATE PROCEDURE inf4(IN val INT)
BEGIN
SET val:=999;
END //
DELIMITER ;
SET @intestval :=10;
CALL inf4(@intestval);
SELECT @intestval;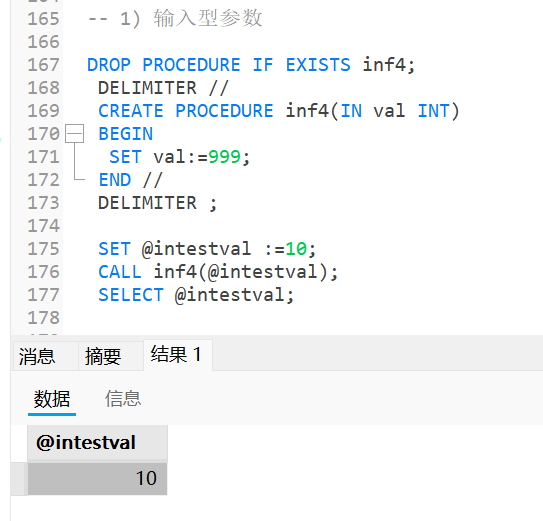
当存储过程传入一个OUT类型参数, 相当于传指针传参, 但OUT类型的数据, 无论是什么数据, 都会在入口处被强制重置为NULL, 因此也像是传入指针后对指针进行了一个*ptr=0的强制清除操作;
SQL
-- 2) 输出型参数
DROP PROCEDURE IF EXISTS outf4;
DELIMITER //
CREATE PROCEDURE outf4(OUT val INT)
BEGIN
SELECT val;
END //
DELIMITER ;
SET @outtestval :=10;
CALL outf4(@outtestval);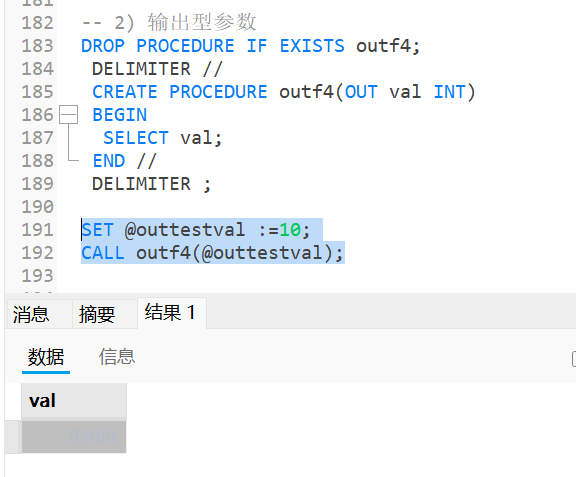
当存储过程传入一个INOUT参数, 相当于进行传引用传参, 该参数既能当做输入型参数, 也能作为输出型参数;
SQL
-- 3) 输入输出型参数
DROP PROCEDURE IF EXISTS inoutf4;
DELIMITER //
CREATE PROCEDURE inoutf4(INOUT val INT)
BEGIN
SELECT val;
SET val:=999;
END //
DELIMITER ;
SET @inouttestval :=10;
CALL inoutf4(@inouttestval);
SELECT @inouttestval;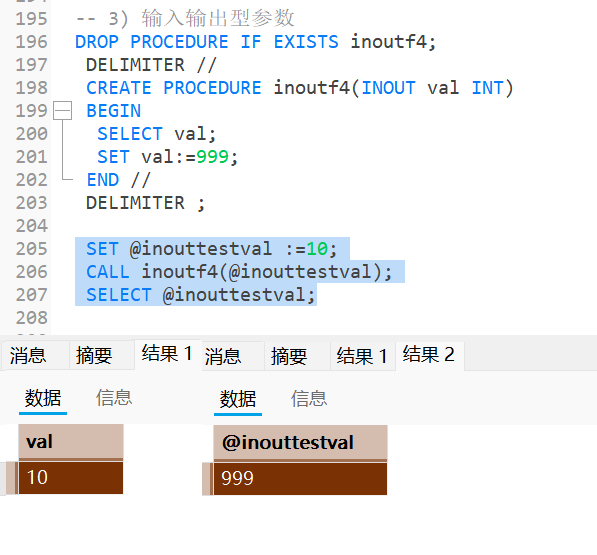
将参数配合4.1中的内容重新生成对应的存储过程, SQL代码为:
sql
drop procedure if exists f4;
DELIMITER // -- 创建存储过程
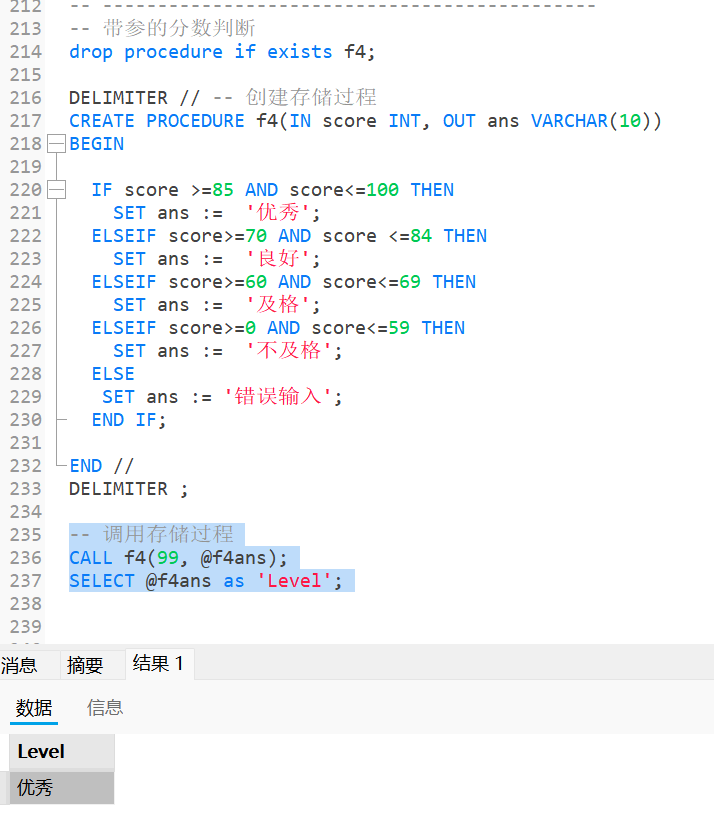
CREATE PROCEDURE f4(IN score INT, OUT ans VARCHAR(10))
BEGIN
IF score >=85 AND score<=100 THEN
SET ans := '优秀';
ELSEIF score>=70 AND score <=84 THEN
SET ans := '良好';
ELSEIF score>=60 AND score<=69 THEN
SET ans := '及格';
ELSEIF score>=0 AND score<=59 THEN
SET ans := '不及格';
ELSE
SET ans := '错误输入';
END IF;
END //
DELIMITER ;
-- 调用存储过程
CALL f4(99, @f4ans);
SELECT @f4ans as 'Level';结果为:
4.3 CASE
相同的, 在存储过程中同样支持CASE语句;
在存储过程中的CASE语句通常分为两种:
-
语法一
sqlCASE case_value WHEN when_value THEN statement_list [WHEN when_value THEN statement_list] ... [ELSE statement_list] END CASE这是一种标准的
case表达式, 该表达式的值与每一个WHEN子句中的when_value比较, 当找到一个相等的when_value时, 将会执行对应的THEN子句的statement_list;如果没有对应的
when_value将会执行ELSE子句(类比于c/cpp中的default);需要注意的是, 这里的
when_value是具体值, 而case_value是一个具体变量;示例:
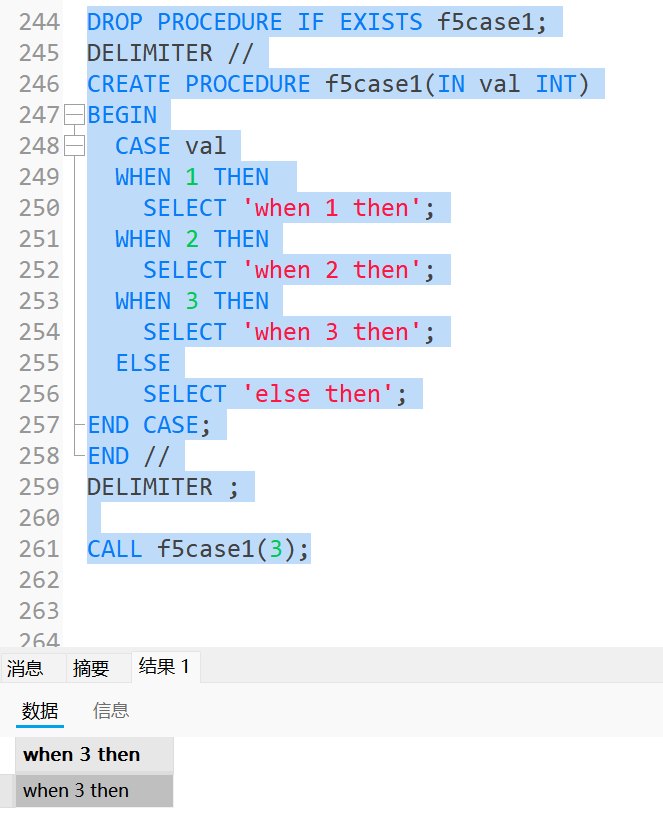
sqlDROP PROCEDURE IF EXISTS f5case1; DELIMITER // CREATE PROCEDURE f5case1(IN val INT) BEGIN CASE val WHEN 1 THEN SELECT 'when 1 then'; WHEN 2 THEN SELECT 'when 2 then'; WHEN 3 THEN SELECT 'when 3 then'; ELSE SELECT 'else then'; END CASE; END // DELIMITER ; CALL f5case1(3);运行结果为:
-
语法二
sqlCASE WHEN search_condition THEN statement_list [WHEN search_condition THEN statement_list] ... [ELSE statement_list] END CASE语法二本质上是对多重判断的简化;
其中每个
WHEN中都带有一个search_condition表达式, 当表达式成立时将去执行他们对应的THEN子句statement_list;如果
search_condition条件都不成立, 将会去执行ELSE的子句statement_list;使用该方法对
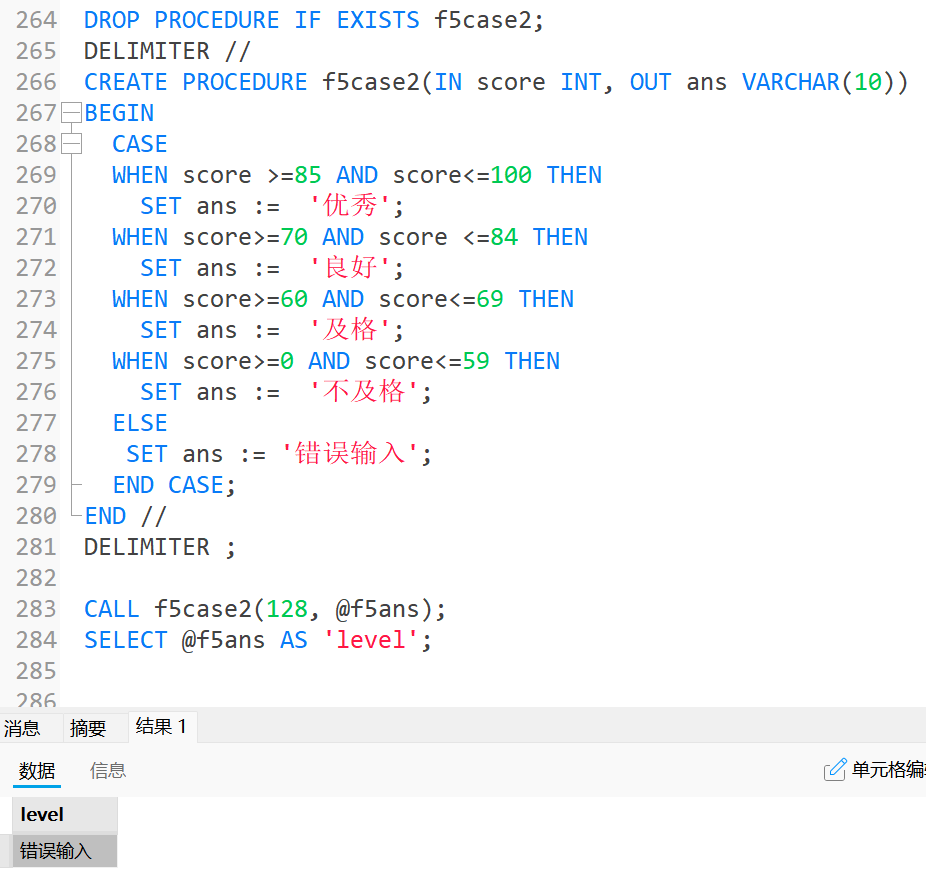
4.1中的内容进行改写:sqlDROP PROCEDURE IF EXISTS f5case2; DELIMITER // CREATE PROCEDURE f5case2(IN score INT, OUT ans VARCHAR(10)) BEGIN CASE WHEN score >=85 AND score<=100 THEN SET ans := '优秀'; WHEN score>=70 AND score <=84 THEN SET ans := '良好'; WHEN score>=60 AND score<=69 THEN SET ans := '及格'; WHEN score>=0 AND score<=59 THEN SET ans := '不及格'; ELSE SET ans := '错误输入'; END CASE; END // DELIMITER ; CALL f5case2(128, @f5ans); SELECT @f5ans AS 'level';运行结果为:
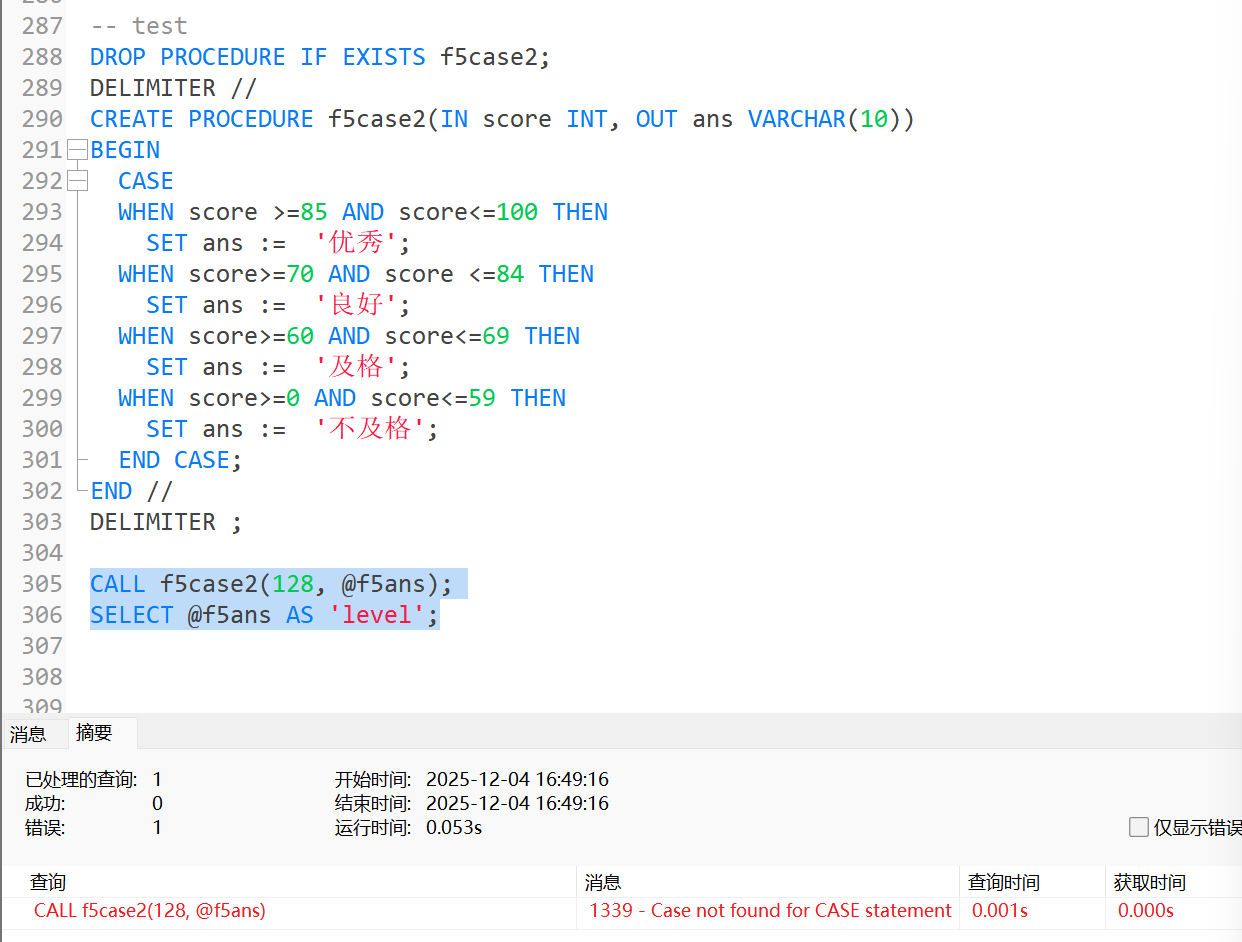
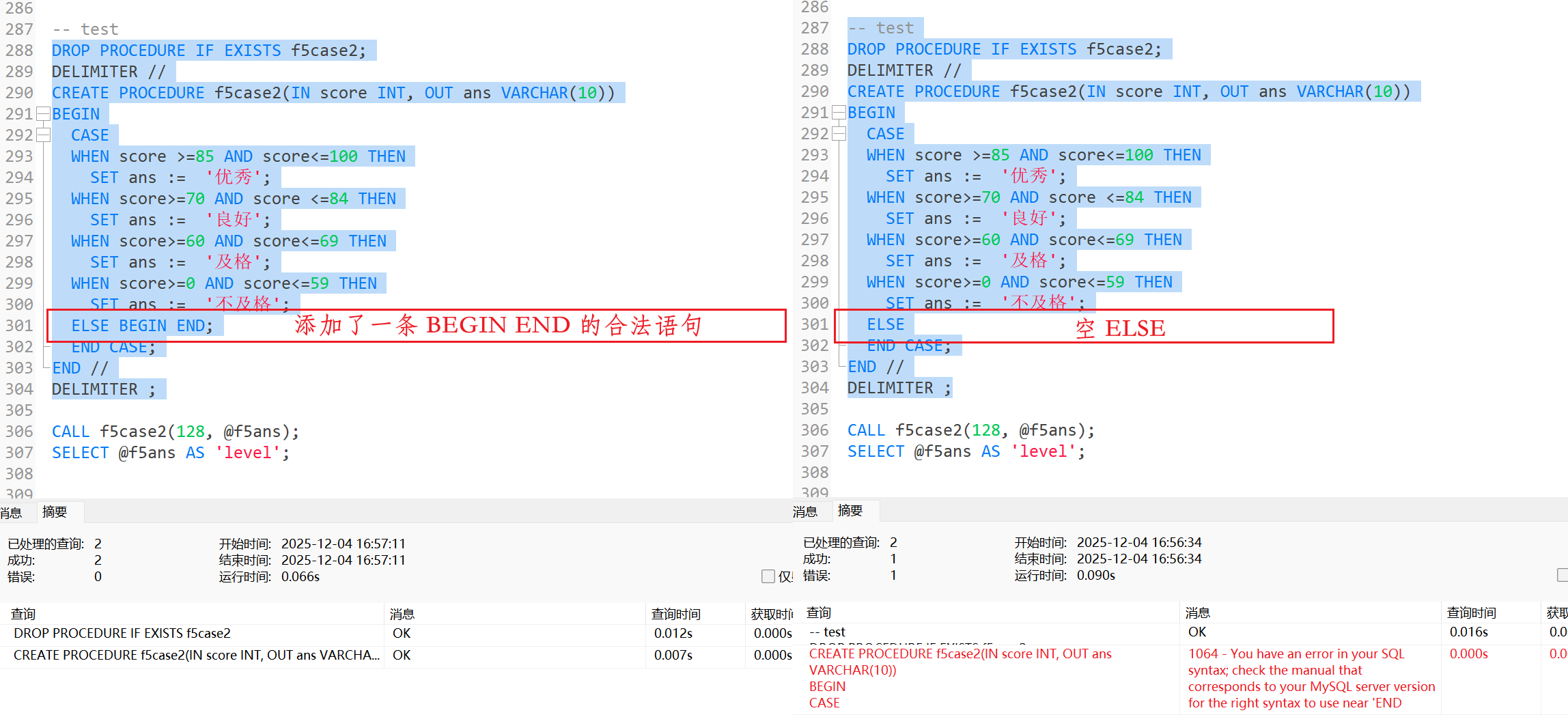
需要注意的是, 在进行CASE语句的编写时, 虽然ELSE条件是可选项, 但是大多数时候都需要编写ELSE在END CASE之前, 写不写ELSE并不会影响编译, 但会影响运行;
当一个语句在对应的CASE语句中没有找到对应的条件时, 将会去执行他的ELSE, 而若是没有ELSE, 它将会执行出错, 因此是否具有ELSE条件, 都需要写上对应的ELSE, 即使他的statement_list为空, 也需要加上ELSE;
当然, 当若是出现对应的空ELSE条件, 我们需要为其加上一条空语句或者无效语句, 如BEGIN END, 这是一个合法的空语句, 否则也可能出现报错;
4.4 循环
在MySQL的存储过程中, 同样也有循环, 其循环方式分为三种, 分别为:
WHILE循环REPETA循环LOOP循环
4.4.1 WHILE 循环
sql
WHILE search_condition DO
statement_list
END WHILE;这里的WHILE循环与c/cpp类似, 同样为条件成立即循环;
其中这里的DO类比c/cpp中的{, 即循环的开始作用域;
END WHILE类比c/cpp中的}, 即循环的结束作用域;
-
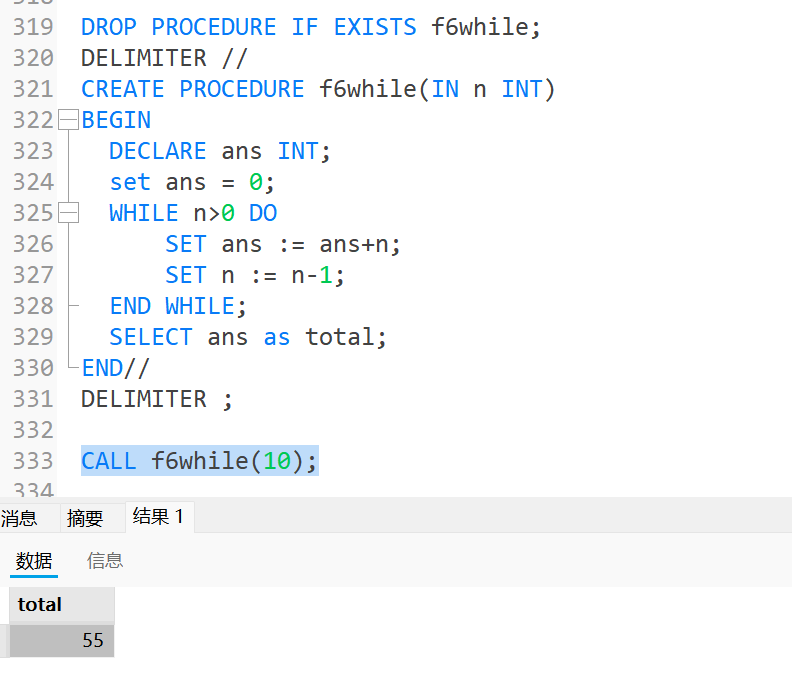
示例
写一个数, 由
1加到n;sqlDROP PROCEDURE IF EXISTS f6while; DELIMITER // CREATE PROCEDURE f6while(IN n INT) BEGIN DECLARE ans INT; set ans = 0; WHILE n>0 DO SET ans := ans+n; SET n := n-1; END WHILE; SELECT ans as total; END// DELIMITER ; CALL f6while(10);运行结果为:
4.4.2 REPETA 循环
sql
REPEAT
statement_list
UNTIL search_condition
END REPEAT;该循环可以类比于c/cpp中的do while循环, 即先进行一次循环体, 再进行判断;
其中UNTIL表示条件标识符, 其后面跟着的search_condition即为条件, 需要注意的是, 这里的条件为结束条件而不是循环条件, REPETA中的条件通常要与WHILE循环条件相反;
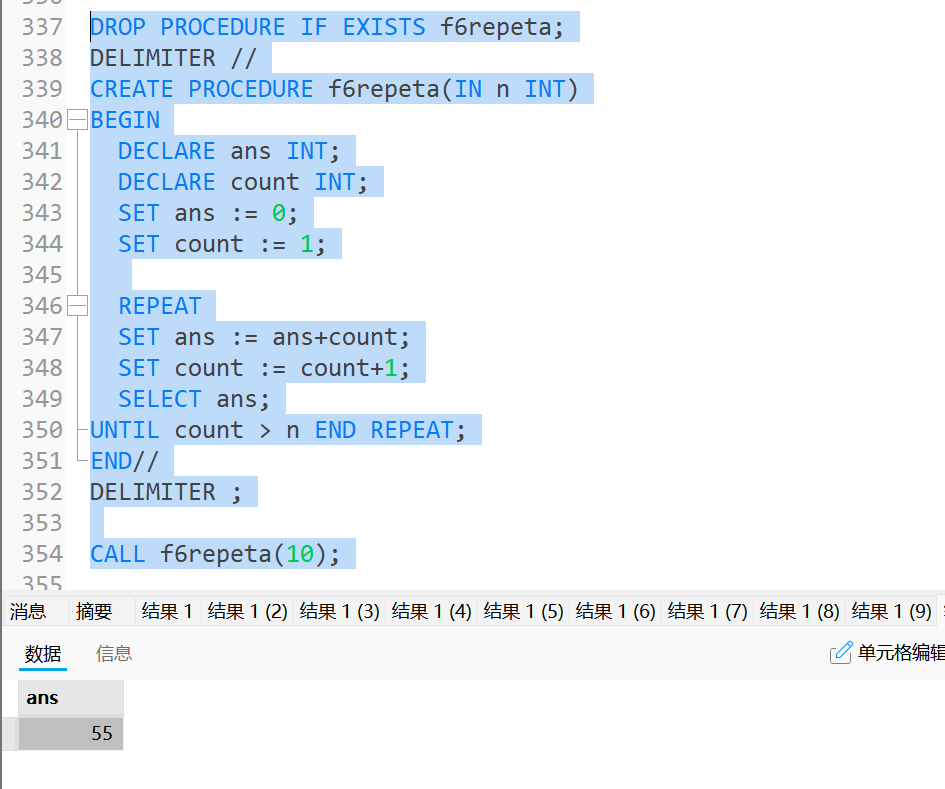
-
示例
写一个数作为
n, 并打印其i累加至n的值;sqlDROP PROCEDURE IF EXISTS f6repeta; DELIMITER // CREATE PROCEDURE f6repeta(IN n INT) BEGIN DECLARE ans INT; DECLARE count INT; SET ans := 0; SET count := 1; REPEAT SET ans := ans+count; SET count := count+1; SELECT ans; UNTIL count > n END REPEAT; END// DELIMITER ; CALL f6repeta(10);运行结果为:
4.4.3 LOOP 循环
该循环是一个最简单的循环, 且当满足某个条件时终止当前循环或是退出整个循环;
通常配合两个子句使用:
-
LEAVE label表示终止整个循环, 类似于
c/cpp中在循环中的break; -
ITERATE label表示跳过本次循环, 进入下一次循环, 类似于
c/cpp中的continue;
若是不使用上面的两个子句, 其行为类似于while(true);
sql
[begin_label: ] LOOP
statement_list
END LOOP [end_label]其中这里的label表示循环的名字, 以能够指定退出循环或者跳过当前循环;
-
示例
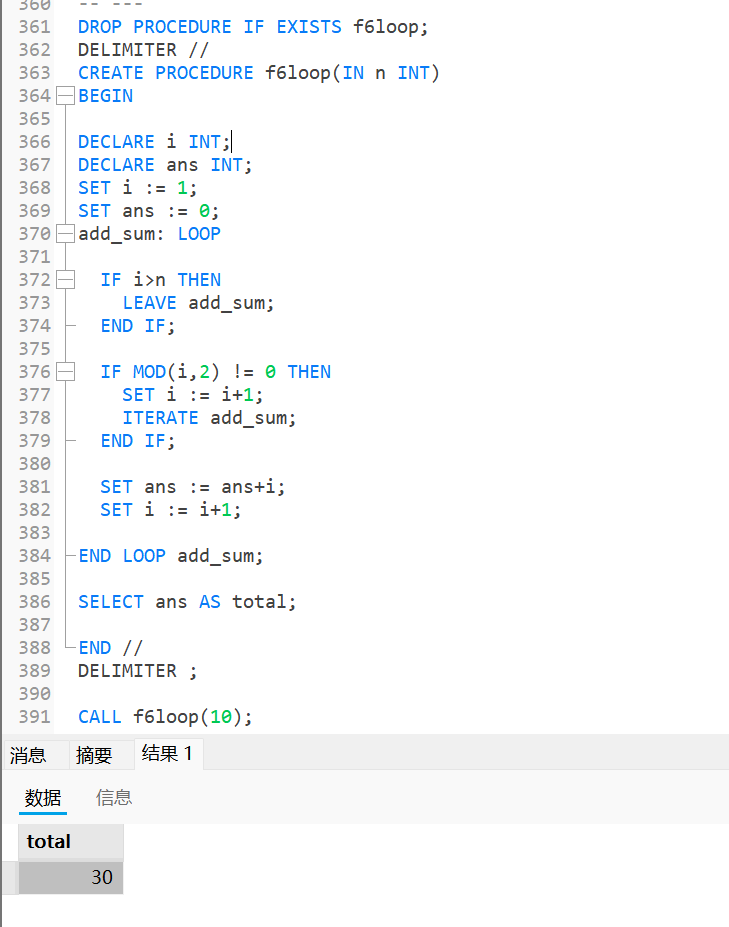
设计一个存储过程, 对
0-n中的偶数进行相加, 奇数则跳过;sqlDROP PROCEDURE IF EXISTS f6loop; DELIMITER // CREATE PROCEDURE f6loop(IN n INT) BEGIN DECLARE i INT; DECLARE ans INT; SET i := 1; SET ans := 0; add_sum: LOOP -- 定义循环体 IF i>n THEN -- 判断结束条件 LEAVE add_sum; END IF; IF MOD(i,2) != 0 THEN -- 判断跳过条件(奇数跳过) SET i := i+1; -- 跳过时也需要自增 ITERATE add_sum; END IF; SET ans := ans+i; -- 累加 SET i := i+1; -- 自增i END LOOP add_sum; -- 循环体结束 SELECT ans AS total; -- 打印累加结果 END // DELIMITER ; CALL f6loop(10);运行结果为: