本期内容为自己总结归档,7天学会Redis。其中本人遇到过的面试问题会重点标记。
(若有任何疑问,可在评论区告诉我,看到就回复)
Day2 - 深入Redis数据结构与底层实现
2.1 五大数据结构源码级解析
2.1.1 String: SDS实现与内存优化
SDS(Simple Dynamic String)设计哲学
Redis没有使用C语言传统的以空字符结尾的字符串,而是自研了SDS(简单动态字符串),这是Redis性能优化的基石之一。
传统C字符串的局限性:
-
长度计算O(n):需要遍历整个字符串
-
缓冲区溢出风险:容易发生内存越界
-
二进制不安全:无法存储包含空字符的数据
-
频繁内存重分配:每次修改都可能需要重新分配内存
SDS数据结构详解
SDS 5.0版本结构:
cpp
struct sdshdr {
int len; // 已使用字节数,O(1)获取字符串长度
int free; // 未使用字节数
char buf[]; // 字节数组,保存实际数据
};SDS 6.0+优化版本(根据长度使用不同结构):
cpp
// 优化为根不同长度使用不同header,节省内存
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; // 低3位存类型,高5位存长度
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // 已使用长度
uint8_t alloc; // 总长度,不包括header和空字符
unsigned char flags;
char buf[];
};
// 还有sdshdr16、sdshdr32、sdshdr64SDS核心优势
-
O(1)时间复杂度获取长度:直接读取len字段
-
杜绝缓冲区溢出:修改前检查空间,不足则自动扩容
-
减少内存重分配:采用空间预分配和惰性空间释放策略
-
二进制安全:使用len判断结束,可以存储任意二进制数据
-
兼容C字符串函数:buf以空字符结尾,可复用部分C库函数
内存优化策略:
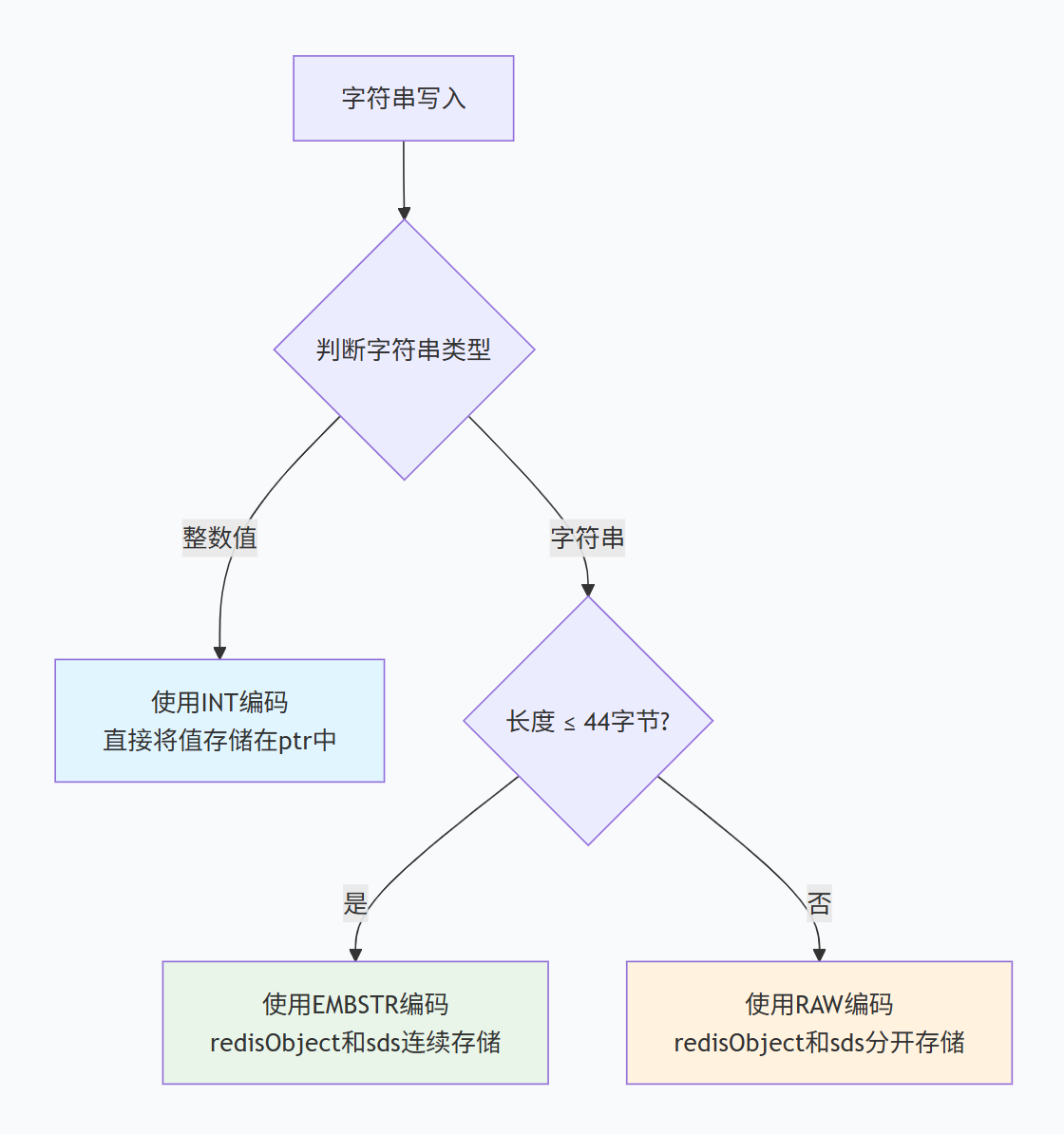
三种编码方式对比:
-
INT编码:存储整数值,ptr直接存储数值
-
EMBSTR编码:redisObject和sds连续存储,一次内存分配
-
RAW编码:redisObject和sds分开存储,两次内存分配
2.1.2 Hash: ziplist与hashtable的转换阈值
Hash的两种底层实现
Redis的Hash类型在底层有两种实现方式,根据数据特征自动选择:
-
ziplist(压缩列表):连续内存,但修改需重新分配,不适合频繁头尾插入,适合小数据量
-
hashtable(哈希表):双向链表,每个节点额外内存开销16字节,内存碎片严重,适合大数据量
ziplist结构

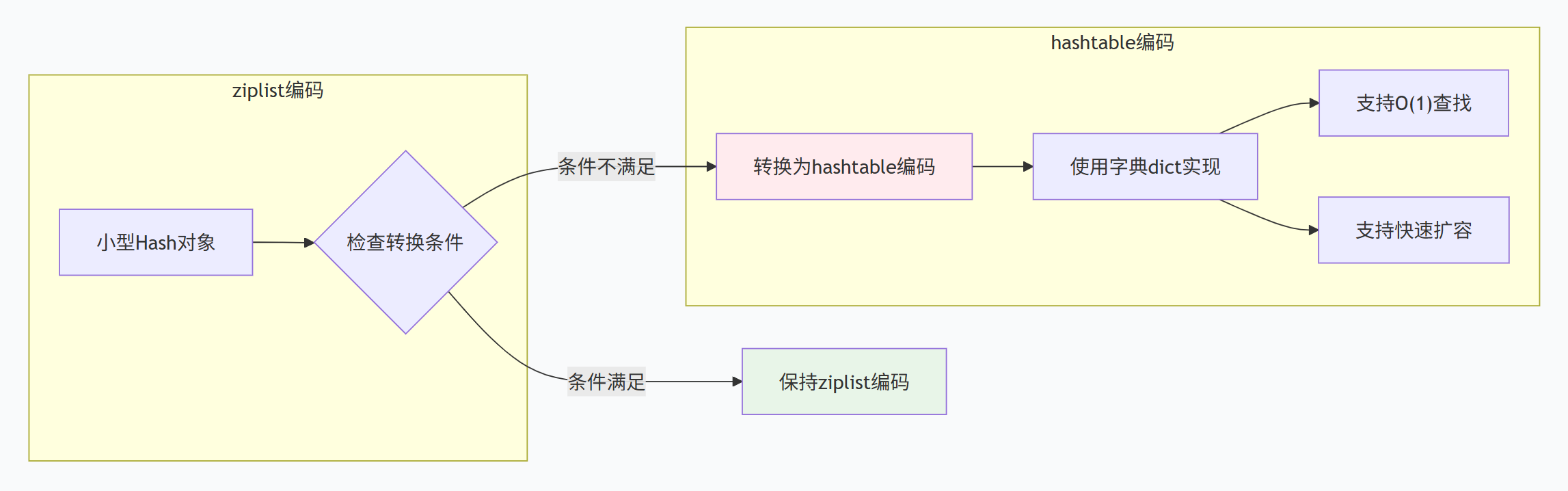
默认转换条件:
-
哈希对象保存的所有键值对的键和值的字符串长度都小于64字节
-
哈希对象保存的键值对数量小于512个
bash
# Redis配置文件中可以调整
hash-max-ziplist-entries 512 # 最大entry数
hash-max-ziplist-value 64 # 最大value长度转换时机示意图:
hashtable实现原理
Redis的hashtable使用dict结构实现,采用渐进式rehash策略:
dict结构:
cpp
typedef struct dict {
dictType *type; // 类型特定函数
void *privdata; // 私有数据
dictht ht[2]; // 哈希表数组,ht[0]和ht[1]
long rehashidx; // rehash索引,-1表示不在rehash
int iterators; // 当前正在运行的迭代器数量
} dict;渐进式rehash流程:
-
为ht1分配空间,大小是ht0.used * 2的2^n
-
设置rehashidx为0,表示rehash开始
-
每次对字典的增删改查操作时,顺带将ht0在rehashidx索引上的所有键值对rehash到ht1
-
rehash完成后,释放ht0,将ht1设置为ht0,创建新的ht1
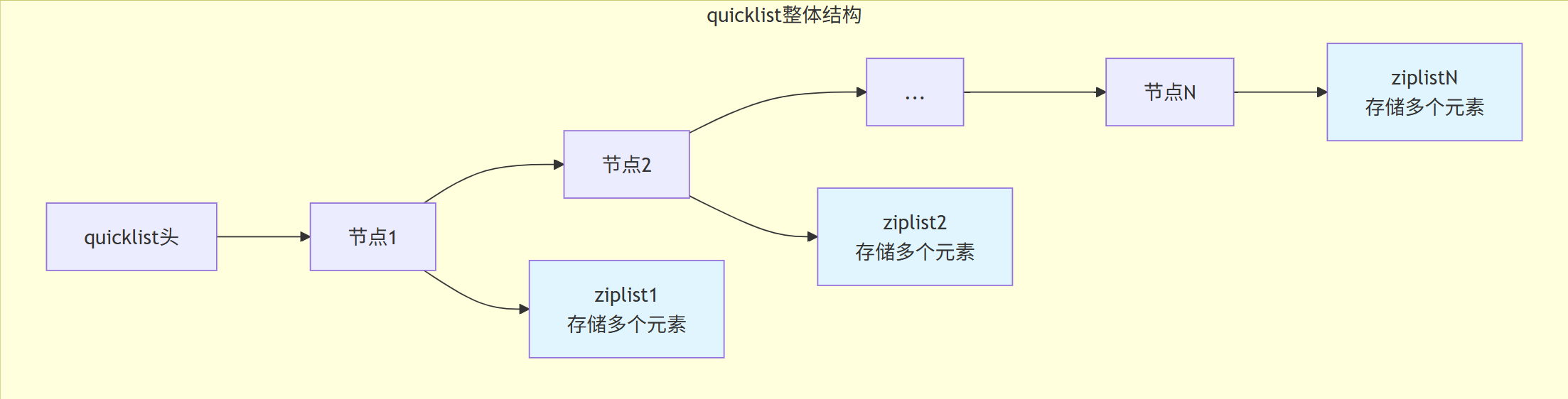
2.1.3 List: quicklist的混合设计
List的演进历程
-
Redis 3.2之前:小列表用ziplist,大列表用linkedlist
-
Redis 3.2之后:统一使用quicklist
quicklist设计思想
quicklist = ziplist + linkedlist,结合两者的优点:
性能优势分析
| 操作类型 | 传统linkedlist | quicklist | 优势 |
|---|---|---|---|
| 内存占用 | 每个节点需要prev/next指针 | 多个元素共享节点头 | 节省内存 |
| 缓存局部性 | 差,节点分散 | 好,相邻元素集中存储 | 提升CPU缓存命中率 |
| 插入删除 | O(1)但需分配节点 | O(1)但可能触发ziplist分裂 | 批量操作更高效 |
| 遍历速度 | O(n)指针跳转 | O(n)但局部连续 | 顺序访问更快 |
2.1.4 Set: intset与hashtable
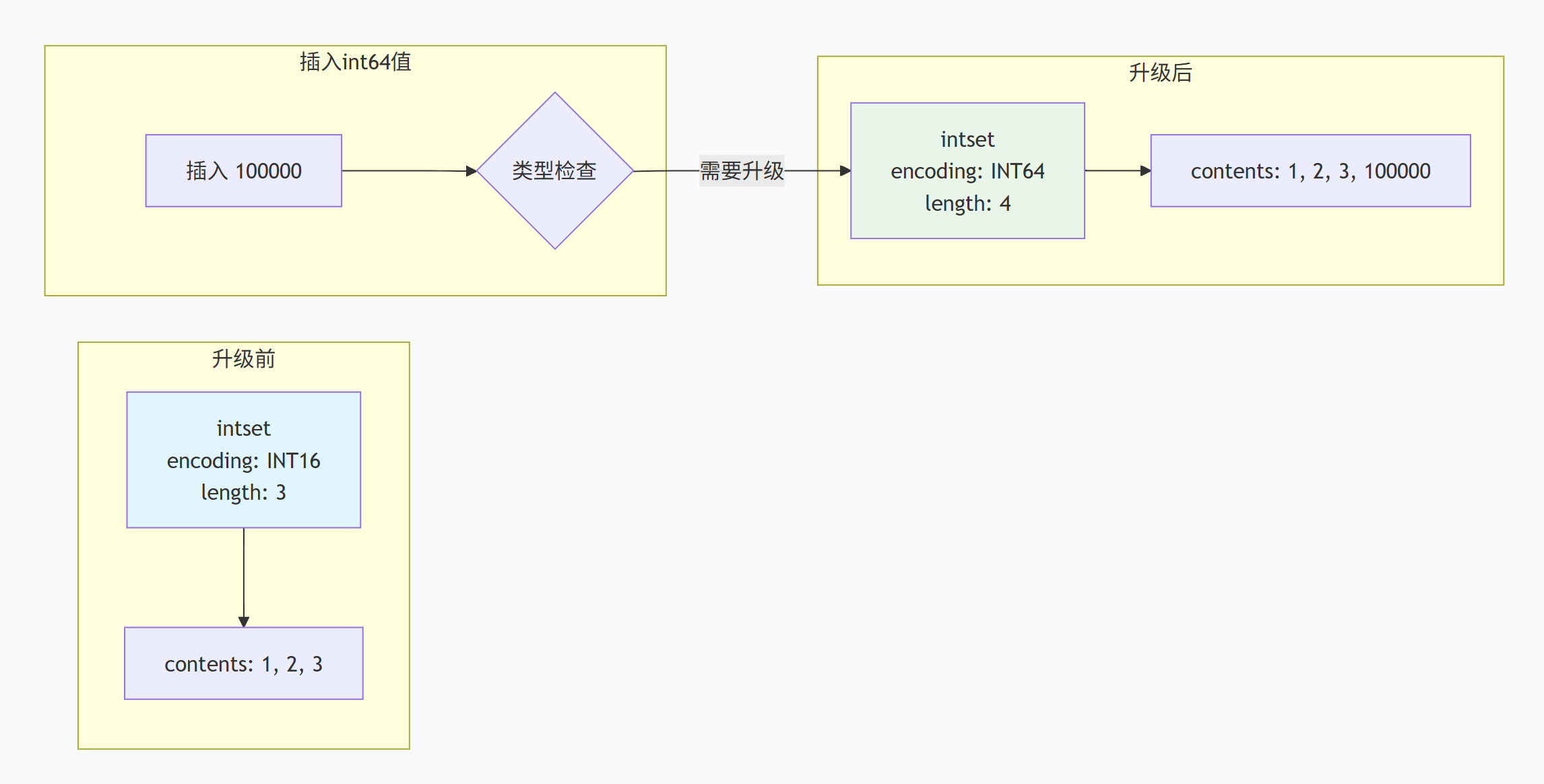
Set的两种编码方式
intset(整数集合)适用条件:
-
集合中的所有元素都是整数值
-
元素数量不超过
set-max-intset-entries(默认512)
**hashtable(哈希表)适用条件:**不满足intset条件时自动转换
intset升级示意图:
2.1.5 ZSet: 跳表+字典的巧妙组合
ZSet的双重数据结构设计
ZSet同时使用跳表(skiplist)和字典(dict)来保证:
-
范围操作高效:跳表支持O(log N)的范围查询
-
单点查询高效:字典支持O(1)的元素分值查找
Mermaid双索引结构图
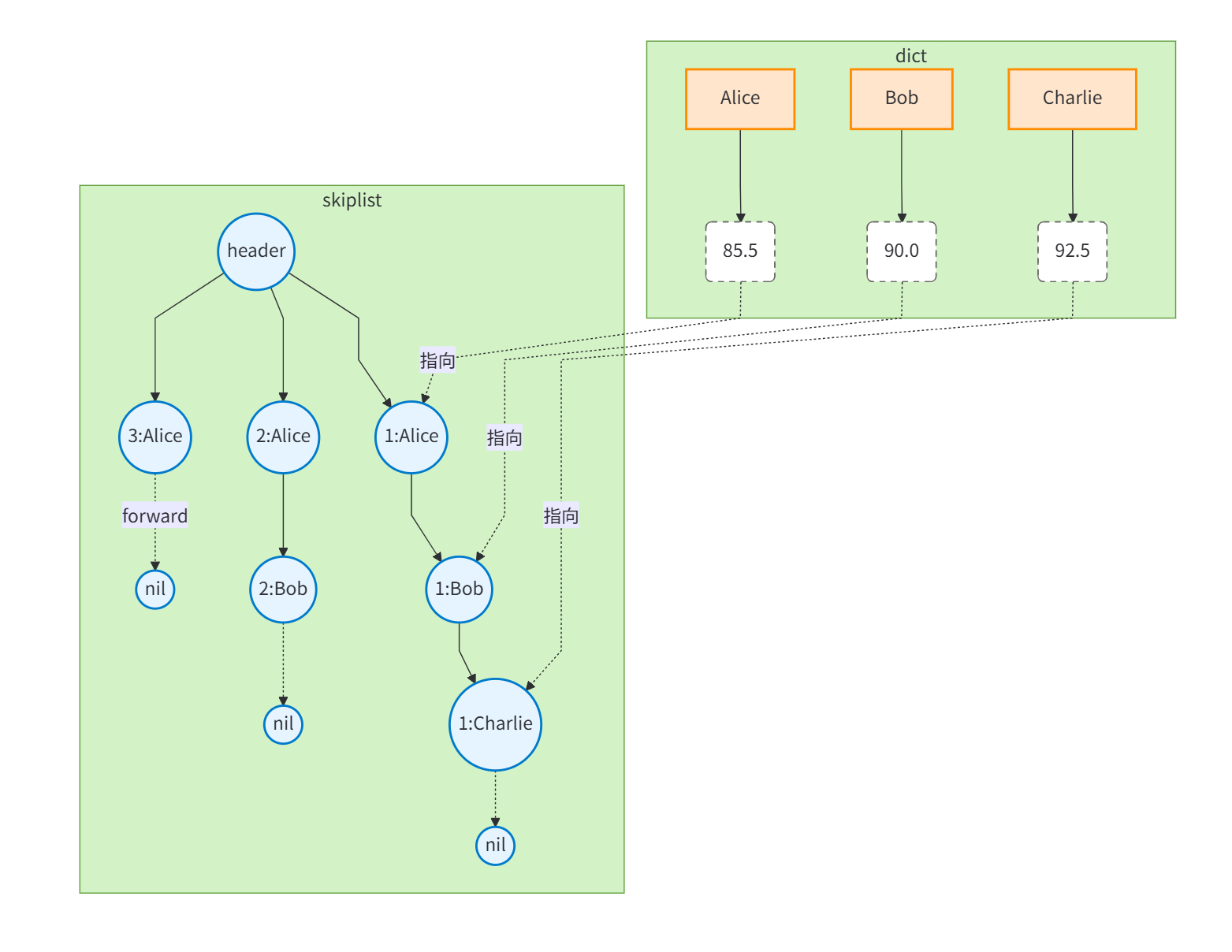
为什么需要双索引?
单用跳表(SkipList)可实现有序集合,但ZSCORE命令需O(logN)。Redis要求ZSCORE为O(1),故引入dict辅助索引。
2.2 ⭐高级数据结构实战
2.2.1 HyperLogLog:基数统计算法(PFADD/PFCOUNT)
算法原理:
基于概率统计的基数估计算法
-
哈希函数:将元素映射为64位二进制串
-
分桶统计:取低14位作为桶索引(16384个桶)
-
计算前导零:统计剩下50位中前导零的数量
-
调和平均:使用调和平均数减少极端值影响
误差分析:
-
标准误差:0.81%
-
内存占用:固定12KB(16384 * 6bit / 8)
常用命令
bash
PFADD uv:20231001 user1 user2 ... # 添加元素
PFCOUNT uv:20231001 # 获取估算值
PFMERGE uv:total uv:20231001 uv:20231002 # 合并多个HLL应用场景:
-
网站UV统计
-
搜索关键词去重统计
-
大规模数据集的基数估算
2.2.2 GeoHash: 地理位置存储
GeoHash算法
将二维经纬度编码为一维字符串:
-
区间划分:经度-180,180,纬度-90,90不断二分
-
二进制编码:根据所在区间生成0/1序列
-
Base32编码:每5位二进制转为一个字符
特性:
-
前缀匹配:相同前缀表示地理位置相近
-
边界问题:边界两侧编码差异大
应用场景:
-
计算距离,例如
# 添加地理位置 GEOADD cities 116.405285 39.904989 "北京" GEOADD cities 121.472644 31.231706 "上海" # 计算距离 GEODIST cities "北京" "上海" km
2.2.3 Bitmaps: 位图操作优化
Bitmaps本质
String类型的位操作,最大支持2^32位(512MB)。
优势:
-
极省内存:1亿用户在线状态只需12.5MB
-
位运算高效:支持与、或、非、异或等操作
应用场景
bash
# 用户签到系统
SETBIT sign:202301:user1001 0 1 # 第1天签到
SETBIT sign:202301:user1001 2 1 # 第3天签到
# 统计当月签到天数
BITCOUNT sign:202301:user1001
# 活跃用户统计
SETBIT active:20230101 1001 1
SETBIT active:20230102 1001 1
SETBIT active:20230102 1002 1
# 统计两天都活跃的用户
BITOP AND both_active active:20230101 active:20230102
BITCOUNT both_active使用建议
-
避免大key问题:单个Bitmap不要过大
-
分片策略:按用户ID范围分片
-
定期清理:过期数据及时删除
2.2.4 Streams: 消息队列实现(Redis 5.0+)
Redis Streams 是Redis 5.0引入的消息队列数据结构,提供高吞吐量、持久化的消息存储和消费机制。 Streams解决了传统消息队列的多个痛点:消息丢失、消费者组管理、消息确认等。
Streams 底层实现:
Redis Streams基于两种核心数据结构实现:
- Listpack:存储消息内容,提供高效的追加和范围查询操作。
- Rax 树(基数树):作为索引,支持快速查找和范围扫描。
常用命令
bash
XADD orders * item apple qty 5 # 添加消息
XGROUP CREATE orders cg1 $ MKSTREAM # 创建消费者组
XREADGROUP GROUP cg1 c1 COUNT 1 STREAMS orders > # 消费消息适用场景:
- 消息队列:替代传统消息中间件(如Kafka)的轻量级消息队列
- 事件流:如用户行为日志、系统事件流
- 实时监控:如服务器指标的实时采集和消费
2.3 实战案例
2.3.1 HyperLogLog实战:统计UV
以下是一个使用HyperLogLog统计网站UV的实战案例(python):
python
import redis
连接Redis
r = redis.Redis(host='localhost', port=6379, db=0)
添加用户ID
user_ids = ["user123", "user456", "user789", ...] # 假设百万级用户ID
for user_id in user_ids:
r.pfadd("web:uv", user_id)
查询UV值
uv_count = r.pfcount("web:uv")
print(f"网站UV:{uv_count}")
合并多个HyperLogLog
r.pfmerge("total:uv", "web:uv", "app:uv")
total_uv = r.pfcount("total:uv")
print(f"总UV:{total_uv}")2.3.2 GeoHash实战:附近的人
以下是一个使用GeoHash实现"附近的人"功能的实战案例:
python
import redis
import math
连接Redis
r = redis.Redis(host='localhost', port=6379, db=0)
添加用户位置
users = {
"user123": {"lon": 116.48105, "lat": 39.9053908600, "name": "张三"},
"user456": {"lon": 116.514203, "lat": 39.905409, "name": "李四"},
# ... 其他用户
}
for user_id, user in users.items():
# 添加用户位置到GeoHash
r.geoadd("users:地理位置", user["lon"], user["lat"], user_id)
# 存储用户详细信息
r.hset(f"users:{user_id}", mapping={"name": user["name"], ...})查询附近用户(以user123为中心,半径5公里)
nearby_users = r.georadius("users:地理位置", 116.48105, 39.9053908600, 5000, "km", withdist=True, withhash=True)
遍历结果,获取用户详细信息
for user_id, (distance, geohash) in nearby_users:
user_info = r.hgetall(f"users:{user_id}")
print(f"用户ID:{user_id},距离:{distance}米,信息:{user_info}")
2.3.3 Bitmaps实战:用户签到统计
以下是一个使用Bitmaps实现用户签到统计的实战案例:
python
import redis
from datetime import datetime, timedelta
连接Redis
r = redis.Redis(host='localhost', port=6379, db=0)
用户签到(假设一个月31天)
def user_signin(user_id):
# 获取当前日期的day of month
today = datetime.now().day
# 设置对应位为1
r.setbit(f"users:{user_id}:sign", today-1, 1)
统计用户本月签到天数
def get_sign_count(user_id):
# 获取本月第一天的日期
first_day = datetime.now().replace(day=1)
# 计算距离本月第一天的天数
offset = (datetime.now() - first_day).days
# 统计当前月已签到天数
return r.bitcount(f"users:{user_id}:sign", start=0, end=offset)
统计用户连续签到天数
def get_max_consecutive_sign(user_id):
max_count = 0
current_count = 0
# 遍历位图
for i in range(31):
val = r.getbit(f"users:{user_id}:sign", i)
if val:
current_count += 1
if current_count > max_count:
max_count = current_count
else:
current_count = 0
return max_count2.3.4 Streams实战:消息队列
以下是一个使用Streams实现消息队列的实战案例:
python
import redis
连接Redis
r = redis.Redis(host='localhost', port=6379, db=0)
生产者:添加消息
def produce_message(message):
# 添加消息到Stream,使用*表示自动生成ID
# 消息ID格式:-
r.xadd("mystream", fields={"message": message}, id="*")
消费者:消费消息
def consume_messages(group, consumer):
# 从消费者组中读取消息
# ">-"表示只读取新消息
# COUNT=1表示每次读取一条消息
# blocking=True表示阻塞直到有新消息
messages = r.xreadgroup(
groupname=group,
consumername=consumer,
streams={},
count=1,
latest_id=">-",
block=True
)
# 处理消息
for stream_id, message in messages:
for entry_id, fields in message.items():
try:
# 处理消息内容
process_message(fields["message"])
# 确认消息
r.xack(stream_id, group, entry_id)
except Exception as e:
# 处理失败,将消息重新入队
r.xclaim(stream_id, group, consumer, 10000, [entry_id]) # 10秒内不确认则重新入队
创建消费者组
def create消费组(group):
# 从开始消费,表示只消费新消息
r.xgroup_create("mystream", group, "", mkstream=True)
主函数
if __name__ == "__main__":
# 创建消费者组
create消费组("group1")
# 启动消费者
consume_messages("group1", "consumer1")2.4 ⭐面试高频考点
考点1、Redis有几种数据类型,各自的场景。
罗列基础5种类型+重点讲述高级数据结构和场景
考点2:Hash类型在什么情况下使用ziplist和hashtable?
面试回答:
Hash类型的编码转换由两个配置参数控制:
-
ziplist编码条件(同时满足):
-
所有键值对的键和值字符串长度都小于
hash-max-ziplist-value(默认64字节) -
键值对数量小于
hash-max-ziplist-entries(默认512个)
-
-
hashtable编码条件: 不满足上述任一条件时转换
ziplist优势 :内存紧凑,连续存储,适合小型Hash
hashtable优势:O(1)查找,支持快速扩容,适合大型Hash
当Hash从ziplist转为hashtable后,即使数据减少也不会转回ziplist,这是为了避免频繁转换的开销。